はじめに
はじめまして,佐藤佑哉です.
新年あけましておめでとうございます.今年もよろしくお願いいたします.
きっかけ
機械学習ライブラリを触ろうと始めたきっかけは,モバイルアプリの開発を通して興味を持ったことがきっかけです.ハッカソン・案件を通して,機械学習の機能を導入した開発にふれる機会が多くありました.その一方で,柔軟なユースケースに合ったライブラリが少なかったり,その背景知識がない影響で技術選定に時間がかかったりしていました.
なので,上記問題を解決するべく,実装ベースでこれらの概要・実装の理解を深めていきたいと考えました.機械学習の根本から学んでいくぞ!と思ったのですが,どうしても実装とはかけはなれた概念・手法がメインになってきたりするため,実装ベースで体系的にアウトプットすることが吉だと考えました.
LiteRT(旧 TensorFlow Lite)の概要
LiteRTは,様々なデバイス上での機械学習を可能にするツールセットです.複数のプラットフォームや言語に対応しており,より効率的な開発が可能になります.昨年11月まではTensorFlow Liteと呼ばれていましたが,性能は劣らず機械学習のツールセットとして機能しております.
ほぼ同様の機能としてMediaPipe Taskが挙げられますが,カスタムなモデルを使用し,より柔軟なユースケースに使用したい場合はLiteRT,既存モデルを使用してユースケースを満たせる場合は,MediaPipe Taskを使用するのも一つの方向性としていいかもしれません(2024/01/04時点でMediaPipe TaskはiOSへのサポートはされていない状態のようです).
It supports multiple platforms, including Android, Web / JavaScript, Python, and support for iOS is coming soon.
LiteRTを使用してモデルを選択する
アプリに統合するためのモデルを選択していきます.ここでは一旦,実装フローを学んでみたいので,下記の物体検出モデルを使用してみたいと思います.
上記,読み進めて,LiteRT (formely TFLite) → lite0-detection-metadataを押下し,1.tfileとしてダウンロードできるかと思います.
取得したファイルは,src/main/assets/フォルダに保存しておきます.
また,あらかじめ,ファイル名をEfficientDet-Lite0.tfliteに変更しておきます.
Androidアプリを実装する
こちらのドキュメントを基に実装を進めていきたいと思います.
LiteRTの依存関係追加
最初に,依存関係を追加します.
今回はGoogle推奨のGoogle Play Services提供のものを使用したいと思います.
// LiteRT dependencies for Google Play services
implementation ("com.google.android.gms:play-services-tflite-java:16.1.1")
// Optional: include LiteRT Support Library
implementation ("com.google.android.gms:play-services-tflite-support:16.1.1")
これによって,モデルとの橋渡しになるInterpreterApiが使用可能になります.
LiteRTを初期化する
LiteRT APIを使用する前に初期化を行います.今回は,MainActivity::onCreateで行います.
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
TfLite.initialize(this)
/*...*/
}
サンプル画像を用意する
今回はこちらの猫イメージを使用したいと思います.かわいいですね.

また,Bitmapとして取得しておきます.
val catBitmap = BitmapFactory.decodeResource(context.resources, R.drawable.cat)
入力用データを作成する
次に,入力用データを用意します.
画像を前処理する
現在のままだと,モデルに対して画像を送信できないため,画像をモデルの入力データの要件に合うように前処理していきます.
LiteRTで画像を扱うために前述のcatBitmapをTensorImageに変換していきます.
EfficientDetのInputsを見てみると,以下の要件で入力する必要があります.
Inputs
Image data: ByteBuffer sized HEIGHT x WIDTH x 3, where HEIGHT = 320 and WIDTH = 320 with values in [0, 255].
最初に,TensorImageを宣言し,対象データを読み込みます.
パラメータの型がfloat32なので,Float32として設定します.
val tensorImage = TensorImage(DataType.UNIT8)
/* or */
val inputTensor = interpreter.getInputTensor(0)
val tensorImage = TensorImage(inputTensor.dataType())
tensorImage.load(catBitmap)
ここで,catBitmapの画像への前処理を行っていきます.
画像への前処理にはImageProcessorを使用して行っていきます.
val imageProcessor = ImageProcessor
.Builder()
// リサイズ, 320x320に変換, バイリニア補間
.add(ResizeOp(320, 320, ResizeOp.ResizeMethod.BILINEAR))
.build()
作成したImageProcessorを使用してcatBitmapの画像に前処理を適用します.
val processedImage = imageProcessor.process(tensorImage)
これで作成した,入力用のデータは完成です.
出力用のバッファを作成する
出力した結果を受け取るためにあらかじめバッファを作成する必要があります.下記はその手順になります.
まず初めに,バッファの容量を決めるために,出力されるデータの情報を知る必要があります.
ダウンロード & ファイル名変更したEfficientDet-Lite0.tfliteにアクセスすると,Outputsが以下のように記載されていると思います.
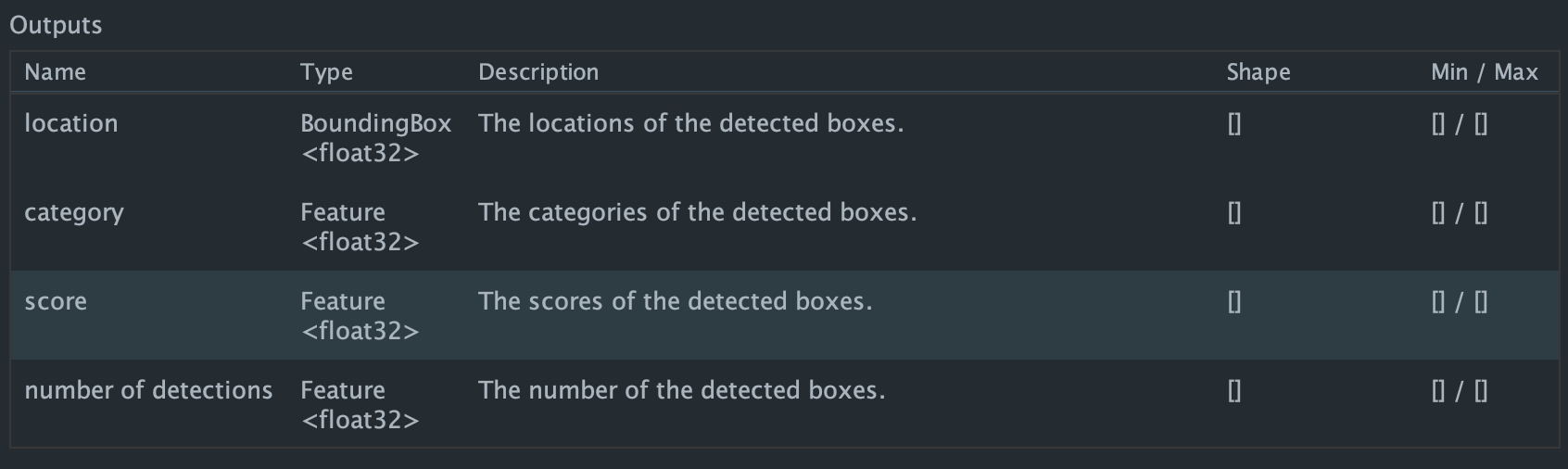
上記説明にしたがって,出力用のバッファを用意していきましょう.
val location = FloatBuffer.allocate(MAX_DETECTIONS * 4)
val category = FloatBuffer.allocate(MAX_DETECTIONS)
val score = FloatBuffer.allocate(MAX_DETECTIONS)
val numberOfDetection = FloatBuffer.allocate(1)
val outputBuffer = mapOf(
0 to location,
1 to category,
2 to score,
3 to numberOfDetection,
)
/*...*/
companion object {
private const val MAX_DETECTIONS = 25
}
入力用データ・出力用バッファを使用して実際に推論する
先ほど作成した入力用データと出力用バッファを使用して推論していきます.
サンプルコードを参考に,推論するための設定クラスを作成していきます.
val interpreterOption = InterpreterApi
.Options
.setRuntime(TfLiteRuntime.FROM_SYSTEM_ONLY)
val file = FileUtil.loadMappedFile(
context,
"EfficientDet-Lite0.tflite"
)
// 推論する際にデータを送信する際に使用する
val interpreter = InterpreterApi.create(file, interpreterOption)
そして実際に推論します.
interpreter.runForMultipleInputsOutputs(arrayOf(processedImage.buffer), outputBuffer)
実際に推論した結果はこちらになります.
location: [0.0996795, 0.29055202, 0.9279443, ... , 0.9960053] (size: 100)
category: [16.0, 16.0, 83.0, ... , 83.0] (size: 25)
score [0.828125, 0.18359375, 0.109375 ... 0.01953125] (size: 25)
numberOfDetection: [25.0] (size: 1)
推論で得た結果をUIに表示する
上記で出力したlocationを使用して物体検出した箇所を枠で囲う実装をしていきたいと思います.
UIで使用できるようにデータクラスを作成する
現在のデータのままだと結果が分かりづらいので,データクラスに落とし込みます.
data class DetectionResult(
val locations: FloatBuffer,
val categories: FloatBuffer,
val score: FloatBuffer,
val numberOfDetection: FloatBuffer,
)
data class BoundingBox(
val yMin: Float,
val xMin: Float,
val yMax: Float,
val xMax: Float,
)
fun FloatArray.toBoundingBoxes(): List<BoundingBox> {
val boxes = mutableListOf<BoundingBox>()
for (i in indices step 4) {
boxes.add(
BoundingBox(
yMin = this[i],
xMin = this[i + 1],
yMax = this[i + 2],
xMax = this[i + 3],
)
)
}
return boxes
}
推論した結果をboundingBoxStateにバインドします.UI側ではこのboundingBoxStateを使用していきます.
class MainViewModel(/*...*/) : ViewModel() {
private val _boundingBoxState = MutableStateFlow(emptyList<BoundingBox>())
val boundingBoxState: StateFlow<List<BoundingBox>> = _boundingBoxState.asStateFlow()
fun runInference(input: Bitmap) {
val result = _runInference(input)
_boundingBoxState.value = result.location.array().toBoundingBoxes()
}
private fun _runInference(input: Bitmap){
/*...*/
return DetectionResult(
location = location,
category = category,
score = score,
numberOfDetection = numberOfDetection,
)
}
}
必要なコンポーネントを作成する
まずはじめに,四角形枠を描画するOutlinedRectangleを実装します.
コンポーネントの作成には,Jetpack Composeを使用します.
@Composable
fun OutlinedRectangle(
xMin: Float,
yMin: Float,
xMax: Float,
yMax: Float,
color: Color = Color.Red,
strokeWeight: Float = 4f,
modifier : Modifier = Modifier,
) {
Canvas(modifier = modifier) {
drawRect(
topLeft = Offset(xMin, yMin),
size = Size(
width = xMax - xMin,
height = yMax - yMin,
),
color = color,
style = Stroke(strokeWeight),
)
}
}
改めて,推論から得た,locationの値を見てみましょう.
location: [0.0996795, 0.29055202, 0.9279443, ... , 0.9960053] (size: 100)
以上のようになっているため,画面のサイズの比率に合わせてスケーリングする必要がありそうです.以下のように実装することで,適切に描画するようになります.
@Composable
private fun BoxWithScaledOutlinedRectangles(
modifier: Modifier = Modifier,
boxes: List<BoundingBox>,
content: @Composable () -> Unit,
) {
var xScale by remember { mutableIntStateOf(0) }
var yScale by remember { mutableIntStateOf(0) }
Box(
modifier = modifier
.onGloballyPositioned {
yScale = it.size.height
xScale = it.size.width
}
) {
content()
boxes.forEach { box ->
OutlinedRectangle(
xMin = box.xMin * xScale,
yMin = box.yMin * yScale,
xMax = box.xMax * xScale,
yMax = box.yMax * yScale,
)
}
}
}
画面全体のComposableを作成して実際に推論していきましょう.
画面全体のComposableコード
@Composable
private fun MainScreen(
viewModel: MainViewModel = hiltViewModel()
) {
@DrawableRes val imageRes: Int = R.drawable.cat_sample
val context = LocalContext.current
val boundingBoxState = viewModel.boundingBoxState.collectAsStateWithLifecycle()
Scaffold(
modifier = Modifier.fillMaxSize(),
) {
Column(
modifier = Modifier.padding(it),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally,
) {
Text("Hello LiteRT!")
Spacer(Modifier.height(16.dp))
BoxWithScaledOutlinedRectangles(
boxes = boundingBoxState.value,
) {
Image(
painter = painterResource(imageRes),
contentDescription = null,
)
}
Spacer(Modifier.height(16.dp))
OutlinedButton(
onClick = {
val bitmap = BitmapFactory.decodeResource(context.resources, imageRes)
viewModel.runInference(bitmap)
},
) {
Text("Run Inference")
}
}
}
}
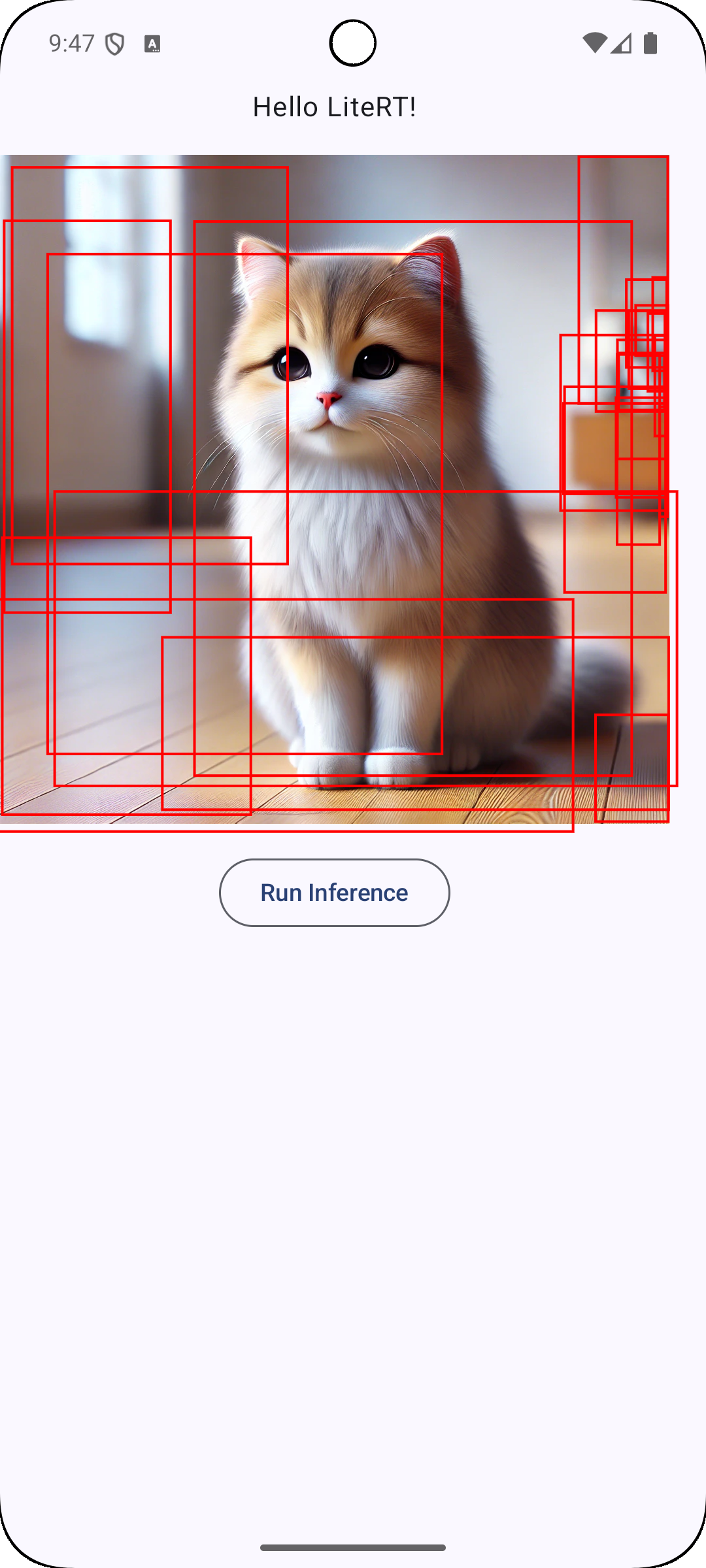
これで推論結果を画面に出力することが出来ました.
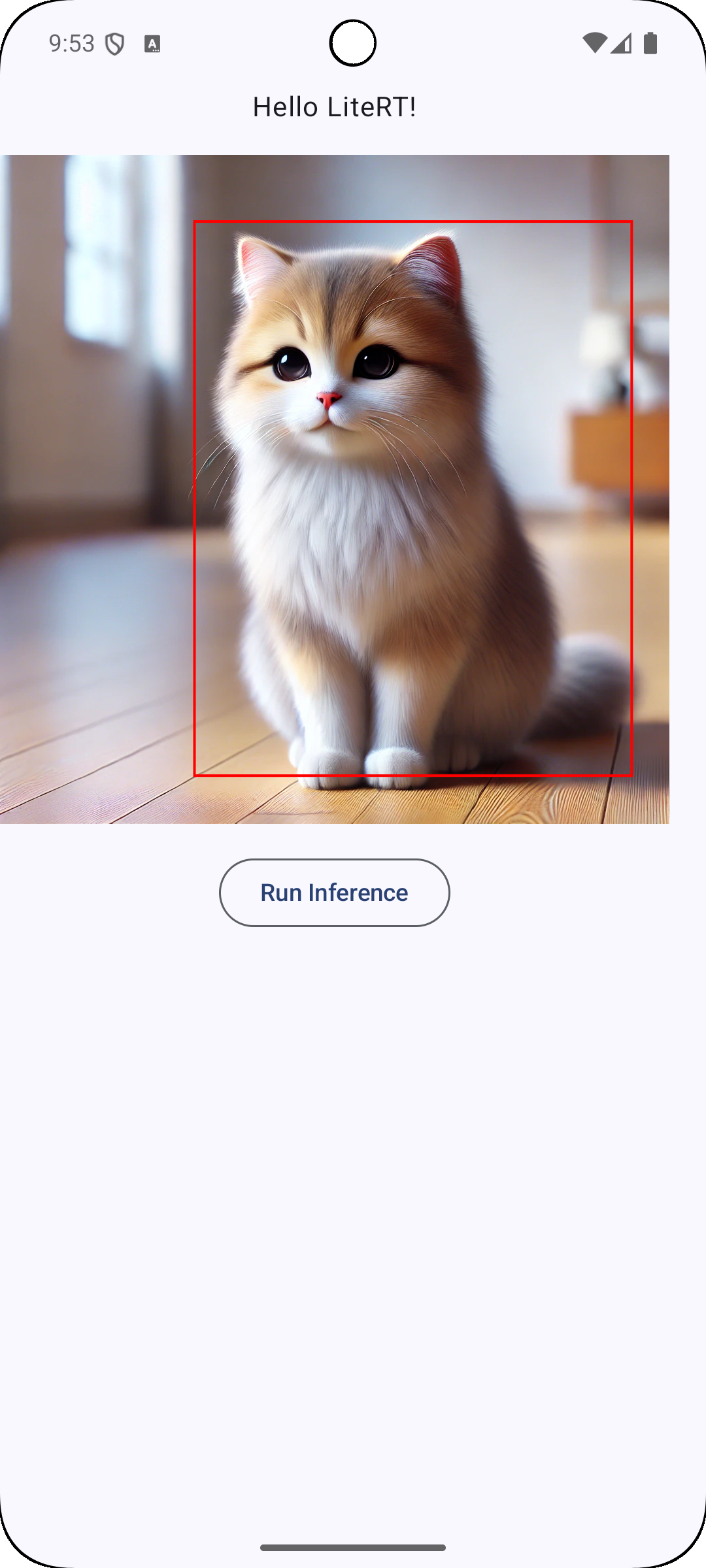
赤枠が多いので,次のようにscoreでフィルタリングして特定の物体だけにフォーカスすることも可能です.
val result = _runInference(data)
// score > 0.5のものだけを抽出
_boundingBoxState.value = result.location.array().toBoundingBoxes()
.zip(result.score.array().toList())
.filter { it.second > 0.5 }
.map { it.first }
検出した結果にラベルをつける(Optional)
推論で得たデータcategoryを使用して,ラベリングしていきます.今回使用したEfficientDet-Lite0.tfliteはカテゴリを数値で返してくるため,それをラベルに変換するデータが必要になります.
色々と見漁ってたらカテゴリをまとめたものがあったので,これを参考に実装していきます.
ObjectDetector APIを使用すると,このカテゴリ値を基にラベルに保管してくれます.
LiteRTをベースに触っているため,今回は触れませんでしたが,モデルの要件を満たしており,物体検出の導入をしたい場合はこちらを使用することをおすすめします.
https://ai.google.dev/edge/litert/libraries/task_library/object_detector
enum class Category(val id: Int, val label: String) {
PERSON(1, "person"),
BICYCLE(2, "bicycle"),
CAR(3, "car"),
MOTORCYCLE(4, "motorcycle"),
AIRPLANE(5, "airplane"),
BUS(6, "bus"),
TRAIN(7, "train"),
TRUCK(8, "truck"),
BOAT(9, "boat"),
TRAFFIC_LIGHT(10, "traffic light"),
FIRE_HYDRANT(11, "fire hydrant"),
STOP_SIGN(13, "stop sign"),
PARKING_METER(14, "parking meter"),
BENCH(15, "bench"),
BIRD(16, "bird"),
CAT(17, "cat"),
DOG(18, "dog"),
HORSE(19, "horse"),
SHEEP(20, "sheep"),
COW(21, "cow"),
ELEPHANT(22, "elephant"),
BEAR(23, "bear"),
ZEBRA(24, "zebra"),
GIRAFFE(25, "giraffe"),
BACKPACK(27, "backpack"),
UMBRELLA(28, "umbrella"),
HANDBAG(31, "handbag"),
TIE(32, "tie"),
SUITCASE(33, "suitcase"),
FRISBEE(34, "frisbee"),
SKIS(35, "skis"),
SNOWBOARD(36, "snowboard"),
SPORTS_BALL(37, "sports ball"),
KITE(38, "kite"),
BASEBALL_BAT(39, "baseball bat"),
BASEBALL_GLOVE(40, "baseball glove"),
SKATEBOARD(41, "skateboard"),
SURFBOARD(42, "surfboard"),
TENNIS_RACKET(43, "tennis racket"),
BOTTLE(44, "bottle"),
WINE_GLASS(46, "wine glass"),
CUP(47, "cup"),
FORK(48, "fork"),
KNIFE(49, "knife"),
SPOON(50, "spoon"),
BOWL(51, "bowl"),
BANANA(52, "banana"),
APPLE(53, "apple"),
SANDWICH(54, "sandwich"),
ORANGE(55, "orange"),
BROCCOLI(56, "broccoli"),
CARROT(57, "carrot"),
HOT_DOG(58, "hot dog"),
PIZZA(59, "pizza"),
DONUT(60, "donut"),
CAKE(61, "cake"),
CHAIR(62, "chair"),
COUCH(63, "couch"),
POTTED_PLANT(64, "potted plant"),
BED(65, "bed"),
DINING_TABLE(67, "dining table"),
TOILET(70, "toilet"),
TV(72, "tv"),
LAPTOP(73, "laptop"),
MOUSE(74, "mouse"),
REMOTE(75, "remote"),
KEYBOARD(76, "keyboard"),
CELL_PHONE(77, "cell phone"),
MICROWAVE(78, "microwave"),
OVEN(79, "oven"),
TOASTER(80, "toaster"),
SINK(81, "sink"),
REFRIGERATOR(82, "refrigerator"),
BOOK(84, "book"),
CLOCK(85, "clock"),
VASE(86, "vase"),
SCISSORS(87, "scissors"),
TEDDY_BEAR(88, "teddy bear"),
HAIR_DRIER(89, "hair drier"),
TOOTHBRUSH(90, "toothbrush");
companion object {
private val map = entries.associateBy(Category::id)
fun fromId(id: Int): Category? {
return map[id]
}
}
}
カテゴリのenumを実装いたしましたので,これをViewModelやScreenに反映していきます.
data class InferenceResultUiModel(
val boundingBox: BoundingBox,
val category: Category?,
val score: Float
)
class MainViewModel @Inject constructor(/*...*/) : ViewModel() {
private val _inferenceResultUiState = MutableStateFlow(emptyList<InferenceResultUiModel>())
val inferenceResultUiState: StateFlow<List<InferenceResultUiModel>> =
_inferenceResultUiState.asStateFlow()
fun runInference(input: Bitmap) {
val result = _runInference(input)
_inferenceResultUiState.value = result.location
.toBoundingBoxes()
.filterIndexed { index, _ -> result.score[index] > 0.5 }
.mapIndexed { index, boundingBox ->
InferenceResultUiModel(
boundingBox = boundingBox,
category = Category.fromId(result.category[index].toInt()),
score = result.score[index]
)
}
}
}
コンポーネントやスクリーンの変更コード(長いので省略)
@Composable
private fun MainScreen(
viewModel: MainViewModel = hiltViewModel()
) {
@DrawableRes val imageRes: Int = R.drawable.cat_sample
val context = LocalContext.current
val inferenceResultUiState = viewModel.inferenceResultUiState.collectAsStateWithLifecycle()
Scaffold(
modifier = Modifier.fillMaxSize(),
) {
Column(
modifier = Modifier.padding(it),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally,
) {
Text("Hello LiteRT!")
Spacer(Modifier.height(16.dp))
BoxWithScaledOutlinedRectangles(
inferenceResults = inferenceResultUiState.value,
) {
Image(
painter = painterResource(imageRes),
contentDescription = null,
)
}
Spacer(Modifier.height(16.dp))
OutlinedButton(
onClick = {
val bitmap = BitmapFactory.decodeResource(context.resources, imageRes)
viewModel.runInference(bitmap)
},
) {
Text("Run Inference")
}
}
}
}
@Composable
private fun BoxWithScaledOutlinedRectangles(
modifier: Modifier = Modifier,
inferenceResults: List<InferenceResultUiModel>,
content: @Composable () -> Unit,
) {
var xScale by remember { mutableIntStateOf(0) }
var yScale by remember { mutableIntStateOf(0) }
Box(
modifier = modifier
.onGloballyPositioned {
yScale = it.size.height
xScale = it.size.width
},
) {
content()
inferenceResults.forEach { result ->
OutlinedRectangleWithText(
xMin = result.boundingBox.xMin * xScale,
yMin = result.boundingBox.yMin * yScale,
xMax = result.boundingBox.xMax * xScale,
yMax = result.boundingBox.yMax * yScale,
text = "${result.category} ${result.score}",
)
}
}
}
@Composable
fun OutlinedRectangle(
xMin: Float,
yMin: Float,
xMax: Float,
yMax: Float,
topLeft: Offset = Offset(xMin, yMin),
color: Color = Color.Red,
strokeWeight: Float = 4f,
modifier: Modifier = Modifier,
onDraw: DrawScope.() -> Unit = {},
) {
Canvas(modifier = modifier) {
drawRect(
topLeft = topLeft,
size = Size(
width = xMax - xMin,
height = yMax - yMin,
),
color = color,
style = Stroke(strokeWeight),
)
onDraw()
}
}
@Composable
private fun OutlinedRectangleWithText(
xMin: Float,
yMin: Float,
xMax: Float,
yMax: Float,
text: String,
topLeft: Offset = Offset(xMin, yMin),
modifier: Modifier = Modifier,
) {
val textMeasure = rememberTextMeasurer()
OutlinedRectangle(
xMin = xMin,
yMin = yMin,
xMax = xMax,
yMax = yMax,
topLeft = topLeft,
modifier = modifier,
) {
val measuredText = textMeasure.measure(
text = text,
style = TextStyle(
color = Color.White,
fontSize = 16.sp,
),
)
drawRect(
topLeft = topLeft,
size = measuredText.size.toSize(),
color = Color.Red,
)
drawText(
textLayoutResult = measuredText,
topLeft = topLeft,
)
}
}
以上の実装で,無事にいい感じの物体検出のアプリを作成することが出来ました.
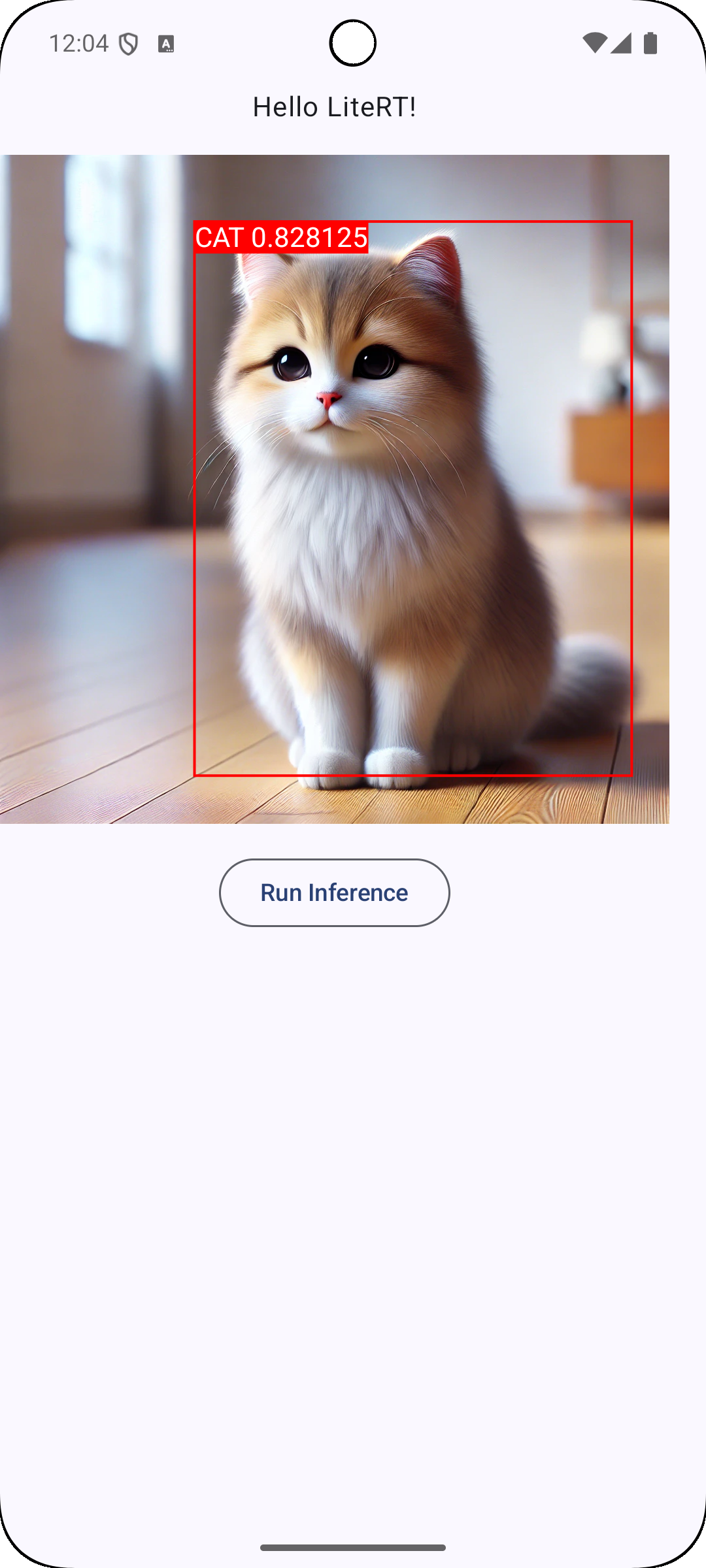
まとめ
本記事では,LiteRTを使用した簡単な物体検出アプリを作成してみました.
TensorFlow Liteを触ったことがない私にとっては,LiteRTのドキュメントを読んでも,実装方法が載っておらずドキュメント内を紆余曲折してしまって実装に少し時間をかけてしまいましたが,モバイルアプリでの実装方法・範囲を網羅できるいい時間となりました.
また,LiteRTを使用したサンプルアプリが少なく,ほぼいちからの実装が必要だったためドキュメントを熟読理解できる良い機会となりました.
今回の記事を通して,LiteRTを使用して実装する方の方の1つの助けになれば幸いです.
参考
TensorFlow Liteを軽く触った際,モデル何もわからんとなっていたので,機械学習・モデルの仕組み・ニューラルネットワークの解像度を上げるために途中途中で学習を挟んでいた教材です.