Neural Network Console Challenge
ソニーが開発したプログラミングなしでディープランニングを実装できるツールである Neural Network Console(以降 NNC)を用いたコンテストのテーマとして「写真の情景を表現するオノマトペ」を作成
- 内容:NNC を用いて PIXTA の写真素材を画像分類
- 期間:2020年3月4日(水) - 2020年3月27日(金)
- リンク: Neural Network Console Challenge
もともと私自身写真が好きで PIXTA の1万枚の画像に興味があったことと、Neural Network を勉強するのにちょうど良いきっかけと思い応募。4つのテーマのうち、『人物画像を NNC で学習させ新しいオノマトペ(擬音語/擬声語/擬態語)の画像カテゴリ分類を作り出す』のコンテストに参加
Neural Network の設計と学習
設計の方向性
-
写真全体の雰囲気で分類
PIXTA の画像が情景に合わせた色合いに出来上がっているので、色合いから情景ごとに分類し、それぞれオノマトペを当てはめた。 -
情景の分類
- 海、空など青を基調とした画像
- 森林や草木などの緑を基調とした画像
- 古い町並みや紅葉などオレンジ系(暖色系)の画像
- 日没間際や夜景などの全体的に輝度が低い(ダークブルー系)画像
- オフィスや会議などの白黒系の色が多い画像
- 複数の人が談笑している明るい雰囲気の画像
- 人の写っていない料理の画像(おまけ)
-
オノマトペ
上記1~7の分類に対してそれぞれ以下のオノマトペを割り当てた。- キラキラ
- さっそう
- しっとり
- しっぽり
- シャキッ!
- わいわい
- ごくり
アノテーション
画像ファイルには「絞り値」、「露出時間」、「ISO速度」、「焦点距離」等の情報が含まれるものの、これらの情報から機械的に振り分けることは難しいと判断し、目視にて各場景の特徴量が強く出ているように見える画像を選び 1万枚の中から 808枚を選択した。今回は時間の都合上、特徴量の強く出ている写真のみを抽出したが、時間があればもう少し特徴量の少ない写真を用いた場合の結果についても試してみたい。
下記が画像分類例
- キラキラ

- さっそう

- しっとり

- しっぽり

- シャキッ!

- わいわい

- ごくり

データセットの準備
目視で分類したデータを 64x64 にリサイズし、80% を Train data、20% を Test Dataとして使用
NNCのモデルの作成
下記に示す Convolutional Neural Network で Train、Test を実施

学習の精度向上
最初の Convolution の Kernel Shape を 7x7、5x5、3x3 の3通りについてテスト。それぞれの結果は以下の通りとなった。
| Kernel Shape | 7x7 | 5x5 | 3x3 |
|---|---|---|---|
| Accuracy | 0.9135 | 0.9506 | 0.9506 |
| Avg.Precision | 0.8954 | 0.9254 | 0.9410 |
| Avg.Recall | 0.9038 | 0.9422 | 0.9555 |
| Avg.F-Measures | 0.8961 | 0.9308 | 0.9467 |
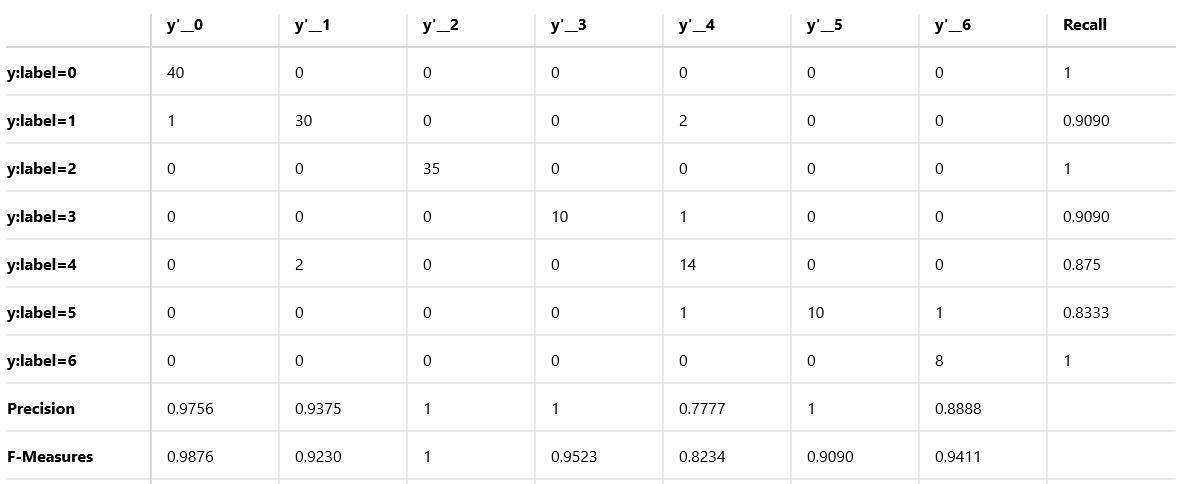
こちらが一番精度の高かった 3x3 の Confusion Matrix。
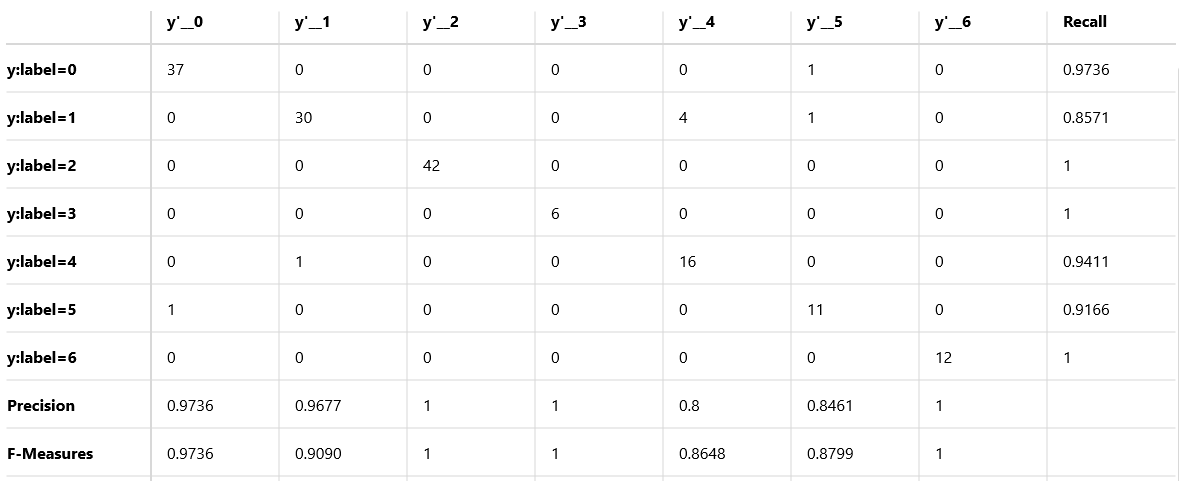
y:label=1 「さっそう」を y'=4 「シャキッ!」と誤検出しているケースがいくつかあった。「さっそう」の中に下記のようにいくつか黒色の多い画像が含まれていたのが原因と推測し、こちらを除外して再度学習させたところ以下のような結果になった。なお一部画像除外後の画像の枚数は合計771枚である。
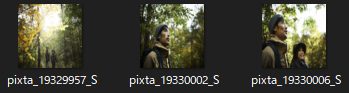
「さっそう」から除外した画像と結果
その他の画像の分類
今回作成したモデルで1万枚の全画像を分類した。今回タイトルに設定した「写真の情景を表現するオノマトペ」には適合しない画像についても分類を実施し、意図した特徴量にて画像を分類できているかを確認することができた。以下分類結果の抜粋である。
-
キラキラ(y'_0 の確率が高い画像)

-
さっそう(y'_1 の確率が高い画像)

-
しっとり(y'_2 の確率が高い画像)

-
しっぽり(y'_3 の確率が高い画像)

- シャキッ!(y'_4 の確率が高い画像)
-
わいわい(y'_5 の確率が高い画像)

-
ごくり(y'_6 の確率が高い画像)
まとめ
今回初めて NNC を使用した画像分類を実施し、
- NNC がとても使い勝手の良いツールであること
- 色合いや人数、人の有無などを高精度で識別し画像を分類可能なこと
- 目的に合った Dataset を準備することの重要性
について理解することができ有意義な検討を行うことができた。