はじめに
この記事はシスコの有志による Cisco Systems Japan Advent Calendar 2023 の 24日目として投稿しています。
2017年版: https://qiita.com/advent-calendar/2017/cisco
2018年版: https://qiita.com/advent-calendar/2018/cisco
2019年版: https://qiita.com/advent-calendar/2019/cisco
2020年版 1枚目: https://qiita.com/advent-calendar/2020/cisco
2020年版 2枚目: https://qiita.com/advent-calendar/2020/cisco2
2022年版(1,2): https://qiita.com/advent-calendar/2022/cisco
2023年版: https://qiita.com/advent-calendar/2023/cisco<---こちら
Geminiとは
Googleが提供するマルチモーダル機能を有するAIモデルです。
マルチモーダルとは画像、文字、音声、動画等の複数種類のデータを同時に扱うことができる機能です。
Geminiには3つバージョンがあります。
1、Gemini Ultra
2、Gemini Pro
3、Gemini Nano
Ultraは複雑なタスクに対応する最大モデルで、2024年初めに公開予定らしい。
proは幅広いタスクに対応する汎用モデルで12月13日より企業向けには「vertex AI」、開発者には
「AI Studio」で提供しているらしい。
nanoはモバイルでのタスクに最適化した軽量モデルで、Pixel 8 proに搭載している。
この記事ではAI studioを使って一足早くGeminiで何ができるのかを共有したいと思います。
Gemini Proを使ってみる。
では、さっそくGemini proを使うために開発者向けの
Google Cloudの「AI studeio」にアクセスしてみましょう。
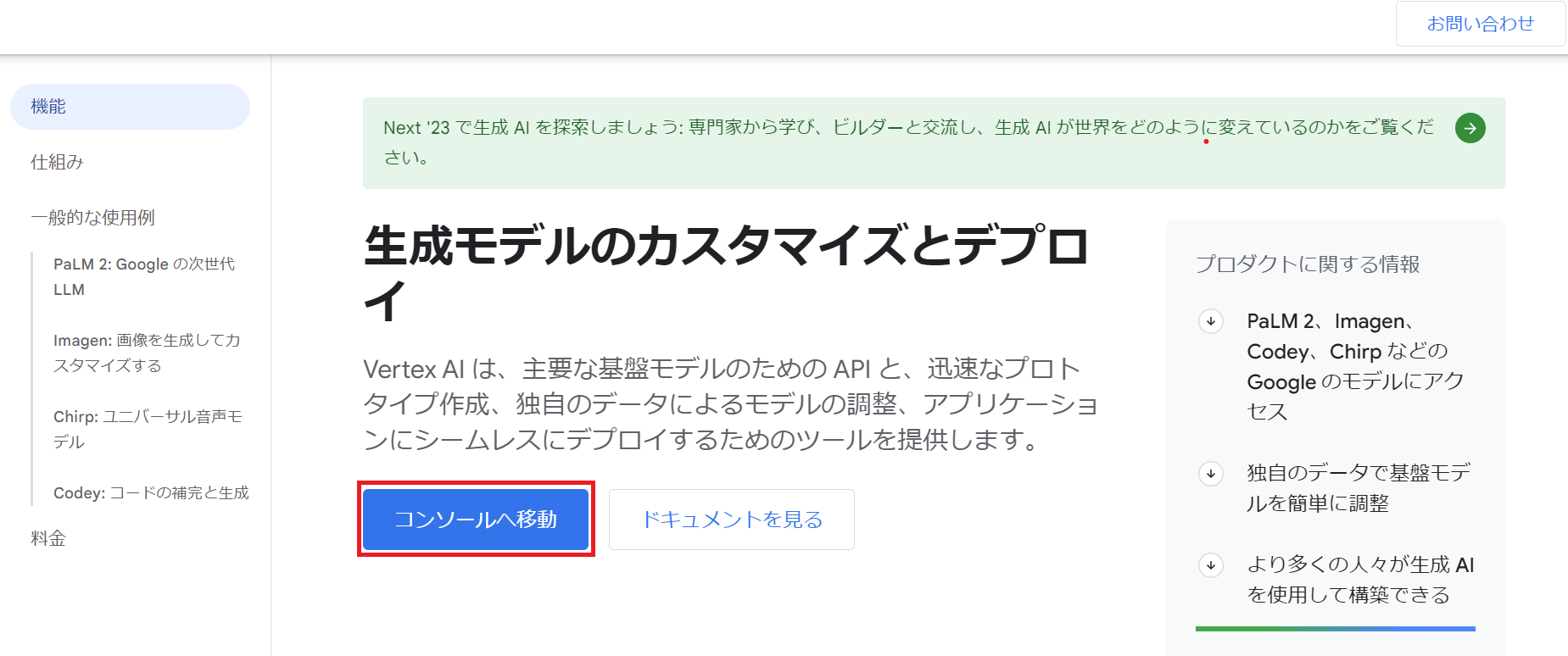
リンクをタップしたら、下画像の赤枠で囲まれた「コンソールへ移動」をタップしてください。
(Google cloud初めて使う方は「無料トライアル」をタップしてください。)
Google Cloudの無料トライアルは90日間無料でGoogle Cloudを利用できて、
その後の自動課金はないので、クレジットカードの登録を求められますが気にせず登録してください。
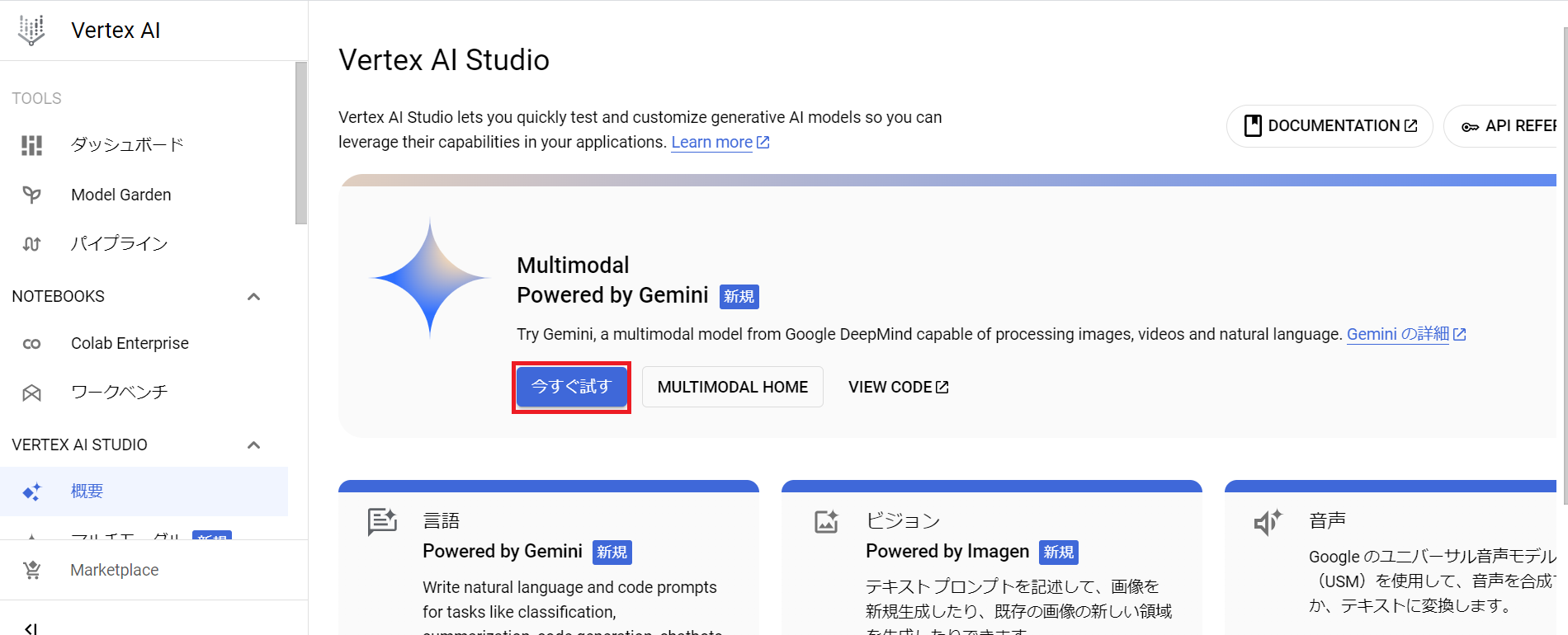
コンソールへ移動をタップすると、以下画像のように
「Multimodal Powered by Gemini」と示す画面がでてきて、
その下に「今すぐ試す」というボタンがあるので、それをクリックしてください。
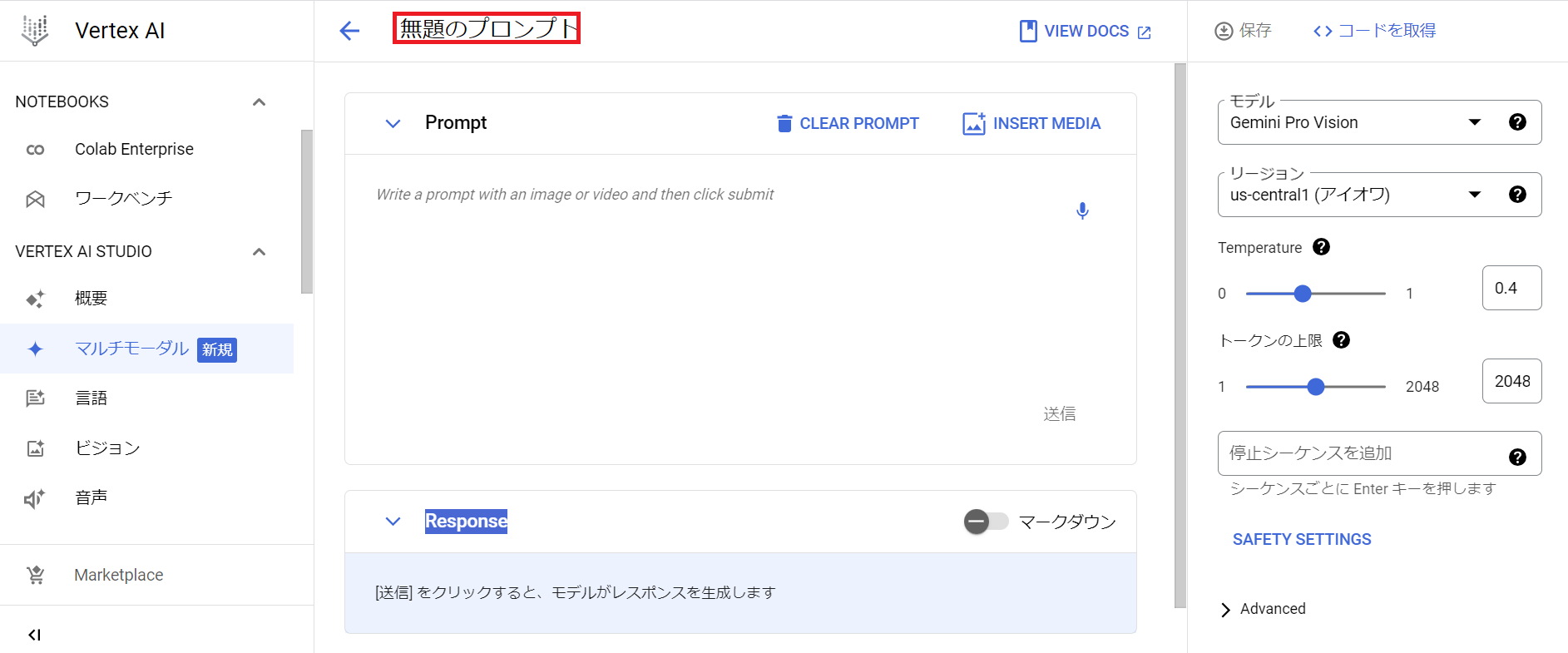
ここまでくるとプロンプト画面がでてきて、「さぁやってみてください!」みたいな感じで
やり方もわからないまま放り出されちゃうので、
下画面のところを押してみてください。(そのままプロンプトで遊ぶのも楽しいので是非やってみてください)
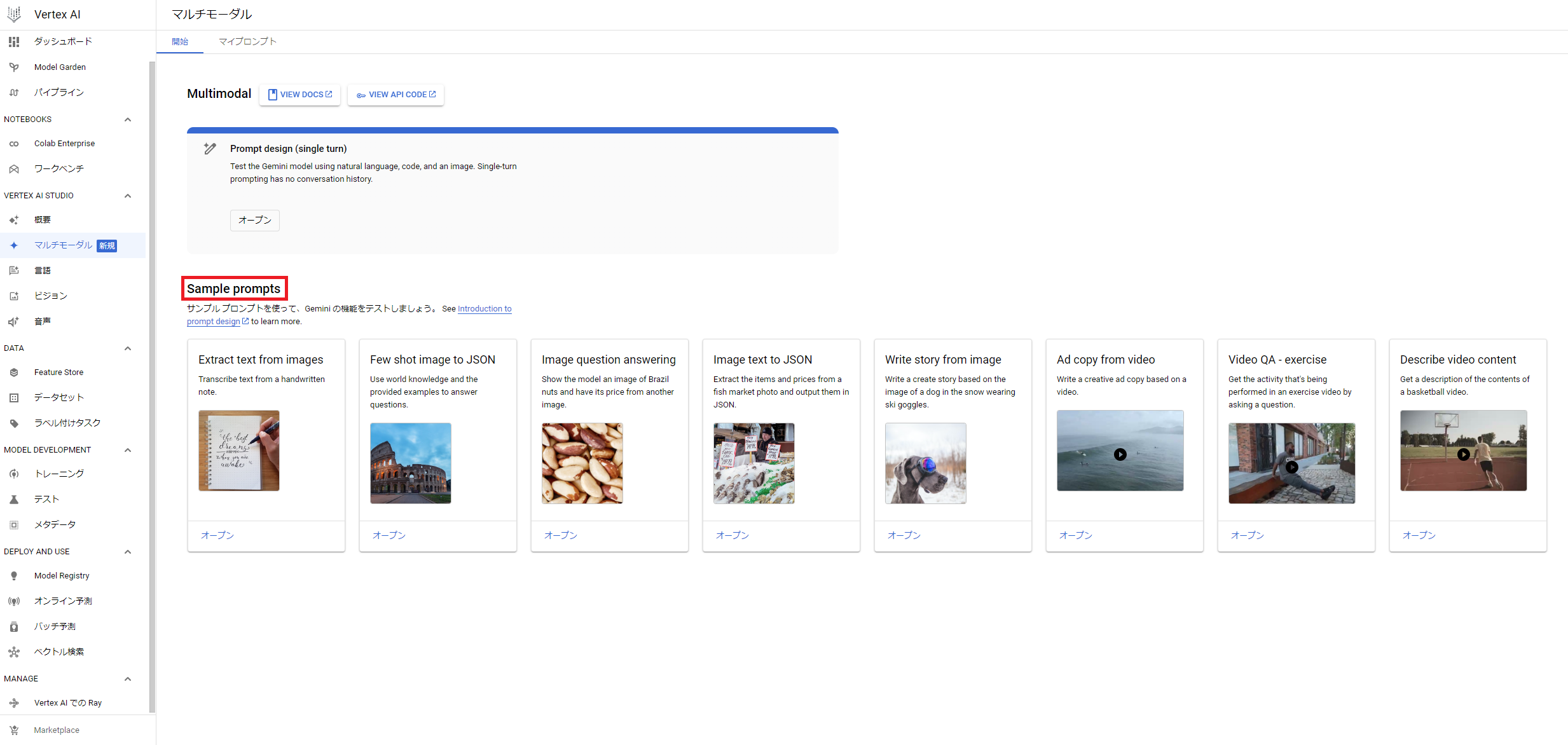
すると、下画面に移動して「Sample prompts」がでてくるので、
Gemini proで何ができるか体験してみましょう!
Extract text from imagesを体験しよう
Sample promptsにあるように、Geminiでは画像に書かれた文字を読み取ることができるらしいので、それを実際に試してみましょう。
最初にある画像は「Extract text from images」のデモ画像で
「The best dreams happen when you are awake」と書いてあって、
Geminiが「Response」としてきちんと読み取れていることが示されています。
デモだけだとつまらないので、実際に手書きのメモを画像として読み込ませて
画像に書いてある通りに読み込んでくれるか見てみましょう。
デモとして、私が書いたメモを読み込ませてみます。
メモは以下の画像に示す内容になってます。
字汚いけど、Geminiの性能を試すには良いですね。

内容は
「Hi, I'm writing a memo to find how gemini performs.
It's wonderful if gemini exactly read my memo from a picture.
You might think if I;m writing a memo that is easy to read for gemini.
But, No. I want to show how great gemini is by writing as I do normally.」
これを以下画像のように、①「INSERT MEDIA」、②「行ってほしい命令を書く」、③「送信(Submit)」の順で行ってみましょう。
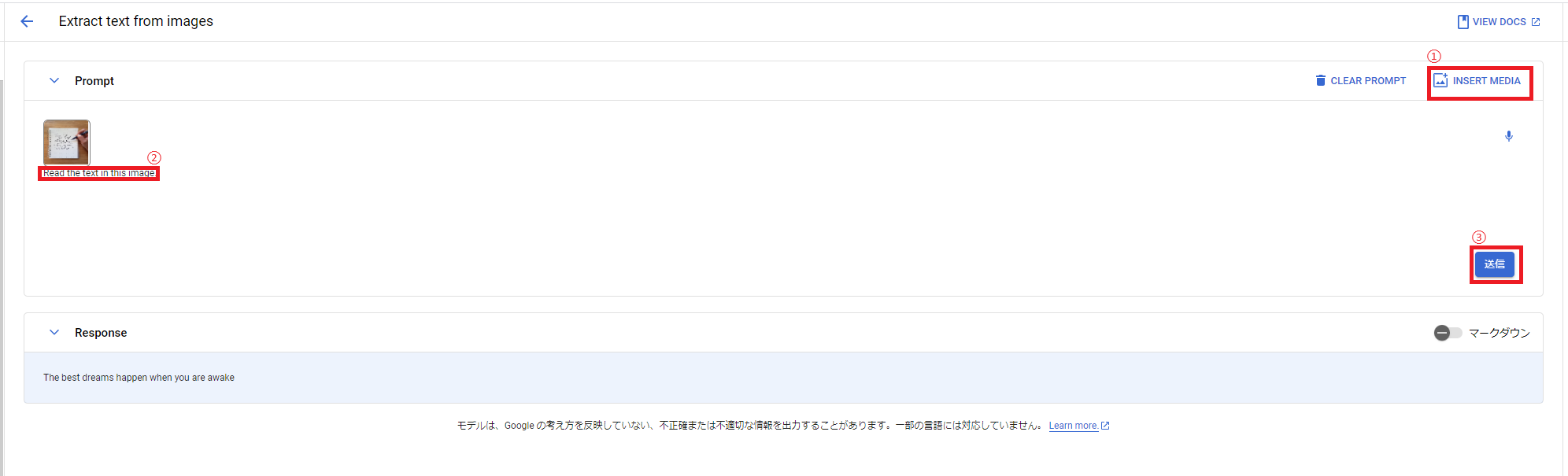
結果が以下のようになってます。
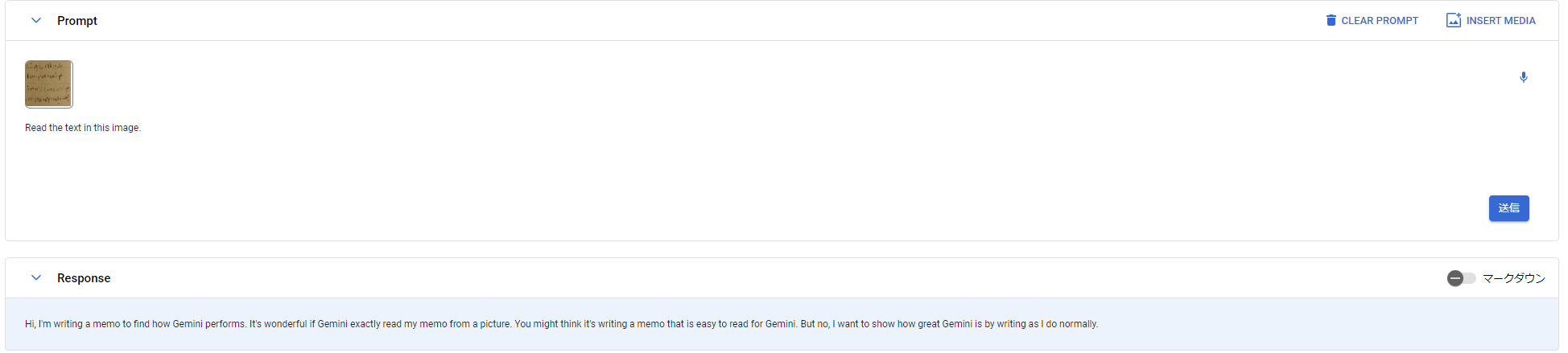
ちょっと見にくいので、タイピングしてみると、
「Hi, I'm writing a memo to find how Gemini performs. It's wonderful if Gemini exactly read my memo from a picture. You might think it's writing a memo that is easy to read for Gemini. But no, I want to show how great Gemini is by writing as I do normally.」
って書いてありますね。
私が書いたメモと比べてみると、「You might think I'm writing」の部分が
「Your might think it's writing」となっており、その部分だけ違いますが、
それ以外は合っており、精度の高さが伺えますね。
消した後とか残っていても読み取れてますし、個人の書き癖とかも精度高く読み取れてます。
私の字がもっと綺麗だったら完璧に読み取れていたでしょうが、それでも非常に精度高く読み取れています。
Few shot image to JSONを体験してみよう
この機能は複数枚の画像とその下にJson形式で説明を加えたのちに、
質問をしたい画像のみを貼り付けることでjson形式でその画像の説明を返してくれる機能です。
デモとしては、ローマのコロッセオと、北京の紫禁城が
それぞれの写真の下にJSON形式でそれぞれ
{"city":"Rome",
"Landmark":"Colosseum"}
{"city":"Beijing",
"Landmark":"Forbidden City"}
と書かれています。
そして、三枚目の写真はJSON形式の答えは書かれておらず、
写真のみが貼り付けられています。
そこで、「送信」を押してみると、
{"city":"Rio de janeiro",
"Landmark":"Christ the redeermer"}
とレスポンスが返ってきました。
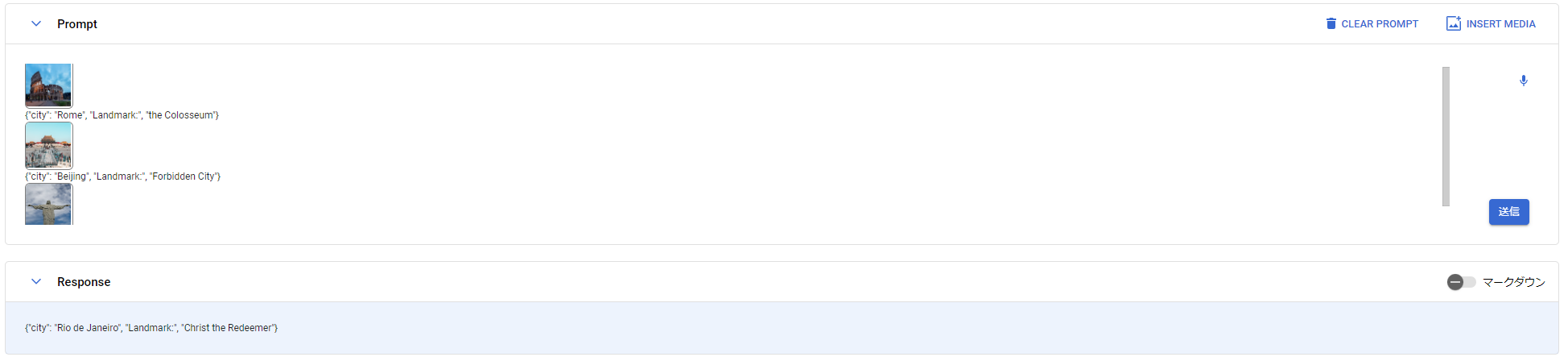
じゃあ、次は日光の東照宮の写真を載せてどのように説明が返ってくるかを見てましょう。
また、JSONに少々変更を加えて、いつ建てられたのかも見てみましょう。
変更後はローマのコロッセオと、北京の紫禁城が
それぞれの写真の下にJSON形式でそれぞれ
{"city":"Rome",
"Landmark":"Colosseum"}
"build": "80AD"
{"city":"Beijing",
"Landmark":"Forbidden City"
"build": "1420"}
としました。
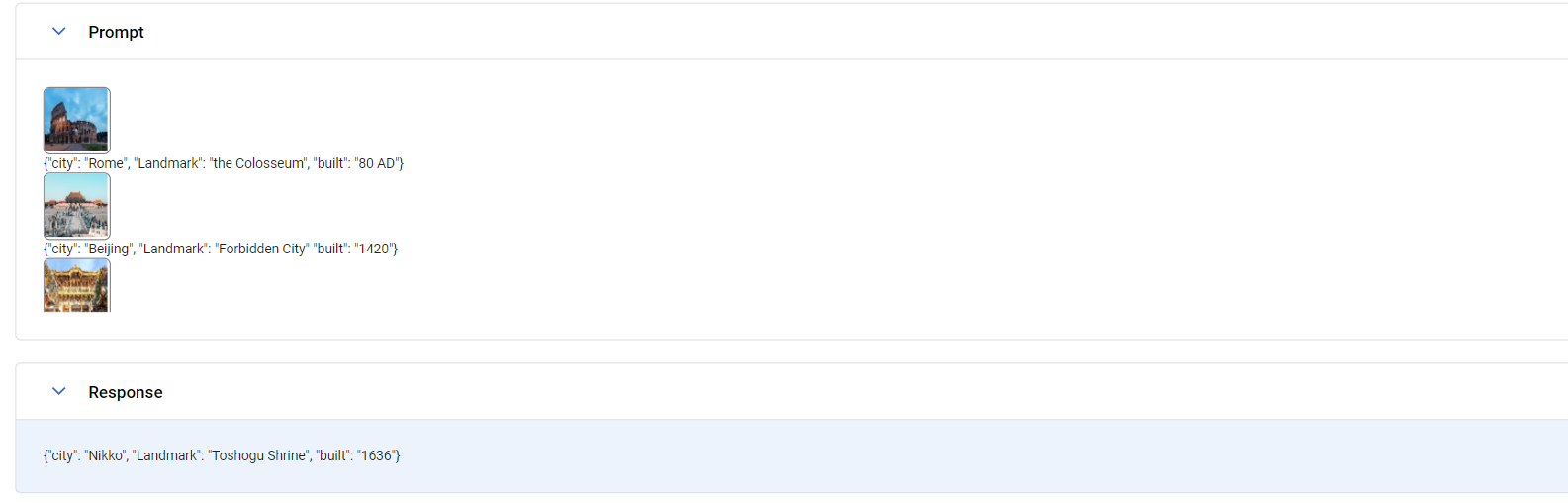
結果が上のようになりました。
日光東照宮の写真を載せた結果、
{"city": "Nikko",
"Landmark": "Toshogu Shrine",
"built": "1636"}
と結果が返ってきました。
東照宮は1617年に創建されましたが、主要な社殿は1636年に造営が行われたので、
結果として間違ってはいないのかなと思います。
欲しい結果がキチンと返ってきましたね
Image question answeringを体験してみよう
「Image question answering」は読み込ませた画像から、プロンプトに入力された命令に従って処理を行う機能です。
デモに添付された画像はそれぞれブラジルナッツと、各ナッツの値段が書かれた写真です。
各ナッツの値段が書かれた写真からGeminiが値段を抽出し、ブラジルナッツの画像が示されたらその値段を出力する動きをしています。
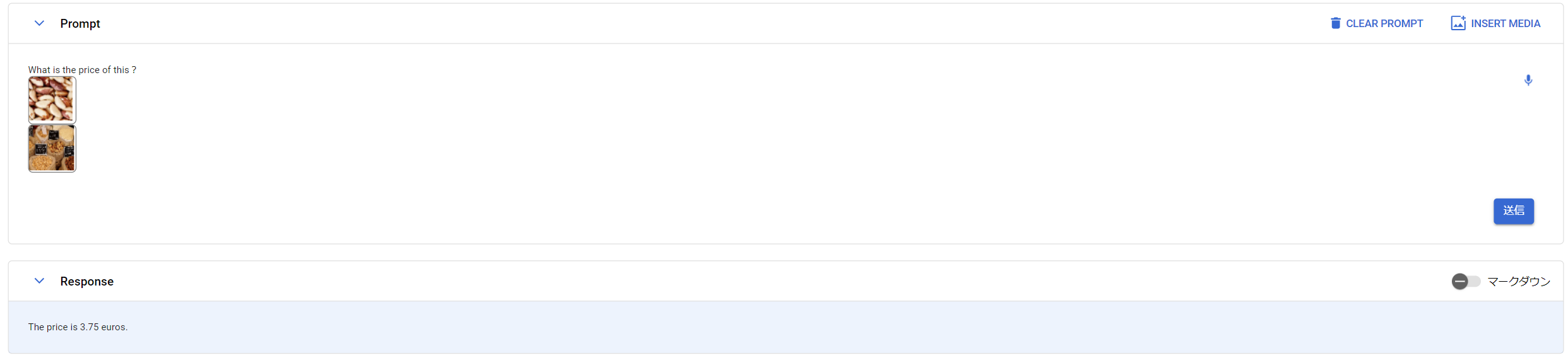
下の画像が様々なナッツの値段を示しており、
ブラジルナッツの値段が250gで3.75ユーロと記載してあります。
様々なナッツの値段が書かれている画像とブラジルナッツの画像、
「What is the price of this?」と質問することで
キチンと「The price if 3.75 euros」と出力されていますね
それでは、ちょっと質問を変えてみましょう。
先ほどはブラジルナッツの写真に加えて「What is the price of this?」と質問するだけでしたが、今度は「What is the price of this if I buy 750 grams of this?」としてみましょう。
ブラジルナッツは250gで3.75ユーロでしたので、750gなら11.25ユーロになるはずですが、結果はどうなるでしょうか?
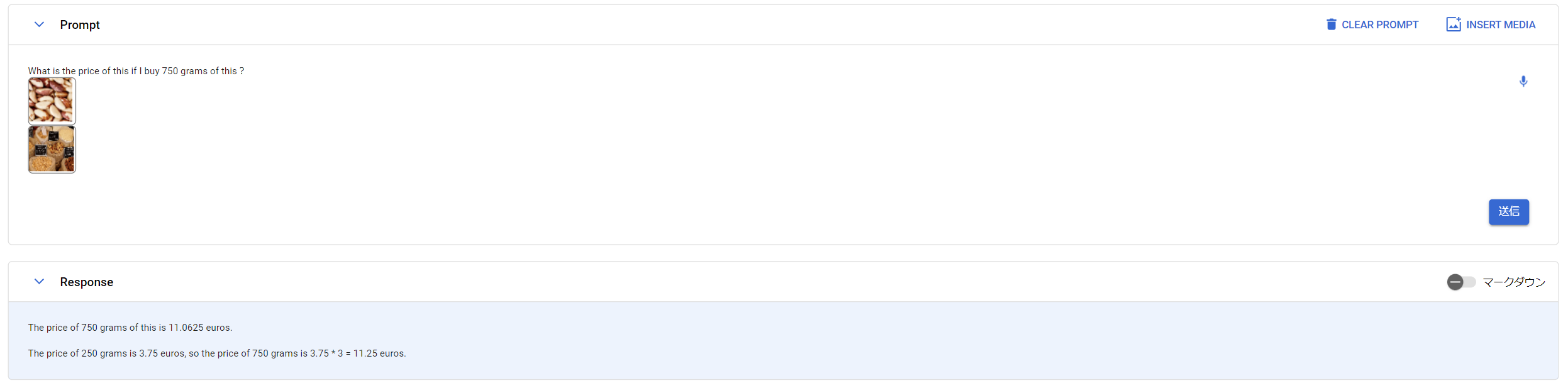
Geminiの回答は
「The price of 750 grams of this is 11.0625 euros.
The price of 250 grams is 3.75 euros, so the price of 750 grams
is 3.75 * 3 = 11.25 euros.」
でした。
2つ回答がでてきて、計算式を書いている方はあってますね。
私の指示が悪かったからかもしれませんが、間違った回答も出ています。
けれど、計算式と一緒に回答するなんてすごいですよね
Image text to JSONを体験してみよう
「Image text to JSON」は読み込ませた画像から情報を抽出して
JSON形式のデータに変換する機能です。
デモに添付された画像は以下の画像です。

この画像をアップロードして
「Extract the items and prices from a fish market photo and output them in JSON.」とGeminiに命令した結果がこちらです。
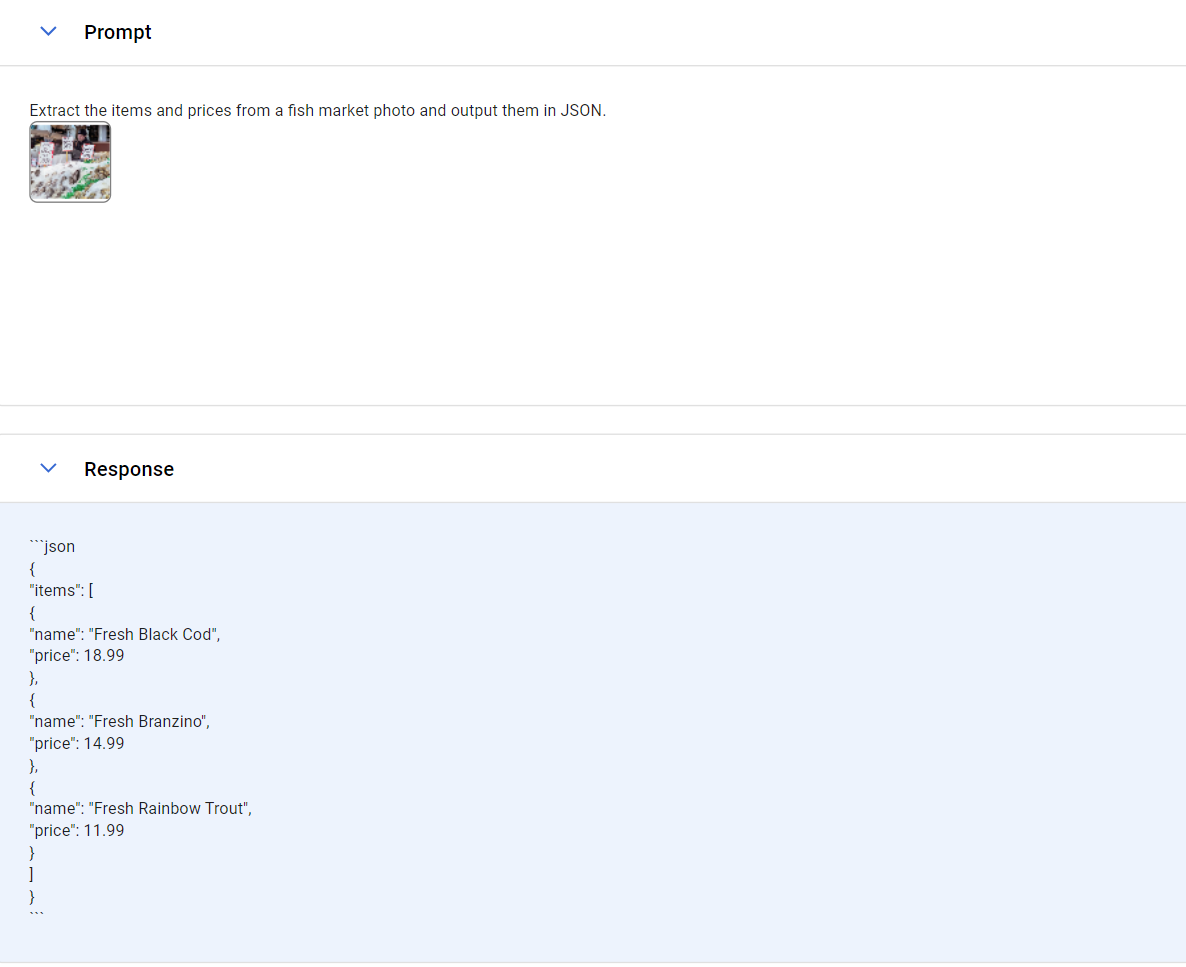
このように、写真の中のそれぞれの商品の名前と値段を画像からGEMINIが抽出してそれをJSONとして出力していることが見て取れます。
これは結構便利な機能ではないでしょうか。
デモではあまりJSONとして抽出するデータの数が多くないですが、
情報量の多い写真からJSON形式でデータを抽出するにはとっても使いやすいですね!
Write story from imageを体験してみよう
「Write story from image」では読み取った画像からストーリーを作成する機能です。
デモ画像では以下のようなゴーグルを被った犬の画像を用いて
「Write a creative story inspired by this image」
と命令していますが、結果をわかりやすくするために日本語で結果を返すようにしてみましょう。

その結果がこちらとなります。
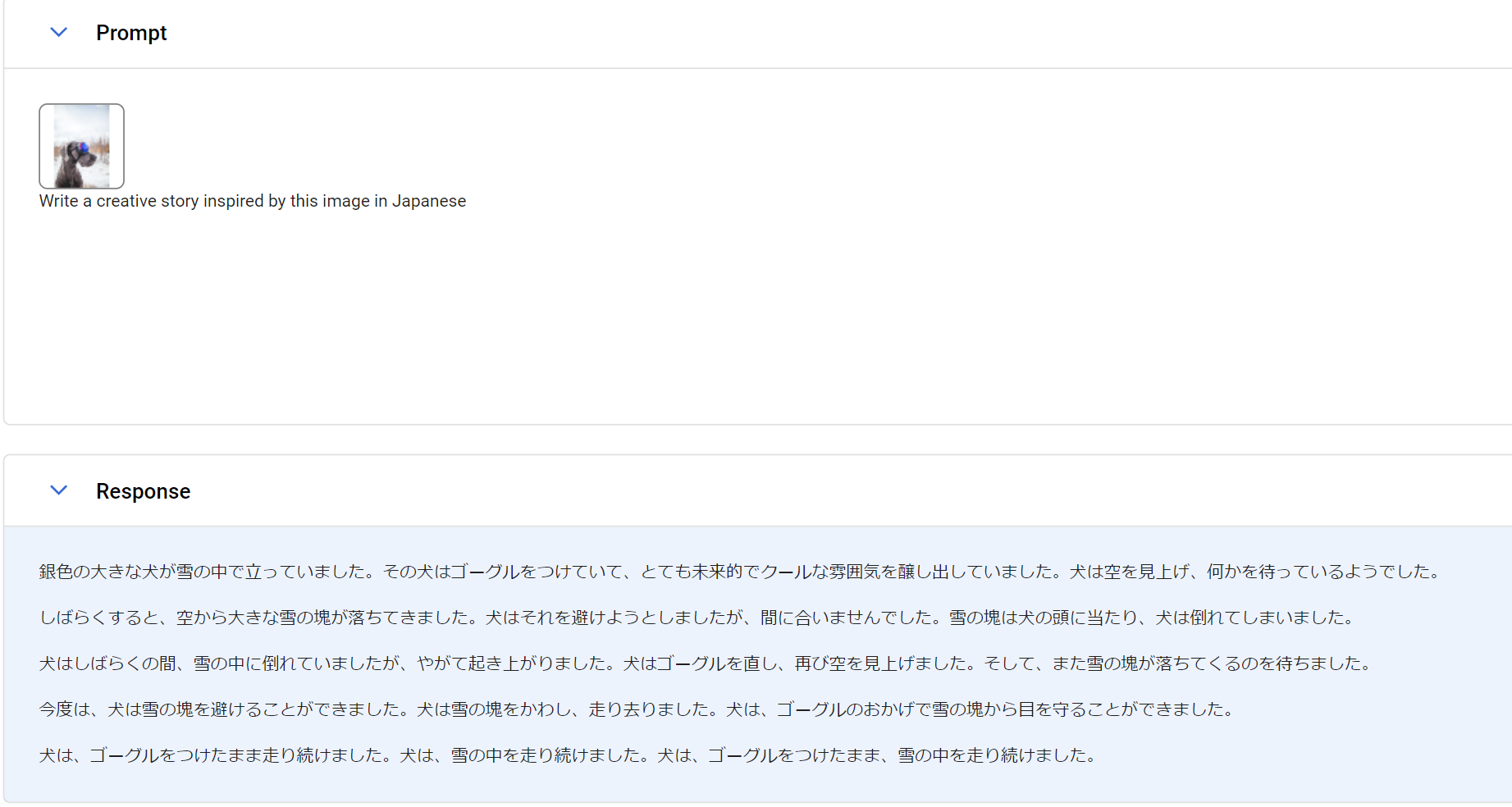
どうでしょう?
思った以上に文章の体裁が整っていて文章に明確な誤り等はなさそうですよね
文章の面白さは置いといて、思った以上にきちんと文章が返ってきます。
デモの内容だけでは少々面白みに欠けるので、
私が以前一緒に住んでいた猫の画像を使ってみましょう。
結構面白いストーリーじゃないですかね。
同じ画像と同じ命令文で何回か試してみましたが、どの場合も同じストーリーを出力する結果となりました。
出力ごとに毎回違うストーリーを出してくれた面白いですが、そこはこれからでしょうかね
終わりに
デモは
「Ad copy from video」
⇒動画から広告用の文章を作成してくれる
「Video QA - exercise」
⇒動画の内容について質問すると返答してくれる
「Describe video content」
⇒動画の概要を文章で示してくれる
この3つがまだ残っていますが、動画形式なのでここで説明するには少々
難しいので、読んでくださっているあなた自身で実際に体験してみてください。
テクノロジーの発展に幸あれ!!
免責事項
本サイトおよび対応するコメントにおいて表明される意見は、投稿者本人の個人的意見であり、シスコの意見ではありません。本サイトの内容は、情報の提供のみを目的として掲載されており、シスコや他の関係者による推奨や表明を目的としたものではありません。各利用者は、本Webサイトへの掲載により、投稿、リンクその他の方法でアップロードした全ての情報の内容に対して全責任を負い、本Web サイトの利用に関するあらゆる責任からシスコを免責することに同意したものとします