1.はじめに
この記事はNTTテクノクロス Advent Calendar 2019の4日目の記事です。
はじめまして、NTTテクノクロスの稲塚と申します。
普段は、デジタル目勘®のチームに所属しており、ディープラーニング関連の業務に携わっています。
また、ソフト道場の講師として、ディープラーニングの入門を社内で教えたりしています。
2.本記事の目標
ディープラーニングを使った物体検出手法の代表例であるFaster R-CNNをChainerCVで動かし、その処理を理解することを目標としています。
3.物体検出(Object Detection)とは
1つの画像から、「何が」「どこに」「どんな大きさ」で写っているかを判定することです。
- ディープラーニングの基本タスクである画像分類(Classification)は「何が」写っているかのみ判定します。
- より発展的なタスクで物体の輪郭を推測する、セグメンテーション(Semantic Segmentation, Instance Segmentation)もあります。
図3-1 画像分類・物体検出・セグメンテーションの比較
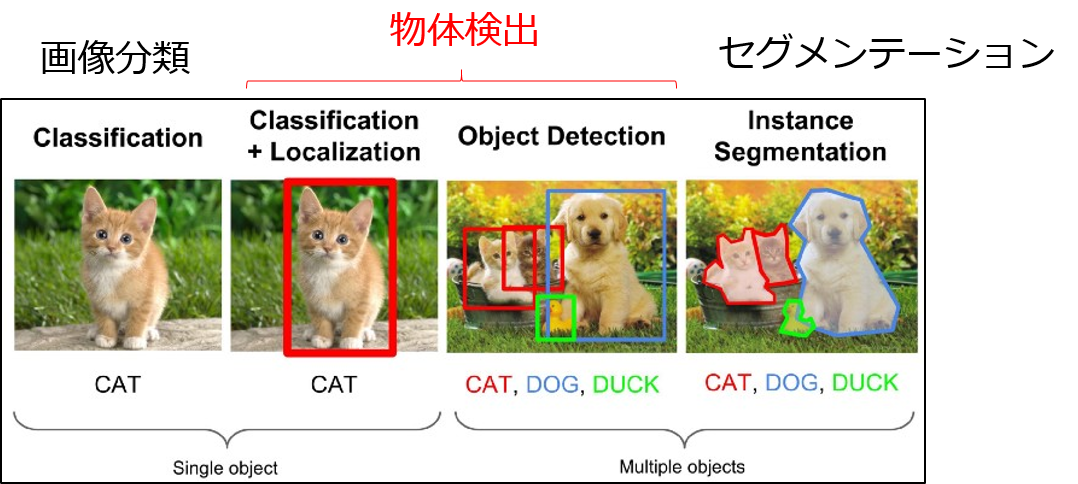
(※)画像引用元
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
4.Faster R-CNNとは
物体検出を行う手法(あるいはディープラーニングのモデル)の1つで、最も広く長く使われている手法です。
- 広く使われていると言っているのは、例えば下記の各ライブラリ等の多くのサイトで学習済みモデルが公開されていることを記載根拠としています。
- 他に長く使われている手法として、「YOLO」(後継のv2,v3含む)や「SSD」があります。
- 一方で図2のように毎年のように新しい手法が出続けています。
- それぞれの処理ロジックを追いかけるのは難しいですが、メジャーどころである「Faster R-CNN」「YOLO」「SSD」あたりを押さえておけば、世に出ている物体検出サービスのコアな処理ロジックが分かると言えます。
図4-1 ディープラーニングを使った物体検出手法の主な研究

(※)画像引用元
https://github.com/hoya012/deep_learning_object_detection#paper-list-from-2014-to-now2019
5.なぜFaster R-CNNが長く使われる?
上述の通り、物体検出手法には多くの手法がありますが、なぜFaster R-CNNが廃れずに使われるのでしょうか。
個人的な推測ですが、Q&A形式で記述していきます。
【Q1】より高精度・高速な手法が望まれる世界で Faster R-CNNより高精度・高速な手法は出ているのに、なぜそれらより使われるか?
【A1】多くの物体検出ライブラリ(ChainerCVなど)やその他github上の実装で「学習・推論用プログラム」や「学習済みモデル」が公開されている。
- そのため使い方・設定のチューニング方法が分かっていればすぐに使うことができる。
- これは、「YOLO」「SSD」にも言える。
- 「多くの人が使う」⇔「プログラムやモデルが改善され公開される」の好循環が起こり、後発の手法が追いつけない。
- 多くのユーザにとって、多少高精度・高速であることは重要でない。
【Q2】 Faster R-CNNより前の手法は、なぜあまり使われないのか?
【A2】当時としても推論速度が遅かったことと、改善の余地が少ない。
- Faster R-CNNの前身「R-CNN」「Fast R-CNN」は物体候補の検出に「Selective Search」という非機械学習の手法を使っており、精度・速度両面でネックとなっていた。
- また、ここについてはほぼ改善の余地が無い。
- Faster R-CNNは、初めから終わりまでディープラーニングを使っている。(end-to-end learning)
- end-to-end learning ができれば、精度・速度両面で改善を続けることができる。
- 環境の進歩
- 高性能なGPUの出現や、データセットの整備など
- ベースモデルの改善
- もともとFaster RCNNはVGG16をベースとしていたが、後発のClassificationモデルに置き換えることもできる。
- 環境の進歩
- end-to-end learning ができれば、精度・速度両面で改善を続けることができる。
6.ChainerCVを使ってFaster R-CNNで推論するまで
6-1 ChainerCVの特徴
物体検出ライブラリとしては、ChainerCVのほかにもTensorFlow Object Detection APIやDetectronなどがありますが、ChainerCVには下記の長所があると考えます。
- インストールが易しく、使えるようになるまでが早い。
- 最短では
pip install chainercvのみでインストール可能
- 最短では
- ほぼpythonで書かれており、print文やpdbによるデバッグによる、途中のロジックの把握がしやすい。
- 分かりやすいモジュール構成。
- chainercv/links/model/faster_rcnn/ 配下に、Faster R-CNNのロジックの確認に関係するコードが、ほぼまとまっている。
6-2 動作環境
本記事で使用するOSや主なライブラリのバージョンは以下の通りです。ChainerとChainerCVは2019/11/29現在の最新版を使用します。
- OS: Windows7 64bit
- Anaconda 4.4.10
- Python 3.6.4
- Chainer 6.5.0
- ChainerCV 0.13.1
6-3 推論方法
手早くChainerCVを使った推論を実施するには下記2通りの方法があります。
- ChainerCVのgitリポジトリにあるサンプルプログラムを実行する方法
- 公式ドキュメントのobject-detection-tutorialのページを参考に実装。本記事ではこちらを実施します。
- リンク先にSSDを使った実装例があるので、Faster R-CNNを使うように変更すると下記のプログラムになります。
# In the rest of the tutorial, we assume that the `plt`
# is imported before every code snippet.
import matplotlib.pyplot as plt
from chainercv.datasets import voc_bbox_label_names
from chainercv.links import FasterRCNNVGG16
from chainercv.utils import read_image
from chainercv.visualizations import vis_bbox
# Read an RGB image and return it in CHW format.
img = read_image('sample.jpg')
model = FasterRCNNVGG16(pretrained_model='voc0712')
bboxes, labels, scores = model.predict([img])
vis_bbox(img, bboxes[0], labels[0], scores[0],
label_names=voc_bbox_label_names)
plt.show()
10行ほどで書けてとてもスマートです。これだけのプログラムで物体検出ができるとは便利な世の中になったものです。
- 推論対象画像
-
こちらの人・車・犬・馬が映っている画像を
sample.jpgという名前で保存しておきます。
-
こちらの人・車・犬・馬が映っている画像を
図6-1 推論対象画像

-
推論実行
-
inference.pyとsample.jpgを同じ場所に置き、下記を実行します。
>python inference.py- 初回実行時は、学習済みモデルが自動でダウンロードされ、
C:\Users\<ユーザ名>\.chainer\dataset\pfnet\chainercv\models\faster_rcnn_vgg16_voc0712_trained_2017_07_21.npzに保存されます。- 名前から、VGG16をベースのモデルに使っており、PascalVOCデータセット(2007+2012)を学習データとしていることが読み取れます。
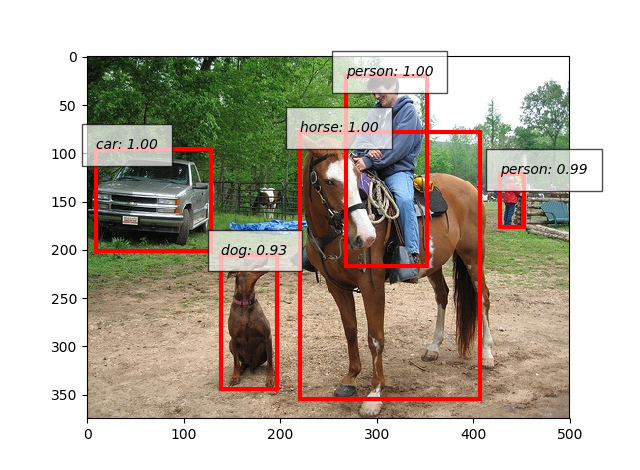
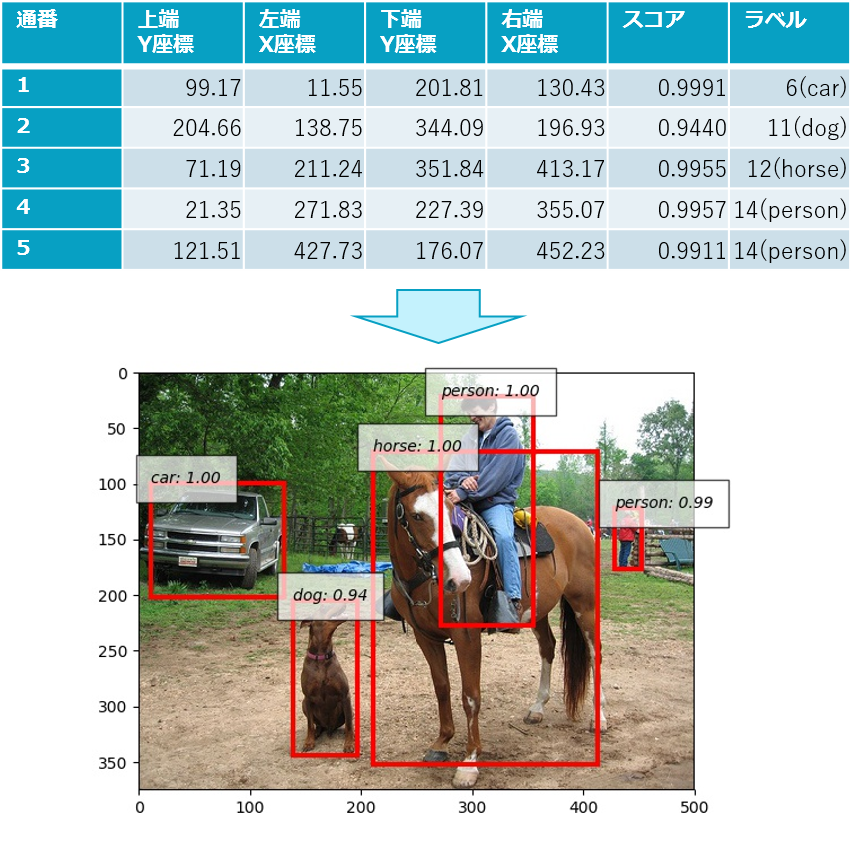
- 出力として下図の画像が得られました。人・車・犬・馬を正しく推論できています!
-
図6-2 推論結果画像
7. Faster R-CNNによる推論の内部処理
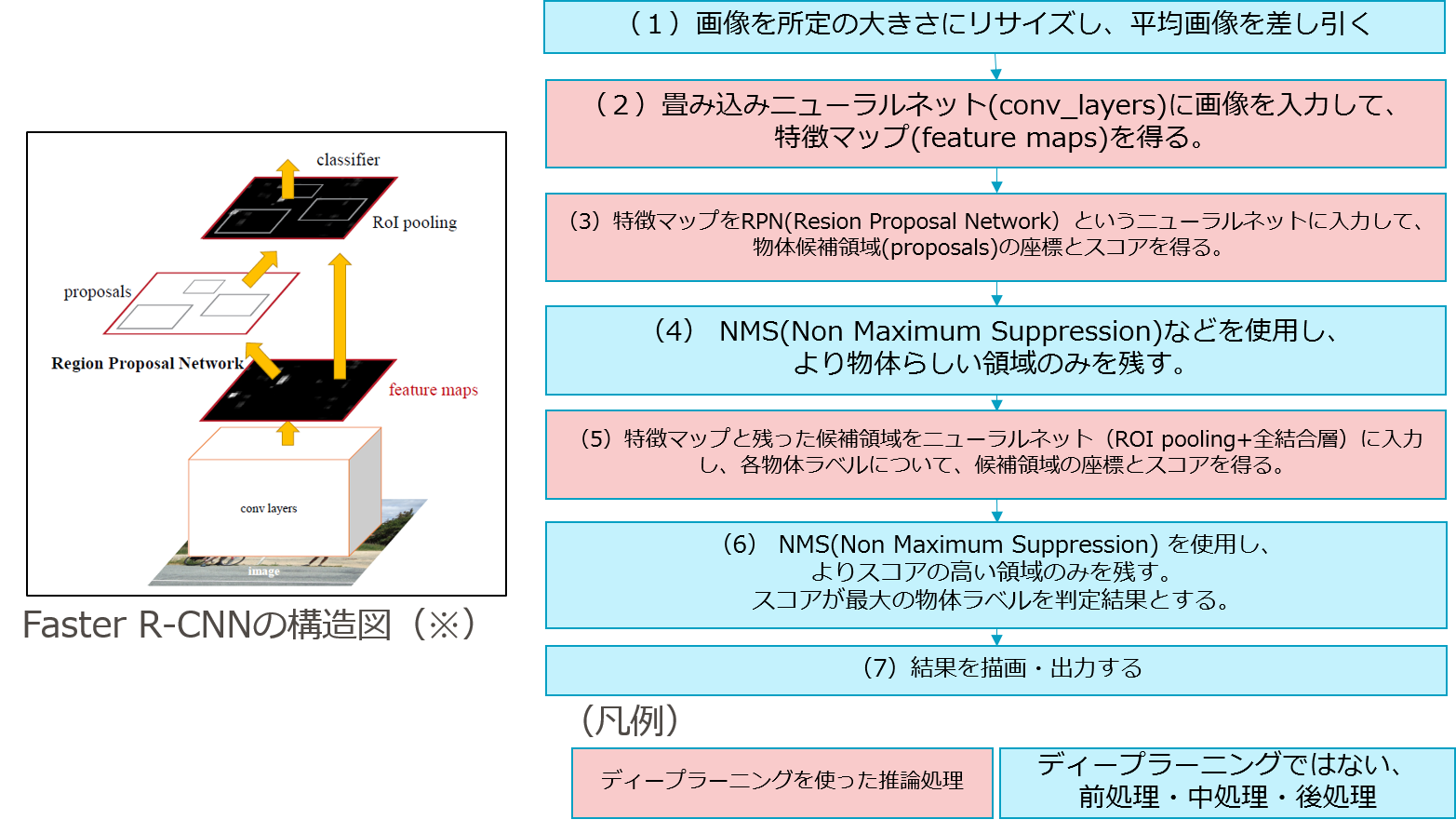
7-1 全体の流れ
学習済みモデルおよび図6-1の画像を読み込んでから、図6-2の出力画像が得られるまで何が行われているのでしょうか。
物体を四角(bounding box)で囲んで、物体が何かを判定するまでに、どんな処理が動いているのかを明らかにしたいと思います。
デバッグしながら処理を追った結果以下の流れで推論されていることが分かりました。
図7-1 Faster R-CNNの推論処理の流れ
(※)画像引用元
Faster R-CNN論文
- ディープラーニングの処理は、大きく3つの段階(2)特徴抽出・(3)物体候補領域抽出・(5)物体ラベル判定に分かれています。
- ディープラーニングではない緻密な前処理・中処理・後処理が合間に挟まれている点も驚きです。
7-2 個々の流れ
7-1 で示した7段階の処理を個別に見ていきましょう。
(※)処理中のコードや変数の中身をpdbを使って確認しています。8節参照
(1)画像を所定の大きさにリサイズし、平均画像を差し引く
- 画像の短辺の長さが600pixelになるようにリサイズする。
(※)以降、上記のようにpdbを使って該当コードの場所と使用している変数の中身を表示していきます。
図7-2 入力画像のリサイズ

- 平均画像を差し引く
- RGB値が、[122, 115, 102]の画像を差し引く。
- 差し引き後は平均がほぼ0となる。
図7-3 平均画像の引き算

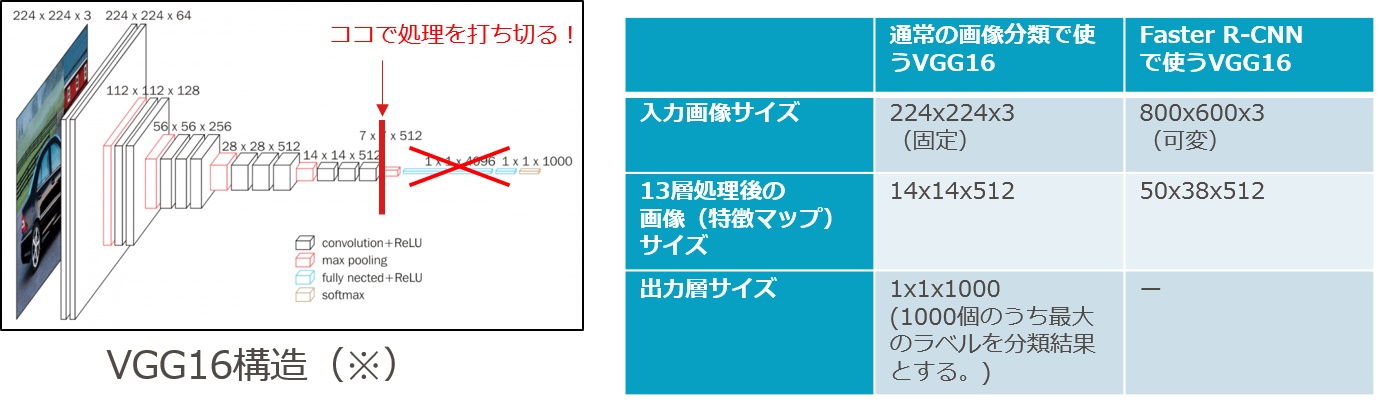
(2)畳み込みニューラルネット(conv_layers)に画像を入力して、特徴マップ(feature maps)を得る。
- 畳み込みニューラルネット(VGG16)に掛けて、[50(横)×38(縦)×512(チャンネル数)]のサイズの3次元特徴マップに変換する。
図7-4 VGG16モデルによる特徴マップへの変換
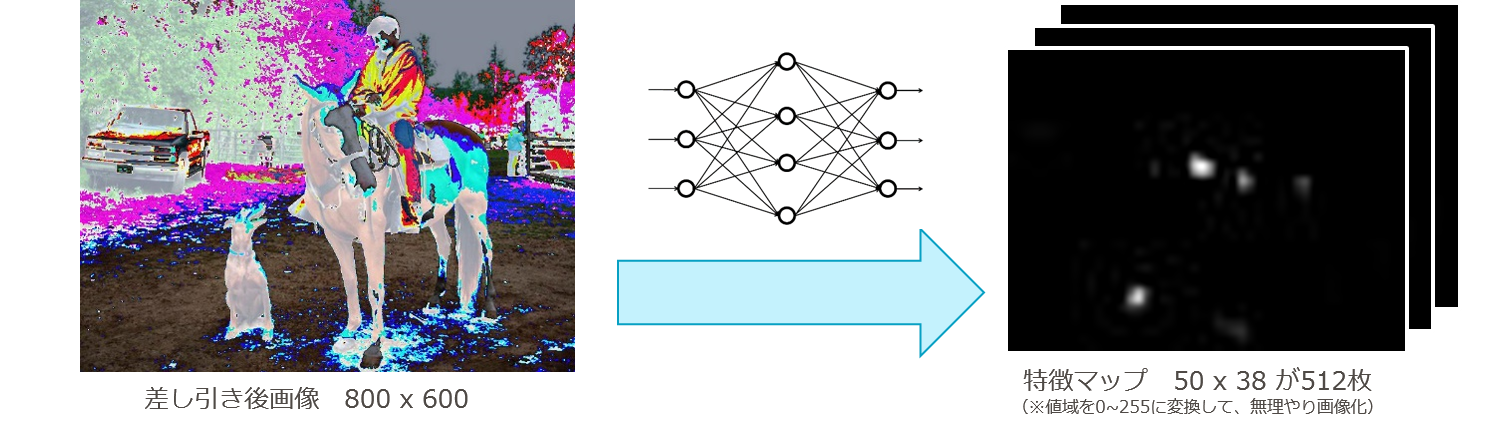
(※)図右の特徴マップ1枚目では、馬の頭や犬の胴体つまり茶色い筒状の形が抽出されていることが分かります。
- 通常の画像分類用のVGG16との違い
- 全結合層+ソフトマックス関数を使った分類までは行わない。
- 16層のニューラルネットの13層目までで順伝播処理を打ち止める。
- 13層順伝播処理後、縦横が元の1/16となること・チャネル数が512になることは同じ。
- 入力画像のサイズは固定ではなく、縦横サイズが異なっても構わない。
図7-5 Faster R-CNNで使うVGG16
(※)画像引用元
https://neurohive.io/en/popular-networks/vgg16/
(3)特徴マップをRPN(Resion Proposal Network)というニューラルネットに入力して、物体候補領域(proposals)の座標とスコアを得る。
- [50 × 38 × 512]の特徴マップをRPN(Resion Proposal Network)というニューラルネットに掛ける。
- [17100 × (4+1)]個の座標4(※)とスコア1の配列を出力する。
- (※)上下左右端のxy座標、正確にはAnchor Boxという仮決めの座標からの補正値、
- ここでのスコアは、「物体らしさ」
- 高ければ当該の領域「物体らしきものがある」、低ければ「物体らしきものがない」
- RPN自体は畳み込み層3層のニューラルネット
- 1層目の畳み込み層の後、座標出力用畳み込み層とスコア出力用の畳み込み層に分岐する。
- [17100 × (4+1)]個の座標4(※)とスコア1の配列を出力する。
図7-6 物体候補17100個の抽出
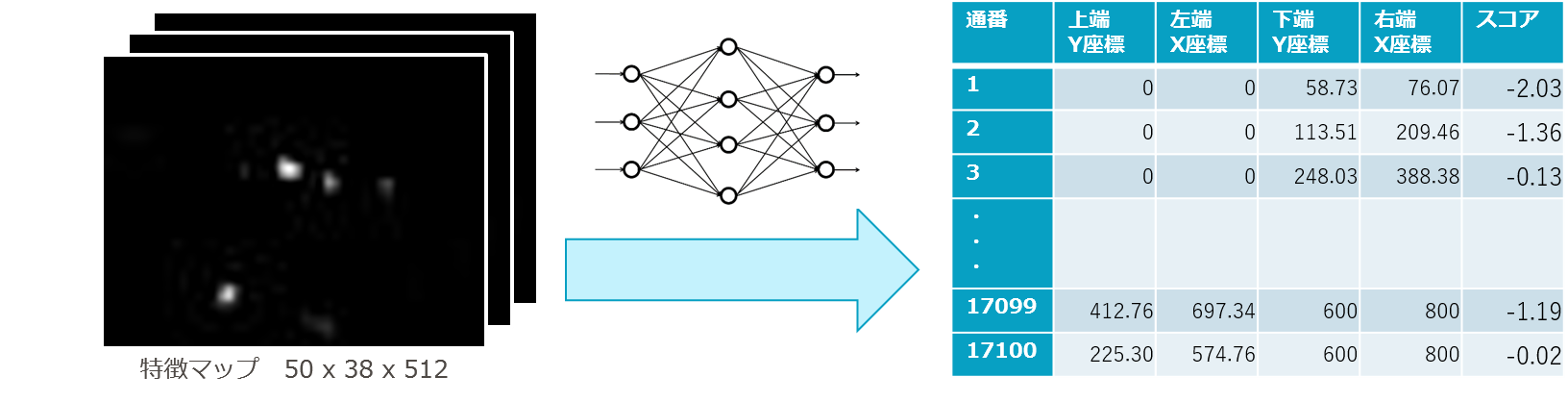
図7-7 仮候補Anchor Box 17100個

- 800x600の画像の場合、AnchorBox は1900通り(横50通り×縦38通り)の中心を持つ。※図中のオレンジおよび紫の点
- 1つあたりの中心点(図ではオレンジの点)は、9通りのAnchor Boxを持つ。面積3通り{ $128^2, 256^2,512^2$}×縦横のアスペクト比3通り{1:2, 1:1, 2:1}で9通り。※図中の青、黄緑、黄色の四角
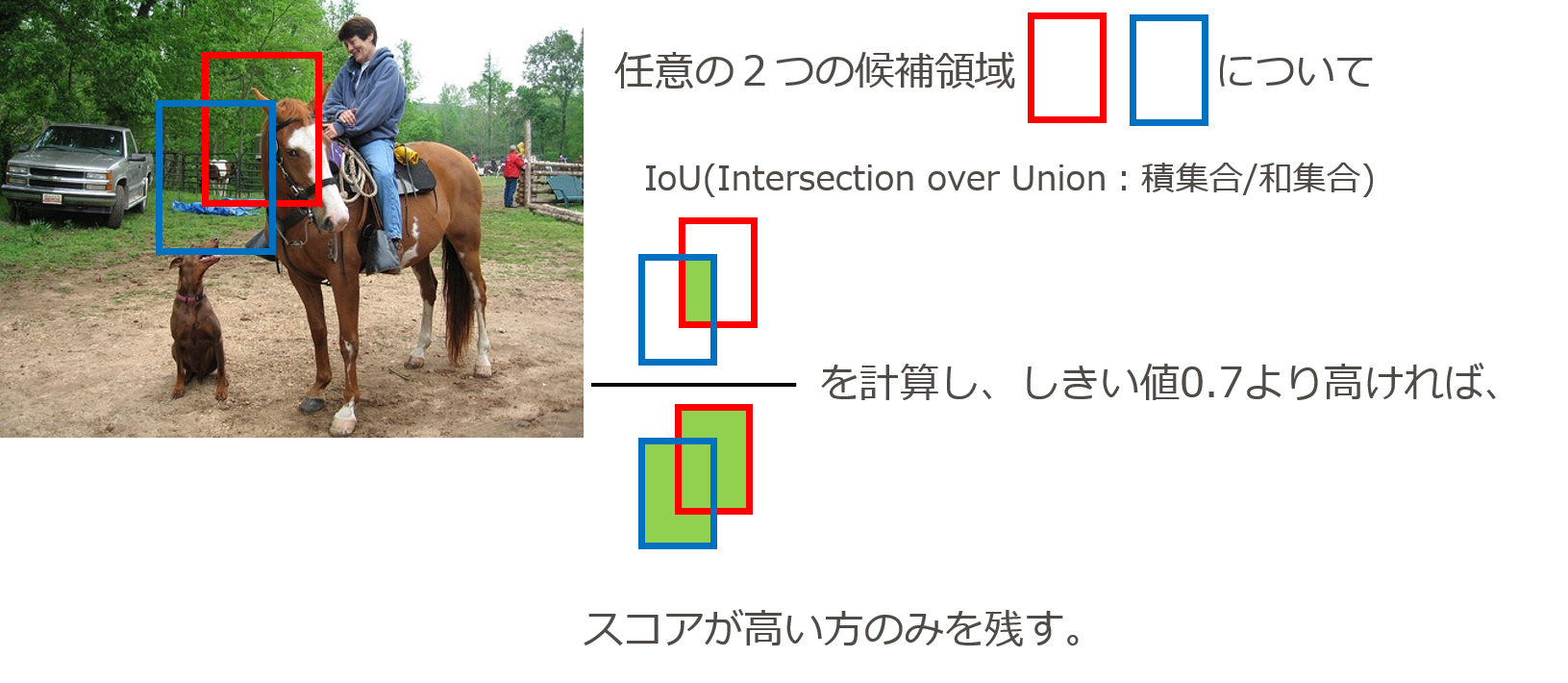
(4) NMS(Non Maximum Suppression)などを使用し、より物体らしい領域のみを残す。
(4-1)min_size = 縦横のサイズがともに25.6以上のbounding box のみを残す。
今回は該当はなく、17100->17100のまま。
(4-2)スコアが高いbounding box を残す。
ここでのスコア=物体らしさ(物体が何かは問わない)
17100->6000まで絞る。
(4-3)複数のbounding box が重なっている場合、重なり度合い(IoU)が0.7以上であれば、スコアが高い方のみ残す。
- この処理をNMS(Non Maximum Suppression)といい、つまりスコアが最高でない領域候補を抑圧するということ。
- 候補が6000->457まで絞られる。
図7-8 NMSの概要
(4-4)再度、スコアが高いbounding box を残す。
- 457 -> 300まで絞る。
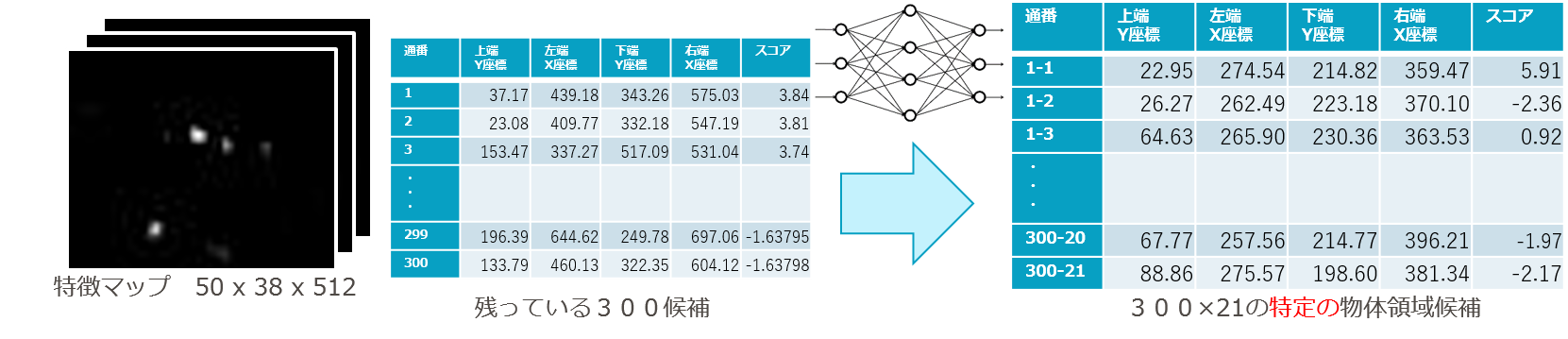
(5)特徴マップと残った候補領域をニューラルネット(RoI Pooing + 全結合層)に入力し、各物体ラベルについて、候補領域の座標とスコアを得る。
- RoI (regions of interest)pooling
- 「興味のある領域のみを残す」
- ここでのニューラルネットはRoI pooling layerと全結合層4層からなる。全結合層2層の後、座標出力用の層とスコア出力用の層に分岐する。
- [50 × 38 × 512]の特徴マップを入力し、 出力として[300 × 21 × (4+1)]のサイズの、1つの候補領域あたり座標84(※)とスコア21の配列を得る。
- (※)正確には(3)で出力された座標からの補正値
- [50 × 38 × 512]の特徴マップを入力し、 出力として[300 × 21 × (4+1)]のサイズの、1つの候補領域あたり座標84(※)とスコア21の配列を得る。
- ここでのスコアは(3)のときと違って「物体らしさ」ではなく「特定の物体らしさ」
- 20種類の物体ラベルのどれか + どれでもない背景かをあらわす。
- (物体ラベル20種類)(※)PascalVOCデータセットのラベル
- ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', ‘diningtable', 'dog', 'horse', ‘motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor')
- (物体ラベル20種類)(※)PascalVOCデータセットのラベル
- 20種類の物体ラベルのどれか + どれでもない背景かをあらわす。
図7-9 各物体ラベルについて、候補領域の座標とスコアを得る
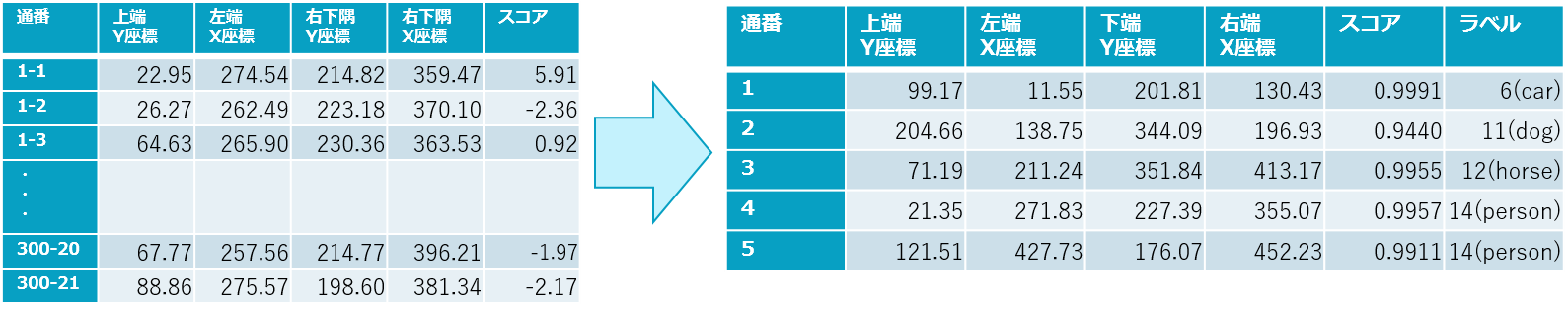
(6) NMS(Non Maximum Suppression) を使用し、よりスコアの高い領域のみを残す。スコアが最大の物体ラベルを判定結果とする。
- 物体ごとに、複数のbounding box が重なっている場合、重なり度合い(IoU)が0.3以上であれば、スコアが高い方のみ残す。
- ’person’の候補領域同士、’dog’の候補領域同士で比べる。
- (4)のNMSより厳しいしきい値を使う
- また、スコア(ソフトマックス関数で0~1の範囲に変換したもの)がしきい値0.7以上のもののみを残す。
- 300(×20)->5に絞り込まれる。
- 800 x 600の画像向けの座標->元のサイズである500 x 375の画像向けの座標に変換する。
図7-10 300(×20)->5に絞り込んで得られた物体ラベルを判定結果
(7)結果を描画・出力する
- (6)までで残った5つの候補を描画して完了!
図7-11 描画処理
8. (付録)pdbの使い方について
-
Pythonの標準ライブラリで、Python用デバッガ
-
使い方
-
python -m pdb inference.pyのように実行時にオプション指定する。 - もしくは、pythonコードの中に下記の行を入れておくと、その行にブレークポイントができ、処理が中断する。
import pdb; pdb.set_trace()- 主なコマンド
-
| コマンド | 用途 |
|---|---|
| s | ステップイン |
| n | ステップオーバー |
| r | ステップアウト |
| l, ll | 現在行周辺のソースを表示 |
| a | 現在の関数の引数一覧を表示 |
-
便利な使い方として、デバッグ中に他のライブラリを呼び出すことができます。
- numpy, PIL, pandasなどを呼び出すことで、デバッグ中に変数の中身を画像やcsvの表として吐き出させることが出来ます。
-
画像の出力コード例
(Pdb) import numpy as np
(Pdb) from PIL import Image
(Pdb) pil_img = Image.fromarray(<2or3次元のnumpy配列が入った変数>.astype(np.uint8))
(Pdb) pil_img.save("output_image.jpg")
- csvの出力コード例
(Pdb) import pandas as pd
(Pdb) pd.DataFrame(<1or2次元のnumpy配列が入った変数>).to_csv("output_csv.csv")
pdbを使って、推論コードの流れを追う。
7 節で示した(1)~(7)の流れをpdbを使って追ってみました。
各処理について、「コードの該当部分」や「主な入出力の値,shape」を以下に記載します。
(1)画像を所定の大きさにリサイズし、平均画像を差し引く
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\faster_rcnn.py(217)prepare()
-> img = resize(img, (int(H * scale), int(W * scale)))
- 主な入出力の値,shape
(Pdb) H, W, scale
(375, 500, 1.6)
(2)畳み込みニューラルネット(conv_layers)に画像を入力して、特徴マップ(feature maps)を得る。
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\faster_rcnn.py(154)forward()
-> h = self.extractor(x)
- 主な入出力の値,shape
(Pdb) x.shape, h.shape
((1, 3, 600, 800), (1, 512, 38, 50))
(3)特徴マップをRPN(Resion Proposal Network)というニューラルネットに入力して、物体候補領域(proposals)の座標とスコアを得る。
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\region_proposal_network.py(121)forward()
-> rpn_locs = self.loc(h)
121 -> rpn_locs = self.loc(h)
122 rpn_locs = rpn_locs.transpose((0, 2, 3, 1)).reshape((n, -1, 4))
123
124 rpn_scores = self.score(h)
125 rpn_scores = rpn_scores.transpose((0, 2, 3, 1))
126 rpn_fg_scores =\
127 rpn_scores.reshape((n, hh, ww, n_anchor, 2))[:, :, :, :, 1]
128 rpn_fg_scores = rpn_fg_scores.reshape((n, -1))
129 rpn_scores = rpn_scores.reshape((n, -1, 2))
- 主な入出力の値,shape
(Pdb) x.shape, rpn_locs.shape, rpn_fg_scores.shape
((1, 512, 38, 50), (1, 17100, 4), (1, 17100))
(4) NMS(Non Maximum Suppression)などを使用し、より物体らしい領域のみを残す。
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\utils\proposal_creator.py(124)__call__()
(Pdb) ll
122 # Remove predicted boxes with either height or width < threshold.
123 min_size = self.min_size * scale
124 -> hs = roi[:, 2] - roi[:, 0]
125 ws = roi[:, 3] - roi[:, 1]
126 keep = np.where((hs >= min_size) & (ws >= min_size))[0]
127 roi = roi[keep, :]
128 score = score[keep]
129
130 # Sort all (proposal, score) pairs by score from highest to lowest.
131 # Take top pre_nms_topN (e.g. 6000).
132 order = score.ravel().argsort()[::-1]
133 if n_pre_nms > 0:
134 order = order[:n_pre_nms]
135 roi = roi[order, :]
136
137 # Apply nms (e.g. threshold = 0.7).
138 # Take after_nms_topN (e.g. 300).
139 if xp != np and not self.force_cpu_nms:
140 keep = non_maximum_suppression(
141 cuda.to_gpu(roi),
142 thresh=self.nms_thresh)
143 keep = cuda.to_cpu(keep)
144 else:
145 keep = non_maximum_suppression(
146 roi,
147 thresh=self.nms_thresh)
148 if n_post_nms > 0:
149 keep = keep[:n_post_nms]
150 roi = roi[keep]
151
152 if xp != np:
153 roi = cuda.to_gpu(roi)
154 return roi
- 主な入出力の値,shape
(Pdb) loc.shape, min_size, n_pre_nms, self.nms_thresh, n_post_nms, roi.shape
((17100, 4), 25.6, 6000, 0.7, 300, (300, 4))
(5)特徴マップと残った候補領域をニューラルネット(RoI Pooing + 全結合層)に入力し、各物体ラベルについて、候補領域の座標とスコアを得る。
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\faster_rcnn_vgg.py(215)forward()
(Pdb) ll
215 -> pool = _roi_pooling_2d_yx(
216 x, indices_and_rois, self.roi_size, self.roi_size,
217 self.spatial_scale)
218
219 fc6 = F.relu(self.fc6(pool))
220 fc7 = F.relu(self.fc7(fc6))
221 roi_cls_locs = self.cls_loc(fc7)
222 roi_scores = self.score(fc7)
223 return roi_cls_locs, roi_scores
- 主な入出力の値,shape
(Pdb) x.shape, pool.shape, roi_cls_locs.shape, roi_scores.shape
((1, 512, 38, 50), (300, 512, 7, 7), (300, 84), (300, 21))
(6) NMS(Non Maximum Suppression) を使用し、よりスコアの高い領域のみを残す。スコアが最大の物体ラベルを判定結果とする。
- コードの該当部分
> c:\users\inadu-d\anaconda3\lib\site-packages\chainercv\links\model\faster_rcnn\faster_rcnn.py(222)_suppress()
-> def _suppress(self, raw_cls_bbox, raw_prob):
222 -> def _suppress(self, raw_cls_bbox, raw_prob):
223 bbox = []
224 label = []
225 prob = []
226 # skip cls_id = 0 because it is the background class
227 for l in range(1, self.n_class):
228 cls_bbox_l = raw_cls_bbox.reshape((-1, self.n_class, 4))[:, l, :]
229 prob_l = raw_prob[:, l]
230 mask = prob_l > self.score_thresh
231 cls_bbox_l = cls_bbox_l[mask]
232 prob_l = prob_l[mask]
233 keep = non_maximum_suppression(
234 cls_bbox_l, self.nms_thresh, prob_l)
235 bbox.append(cls_bbox_l[keep])
236 # The labels are in [0, self.n_class - 2].
237 label.append((l - 1) * np.ones((len(keep),)))
238 prob.append(prob_l[keep])
239 bbox = np.concatenate(bbox, axis=0).astype(np.float32)
240 label = np.concatenate(label, axis=0).astype(np.int32)
241 prob = np.concatenate(prob, axis=0).astype(np.float32)
242 return bbox, label, prob
- 主な入出力の値,shape
(Pdb) raw_cls_bbox.shape, raw_prob.shape, self.n_class, self.nms_thresh
((300, 84), (300, 21), 21, 0.3)
(Pdb) bbox
array([[ 95.76969 , 9.342056, 200.67508 , 128.2852 ],
[204.80559 , 139.05988 , 344.04272 , 196.89499 ],
[ 77.68669 , 220.2981 , 354.05774 , 407.38 ],
[ 19.883629, 268.0022 , 217.0835 , 352.26886 ],
[121.284515, 427.82748 , 175.92154 , 452.2264 ]], dtype=float32)
(Pdb) label
array([ 6, 11, 12, 14, 14])
(Pdb) prob
array([0.999156 , 0.93468636, 0.9970132 , 0.99691606, 0.991097 ],
dtype=float32)
(7)結果を描画・出力する
- コードの該当部分
> c:\users\inadu-d\pjフォルダ\14.2019アドベントカレンダー\inference.py(16)<module>()
16 -> vis_bbox(img, bboxes[0], labels[0], scores[0],
17 label_names=voc_bbox_label_names)
18 plt.show()
9.おわりに
- 論文を読んだりするのみだけでなく、こうしてプログラムをデバッグしながら動かすことでより速く手法の理解ができます。
- 物体検出のプログラムを動かす選択肢としては、ChainerCVが取っ付き易いです。
- 今回(推論編)と題した記事を書きましたが、機会ができれば続きとして(学習編)を書きたい。
- 初めてQiitaに投稿しますが、段組とか見栄え面の調整が難しかった・・・。読みづらいところはご容赦ください。
- もし誤りあればコメントいただけますと幸いです。