こんにちは、@daifukusanです。
専門学校でITを教えている傍らで、趣味で機械学習やデータサイエンスを勉強しています。
参考書を読むだけの勉強は、中々モチベーションが続かないので、学生時代にハマっていた競馬を題材にして、分析やら機械学習やらで遊んでいます。
今回は、その際に試した内容を紹介します。
競馬分析関連の記事リンク
競走馬の強さの数値化に挑戦する ← 本記事
競走馬のレース適正の数値化に挑戦する
競走馬の強さ、レース適正を数値化したので折角だし使ってみる
1. はじめに
機械学習をやっていて厄介な問題の一つがカテゴリカル・データの扱いです。
例えば、以下のようなデータだと、馬名や騎手名、レース名、天気、馬場などの大小関係のないラベルデータです。
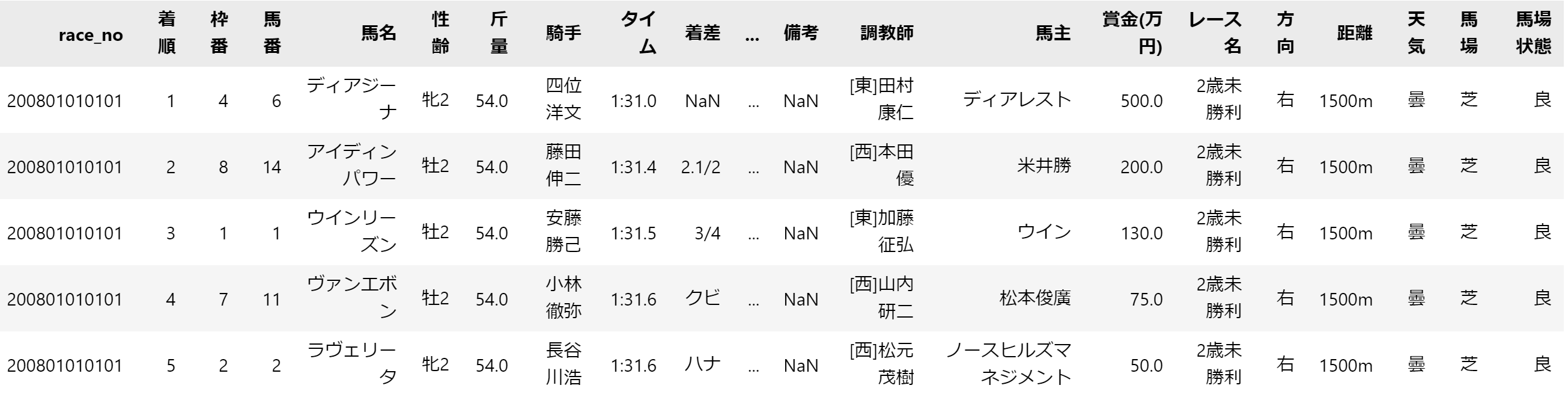
以下のページによると、カテゴリカル・データを数値化する手法は大きく4つあるようです。
※それぞれの特徴については、割愛します。
- One hot Encoding
- Label Encoding
- Count Encoding
- Target Encoding
天気や馬場、馬場状態などの種類がバリエーションが少ないデータに対してOne hot Encodingは有効ですが、馬名や騎手名についてはバリエーションが多いため、現実的ではありません。
一方、Label EncodingやCount Encodingなどの手法を使うと、データサイズの急激な増大は抑えられます。
しかし、数値同士に予測とは関係のない(少ない)大小関係が生まれてしまうため、数値化の手法としては微妙です。
そうなると、残る候補はTarget Encodingになります。
この方法では、何らかの方法を使って、カテゴリカル・データを予測と相関のある数値データに落とし込む必要があります。
今回の競馬の例では、レース開始時点での馬の強さのようなものを求めることが必要になります。
ネットで検索した限りでは、西田式スピード指数が競馬予測では有名なようです。
また、Bradley-Terryモデルというモデルを使って、同じような数値化に試みた例もありました。
今回は、そのどちらでもない数値化手法を使って、競走馬の強さを数値化したいと思います。
ちなみに
カテゴリカル・データの手法として、大きく4つ紹介しましたが、ディープラーニングでは埋込み層(Embedding Layer)を使ったカテゴリカル・データのベクトル化がよく用いられているようです。
こちらも、スカラ値、ベクトル値という違いはあれど、一種のTarget Encodingと言っていいのでしょうかね?
詳しい人教えてください。
2. 麻雀のレーティング計算を応用した手法
麻雀など多くの対戦ゲームでは、レーティングと呼ばれる強さを数値化した指標が使われています。
例えば、天鳳という麻雀サイトでは、以下の計算式でレーティングを計算しています。
※少し古いかもしれません。
Rの変動=試合数補正×(順位基準点+補正値)
試合補正数:400試合未満 1-試合数×0.002 400試合以上 0.2
順位基準点: 1位 +30 2位 +10 3位 -10 4位 -30
補正値 :(卓平均R-自分のR)÷40(50に変更との噂あり)
(https://w.atwiki.jp/vipdetenho/pages/280.html より引用)
今回は、こちらを競馬用にアレンジして使用しました。
レーティングの計算式は、以下のとおりです。(太字が修正箇所です)
Rの変動=試合数補正 × 順位基準点 × (1 + 5 × 補正値)
試合補正数:10試合未満 1-試合数×0.008 10試合以上 0.2
順位基準点: 1位+30、最下位-30 となるよう頭数で分割
補正値 :(レースの平均R-競走馬のR)÷ レースの平均R
2.1. レーティングの算出
netkeibaからスクレイピングで取得した2008年~2020年までのデータを使用して、レーティングを算出しました。
使用したデータの形式は、以下のとおりです。

また、算出に使用したコードは以下の通りとなります。(df4にデータが格納されています。)
import numpy as np
race_list = list(df4.loc[:,'race_no'].unique())
uma_list = list(df4.loc[:,'馬名'].unique())
rate_dict = {k:(0,1000, 1000) for k in uma_list}
rate_before_ = []
rate_after_ = []
race_rate_ = []
for race in race_list:
df_race = df4[df4.loc[:,'race_no'] == race]
rate_before = [rate_dict[el[4]][1] for el in list(df_race.values)]
rate_mean = sum(rate_before)/len(rate_before)
base_ = np.linspace(30,-30,len(df_race))
rate_after = []
race_rate = []
for i, el in enumerate(list(df_race.values)):
# 学習率
cor_match = 0.2
n_match = rate_dict[el[4]][0]
if n_match <= 10:
cor_match = 1 - 0.08*n_match
#順位基準点
base = base_[i]
# 補正値
corr = (rate_mean - rate_before[i])/ rate_mean
ra = rate_before[i] + cor_match * base * (1 + 5*corr)
rate_after.append(ra)
rate_dict[el[4]] = (n_match+1, ra, max(rate_before[i], ra))
race_rate.append(-corr*100)
rate_before_ += rate_before
rate_after_ += rate_after
race_rate_ += race_rate
df4.loc[:,'レート(前)'] = rate_before_
df4.loc[:,'レート(後)'] = rate_after_
df4.loc[:,'レース内レート'] = race_rate_
算出したレーティングが高い順に競走馬を並べると以下の通りとなります。
同一馬が複数回登場しないよう、キャリアハイの1件のみ表示しています。

うーん、、、最近の馬はよく知らないんですが、キングズガードという馬は有名なのでしょうか?
キタサンブラックやゴールドシップ、ロードカナロアなどが強いのは何となく知っていますが、、、
どうやら、レーティング算出のための式はもう少し改善が必要なようです。
3. TrueSkillを使用した手法
対戦ゲームのレーティングの計算式を調べているときに、TrueSkillというレーティングアルゴリズムを知りました。
こちらは、Microsoftが開発した複数人対戦に対応したレーティングアルゴリズムで、収束が早いことが特徴なようです。
このアルゴリズムの実装がpythonのライブラリとして提供されていたので、こちらも試してみました。
導入方法などの詳しい説明は、以下の記事を確認してください。
※TrueSkillの商用利用にはライセンス登録が必要なようなので、商業利用する際は注意しましょう。
3.1. レーティングの算出
2.1.で紹介したものと同様のデータを使って、trueskillによるレーティングを算出します。
実装は以下のとおりです。
CPU:AMD Ryzen 7 2700、メモリ:32GBのPCで5分近くかかりましたが、実装が下手くそなだけでもっと早くなると思います。
# trueskill版
import trueskill
mu = 25.
sigma = mu / 3.
beta = sigma / 2.
tau = sigma / 100.
draw_probability = 0.001
backend = None
env = trueskill.TrueSkill(
mu=mu, sigma=sigma, beta=beta, tau=tau,
draw_probability=draw_probability, backend=backend)
race_list = list(df4.loc[:,'race_no'].unique())
uma_list = list(df4.loc[:,'馬名'].unique())
rate_dict = {k:env.create_rating() for k in uma_list}
rate_dict = {k:(v,v) for k,v in rate_dict.items()}
rate_before_ = []
race_rate_ = []
race_after_ = []
for race in race_list:
df_race = df4[df4.loc[:,'race_no'] == race]
rate_before = [env.expose(rate_dict[el[4]][0]) for el in list(df_race.values)]
rate_mean = sum(rate_before)/len(rate_before)
teams = [(rate_dict[el[4]][0],) for el in list(df_race.values)]
teams = env.rate(teams, ranks=list(range(len(df_race))))
rate_after = [env.expose(t[0]) for t in teams]
race_rate = [(x-rate_mean)/(rate_mean + 0.001)*100 for x in rate_after]
for i, el in enumerate(list(df_race.values)):
rate_dict[el[4]] = (teams[i][0], max(rate_dict[el[4]][0], teams[i][0]))
rate_before_ += rate_before
race_rate_ += race_rate
race_after_ += rate_after
df4.loc[:,'馬レート(前)'] = rate_before_
df4.loc[:,'レース内馬レート'] = race_rate_
df4.loc[:,'馬レート(後)'] = race_after_
先程同様、算出したレーティングが高い順に競走馬を並べます。

これは!!にわか競馬ファンでも先程の結果より、明らかに直感に近い順位になっていることが分かります。
やはり自作で頑張るより、既存の最適化されたライブラリを使ったほうが良さそうですね。
もっと昔のデータから遡って分析して、歴代最強の競走馬を調べるのも面白そうですね。
netkeibaに2008年以前のデータがないので無理ですが、、、JRA-VAN入会しようかな。
以上、結構面白い結果が出たので個人的には大満足でした!
次回 : 競走馬のレース適正の数値化に挑戦する