PythonとKerasで画像認識CNN構築
本記事はCNNを利用した画像認識を記載します。
CNNについて分からない人は適宜調べてください。
簡単に言うとCNNという学習手法によって判別機を作り、入力画像がどのカテゴリーに一番近いを判別するものです。
ちなみにKerasの裏側ではTensorflowというライブラリが使われています。
開発環境
Python : 3.5
Keras : 2.0.0
Tensorflow : 1.10.0rc0
構成
今回はディレクトリごとにカテゴリーを区切っています
例えばカテゴリーを「犬」、「猫」とした場合
「犬」ディレクトリに犬の画像
「猫」ディレクトリに猫の画像
を入れてください。
下記のような構成にしておいてください。
---cnn
---dog
---cat
ライブラリ
下記を使用していますので、足りないものがあればpipで入手しておいてください。
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers.convolutional import MaxPooling2D
from keras.layers import Activation, Conv2D, Flatten, Dense,Dropout
from sklearn.model_selection import train_test_split
from keras.optimizers import SGD, Adadelta, Adagrad, Adam, Adamax, RMSprop, Nadam
from PIL import Image
import numpy as np
import glob
import matplotlib.pyplot as plt
import time
import os
画像読み込み
各ディレクトリ内の(今回は「dog」と「cat」)の画像を全て読み込みんで、サイズ変換などの画像処理をします。
今回は学習に使用するテストデータを各ディレクトリ内の画像の10%としています。もし変えたい場合は"test_size=0.10"という部分を変更してください。
また、.pngのみを参照していますが、jpgなどを使用したい場合は適宜追加してください。
folder = os.listdir("cnn")
folder.pop(-1)
image_size = 50
dense_size = len(folder)
X = []
Y = []
for index, name in enumerate(folder):
dir = "./cnn/" + name
files = glob.glob(dir + "/*.png")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, dense_size)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.10)
CNNモデル作成
CNNの肝となるのはこのモデルです。
モデルの形によって結果に大きな差が出ることもあるので、下記のコードで上手くいかない場合はCNN層を増やしたり減らしたり、活性化関数を変えてみたりしてください。
変えると良いのはActivation関数やConv2D層などですかね。
Dropoutは過学習を防ぐものなのであまり変えてもそんなに変わりません。
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(dense_size))
model.add(Activation('softmax'))
model.summary()
CNN学習器作成
CNNの学習器を作成します。
また、学習した結果をを.jsonと.h5というファイルに格納することで、次回から毎度学習しなくても利用できるようにしておきます。
またoptimizersというのは最適化関数のことですが、これを変えると結構差が出たりするので、全部試してみるとよいです。
Adadelta以外にもSGD, Adagrad, Adam, Adamax, RMSprop, Nadamなどがあるので試してみてください。
エポック数は200にしてありますが、適宜変更してください。
optimizers ="Adadelta"
results = {}
epochs = 200
model.compile(loss='categorical_crossentropy', optimizer=optimizers, metrics=['accuracy'])
results= model.fit(X_train, y_train, validation_split=0.2, epochs=epochs )
model_json_str = model.to_json()
open('mnist_mlp_model.json', 'w').write(model_json_str)
model.save_weights('mnist_mlp_weights.h5');
グラフ表示
最後にこの学習したときのグラフを出力するコードを記載します。
x = range(epochs)
for k, result in results.items():
plt.plot(x, result.history['acc'], label=k)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5),borderaxespad=0, ncol=2)
name = 'acc.jpg'
plt.savefig(name, bbox_inches='tight')
plt.close()
for k, result in results.items():
plt.plot(x, result.history['val_acc'], label=k)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5),borderaxespad=0, ncol=2)
name = 'val_acc.jpg'
plt.savefig(name, bbox_inches='tight')
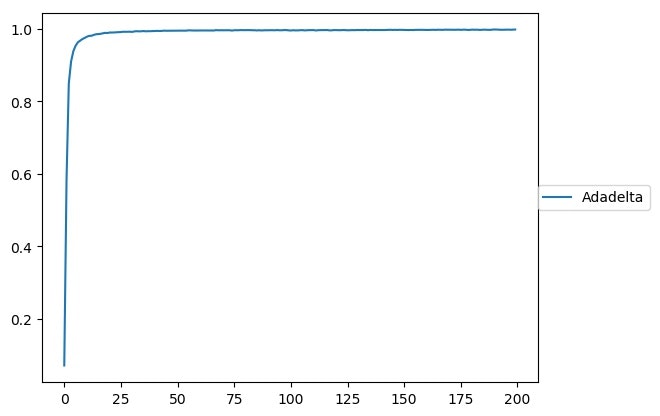
下記のようなグラフが作成されます。
[学習結果]
[テスト結果]
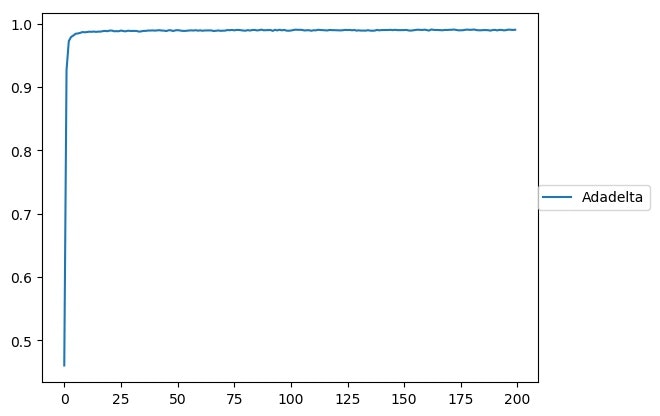
グラフからだとあんまり分かりづらいですが、ログにはちゃんとした結果が書かれています。
学習結果は100%、テスト結果は99.2%でした。
まずまずですが、残りの0.8%をどう攻略していくかが課題ですね。
全コード
全コードを乗せておきます。
folder = os.listdir("cnn")
folder.pop(-1)
image_size = 50
dense_size = len(folder)
X = []
Y = []
for index, name in enumerate(folder):
dir = "./cnn/" + name
files = glob.glob(dir + "/*.png")
for i, file in enumerate(files):
image = Image.open(file)
image = image.convert("RGB")
image = image.resize((image_size, image_size))
data = np.asarray(image)
X.append(data)
Y.append(index)
X = np.array(X)
Y = np.array(Y)
X = X.astype('float32')
X = X / 255.0
Y = np_utils.to_categorical(Y, dense_size)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.10)
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',input_shape=X_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(dense_size))
model.add(Activation('softmax'))
model.summary()
optimizers ="Adadelta"
results = {}
epochs = 200
model.compile(loss='categorical_crossentropy', optimizer=optimizers, metrics=['accuracy'])
results[0]= model.fit(X_train, y_train, validation_split=0.2, epochs=epochs)
model_json_str = model.to_json()
open('mnist_mlp_model.json', 'w').write(model_json_str)
model.save_weights('mnist_mlp_weights.h5');
x = range(epochs)
for k, result in results.items():
plt.plot(x, result.history['acc'], label=k)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5),borderaxespad=0, ncol=2)
name = 'acc.jpg'
plt.savefig(name, bbox_inches='tight')
plt.close()
for k, result in results.items():
plt.plot(x, result.history['val_acc'], label=k)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5),borderaxespad=0, ncol=2)
name = 'val_acc.jpg'
plt.savefig(name, bbox_inches='tight')
最後に
今回はCNNを利用した画像認識を記載しましが。
精度を高めるには画像の質を高めることが第一で、その次にCNNモデルの見直し、最適化関数、エポック数、などが判断材料となってきますので、色々試してみてください。
また、ディレクトリ毎に画像を読み込んでいるので、新しくディレクトリを作れば、簡単に新しいカテゴリーが作れるのでやってみてください。
もしエラーが起こるなどがありましたら、コメント頂ければと思います。