更新記録
2021/6/17 - 「Cloud 型ベンダーロックイン」「Cloud Native DB」について加筆
2021/6/16 - 「OSS」 について加筆
2021/6/14 - 「業界標準」について補足
はじめに
IT企業 = ベンダーロックインの塊
プラットフォーマー = ベンダーロックインの塊
残念ですが、その視点の方は、多くいらっしゃいます。ソフトウェア自身が期待していたほど正しく動作しなかった、もっと言うと枯れていなかった時代には、それしか選択肢が無かったかもしれません。
IT業界は Dog Year だと言われて久しいわけですが、Cloud 全盛の今。ベンダーの儲けどころは大きく変わっています。ベンダーロックインは「囲い込み戦略」であり、その負の部分の方が大きい事をベンダーは知っています。
定義
ベンダーロックインの定義を Wikipedia から拾ってみます。
特定のベンダーの製品・技術 への 依存 が問題となる事があるという事ですね。
これがなぜ「問題」になるのか?
幾つか議論のポイントになりそうなものを列挙してみます。
影響を受けるもの
主に以下になるかと思います。
- プログラムのCode。アプリケーションそのものと言えますね。
- Data ... 構造化データと言いましょうか。
- ファイル ... 半構造化データ。非構造化データとも言えますね。つまり Data の一種
端的に。Code と Data ですね。
ビジネスへの影響
幾つかのプロジェクトで私が考える主要な事は以下になります。
-
アプリの移行が困難になる
- 例えば、Windows アプリから、iOS アプリへの移植
- 例えば、Oracle から、SQL Server への移植
- これを鑑みると 既存の Code の変更の必要性が少ない場合 が対象となりますね。
-
Data の閲覧が困難になる
- 例えば、Excel のファイルを、Google Sheet で正確に再現できない
- 例えば、BigQuery のデータを、Azure Synapse Analytics に移行が出来ない
- これを鑑みると 既存のデータを移動させる必要性が高い場合 が対象となりますね。
なぜ移行をする必要があるのでしょうか?
- アプリケーションの場合
- 長期にわたってフローが変わらない
ビジネス上、変える必要がないアプリケーションに、ベンダー都合のバージョンアップは辛いものがあります。塩漬けの選択肢が出てきますが、API化などをして、最低限の新しいアプリケーションとの連携が出来る状態は作っておきたいものです。
- Data の場合
- Big Data を実現できる環境の登場により、Data のライフサイクルが長くなった。特に RAW Data。
- Data が企業の意思決定や、B2C・B2B・B2E などでの自動化のための様々なエンジン (機械学習のモデル作成など) を開発するための源泉であると再認識された。
特に Data はアプリケーション (つまり Code) よりもライフサイクルが長くなりがち です。スマートフォンのアプリケーションのCode。後、何年使えますかね? Data は10年以上は使える場合が多いと思います。経年での変化をつぶさに見る事が出来るようになったからです。
となると:
- 構造化データよりも、非構造化データ。特にファイル
- ファイルのフォーマット (CSV、Paquetなど)
をどう持つか? は重要です。
ちなみに、NLP (Natural Language Processing) 系の機械学習の技術が重要になってくるのは、ここです。メールやファイルなどの非構造化データから、構造化データを抽出できる可能性があるからです。そして、それは Microsoft 365 の Viva で始まっています。結果、リコメンデーションなどが行えるのですよね。
典型的なベンダーロックイン
これまでのお話の中にも出てきましたが。整理をしてみます。
- 過度に求めたパフォーマンス
- Hardware 機能の直接呼出し
- OS のAPIの直接呼出し
- RDBMS でのストアドプロシージャ
- RDBMS でのベンダーが売りにしている関数・機能の実装
- 単独の Platform への過信
- 全てを Cloud に置く
- 全てを 最速と言われているファイルフォーマットに統一する
- 自社にエンジニアを抱える。あるいはそこが触れる組織との有償契約の準備
- Open Source の場合は、Contribute 出来る道を作る
- 全てを丸投げする。ベンダーの言う事を鵜呑みにする。
- カネでしか解決できない
皆さん、時間 が有限という事は十二分にご存じですよね?
Open Source との関係
「Open Source ならベンダーロックインじゃない」
このお話は頻繁に出てきます。
果たしてそうでしょうか?
例えば .NET。
現在は、.NET Foundation のプロジェクトです。Microsoft もそのメンバーの一部です。
Privacy Policy や、Code of Conduct は、Microsoftではなく、dotnetfoundation.org で管理されています。
[.NET - オープンソース] (https://docs.microsoft.com/ja-jp/dotnet/core/introduction#open-source)
例えば TensorFlow。
同じ Open Source でも tensorflow.org の利用規約は、Google.com にあります。
[TensorFlow] (https://www.tensorflow.org/)
ONNX も当初は Facebook と Microsoft で開発を始めました。現在は Linx Foundation が管理しています。これも、当該サイトの Terms of Use などがどこにあるかである程度の判断が出来ますね。
ONNX
良し悪しではなく、現時点で誰の管理下なのか が理解できますね。
Open Source は Community の善意だけで成立するわけではないと思います。スポンサーも必要であり、その先でContributeしているエンジニアの方が評価され、報酬を得られる仕組みが必要です。スポンサーが偏っているかどうか が重要なのではないでしょうか?
ここでももう一つ見えてきます。そのOpens Sourceのプロジェクトが 今後どうなるのか? 特定のベンダーの管理下で続けられるのか? あるいは、Linux Foundation の様なベンダーの外にある団体に寄贈されるのか? その目利きが必要で、そのために業界の動向にもアンテナを張り巡らせる事が大事そうですね。
Open Source の製品については、商用製品とは全く異なる扱い方が必要になります。
別の Blog で書きましたが。
クラウド時代の製品・サービス選定の考え方
- 消費するだけの立場しか取れない場合
- その製品へのロックインが始まる可能性があります。
- 将来、似た役割の別の製品に引っ越しできる準備を常に考慮した方がいいです。例えばRDBMSなら、別のRDBMSにデータを持っていけるのか? RDBMSの場合は、スキーマつまりテーブルが無いとデータの格納が出来ません。テーブルのスキーマの互換性も重要です
- Contribute つまり、一緒に開発する力がある場合
- License に注意を払って、Community と一緒にその製品を普及させる。それが結果として多くのエンジニアとユーザーを巻き込み、長く使えるようになります
つまり、技術力を持っているかどうかで大きく変わってきます。
そもそもがコントロールを自分達だけでしたい訳ですから、自社にその技術を持ちたいですね。
「安いからOpen Source」
これは製品単価だけの話です。TCO/ROI を加味すれば、妥当な発言かどうか は直ぐに分かりますよね😊
新型ベンダーロックイン「クラウド型ベンダーロックイン」
「xxx システムが AWS で稼働しているから、それと連携が見込まれるこのシステムも AWS で動かします」
この手のお話が増えてきました。AWSに限りません。Azure でも、GCP でも同様です。
私はこれを亜種であるベンダーロックインと認識しています。クラウド型ベンダーロックイン です。
問題
これが発生する理由は主に以下になります。
- クラウドからのデータのダウンロードに費用が発生する
- アーキテクチャ上、連携システムはネットワークの観点から近い方が良い
更に
- その Cloud にしかないテクノロジーがある。特に SDK に関連するもの。アプリが SDKに依存して記述されてしまうのを最小化する考慮は必要。Driver的なものを適用する、など。この観点では、SQL Server - SQL Database は、接続文字列だけでそれが吸収できるのは凄い可搬性を持つと言えますね。
置き場所の検討は重要です。Cloud に大量の Data を置く。それは、技術とは別の観点でベンダーロックインの可能性が出てくるわけです。単なるファイルコピーが何千万円のコストを生む事もある事を、エンジニアだからこそ知っておきたいです。
その Cloud は本当に信用できるのでしょうか? 取り返しのつかない事にならないよう、プライバシー、コンプライアンスなど、その Cloud ベンダーを企業として調査する事は重要だと思います。
Cloud に Data を置かない、という事ではありません。リスクを踏まえ、適切な利用を心がけたいものです。
そして、Code も GitHub などの CI/CD 経由で展開したいものです。Code の可搬性も高くなりますし、何より障害発生時に別の Region や Cloud で即座にサービスを立ち上げる事が出来るようになります。
極論は思考を前に進める上では、大変重要ですが、実行のための落としどころは別にある事が多いです。そして、そのために 専業ベンダーだけと会話する危険性 も十二分に理解したいものです。それこそ Cloud ベンダーと心中になってしまいます。
疎結合
Cloud になっても、疎結合 の観点は、常に私たちを助けてくれます。ベンダーロックインを回避する事は難しいので、最小化する。疎結合も 疎 に 結合 するんです。つまり、何らかの依存関係は持ちます。
1つのアプリケーションが依存していそうなものを、乱暴ですが書いてみました。垂直方向での疎結合ですね。
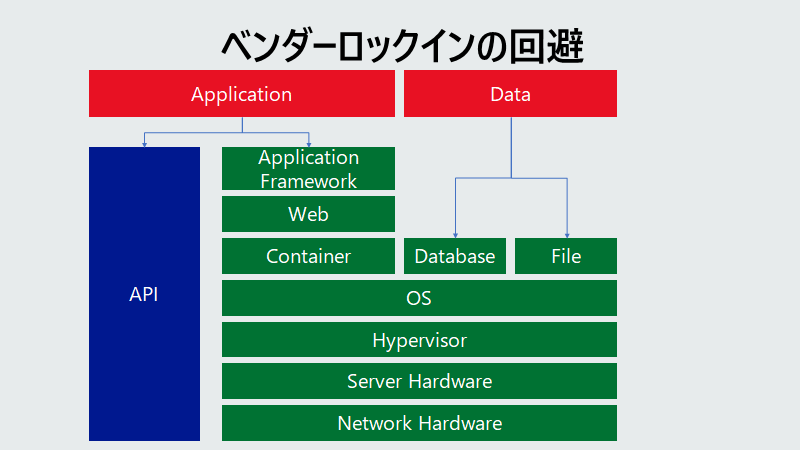
- もはや OSのAPIを直接呼び出すような最適化をするコードは存在はしますが、数としては少ない。
- 通信は HTTP/HTTPS 系で確定。
こうした図を書いておけば、こんなことが言えるかと思います。
- アプリケーションは、Java 11 上で動くようにしている。別のOSで動かす場合は、テストは必要だけど、最小限に留まるかと。
- RDBMSを使っていますが、データは全件 Export 出来ます。ベンダー独自のデータ型を使っていないのであれば、別の RDBMS に移行したい場合は、テストは必要だけど、最小限に留まるかと。
PaaS = ベンダーロックインじゃない事も多い
Azure に Web App というメチャクチャ使われている PaaS があります。Web Serverのホスティング環境と言っていいです。
「PaaSはベンダーロックイン」だから。
果たしてそうでしょうか?
- Web App で動かすコードは、ピュアな .NET/Java/PHP/Python の Web アプリケーション
- Web App は、Web Server 以下のレイヤーのホスティング。Web Serverの設定もある程度変更できる
- Windows 版 なら、web.config
- Linux 版 なら、httpd.conf
- Container 版なら、docker config
- しかも、そもそもそれらを吸収する UI や CLI などもある。全ての差分吸収は勿論、難しいですけど。
- CI/CD に至っては、GitHub など複数のサービスが使える
つまり、管理系は、どうしてもベンダーロックイン部分が残ります。でも、アプリの引っ越しは容易なことが分かると思います。
この観点で、面白いのが Azure Cosmos DB です。何故か?
-
Cosmos DB 独自の API は SQL のみ。それも ANSI SQL に相当近い。それ以外の NoSQL (Cassandra, MongoDB, Gremlin) は、ほぼ100%互換。Key-Value は単純なオペレーションのみなので割愛。以下、明確な違いではないですが😊
-
インフラだけは、設定のみ。頑張れ Cloud と委任できる。
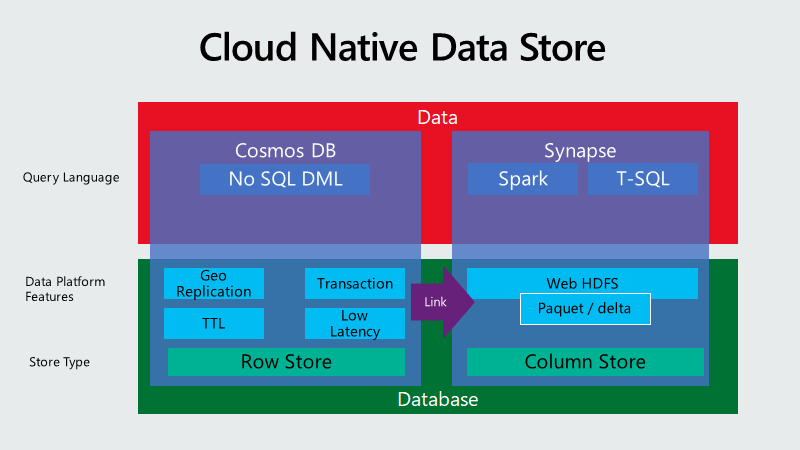
つまり、Code の可搬性は高いし、Data は標準的な方法でいつでも抽出できる わけです。オンプレにだって、持っていけますよね。IaaS を想像してもらえば分かります。
これが、私の中だと Cloud Native だと思います。Cloud Born と言ってもいいかもしれません😊
ベンダーロックインを回避したい。完全回避は不可能。じゃ、落としどころは? = 業界標準かどうか
ビジネスでも、日常でも、学校でも使われる OSは、Windows / iOS / Android の事実上3種類。いずれも「ベンダー」が開発を行っています。
コンピューターのCPUは、ざっくり言って😊、Intel / AMD / ARM が多いです。いずれも「ベンダー」が開発を行っています。
ベンダーロックインを否定する事は、全て自社で開発・保守が出来る状態が必要になると思います。これは、事実上難しいと思います。つまり、ある程度のベンダーロックインは回避する事が難しいです。
となると、重要な点は 選択肢があるか? ではないですかね。
それよりは 標準的な技術 なのかどうかが重要です。
例えば、SQL。ANSI/ISO などで、SQL文は定義されています。
商用・Open Sourceに関わらず、多くのRBMS。あるいは SQL 準拠を目指している Spark SQL なども ANSI SQL準拠を謳っています。引っ越し先でも同じ標準に準拠しているか? これは即座に調べられるかと思います😊
[ANSI SQL の例] (https://blog.ansi.org/2018/10/sql-standard-iso-iec-9075-2016-ansi-x3-135/)
これが最重要な評価のポイントと言っていいと思います。
Web の技術がなぜこれだけ広く・長く使われているか? それは W3C の存在といえます。現在、HTTP/3 の議論が進んでいますね。これは Google が QUIC というプロトコルで独自実装していたのですが、その効用が広く認められ (Chrome というブラウザーの普及率は大きいですよね)、現在 IETF などで採用の議論が続いています。W3C でも議論がされるんでしょうかね?
つまり、皆さんは、その分野での標準的な技術が何で、今後標準化団体が採用するかどうか? について、見識を持つことが大事になってきますね。
実はベンダーロックイン以外で発生する、移行時の問題点 - バージョンアップが出来ない
これは Open Source のプロダクトを使っていると良く発生します。下位互換性の欠如 です。
1つ前のバージョンからのアップグレードは比較的サポートされていますが、2つバージョンを飛ばすと、途端に難しくなります。
商用製品は、サポートライフサイクルが明確な事もあり、複数のバージョン飛ばしの影響は最小化されています。商用製品の場合はバージョンよりも10年、といった時間が重要です。
まとめ
見えてくることは、塩漬け の選択肢を極力減らす、という事かと思います。
塩漬けをした瞬間から、互換性の問題に突入します。後回しにすればするほど、捨てたほうが良いコトが多いです。
また、ソフトウェアの中でも、コードとデータを分けて ライフサイクルを考える事は重要です。巨大な単独データベースを作るのは、避けたいですね。アプリケーションが直接使う読み書きするデータベースと、Big Data で使うデータベースは、分けたいものです。なぜなら、データの寿命が異なるからですね。
業界標準 にどれだけ準拠しているか? Open Source であっても、それは重要です。
そして、Agile の考え方はやはり全てのプロジェクトに入れたいです。常に手を入れられるようにする。
人が手を入れる全体であれば、コードも読みやすくしようとしますし、依存性、つまりは疎結合ついても考慮されると思います。そして他社への依存を減らすため、自分達で判断できるよう自社にエンジニアを。取引先ではなく、同じビジネスの目標に向かって、彼らと仕事をご一緒したいものです。
「動けばいい」
これだけだと、世に役に立つシステムを作るエンジニアには遠いのでしょうね。
おまけ
iOS は、これを考えるとなぜ存続できているのか、不思議なエコシステム。アプリのNativeは、Objective C ですからね。
対照的なのが Web。
ユーザーが大量にいるって、凄い事ですよね😊