はじめに
lightgbmで学習から評価までの一連の流れをやってみました。
(結構忘れてしまうんですよねぇ…)
※ 追記追記で読みにくいところもあるかと思います
環境
Corabolatory で実行しています。
※ これ環境変わっちゃうので良くなかった…
コード
4.1.0 の例
バージョン上がって今までのじゃNGになったので。
ついでに GroupKFold も。
import os
import random
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import GroupKFold
def seed_everything(seed: int):
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
np.random.seed(seed)
seed_everything(42)
X = train_data_lrg_cd.drop(['group_key', 'y'], axis=1)
y = train_data_lrg_cd['y']
# 同一グループのデータが train/valid に別れないよう分割
groups = train_data_lrg_cd['group_key']
group_kfold = GroupKFold(n_splits=4) # train:test = 3:1
group_kfold.get_n_splits(X, y, groups)
# LightGBM のパラメータ
params = {
'objective': 'binary',
'metric': 'auc',
'boosting_type': 'gbdt',
'verbosity': -1,
'random_state': 42,
'learning_rate': 0.01,
# 'scale_pos_weight': 10, # label=1 に重み付けしたければいじる
}
verbose_eval = 100
num_iterations = 100000
early_stopping_round = 100
# 学習
for i, (train_index, test_index) in enumerate(group_kfold.split(X, y, groups)):
# データセットを生成する
lgb_train = lgb.Dataset(X.iloc[train_index], y.iloc[train_index])
lgb_eval = lgb.Dataset(X.iloc[test_index], y.iloc[test_index], reference=lgb_train)
# 学習する
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_eval],
num_boost_round=num_iterations,
callbacks=[
lgb.early_stopping(early_stopping_round, False, True),
lgb.log_evaluation(verbose_eval),
]
)
バックアップ
# lightgbmインストール
!pip install lightgbm
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', 100)
from sklearn import metrics
import matplotlib.pyplot as plt
%matplotlib inline
# Breast Cancer データセットを読み込む
bc = datasets.load_breast_cancer()
X, y = bc.data, bc.target
# 訓練データとテストデータに分割する
X_train, X_test, y_train, y_test = train_test_split(X, y)
# データセットを生成する
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# LightGBM のハイパーパラメータ
params = {
# 二値分類問題
'objective': 'binary',
# AUC の最大化を目指す
'metric': 'auc',
# Fatal の場合出力
'verbosity': -1,
}
# 上記のパラメータでモデルを学習する
model = lgb.train(params, lgb_train, valid_sets=lgb_eval,
verbose_eval=50, # 50イテレーション毎に学習結果出力
num_boost_round=1000, # 最大イテレーション回数指定
early_stopping_rounds=100
)
# 保存
model.save_model('model.txt')
# テストデータを予測する
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
# 保存したモデルを使う場合はこんな感じ
#bst = lgb.Booster(model_file='model.txt')
#ypred = bst.predict(X_test, num_iteration=bst.best_iteration)
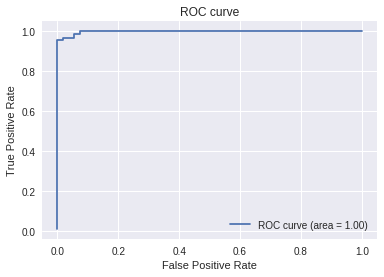
# AUC (Area Under the Curve) を計算する
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)
auc = metrics.auc(fpr, tpr)
print(auc)
> 0.9977272727272727
# ROC曲線をプロット
plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc)
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
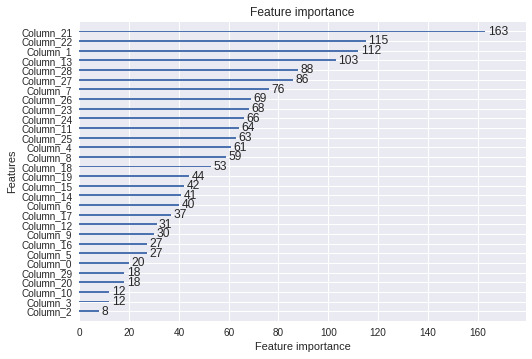
# 特徴量の重要度出力
print(model.feature_importance())
>[ 20 112 8 12 61 27 40 76 59 30 12 64 31 103 41 42 27 37
53 44 18 163 115 68 66 63 69 86 88 18]
# 特徴量の重要度をプロット
lgb.plot_importance(model)
Optuna(最適化)
この項目は 2020/08/21 追記。
まずは optuna をインストール。
!pip install optuna
その後、以下のように import 行を 1 行変更するだけで LightGBM Tuner を使えます。
import optuna.integration.lightgbm as lgb
params = {
略
}
model = lgb.train(params, lgb_train, valid_sets=lgb_eval,
verbose_eval=False, num_boost_round=1000, early_stopping_rounds=100)
print('Best Params:', model.params)
しかし、この方法ではすべてのパラメータをチューニングしてくれるわけでは有りません(そりゃそうか)
https://optuna.readthedocs.io/en/stable/reference/generated/optuna.integration.lightgbm.LightGBMTuner.html?highlight=lightgbm
It optimizes the following hyperparameters in a stepwise manner: lambda_l1, lambda_l2, num_leaves, feature_fraction, bagging_fraction, bagging_freq and min_child_samples.
そういうのをチューニングするにはやはり自分で実装する必要がありそうです。
# 急に cross_entropy になっています、すみません。
# コードサンプルとしては十分かと思うので読み替えてください。
import optuna
from sklearn.metrics import roc_auc_score
def objective(trial):
params = {
'objective': 'cross_entropy',
'metric': 'auc',
'boosting': 'gbdt',
'learning_rate': 0.05,
'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0),
'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0),
'num_leaves': trial.suggest_int('num_leaves', 2, 512),
'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0),
'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0),
'bagging_freq': trial.suggest_int('bagging_freq', 0, 10),
'min_child_samples': trial.suggest_int('min_child_samples', 5, 100),
'seed': 0,
'verbosity': -1,
}
gbm = lgb.train(params, lgb_train, valid_sets=lgb_eval,
verbose_eval=False, num_boost_round=1000, early_stopping_rounds=100)
y_prob = gbm.predict(X_test)
y_pred = np.round(y_prob)
return roc_auc_score(
np.round(y_test.values),
np.round(y_pred)
)
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=50)
print('Number of finished trials:', len(study.trials))
print('Best trial:', study.best_trial.params)
評価関数自作
公式ドキュメント参照。関数の引数、返り値に指定がある。
https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.train.html?highlight=feval
こんな風に eval 関数を書いて、
(引数、返り値の意味するところはドキュメントを読んでください)
def eval_func(preds, train_data):
trues = train_data.get_label() # データから正解ラベルを取得
〜 処理を書く 〜
return ('eval_name', eval_result, True)
params の metric を 文字列 None にしてから、
params = {
〜 略 〜
'metric': 'None',
〜 略 〜
}
train 時に feval=自作関数 と指定してやれば良い。
lgb.train(params, lgb_train, valid_sets=lgb_eval, feval=eval_func)
その他
ROC曲線とAUCについてはこちらがとてもわかり易かったです。
http://www.randpy.tokyo/entry/roc_auc