こんにちは。株式会社 日立ソリューションズの森下です。
この記事は、日立グループ OSS Advent Calendar 2018 の24日目の記事になります。
#はじめに
昨今のプロダクト開発の現場では、OSS(オープンソースソフトウェア)の利用が一般的となっています。ライブラリやフレームワーク、ミドルウェアなど、さまざまなOSSを活用して開発を行っていることでしょう。今の時代、OSSをいかに活用できるかで開発の生産性が大きく変わってくるといっても過言ではありません。
ですが、OSSの利用にはさまざまなリスクも存在します。
- OSS由来の脆弱性に起因するセキュリティ事故
- OSSライセンスに関わるコンプライアンス違反
- OSSコミュニティ終了にともなう保守コスト発生
このような状況に陥ると、開発の生産性向上はおろか、かえってコスト増になってしまいます。近年ではApache Struts2やOpenSSLの脆弱性が話題になったこともあり、このようなリスクを組織的に管理しようというニーズは年々増加しているように感じます。
そこで今回は、このOSSリスク管理のベースとなる「OSSの検出」について、技術的な視点からまとめ記事を作成することにしました。私自身、これまでソフトウェア開発業務に取り組む傍ら、さまざまなプロダクトを対象として「どんなOSSが利用されているか」の調査、つまり「OSSの検出」というタスクを数多く実施してきました。今回は、これに関するノウハウを投稿しようと思います。
なおOSSの検出というと検出ツールの使い方等に関するノウハウだと思われるかもしれませんが、今回はどちらかというと、各ツールにおいて共通する、検出の「一般的な仕様」を主な切り口とし、「どんな検出のタイプがあるのか」「どんな仕組みか」「仕組みによってどんな違いがあるのか」という点についてまとめていきます。その点ご承知おきください。
また今回は、主に"Webアプリーション"を調査対象プロダクトとした場合の観点についてまとめます(特に、単一のサーバマシンで完結するようなWebアプリケーションを想定します)ので、これもご承知おきください。(とはいえ、デスクトップアプリやスマートフォンアプリ、その他のさまざまなプロダクトにも転用できるノウハウになっていると思いますでの、是非参考にしていただけたら幸いです。)
#この記事の概要
- プロダクト開発における「エンジニアがOSSを取得するパターン」の3つの段階について。
- OSS検出方法における「プログラムの実体を見て検出する方法」「パッケージ管理情報を見て検出する方法」の2種類について。
- 各検出方法にはどんな特徴があるのか、そしてその考察について。
#対象読者
- 自プロダクトが利用しているOSSを把握したいが、何から始めたら良いか分からない方
- OSSを検出するためのツールがたくさんありすぎて何を使うべきか分からない方
- 職場でOSS管理の仕事を任されたので関連する知識をとにかく得たいという方
#「OSSの検出」を実現するツール
それではまず「OSSの管理」という話題で必ずといっていいほど出てくる、OSS管理ツールの話を少ししておきます。上述のようなOSS管理ニーズの高まりから、近年さまざまなツールが登場してきました。これらのツールの多くはOSS検出機能を含んでいるため、今回のトピックである「OSSの検出」を行う場合に利用できます。
無償および有償のツールについて、いくつか例を挙げておきます。この記事を読んでいる方々なら、もしかすると聞いたことがあるかもれません。
- Fossolgy
https://www.fossology.org/ - BlackDuck
https://www.blackducksoftware.com/ja/black-duck-home - WhiteSource
https://whitesourcesoftware.com/ - FOSSA
https://fossa.com/
※他にも数多くの無償/有償のOSS管理ツールがあります。Linux Foundationの「オープンソースプログラムを管理するためのツール」も参考にしてみてください。https://www.linuxfoundation.jp/resources/open-source-guides/tools-managing-open-source-programs/
このように、OSSを検出するためのツールの選択肢が増えた一方で、逆に今度は「どれを使えば良いのか?」という疑問が発生してくるでしょう。この点において、検出ツールにおける「検出の仕様」が、一般的にどのようなものになっているのかを把握しておくことは重要です。次章以降、これについて書いていきます。
※なお今回の内容は、OSS検出とセットで語られることが多い「脆弱性の検出」「ライセンスの検出」は対象外です。「何のOSSが利用されているか検出する」という観点のみにフォーカスした内容となります。
#まずは「OSS取得パターン」を理解する
それではOSS検出の仕様について書いていきます。が、これを示すためには、まず我々エンジニアが実際にOSSをどのように取得・利用しているかを理解しておく必要があります。というわけで、「エンジニアがOSSを取得するパターン」について、ここでは3つの段階に分け、今一度おさらいしておきます。
- コーディング段階
ソースコードを実装する段階 - パッケージング段階
ソースコードをビルドし、パッケージ化する段階 - コンフィグレーション段階
アプリケーションの稼働に必要なものを準備する段階
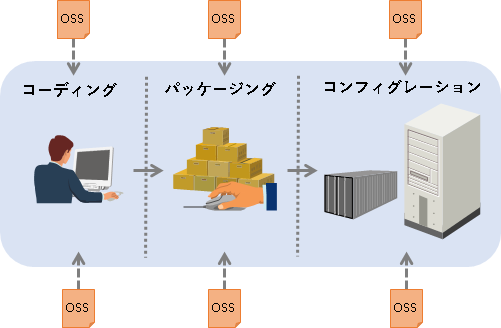
それでは、それぞれの段階について説明していきます。
##コーディング段階におけるOSS取得
エンジニアがコーディングする段階では、どのようにOSSが取得されているでしょうか?
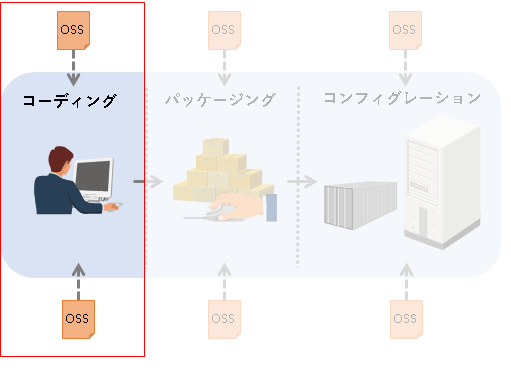
概ね、以下のようなパターンが考えられます。
- OSSのコード断片(スニペット)を自身のソースファイル内にコピーする
- OSSの任意の1ファイルを自身のソースツリーに加える
- 複数のファイルで構成されるOSSを、改変し、自身のソースツリー内に加える
一言で言うと、ソースコードの「コピー&ペースト」による取得です。このパターンにおいては、OSSの実体は自身のソースコードリポジトリ内に格納(commit/push)されることになるでしょう。もはや「OSSを自身のプログラムかのごとく扱っている」ような利用形態となります。
##パッケージング段階におけるOSS取得
続いて、コーディングしたコードをIDEまたはCI環境等でビルド(パッケージング)する段階についてです。この段階においては、どのようなOSSの取得パターンがあり得るでしょうか。
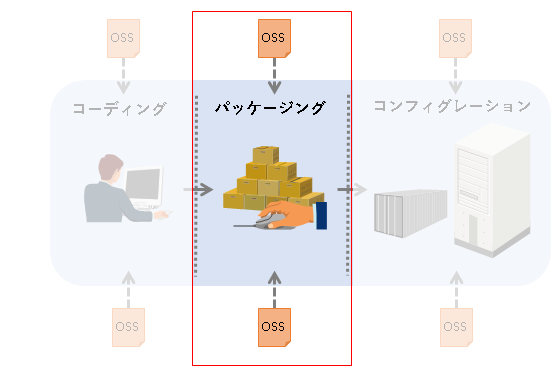
この段階における最も一般的なOSS取得方法は、プログラミング言語ごとのパッケージ管理ツールによる取得になると思われます。大多数の開発現場では、以下のようなパッケージ管理ツールを使ってOSSのライブラリを取り込んでいることでしょう。
- Java
Maven、Gradle - Node.js
npm - PHP
Composer、PEAR - Python
pip、Pipenv - Ruby
RubyGems
例えばnpmの場合は、package.jsonというファイルの「dependencies(依存)」項目に、取得・利用するOSSパッケージを指定します。
{
"name": "sample",
"version": "1.0.0",
"dependencies": {
"async": "^2.6.1"
}
}
このpackage.jsonがあるディレクトリでnpm installを実行することにより、上記の場合はasyncパッケージが取得できます。また、仮に「OSS-Aを使うためにOSS-Bが必要となる」ような場合には、package.jsonでOSS-Aを指定するだけで、npmがこれら両方を取り込んでくれます。例えば上記のdependencies指定の場合、npmでは内部的に以下のような依存関係階層が生成されます。
sample@1.0.0 # ←これが開発対象プロジェクト
`-- async@2.6.1 # ←これが取得OSS
`-- lodash@4.17.11 # ←これが取得OSSを使うために必要なOSS
これら(async、lodash)が芋づる式に全て取得され、利用できるようになります。これがパッケージング段階における主なOSSの取得方法となります。他のパッケージ管理ツールも概ね同じような仕組みであり、利用したいパッケージを依存指定することで、それとともに必要なパッケージも芋づる式に取得されます。
この例ではパッケージ使用数があまり多くありませんでしたが、稀に大量(100個や1000個というレベル)のパッケージを取り込むこともあります。こうなってくるとエンジニアが全てのOSSを把握しきるのは困難です。
以上の方法がこの段階における主なOSS取得パターンになります。ですが、例外的に以下のようなパターンもあります。
- パッケージ管理ツールのプラグインの機能等によって、ビルド時に外部サイトから任意のファイルが取り込まれて利用されるパターン
- 開発環境に含まれるSDKなどがビルド時に同梱されて利用されるパターン
これらは「パッケージ管理ツールで依存指定していないにもかかわらずOSSを取得することになる」というパターンです。このような例外的な取得もあり得ます。つまりパッケージング段階においては、「依存指定により能動的に取得したもの」に加えて、「依存指定なしでも取得されるもの」が存在します。
#コンフィグレーション段階におけるOSS取得
続いて、ビルド(パッケージング)されたプログラムとともにアプリケーションの各構成要素をサーバに構築(コンフィグレーション)する段階についてです。「デプロイ段階」「実行段階」などと言い換えてもいいかもしれません。なおコンテナイメージのビルド等はこの段階だと考えてください。この段階においては、どのようなOSSの取得パターンがあり得るでしょうか。
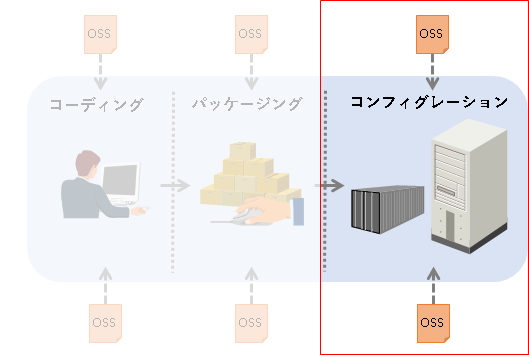
この段階における最も一般的なパターンは、yumやapt-get等の、OSのパッケージ管理ツールによる取得です。
- RedHat系:rpm、yum
- Debian系:dpkg、apt-get
Linuxのサーバを触ったことのある方ならこの辺については把握されているかと思います。パッケージのインストールは以下のようなコマンドとなります。
> yum install java-1.8.0-openjdk
また、コンテナにより稼働するWebアプリケーションの場合には、イメージビルド時にDockerfile等で取得パッケージを指定することになります。
FROM centos7
RUN yum update -y && \
yum install -y java-1.8.0-openjdk
……(省略)……
yumやapt-getを用いる場合は、依存関係も込みでインストールされることになります。そのため、これもまたパッケージによっては大量の依存関係をインストールすることになるでしょう。これがコンフィグレーション段階における主なOSSの取得、利用パターンとなります。
一方で、パッケージ管理ツールを使わずにインストールされるという場合もあるでしょう。例えば、以下のような場合が挙げられます。
- パッケージ管理ツールでインストールできない特定のバージョン等を自前でビルドし構成する場合
- OSSを含む独自開発モジュール(有償製品等も含む)を特定ディレクトリに格納する場合
これらはパッケージ管理ツールを利用せずにOSSを取得・利用しているパターンです。つまりコンフィグレーション段階においては「パッケージ管理ツールを用いた取得」に加えて、「自前で取得し配置する」といった場合も考えられます。
##各段階まとめ
各段階をまとめると、以下のようになります。
| 段階 | OSS取得方法 |
|---|---|
| コーディング段階 | エンジニア自身によるコードレベルでの取得(改変または断片コピーを含むコピー&ペースト) |
| パッケージング段階 | パッケージ管理ツールでの依存指定による取得 + 依存未指定での取得 |
| コンフィグレーション段階 | パッケージ管理ツールでのインストールによる取得 + エンジニア自身による取得(配置) |
これ以外のパターンも存在するかもしれませんが、概ねこのようなものになるでしょう。それでは続いて「OSSをどのように検出していけば良いか」という点について書いていきます。
#OSSを把握するための検出の種類
先に述べたとおり、今回は特定の検出ツールに関する話題は取り上げません。その代わりに「検出の種類にはどういったものがあるのか」「どんな仕組みなのか」について書いていきます。検出にはさまざまなパターンがありますので、今回は以下の2つのカテゴリに分類した上で説明していきます。
- プログラムの実体を見て検出する方法
例:検出対象のプログラムから、OSSのライセンス文言や、それに関わる文字列(CopyrightやLicense等)を検出する
例:検出対象のプログラムから、OSSの任意のファイルとハッシュ値が一致していたり、コードパターンが似ているファイルを検出する - パッケージ管理情報を見て検出する方法
例:インストール済みパッケージの情報(静的なファイルテキスト)から、OSSを検出/特定する
例:インストール済みパッケージを確認するコマンドの結果から、OSSを検出/特定する
以降で、上記それぞれについて説明します。
##プログラムの実体を見て検出する方法
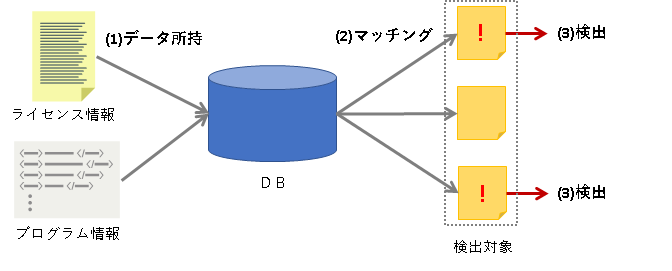
この検出方法の仕組みは、概ね以下のようなものになります。
- まず、事前にマッチの基となる(辞書となる)データをDBに持ちます。※データは検出ツール自身が提供している場合と独自にカスタマイズする場合があります。
- 検出対象の全体に対して、DBの情報とマッチするか調べます。※マッチングにはさまざまなパターンがありますが、それだけで記事になりそうなので詳細は割愛。
- マッチしたものを「OSSの疑いがあるもの」として検出します。
この検出方法は、OSS検出のさまざまな場面で有効です。上述した3つの段階においても、以下のとおり適用可能です。
- コーディング段階
OSSをコピー&ペーストした後のソースコードを検出対象にすれば、OSSと疑われるファイルを見つけることができます。 - パッケージング段階
パッケージング後のモジュール(アーカイブなど)を検出対象にすれば、OSSと疑われるファイルを見つけることができます。 - コンフィグレーション段階
サーバまたはコンテナ内の各ファイルを検出対象にすれば、OSSと疑われるファイルを見つけることができます。
また検出対象となるプログラム形式としては、ソースコード形式およびバイナリ形式のどちらも対象となり得ます。何をどこまで検出できるかという点は、もちろんツールによってレベルが異なってきます。
特筆すべき点として、この検出方法は上記のとおりさまざまな用途で活用できる一方で「何のOSSなのか特定しきれないものが出てくる」という特徴があります。例えば「ライセンス文言が存在する」「OSSに似ている」という検出結果については、最終的に目視確認しないことには「何のOSSなのか」という点を特定できません。また「OSSとハッシュ値が一致している」という検出結果については、(大多数の場合は何のOSSか特定されますが、)理論上は誤検知もあり得るので、目視確認が必要な場合があります。※誤検知となる場合の例としては「OSS-AとOSS-Bの任意のファイルがたまたま同内容である場合」などがあります。
総じて言えるのは、この検出方法の場合、文字どおり「検出」まではできますが、「特定」まで至らない場合があります。そのため「特定」を行うためには多少なりとも人間が介入する必要が出てくる場合があります。
##パッケージ管理情報を見て検出する方法
この検出方法は、何らかのパッケージ管理の仕組み上でOSSを取得・利用している場合に使うことができます。この検出方法の仕組みは概ね以下のようなものになります。
■ パッケージング段階における、利用OSS検出の仕組み
例えばJava開発におけるパッケージ管理ツールとしてGradleを用いているとしましょう。この場合、依存OSSの情報は以下のコマンドで出力することができます。
> gradle dependencies
------------------------------------------------------------
Root project
------------------------------------------------------------
archives - Configuration for archive artifacts.
No dependencies
compile - Dependencies for source set 'main'.
+--- org.springframework.boot:spring-boot-starter-thymeleaf:1.4.2.RELEASE
| +--- org.springframework.boot:spring-boot-starter:1.4.2.RELEASE
| | +--- org.springframework.boot:spring-boot:1.4.2.RELEASE
| | | +--- org.springframework:spring-core:4.3.4.RELEASE
| | | \--- org.springframework:spring-context:4.3.4.RELEASE
| | | +--- org.springframework:spring-aop:4.3.4.RELEASE
……(省略)……
これにより、取得したOSSを検出できます。この出力をパースし構造データにして内部的に活用しているツールもあります(例:Gradle Dependencies Viewer(←本件引用元))。ポイントとして、ここで出力されるOSSはすべて「groupId:artifactId:version」というフォーマットで出力されます。これらのIDはMavenにおけるパッケージ管理仕様であり、これを利用することでOSSを一意に「特定」することができます。
■ コンフィグレーション段階における、利用OSS検出の仕組み
例えばパッケージ管理ツールとしてdpkgが用いられている場合、/var/lib/dpkg/statusの中身は以下のようになっています。
Package: python-apt-common
Status: install ok installed
Priority: optional
Section: python
Installed-Size: 244
Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com>
Architecture: all
Source: python-apt
Version: 1.1.0~beta1build1
Replaces: python-apt (<< 0.7.98+nmu1)
Depends: python | python3
Breaks: python-apt (<< 0.7.98+nmu1)
Enhances: python-apt, python3-apt
Description: Python interface to libapt-pkg (locales)
The apt_pkg Python interface will provide full access to the internal
libapt-pkg structures allowing Python programs to easily perform a
variety of functions.
.
This package contains locales.
Original-Maintainer: APT Development Team <deity@lists.debian.org>
これを参照することで、取得したOSSを含むサーバ内のOSSを検出できます。この情報をパースし構造データにして、内部的に活用しているツールもあります(例:Clair(←本件引用元))。なお、この「項目名:値」の形式は仕様として決まっているため、この「Package」や「Version」の値を利用することで、OSSを一意に「特定」することができます。
~~
上記はあくまで検出の一例ですが、他についてもある程度同じようなものになるでしょう。これらの方法に共通しているのは「OSSを一意に識別できる情報を基に検出を行う」という点です。つまり、何のOSSであるのか「特定」まで行うという特徴があります。
一方で、この検出方法においては「適用可能な範囲が限られてしまう」という特徴もあります。パッケージ管理ツールを用いることがないコーディング段階での取得OSSは、この方法では検出できません。また、パッケージング段階およびコンフィグレーション段階においても、パッケージ管理ツールで依存パッケージとして認識されない例外的なOSSについては、検出することができません。
##検出方法まとめ
検出の方法は以下のようにまとめられそうです。
| 検出可能範囲 | 一意に特定可能か | |
|---|---|---|
| プログラムの実体を見て検出する方法 | 各OSS取得段階において可能。 | 必ずしも可能とは限らない |
| パッケージ管理情報を見て検出する場合 | パッケージングおよびコンフィグレーション段階のみ。またパッケージ管理ツールが依存を認識しているパッケージのみ検出可能。 | 可能 |
#検出方法に関する考察
上記にまとめたとおり、各方法によって一長一短があります。そのため、検出ツールによっては(特に有償ツールにおいては)これらの検出方法を組み合わせるなどして、独自の改良がなされている場合もあります。こういった面に気付けるかどうかという意味でも、今回のような検出の一般的な仕様を把握しておくことは重要となるでしょう。
また上記の結果は「原理上こうなる」というもので、実際にはツールのアーキテクチャなどによって状況が異なってくる部分はあります。例えば、「パッケージ管理情報から一意にOSSを特定した後に、ツールが持つ自前のDBからサマリ情報を抽出して表示する」といったアーキテクチャのツールがあった場合、自前DBにそのOSSが登録されていなかった瞬間にサマリ情報を抽出および表示できないので、見た目上は「OSSを特定できなかった」と思われるでしょう。これ以外にも、実際に運用していく場面になった場合にはさまざまな検討事項が出てくるはずです。
いずれにしても、検出ツールの導入を考える場合には、自分たちがどのようにOSSを利用しているのか、検出はどのような仕様で行われているのか、このツールはどこまで検出をカバーできるのか、といった面をよく検討、調査し、全体として最適な方法を考えていくことが必要です。
#おわりに
今回「OSSの検出」という業務を行う上で必要になりそうな観点についてまとめました。一つの考え方として、参考にしていただければ幸いです。
また今回、「プロダクトが利用しているOSS」という観点について書いたわけですが、実を言うと「プロダクトが利用しているOSSが利用しているOSS」については取り上げていません(以下の赤枠部分)。
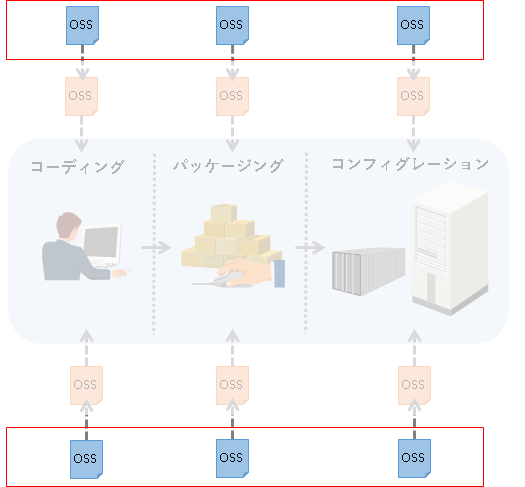
これらの部分についても、基本的には今回示した観点をそのまま流用できます。ですが、少し別の観点も必要になってきます。次に記事を書く機会があれば、こういった内容も含め、他のさまざまな観点についても考えられたらと思います。