今日のデジタル商戦において、データは企業競争力を左右する重要な経営資産の一つです。とくに Amazon や 淘宝(Taobao)といった EC プラットフォーム上の「競合価格」や「ユーザーレビュー」は、市場分析や戦略立案に欠かせない情報と言えるでしょう。
一方で、こうしたデータを取得しようとすると、CAPTCHA 認証や IP ブロック、動的レンダリングなどのアンチスクレイピング対策に直面するケースが少なくありません。
従来の手作業による情報収集は非効率なうえ、取得漏れやブロックのリスクも高くなりがちです。また、自社で本格的なスクレイピング基盤を構築しようとすると、インフラ整備や保守運用を含め、多大な開発コストと専門知識が求められます。
こうした課題に対する一つの選択肢として、Bright Data(亮数据)は、ノーコードで利用できる Web Scraper API と大規模なプロキシネットワークを提供しています。これにより、EC 事業者は複雑な実装を行うことなく、効率的かつコンプライアンスを意識した形で、必要な公開データを収集できるようになります。
1. なぜ Bright Data を選ぶのか?
従来のデータスクレイピングでは、Python や JavaScript といったプログラミング言語に加え、Scrapy や BeautifulSoup などのフレームワークを理解する必要があり、学習・導入コストが高くなりがちでした。
特に運用担当者やマーケターが自らデータ収集を行おうとすると、エンジニアリングの壁が大きな課題になります。
Bright Data の Web Scraper API は、こうした複雑な実装を、可視化された UI と設定ベースの操作に置き換える設計になっています。収集ルールやアンチボット対策をコードを書かずに定義できるため、プログラミング経験がない場合でも、比較的スムーズにデータ収集を始められる点が特徴です。
1.1 グローバルプロキシを前提とした設計
現在、多くの Web サイトでは IP ブロックや CAPTCHA、行動分析によるアクセス制御など、さまざまなアンチボット対策が導入されています。そのため、単純なクローリング手法では、安定したデータ取得が難しいケースも少なくありません。
Bright Data は、住宅プロキシ・データセンタープロキシ・モバイルプロキシといった複数タイプのプロキシを組み合わせたグローバルネットワークを基盤としており、IP のローテーションや実ユーザーに近いアクセス挙動を前提とした収集が可能です。
また、CAPTCHA の検知や JavaScript による動的レンダリングページへの対応なども含まれており、制限の影響を受けにくい構成になっています。
1.2 構造化されたデータ出力による後工程の軽減
一般的なクローラーで取得したデータは、HTML が混在していたり、不要な情報が多かったりと、後処理に手間がかかることが少なくありません。
そのため、実際の分析に入る前段階で、クレンジングや整形に多くの工数を割く必要があります。
Bright Data の Web 収集ツールでは、データ取得と同時に一定の構造化処理が行われ、比較的整理された形式で出力されます。これにより、後続の分析や可視化工程にスムーズに接続でき、全体の作業効率を高めやすくなります。
1.3 ノーコード前提のデータ収集環境
従来のスクレイピングは、プログラミングに加えて HTML 構造の理解や Cookie 管理、ログイン処理の再現など、多くの専門知識を必要としてきました。さらに、サイト構造の変更や対策強化のたびに、継続的な修正作業が発生します。
Bright Data が提供する Web Scraper IDE などの可視化ツールでは、これらの作業を GUI ベースで構成できるため、非エンジニアでも扱いやすい設計になっています。
エンジニア依存を減らしつつ、データ収集の内製化やスピード向上を目指す場合の一つの選択肢として検討しやすい点が特徴と言えるでしょう。
2. Bright Data Web MCP Server 概要
Bright Data Web MCP Server は、Webデータや音声・動画といったメディアデータを、AIモデルから扱いやすい形で提供するための MCP(Model Context Protocol)対応サーバーです。
YouTube、TikTok、Instagram などの主要プラットフォームを対象に、動画メタデータや字幕、広告関連データなど、マーケティングや分析用途で利用される情報を幅広くカバーしています。
提供される API には、動画検索、関連コンテンツの取得、チャンネル単位のパフォーマンス分析、広告データの取得、字幕抽出などが含まれており、外部データを AI から利用するためのインターフェースが一通り揃っています。
MCP Server は、AI と外部メディアデータを接続するための 共通の接続口 として位置づけられます。
2.1 従来の収集方式における課題
動画・SNS プラットフォームのデータを継続的に取得する場合、以下のような課題に直面しがちです。
-
技術的な難易度が高い
CAPTCHA、IP ブロック、User-Agent 検知などへの対応が必要 -
運用が不安定になりやすい
HTML 構造や API 仕様の変更によって、既存の取得ロジックが頻繁に破綻する -
自動化しづらい
非構造データや例外処理が多く、人手による補正が入りやすい
これらは、AI エージェントと組み合わせて継続的にデータ活用を行う際のボトルネックになりやすい部分です。
2.2 MCP Server をデータ連携レイヤーとして使う意義
MCP Server を介することで、こうした課題を個別実装 ではなく共通インターフェースとして吸収できます。
-
リアルタイム性を意識したデータ取得
ライブ配信、VOD、ショート動画などを対象に、更新頻度の高いデータにも対応 -
AI エージェントとの親和性
構造化されたデータ形式で提供されるため、Dify や LangChain などからそのまま扱いやすい -
スケーラブルな設計
データ取得量の増減に応じてスケールしやすく、運用負荷を抑えやすい
結果として、AI 側は「どこから・どうやって取得するか」を意識せずに、メディアデータを前提とした分析や生成タスクに集中できるようになります。
3. Bright Data MCP によるリアルタイム音声・動画データ取得
AI エージェントの活用が進む中で、音声・動画といったメディアデータをリアルタイムに扱う重要性は年々高まっています。
コンテンツ制作、市場分析、ユーザー行動の把握、競合調査など、動画プラットフォームに蓄積されるデータは、AI にとって有用な情報源の一つです。
Bright Data MCP は、こうしたメディアデータを AI から扱いやすい形で取得するための仕組みを提供しており、リアルタイム性を求められるユースケースにも対応可能な構成となっています。
3.1 リアルタイムメディアデータが持つ意味
動画・音声データを継続的に収集・分析することで、以下のような活用が考えられます。
-
市場動向やトレンドの把握
YouTube や TikTok 上の人気動画、コメント、エンゲージメント指標を追跡することで、話題の変化やユーザー関心の移り変わりを把握 -
ユーザー行動の分析
視聴時間やインタラクション傾向などを基に、レコメンドやパーソナライズ施策の精度向上に活用 -
コンテンツ制作の改善
タイトルや構成、投稿タイミングなどの傾向分析を通じて、データに基づいた改善のヒントを得る
リアルタイム性のあるデータは、過去分析 だけでなく即時の意思決定にも活用しやすい点が特徴です。
3.2 Bright Data MCP の特徴
Bright Data MCP は、複数の動画・SNS プラットフォームを対象としたデータ取得を、共通インターフェースで扱える点が特徴です。
-
複数プラットフォームへの対応
YouTube、TikTok、Instagram、Twitch などを対象に、メタデータ、コメント、チャンネル情報、ライブ関連データを取得可能 -
動的コンテンツへの対応
JavaScript による動的レンダリングや、スクロールで追加読み込みされる要素、リアルタイム更新される数値データなどを考慮した設計 -
スケールを意識した構成
大量リクエストが発生するケースでも、安定した取得を前提とした仕組みを備えている
これにより、個別にクローラーを実装・保守する場合と比べ、運用負荷を抑えやすくなります。
3.3 取得可能なデータと想定ユースケース
- 動画関連データ
- タイトル、説明文、タグ、動画長、解像度
- 再生数、いいね数、コメント数などの統計情報
- チャンネル情報(投稿履歴、登録者数など)
- 字幕・テキストデータ(多言語対応)
- ユーザーインタラクション
- コメント内容
- インタラクションの発生傾向
- ユーザー行動に関するメタ情報
- マネタイズ・広告関連データ
- 広告表示に関する情報
- ブランドタイアップや商品露出の検知
- ライブコマースやアフィリエイト関連指標
【活用例】
- レコメンド補助:視聴傾向と人気コンテンツを組み合わせた提案
- SNS マーケティング分析:競合や市場の動きを継続的に観測
- トレンド分析:一定期間のデータから話題の兆しを検出
- ユーザープロファイル分析:複数プラットフォームの情報を統合した傾向把握
3.4 AI フレームワークとの連携
Bright Data MCP は、Dify や LangChain、Claude などの AI フレームワークから利用できることを前提に設計されています。
標準化されたインターフェースを通じて外部メディアデータを取得できるため、AI 側ではデータ取得の実装詳細を意識せずに、分析や生成処理に集中しやすくなります。
結果として、スクレイピング基盤の構築や保守にかかるコストを抑えつつ、AI を活用した機能開発や検証を進めやすい構成といえます。
4. 技術実装
本節は、Bright Data MCP と Dify を連携させるまでの一連の流れを、できるだけシンプルな形で整理します。
専門的な実装を前提とせず、全体像を把握しながら進められるよう、操作フローを段階的に分けて説明します。
構成は以下の3ステップです。
- 環境構築:必要なサービスや設定の準備
- フロー設計:Dify 上でのエージェント・処理フローの構成
- 動作確認:実際にデータを取得し、想定どおり動くかを確認
それぞれの工程で どこを設定し、何ができるようになるのか を意識しながら進めていきます。
細かなカスタマイズは行わず、まずは MCP 連携の基本的な使い方を理解することを目的としています。
4.1 基礎環境構築
このセクションでは、Bright Data MCP と Dify を連携させるための基本的な環境準備を行います。
ここでの設定が正しくできていないと、後続のフローが動作しないため、一つずつ確認しながら進めるのがおすすめです。
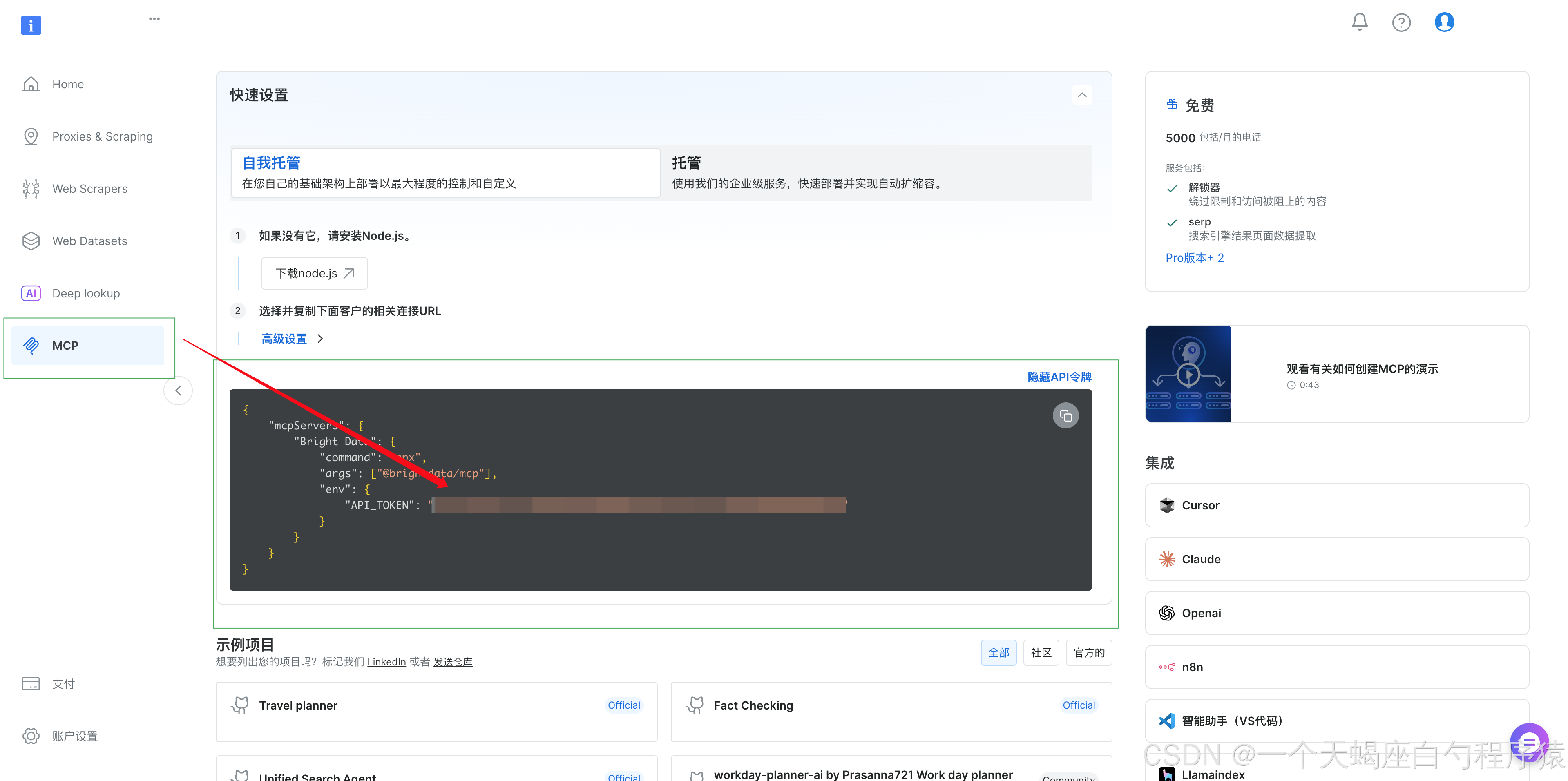
4.1.1 Bright Data API 資格情報の取得
まずは、Bright Data 側で API を利用するための認証情報を準備します。
手順:
- Bright Data公式サイトにアクセスし、アカウントを作成
- メール認証と基本情報の入力を行い、アカウントを有効化
- アカウント設定画面の「ユーザーとAPIキー」タグから APIキーを取得
- Web Scraper API および MCP Server へのアクセス権が付与されていることを確認
補足
取得した API Token は認証情報そのものになるため、GitHub リポジトリや公開設定ファイルに直接書き込むのは避け、環境変数で管理することを推奨します。
4.1.2 Dify プラットフォーム設定
続いて、Dify 側に Bright Data MCP プラグインを導入します。
Bright Data MCP プラグインのインストール手順:
- Dify にログインし、対象のワークスペースを開く
- 「プラグイン管理」または「ツールマーケット」を選択
- Bright Data MCP プラグインを追加

【注意事項】
- 現在、Bright Data MCP プラグインはオンラインマーケットからの直接インストールには対応していません
- 公式経路から取得したプラグインパッケージを、ローカルアップロードで導入する必要があります
- 事前に、利用中の Dify バージョンとの互換性を確認してください
- インストール後、設定を反映させるために関連サービスの再起動が必要な場合があります
4.1.3 環境の動作確認
最後に、ここまでの設定が正しく完了しているかを確認します。
チェックリスト:
- ✅ Bright Data の API Token が取得済みで、有効である
- ✅ Dify に正常にログインできる
- ✅ Bright Data MCP プラグインがインストール済み
- ✅ プラグインの状態が「有効」になっている
- ✅ ネットワーク経由で Bright Data API に接続可能
よくあるつまずきポイント:
- ❌ API Token エラー:コピー漏れや期限切れがないか確認
- ❌ プラグインが反映されない:ファイル破損や Dify バージョン不一致をチェック
- ❌ 通信エラー:Firewall やネットワーク制限の影響がないか確認
4.2 フロー構築
ここからは、実際に AIエージェントがどのようにデータを処理していくのか を定義していきます。
Dify のワークフロー機能を使い、メディアデータの取得から分析・出力までを一連の流れとして構築します。
各処理をノード単位で分離することで、
- 処理の役割が分かりやすい
- 後から修正・拡張しやすい
といったメリットがあり、実運用を見据えた設計になります。
4.2.1 ワークフロー全体の流れ
今回構築するワークフローは、次のようなシンプルな構成です。
- 入力:開始ノードで、分析対象となる動画やチャンネルのURLを受け取る
- 収集:Bright Data MCP プラグインを使って、対象ページの構造化データを取得
- 分析:LLM が取得したデータをもとに、要点抽出や傾向分析を実行
- 出力:分析結果を、読みやすい形式でユーザーに返却
「URLを渡すだけで、裏側ではここまで処理されている」という状態を目指します。
4.2.2 各ノードの設定内容
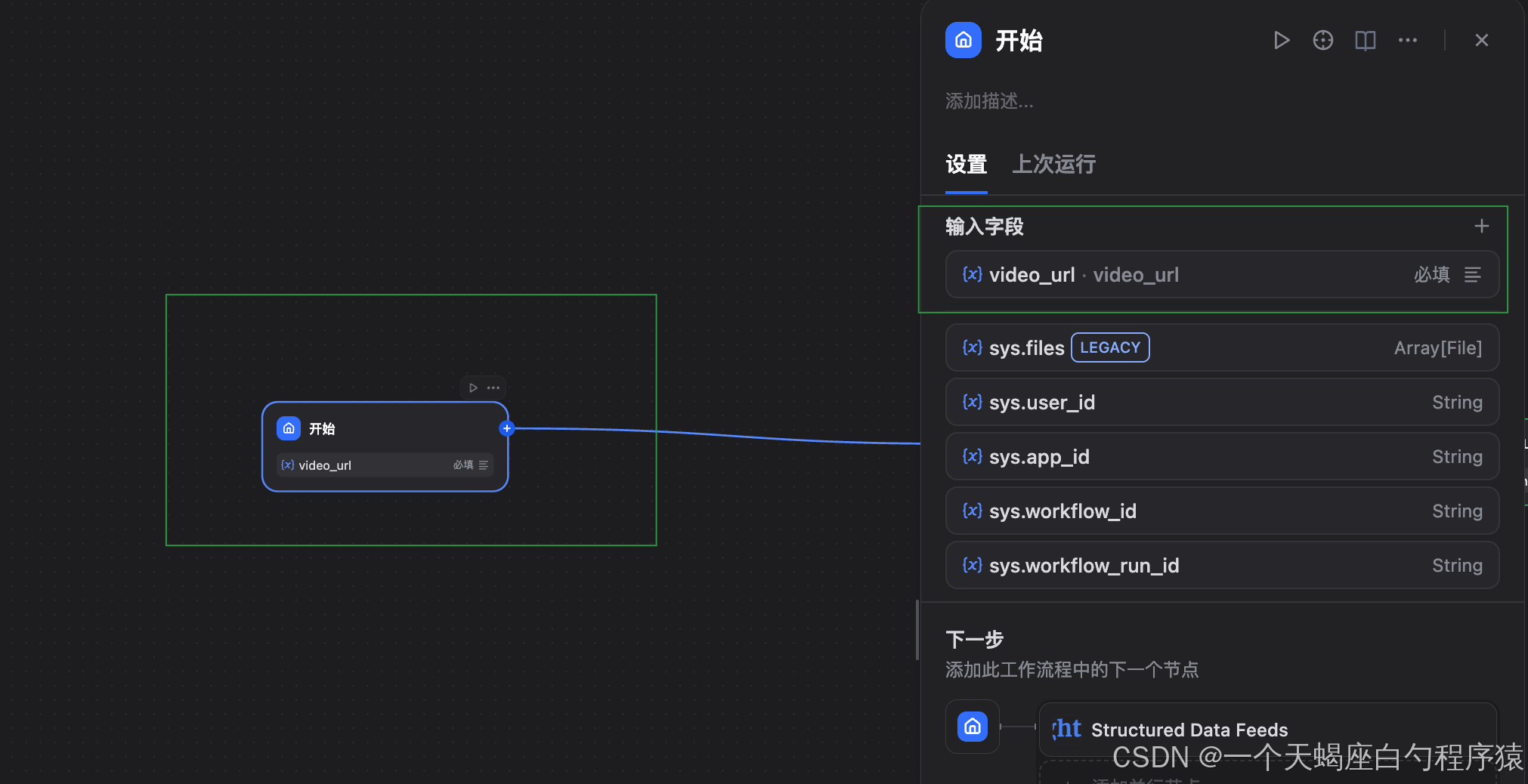
ステップ1:開始ノード(入力の定義)
まずは、ワークフローの起点となる開始ノードを設定します。
ここでは、ユーザーから「分析対象のURL」を受け取る設計にします。
【主な設定項目】
- パラメータ名:
video_url(必須) - データ型:String(URL)
- 検証:URL形式が正しいこと。YouTube / TikTok 等の主要プラットフォームに対応
- 例示:ユーザー向け入力例を提示
入力例:
- YouTube動画:
https://www.youtube.com/watch?v=xxxxx - YouTubeチャンネル:
https://www.youtube.com/@username - TikTokユーザー:
https://www.tiktok.com/@username - Instagramアカウント:
https://www.instagram.com/username/
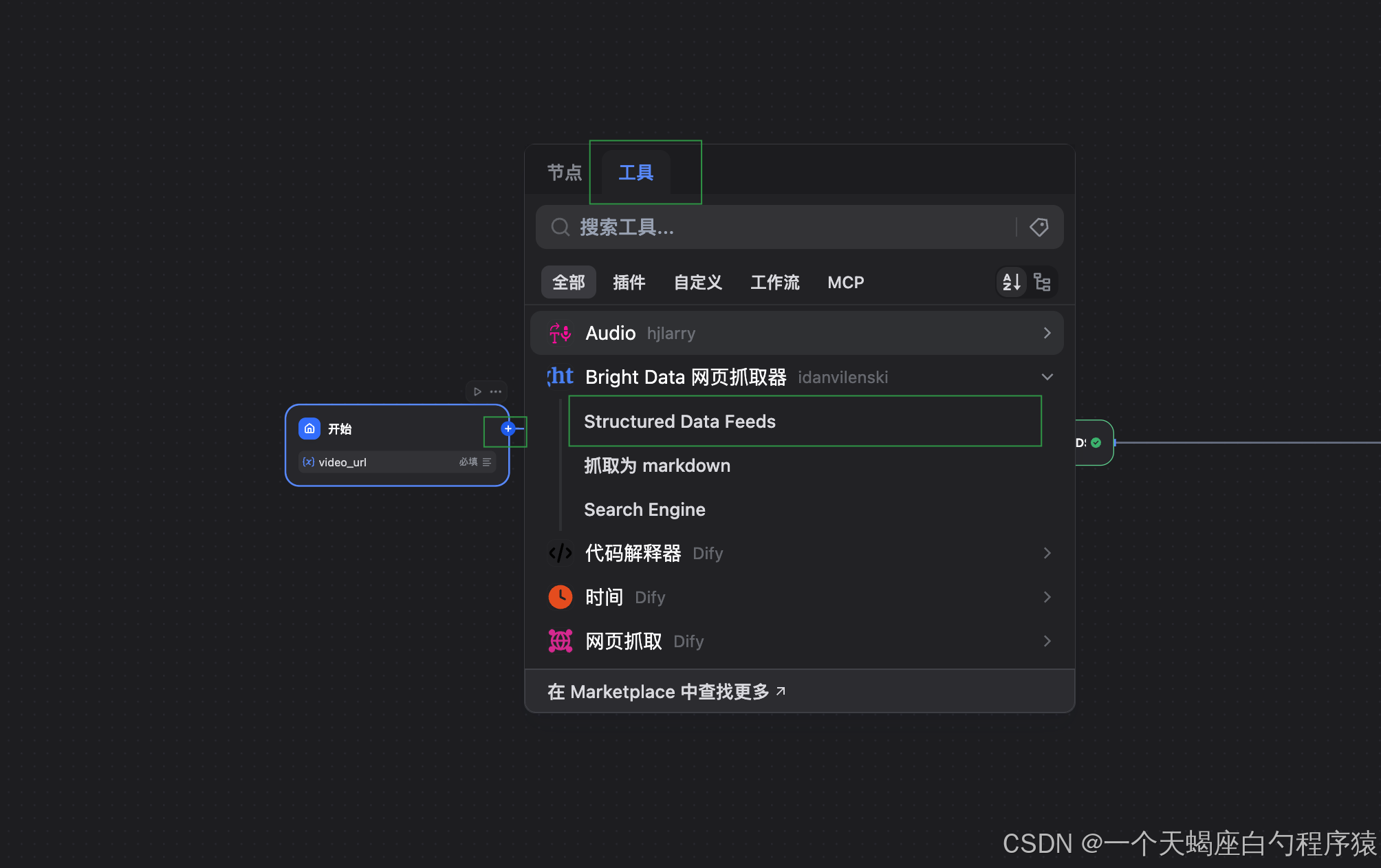
ステップ2:Bright Data MCP ノード
このノードが、ワークフロー全体の中核です。
Bright Data MCP を通じて外部 Web にアクセスし、対象URLから 高品質かつ構造化されたデータ を取得します。
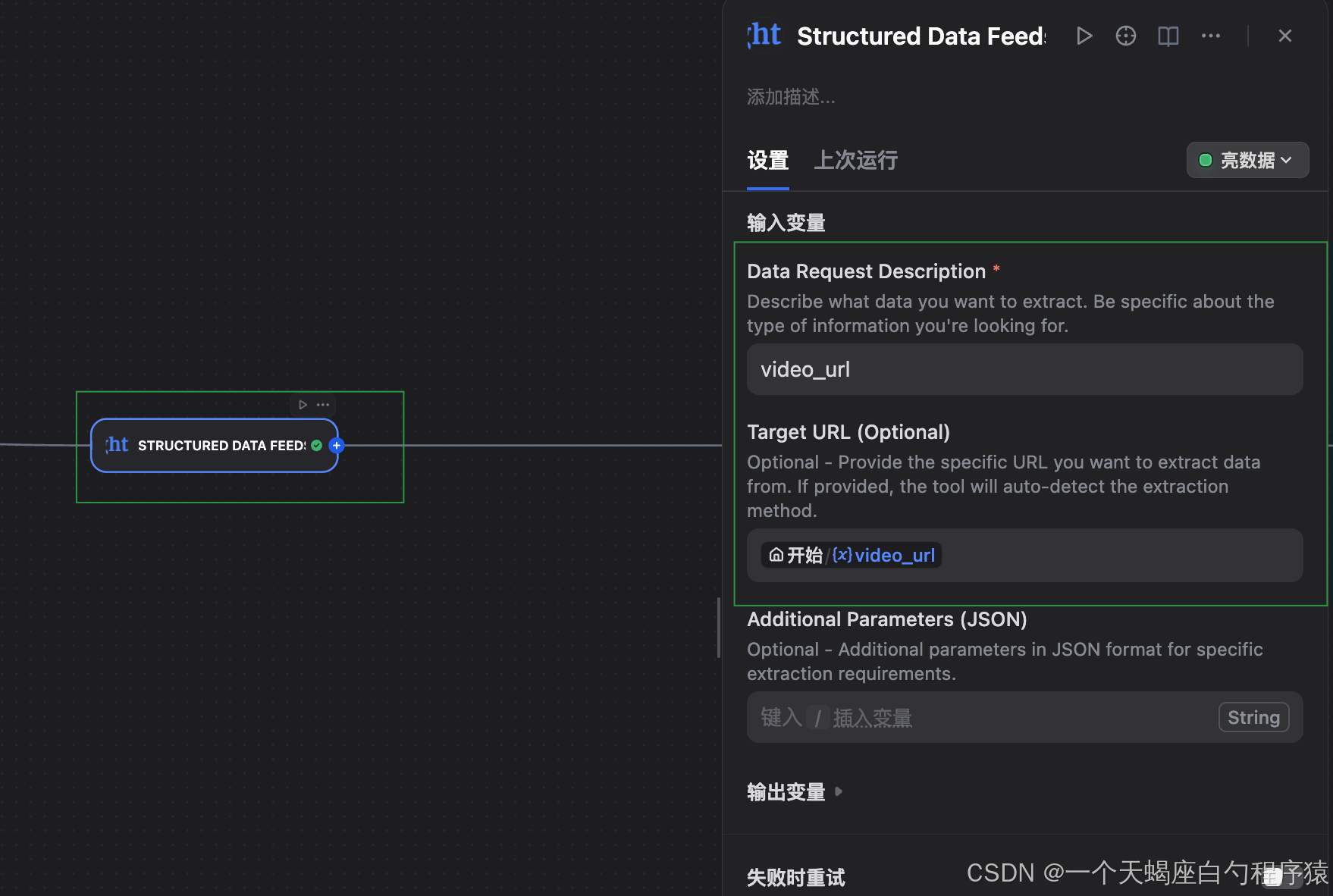
主な設定:
-
API認証
- Token:4.1で取得した Bright Data API Token
- 認証方式:Bearer Token
- タイムアウト:30〜60秒を推奨
-
データソース指定:
- URL:開始ノード変数
{{#sys.query.video_url#}}を参照 - プラットフォーム判定:URLから自動判別
- データ深度:取得する情報量(必要に応じて調整)
- URL:開始ノード変数
主な取得対象データ:
- 基本メタデータ(タイトル、説明文、投稿日、動画長など)
- 各種統計情報(再生数、いいね数、コメント数、シェア数など)
- チャンネル情報(作成者プロフィール、登録者数、認証有無など)
- コンテンツ解析情報(タグ、カテゴリ、言語判定など)
URLを渡すだけで、これらの情報が整った形でまとめて取得できるのが、このノードの役割です。
ステップ3:LLM分析ノード(インサイト抽出)
次に、Bright Data MCP で取得した生データを、人が読んで理解できる分析結果 に変換する工程です。
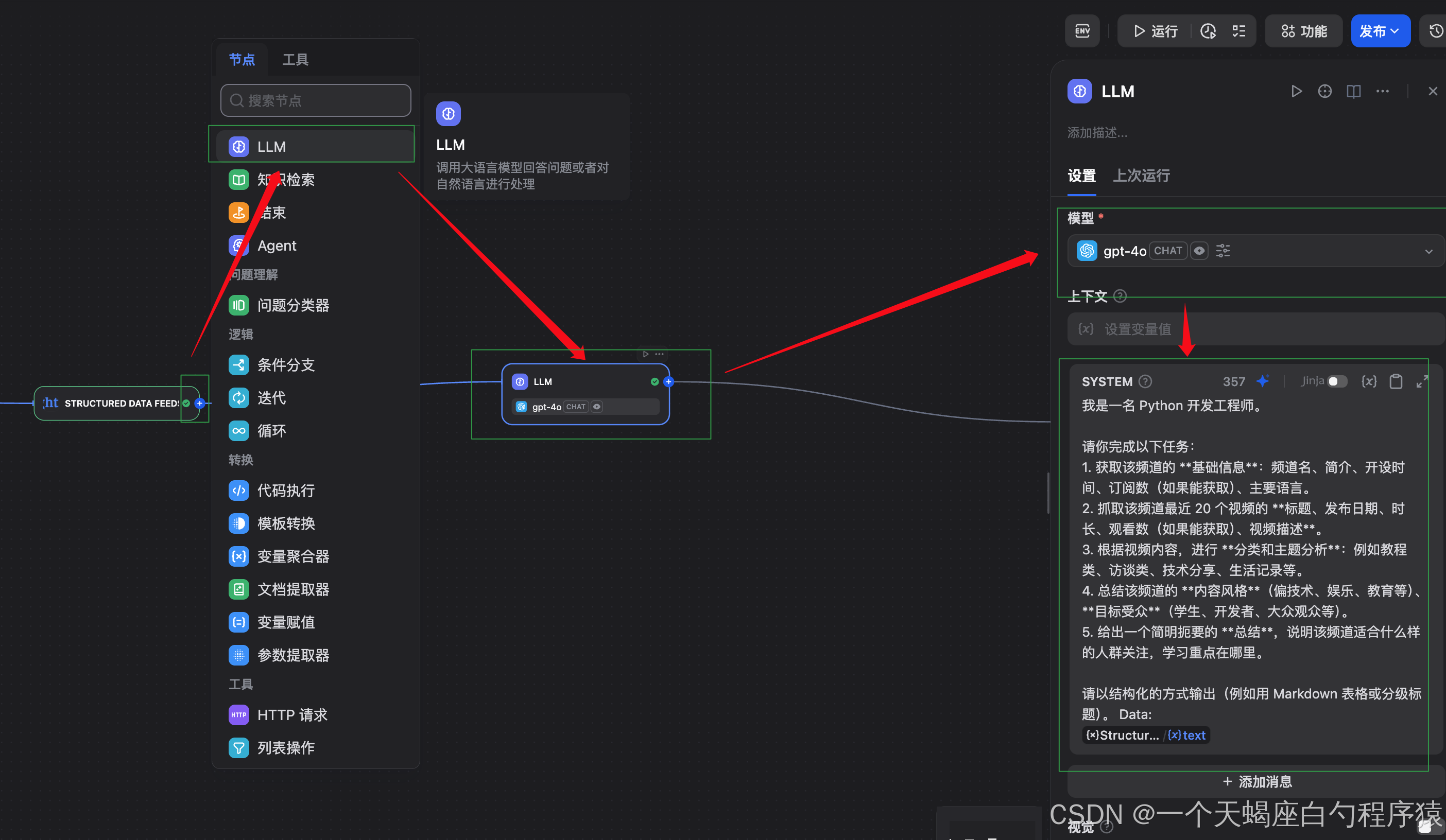
ここでは LLM に対して、「どんな観点で、どこまで分析してほしいか」を明示的に指示します。
Prompt例(一例):
私は Python 開発エンジニアです。
以下のタスクを実行してください。
- このチャンネルの基礎情報(チャンネル名、概要、開設時期、登録者数、主要言語)
- 直近20本の動画について、タイトル・公開日・長さ・視聴数・説明文を整理
- 動画内容をもとに、テーマやカテゴリを分類
- コンテンツの傾向(技術寄り/教育/娯楽など)と想定ターゲット層を要約
- 最後に「どんな人に向いているチャンネルか」を簡潔にまとめる
出力は Markdown 形式で、見出しや表を使って構造化してください。
このように指示することで、単なる要約ではなく「使える分析レポート」 が得られます。
ステップ4:終了ノード(標準化出力)
最後に、ワークフローの出力を整理します。
【出力内容の例】
- 構造化データ(JSON):元データとして再利用可能
- 分析レポート(Markdown):そのまま資料やメモとして活用
- 抽出指標(KPI):再生数・傾向・特徴
- 推奨アクション:分析結果に基づく示唆

4.2.3 フロー最適化のポイント
実運用を想定すると、以下の工夫を入れておくと安定します。
パフォーマンス面:
- 複数URLを扱う場合は並列処理を活用
- 重複分析を防ぐため、結果キャッシュを導入
- 失敗時のリトライや例外処理を追加
データ品質面:
- 開始ノードでのURL検証を強化
- 取得データの重複・欠損チェック
- 出力結果の妥当性確認(空データ対策)
4.3 実戦例①:YouTube チャンネルを深掘り分析してみる
4.3.1 対象チャンネル
【選定理由】
- 技術系コンテンツで構造が明確
- 一定数の動画と登録者があり、分析しやすい
- テーマが分散しすぎておらず、検証に向いている
4.3.2 実行手順
- Dify の開始ノードにチャンネルURLを入力
- Bright Data MCP が自動でデータ収集
- LLM が内容を分析
- 構造化されたレポートを出力
4.3.3 実行結果
-
データ収集成功画面

-
分析レポート出力
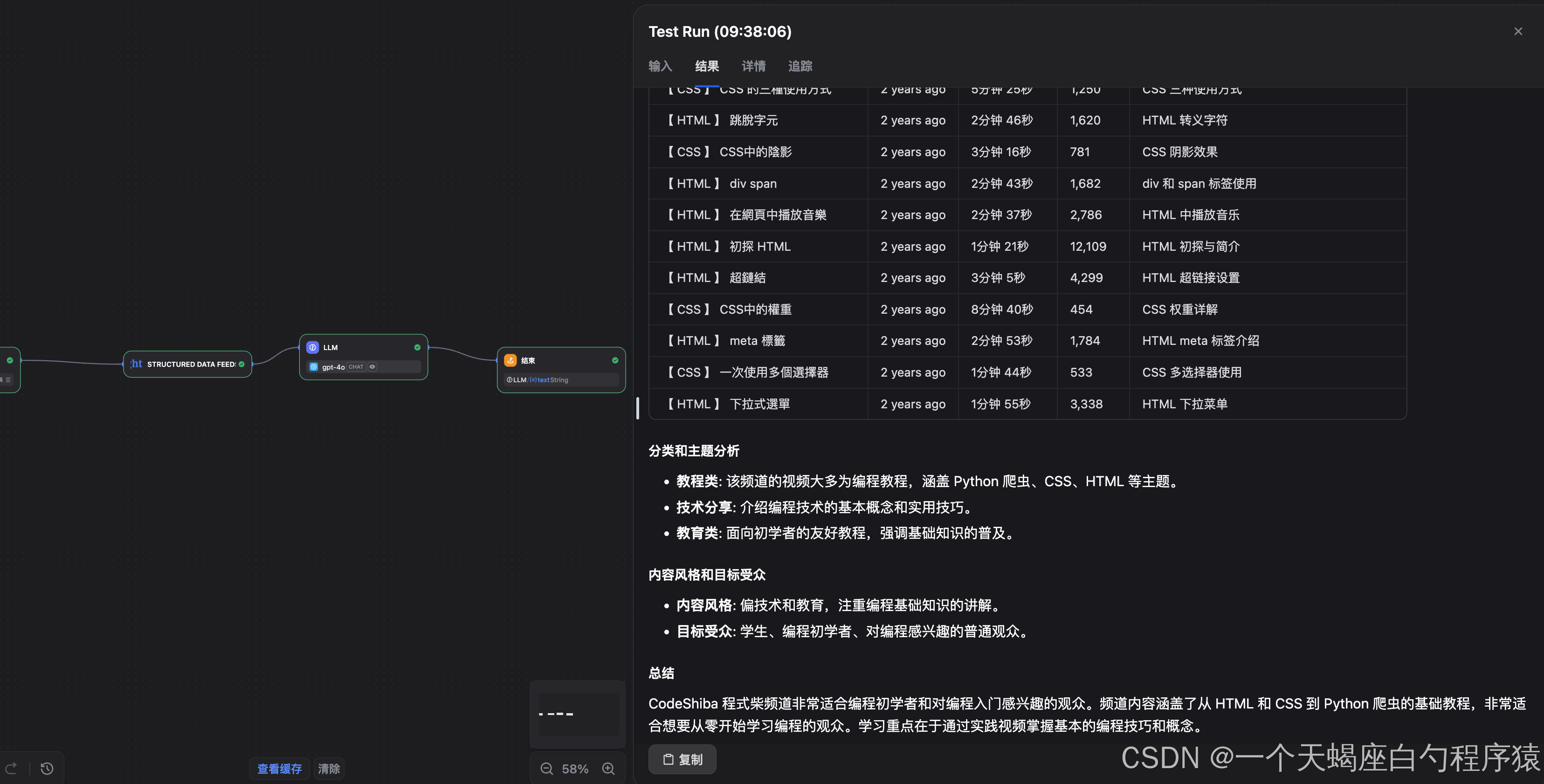
4.3.4 品質評価
評価結果として良かった点:
- データの網羅性
チャンネル基本情報から動画一覧、各種統計指標まで、必要な情報を過不足なく取得できている。 - 分析の深さ
単なる数値の列挙にとどまらず、コンテンツ分類や想定オーディエンス像まで踏み込んだ分析が行われている。 - 出力の読みやすさ
指定した Prompt に沿った構造化出力で、そのまま資料として利用できる形式になっている。 - 実務への活用可能性
チャンネルの特徴やポジショニングが明確になり、マーケティングや競合調査に活かしやすい。
正確性の確認結果:
- ✅ 登録者数が実際の数値と一致
- ✅ 動画の公開日が正確
- ✅ 再生数などの主要指標に大きな乖離なし
- ✅ コンテンツ分類・テーマ判断も妥当
実務利用を想定しても、十分に信頼できる精度であることが確認できました。
4.4 実戦例②:TikTokクリエイター分析
続いて、同じワークフローを用いてTikTokクリエイターの分析を行い、プラットフォームが変わっても問題なく機能するかを検証します。
操作フローは YouTube の場合と 完全に同一 で、
特別な設定変更を行わずに実行できる点が、MCPの大きな特徴です。
4.4.1 ケース選定
対象アカウント:代表的なTikTokクリエイターを選定
選定理由:
- TikTokは世界的に影響力の大きいショート動画プラットフォーム
- YouTubeとは異なるデータ構造・指標を持ち、汎用性を検証しやすい
- コンテンツ形式が多様で、分析の柔軟性を確認できる
4.4.2 実行手順
- 開始ノードに TikTok のアカウントURLを入力
- Bright Data MCP によるデータ収集
- LLM による内容分析
- TikTok向けの構造化レポートを出力
4.4.3 実行結果
- TikTok分析成功画面
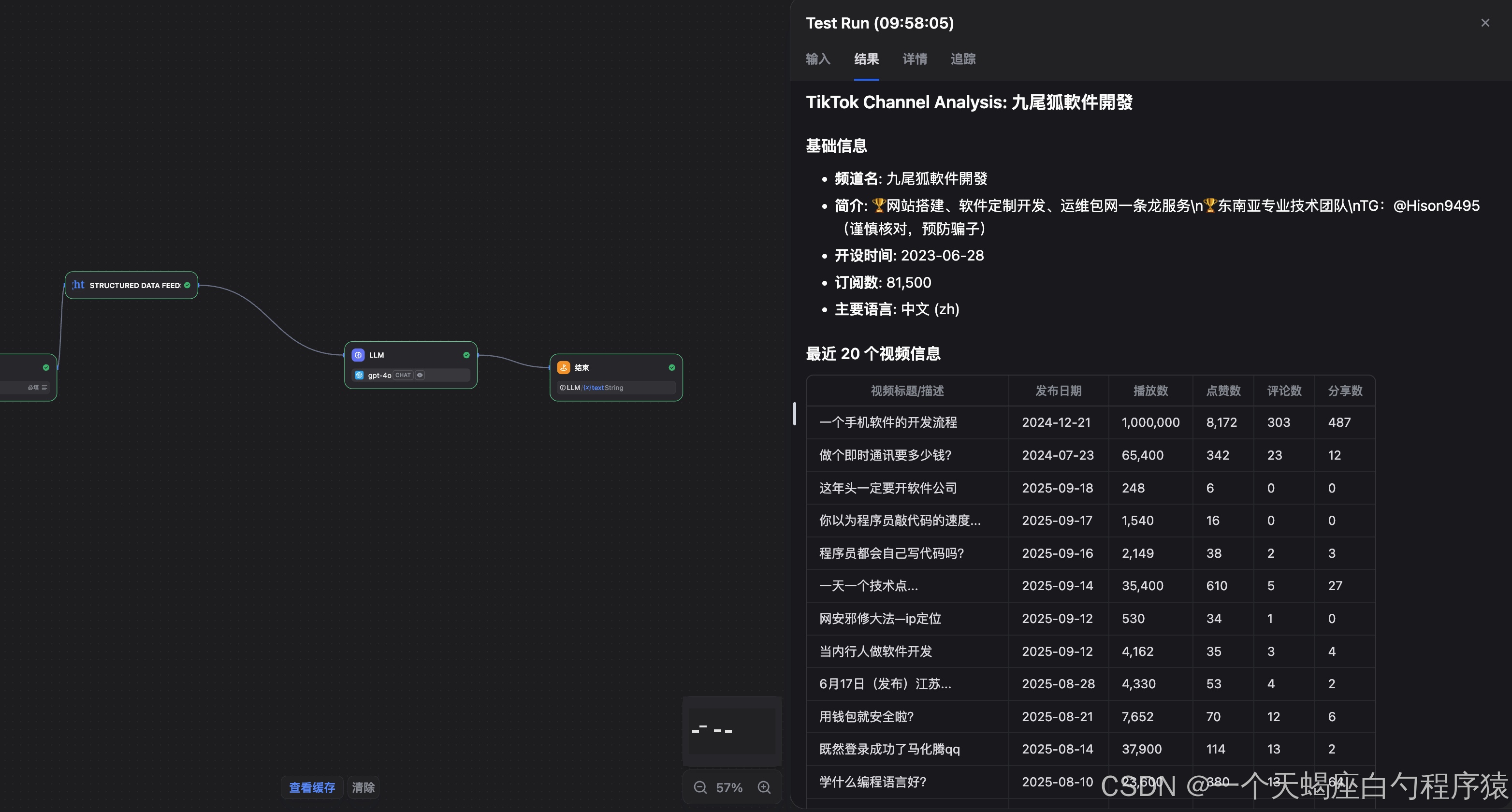
4.4.4 品質評価
プラットフォーム互換性の観点:
-
取得精度
アカウント基本情報、投稿一覧、エンゲージメント指標を安定して取得。 -
特性理解
TikTok特有のフォーマットや挙動を自動的に認識。 -
分析の適応性
YouTubeとは異なる視点(拡散性・ショート動画特性)で分析が行われている。 -
出力の一貫性
プラットフォームが変わっても、同じ構造のレポート形式を維持。
TikTok特有要素への対応:
-
✅ ショート動画中心の特性を反映した分析
-
✅ いいね/シェア/転送などの指標を適切に取得
-
✅ 音源・エフェクト・チャレンジタグといった要素を認識
-
✅ TikTokのレコメンド・拡散メカニズムを考慮した解釈
5. 技術的ハイライト
5.1 柔軟な出力とデリバリー
Bright Data は、JSON や CSV などの構造化フォーマットに対応しており、Webhook や API 経由でデータを取得できます。
出力形式は JSON / NDJSON / CSV / XLSX から選択可能で、既存のワークフローや分析基盤に無理なく組み込めるのが特長です。
「収集して終わり」ではなく、そのまま分析・連携に使える形で受け取れる点が、実務では大きなメリットになります。
5.2 高速なデータ処理
バッチ処理に対応しており、1回のジョブで最大5,000URL を処理可能。さらに並列取得数に制限がないため、大規模データ収集にも対応できます。
また、インテリジェントなデータ発見機能により、
- ページ構造やパターンを自動認識
- HTMLを高速に構造化データへ変換
- 抽出ルール設計を最小限に削減
といった処理を自動化。
収集 → 整形 → 分析 の工程を一気通貫でシンプルにし、生産性を大幅に向上させます。
5.3 複数ツールの統合
Bright Data は、数十種類のデータ取得ツールをネイティブに統合しています。
用途に応じて SERP、EC、SNS、動画、レビューなどを横断的に扱えるため、ツールを切り替える手間がほぼありません。

5.4 安定性とスケーラビリティ
世界トップクラスのプロキシ基盤を活用することで、障害率を極めて低く抑えた安定したデータ取得を実現しています。
トラフィック増加や対象サイト拡大にも柔軟に対応でき、収集規模のスケールも容易です。
さらに、
- プロキシ管理不要
- 自動ブロック解除
- CAPTCHA 回避
といった仕組みが内蔵されており、インフラ運用を意識せずにデータ収集に集中できる点も大きな強みです。
5.5 コンプライアンス
Bright Data は、グローバル初となる多国籍・多言語対応のコンプライアンス・倫理専門チームを擁しています。
各国の法規制やプラットフォームポリシーの変化を継続的に監視し、常にベストプラクティスを反映した運用が可能です。

6. Bright Data の SERP API
Bright Data の SERP API は、検索エンジンデータ取得に特化した専用 API です。
Google / Bing / DuckDuckGo など主要検索エンジンの構造変更やアルゴリズム更新にも自動追従し、安定したデータ取得を実現します。
主な特長は以下の通りです。
-
高速レスポンス
ミリ秒単位で JSON / HTML を返却し、ピーク時でも大量リクエストを安定処理 -
スマートクローリング
検索条件、端末、地域、ユーザー行動を考慮した実ユーザー挙動を再現し、ブロックを回避 -
コスト効率と運用のしやすさ
成果課金(成功リクエストのみ課金)モデルを採用し、無駄なコストを抑制
検索データを「安全かつ継続的に取得したい」ケースでは、非常に実用性の高い選択肢です。
7. まとめ
Bright Data Web Scraper API は、ノーコードを軸にデータ収集の技術的ハードルを大きく下げ、非エンジニアでも実用レベルのデータ取得を可能にするプラットフォームです。
強力なアンチボット対策と高い汎用性により、EC、SNS、動画、検索など幅広いシーンに対応しています。
APIキー作成からジョブ実行、分析までの一連の流れも直感的で、導入・運用の負担が最小限に抑えられています。
ビジネス担当者、データアナリスト、起業家など立場を問わず、データを素早く集め、意思決定に活かしたい 人にとって、有力な選択肢となるでしょう。
今後の継続的な機能拡張により、ノーコード × 高品質データ収集はさらに一般化し、Bright Data は DX 時代の標準的なデータ基盤として存在感を高めていくはずです。