この記事は、「#日めくりLayerX」と題して発信するブログリレーの2025年7月7日の記事として投稿しています。7月はAI・LLM事業部(Ai Workforce)の集中月間です!「私のUUID愛を語る」というテーマに沿ってお送りします。
せっかくの七夕(令和7年7月7日)なので、UUID v7について語ります。
ソフトウェア開発において、ユニークな識別子(ID)の生成は避けて通れない課題です。データベースの主キー、分散システムでのメッセージID、ログトレース等々、その用途は多岐にわたります。古くからある連番ID、GUID、そして今回取り上げるUUIDなど、様々なID生成方式があります。今回はUUIDの歴史を振り返りつつ、UUID v7に焦点を当てていきたいます。
なぜUUIDが必要か?
なぜUUIDのようなグローバルにユニークな識別子を必要とするのでしょうか?
従来のシステムでは、データベースのオートインクリメント機能などを用いて連番IDを生成することが一般的でした。これはシンプルで分かりやすい反面、以下のような課題を抱えています。
- 分散環境での衝突: 複数のサーバやサービスで並行してIDを生成する場合、連番IDでは衝突(重複)のリスクがあります
- 水平スケーリングの困難さ: データベースのシャーディングなどを行う際、連番IDの一意性を保証するのが難しくなります
- 情報漏洩のリスク: 連番IDは次のIDを推測しやすいため、悪意のあるユーザーによってデータ件数や登録順序などを推測される可能性があります
UUIDがもたらす解決策
UUID(Universally Unique Identifier)はこれらの連番IDの課題を解決するために考案された128ビットの識別子です。その名の通り、「普遍的に(Universally)」、「一意な(Unique)」識別子であり、極めて低い確率でしか衝突しないことが保証されています。
UUIDの導入により、以下のようなメリットが得られます。
- 分散環境での一意性保証: 複数のノードやサービスが独立してUUIDを生成しても、IDが重複する可能性は事実上ゼロに近いです
- 水平スケーリングの容易さ: ID生成が中央集権的なボトルネックとならず、システムをスケールアウトしやすくなります
- 情報漏洩リスクの軽減: UUIDはランダム性が高いため、IDから情報が推測されるリスクが極めて低いと言われています
- データの統合の容易さ: 異なるシステム間でUUIDを使用しても衝突の心配がないため、データの統合が容易になります
UUIDの歴史と進化 - 各バージョンを紐解く
UUIDは、その進化の過程で様々なバージョンが策定されてきました。主要なバージョンであるv1, v4, v5, v6, v7について解説します。
UUIDは、RFC 4122で標準化され、RFC 9562で拡張されており、 xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx の形式で表現されることが多いです。ここで、 M はUUIDのバージョンを示し、 N はバリアント(RFC 4122では常に 10xx の形式)を示します。
各バージョンの仕様は以下のようになります。
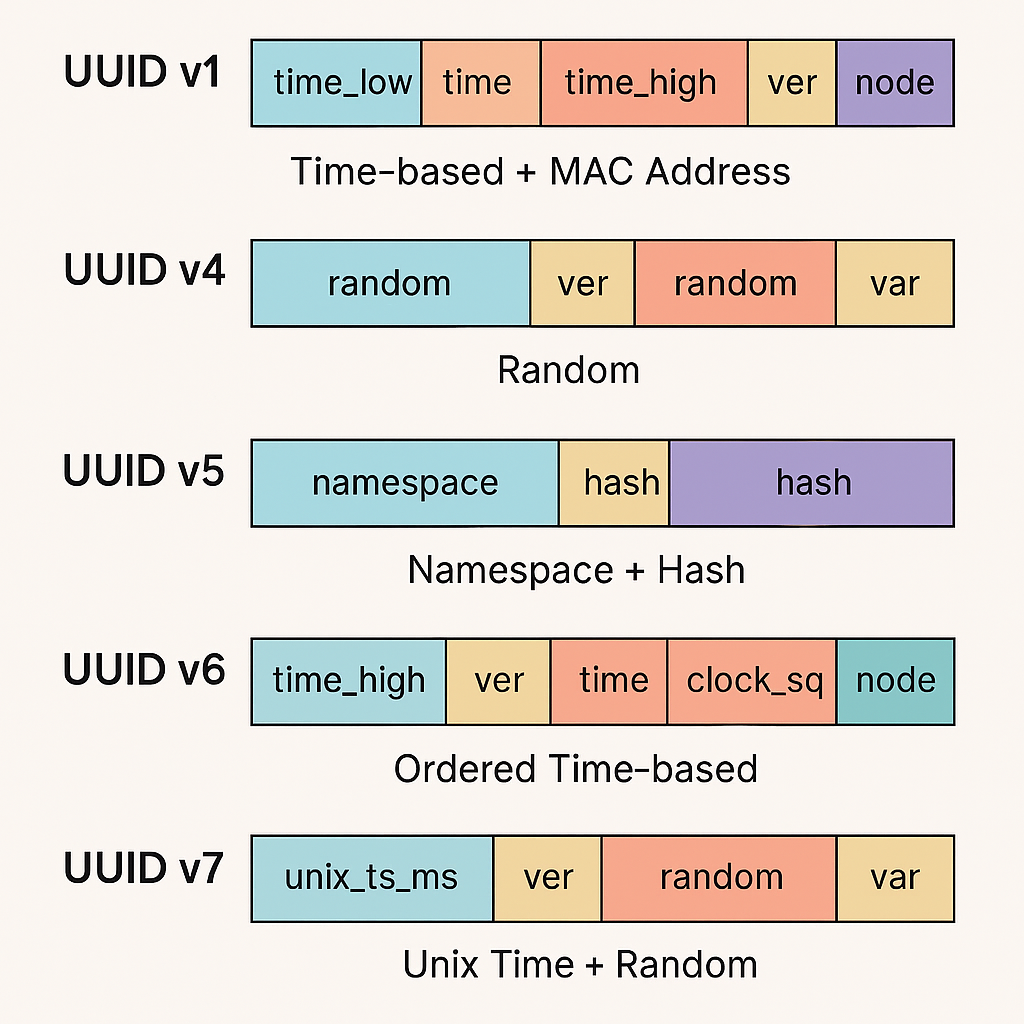
UUID v1: タイムスタンプとMACアドレス
UUID v1は、タイムスタンプとネットワークカードのMACアドレスに基づいて生成されます。
- 生成日時を推測可能
- MACアドレスが含まれるため、生成元を特定できる可能性あり
- 時間順にソート可能(ただし、ミリ秒以下の精度は保証されない)
- 用途: MACアドレスが外部に漏洩しても問題ない環境や、生成元を特定したい場合に利用
- トレードオフ: MACアドレスが含まれるため、プライバシー上の懸念がある場合や、仮想環境でMACアドレスが一意でない場合に問題となることがある
UUID v4: 純粋なランダム性
UUID v4はほとんどが乱数で構成されます。
- 高いランダム性により、衝突の可能性が極めて低い
- 生成日時や生成元などの情報を含まないため、プライバシー保護に優れる
- 用途: 特別な情報を含まず、単に一意なIDが必要な場合に広く利用
- トレードオフ:
- 完全にランダムなため、生成順序とソート順序に関連性がない。データベースのインデックス効率が悪くなる可能性がある(特にB-treeインデックス)
- データの局所性がないため、キャッシュ効率が悪くなることがある
UUID v5: 名前空間とハッシュ
UUID v5は、名前空間(Namespace)と入力文字列のSHA-1ハッシュに基づいて生成されます(v3はMD5ハッシュを使用)。
- 同じ名前空間と入力文字列からは、常に同じUUIDが生成(決定論的)
- 特定の情報から一意のIDを生成したい場合に有用
- 用途:
- ドメイン名やURLなど、特定の識別子から一意かつ永続的なIDを生成する場合
- 例えば、DNSのUUIDやURIのUUIDなどに利用
- トレードオフ: 入力情報が変更されると、UUIDも要変更
UUID v6: 再び時間ベース、ソート性向上
UUID v6は、RFC 9562で定義された新しいバージョンで、UUID v1の時間フィールドの並びをビッグエンディアン形式に再配置することで、ソート性を向上させたものです。
- UUID v1と同様にタイムスタンプとMACアドレス(またはランダムなノードID)を使用
- 時間順にソート可能であり、データベースのインデックス効率やデータ局所性が改善
- 用途: UUID v1の機能が必要だが、ソート性も重視したい場合に有効
- トレードオフ:
- UUID v1と同様に、MACアドレスの使用に関するプライバシーの懸念が残る可能性あり
- MACアドレスではなくランダムなノードIDを使用する場合、そのノードIDが一意であることの保証が必要
UUID v7: 時間ベースの進化形
本題のUUID v7です。UUID v7は、UUID v6と同様に時間ベースのUUIDですが、より現代的なニーズに対応するために設計されました。UUID v7は、IETFのdraft-peabody-dispatch-new-uuid-format-04で提案され、RFC 9562で正式承認されています。その特徴は、UNIXエポックタイム(ミリ秒精度)を基盤としつつ、ランダム性を含めていることです。
構造
- 48ビットのUNIXエポックミリ秒タイムスタンプ: これにより、ミリ秒精度での生成順序を保証し、ソート性が非常に高い
- 12ビットのバージョンとバリアント情報: UUIDのバージョンとバリアントを示す
- 74ビットのランダムまたはシーケンスデータ: 高いユニーク性を確保するためのランダムな値、または同じミリ秒内に複数のUUIDを生成する際のシーケンスカウンタ
メリット
- 極めて高いソート性: ミリ秒精度のタイムスタンプにより、生成順に完全にソート可能。これは、データベースのB-treeインデックスにおいて非常に効率的であり、パフォーマンス向上に寄与
- 高いランダム性: タイムスタンプに加えて十分なランダムビットが含まれるため、UUID v4に近い高いユニーク性を保ちつつ、衝突の可能性を最小限に抑制
- 推測可能性の低減: タイムスタンプが含まれるものの、その後のランダム部分が十分なエントロピーを持つため、UUID v1のようなMACアドレスの露出や推測可能性の問題を軽減
- 生成が容易: UNIXエポックミリ秒という普遍的なタイムスタンプを使用するため、様々なプログラミング言語や環境で簡単に生成可能
- クロックフォワード耐性: システムクロックが未来に設定された場合、UUIDの単調増加性を維持するための仕組み(クロックフォワード検出と調整)が考慮されている
用途:
- データベースの主キー(特にPostgreSQLやMySQLなどのB-treeインデックスを使用するRDBMS)
- ログやイベントのID(時間順でソートして追跡したい場合)
- 分散システムにおけるトランザクションIDやメッセージID
- マイクロサービス間の連携における識別子
- 時間ベースでデータの関連性を把握したいあらゆるケース
トレードオフ:
タイムスタンプを含むため、生成時刻が外部から推測される可能性があります。これがセキュリティ上の懸念となるシステムでは、使用を慎重に検討する必要があります。しかし、UUID v1のようにMACアドレスから生成元を特定するような直接的な情報漏洩のリスクは低いです。
UUID 各バージョンの比較表
| 特徴 | UUID v1 | UUID v4 | UUID v5 | UUID v6 | UUID v7 |
|---|---|---|---|---|---|
| 基盤 | タイムスタンプ, MACアドレス | 乱数 | 名前空間, SHA-1ハッシュ | タイムスタンプ, ノードID | UNIXエポックミリ秒, 乱数/シーケンス |
| ソート性 | △ (一部ソート可) | × (ランダム) | × (ランダム) | ◯ (時間順) | ◎ (ミリ秒精度でソート可) |
| ランダム性 | 低 | 高 | 低 (決定論的) | 中 | 高 |
| 情報漏洩リスク | 高 (MACアドレス) | 低 | 低 | 中 (ノードID) | 低 |
| 衝突可能性 | 低 | 極めて低い | 決定論的 | 低 | 極めて低い |
| 用途 | 古い時間ベースID | 一般的なユニークID | 決定論的ID | ソート可能な時間ベースID | ソート可能な時間ベースID |
UUID v7の具体的メリットとトレードオフ
UUID v7は、UUID v1やv6の持つ時間ベースのソート性と、UUID v4の高いランダム性の良いところを組み合わせた仕様になります。結果として、両者の「いいとこ取り」が期待されます。
データベースパフォーマンスの向上: B-treeインデックスとの相性
データベースのインデックスには様々な種類がありますが、リレーショナルデータベースで広く使われているのがB-tree(B-木)インデックスです。このB-treeインデックスの仕組みを理解すると、UUID v7がなぜパフォーマンス向上に寄与するのかが分かります。
B-treeインデックスの仕組み
B-treeは、データを効率的に検索、挿入、削除するために設計された自己平衡探索木です。ディスクI/Oを最小限に抑えるように最適化されており、各ノードは複数の子ノードと、ソートされたキー値の範囲を保持します。
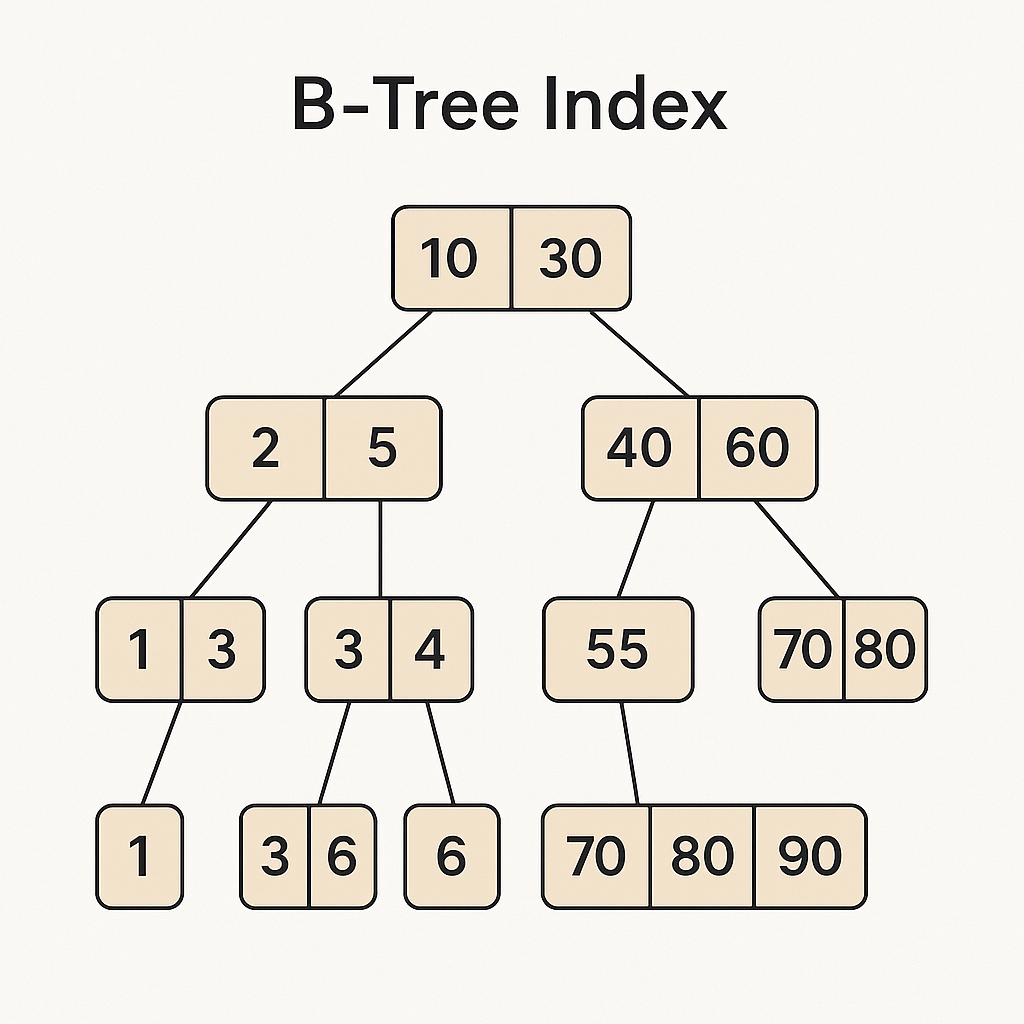
- ノードとページ: B-treeは複数のノード(データベースの文脈では「ページ」とも呼ばれます)で構成されます。各ノードには、いくつかのキーと、対応する子ノードへのポインタが格納されています
- ソート順: 各ノード内のキーはソートされた順序
で格納されており、左の子ノードのキーは親ノードのキーより小さく、右の子ノードのキーは親ノードのキーより大きいという規則に従います - 平衡性: B-treeは、木の高さが常に平衡に保たれるように設計されており、どの葉ノードも根ノードからほぼ同じ距離にあります
- 挿入時の挙動: 新しいデータが挿入される際、適切な葉ノードにキーが追加されます。もしそのノードがいっぱいになった場合、ノードは2つに分割され、中央のキーが親ノードに昇格します。これが繰り返されると、インデックスの木が成長し、ディスク上の様々な場所に新しいページが作成されます
UUID v7がB-treeインデックスで効率的な理由
UUID v7は、先頭部分にUNIXエポックミリ秒タイムスタンプを持っています。これは、UUIDが時間とともに単調増加する特性を持つことを意味します。
UUID v4のような完全にランダムなIDを主キーとして使用する場合、新しいデータが挿入されるたびに、インデックスのどこにでも挿入される可能性があります。これにより、既存のB-treeノード(ページ)の途中に新しいキーを挿入するために、頻繁にページ分割が発生します。ページ分割はディスクI/Oを伴う高コストな操作であり、インデックスの断片化を引き起こし、パフォーマンスを低下させます。
一方、UUID v7は時間とともに増加するため、新しいIDは常にインデックスの「末尾」近くに挿入される傾向があります。これにより、既存のページへの挿入が少なくなり、ページ分割の頻度が大幅に減ります。
時間的に近いデータが物理的にも近くに格納されるため、データベースがディスクからデータを読み込む際のキャッシュ効率が向上します。例えば、最近のデータを連続して取得するようなクエリでは、必要なデータがディスク上で近接しているため、より高速にアクセスできます。UUID v4では、ランダムなIDによってデータがディスク上に散らばるため、キャッシュミスが増え、ディスクI/Oが増加する傾向があります。
ページ分割が少ないということは、インデックスの断片化も抑えられるということです。断片化が少ないインデックスは、より効率的な検索と挿入を可能にし、データベースのメンテナンスコストも削減できます。
まとめ
UUID v7は、これまでのUUIDが抱えていた「ソート性」と「ランダム性」のトレードオフを高度にバランスさせ、現代の分散システムや大規模データベースのニーズに合致するUUIDとして期待されています。
まだ公式サポートしていないプログラミング言語が多々ありますが、UUID v7はとても便利なID仕様なので、今後さらに広まっていくことを期待しています。
宣伝
「ワークフロー自動生成R&Dとか業務フロー合成データとか検索とかに興味ある方、雑談しましょう!」というOpenDoorを用意してるので、LayerXにご興味ある方はご一報ください!