はじめに
前篇の「リアクティブマイクロサービス入門(1/2)- 概念編」では、なぜリアクティブマイクロサービスが必要なのか、リアクティブマイクロサービスとは何なのかをご紹介しました。
後編となるこの記事では、リアクティブマイクロサービスの実装するために使えるテクニック・技術を、目的別にご紹介します。
もちろん、これらすべてを盛り込まなければリアクティブマイクロサービスを実現できないわけではありませんが、引き出しとして知っておけばより柔軟な設計ができるのではないかと思います。
目的別にまとめているので、適宜リファレンス的にご参照いただければと思います。
モジュール化
リアクティブマイクロサービスに求められる性質をバランス良く満たすためには、ビジネス上の関心事を分割することが重要です。
トレードオフで同時に実現することが難しい要件でも、分割することでそれぞれの関心時に最適化した手段を選択して実現できるようになります。
ドメイン駆動設計
リアクティブマイクロサービスの構築においてDDDは必須ではありませんが、DDDのいくつかの原則はリアクティブマイクロサービスの設計でも役に立ちます。
DDDでマイクロサービスを分割する
マイクロサービスのみならず、リアクティブシステムの要件を満たすためにも、どのようにしてマイクロサービスを分割するか?が非常に重要です。
障害が発生した場合の影響が及ぶ境界線になり、つまりは耐障害性に繋がります。
スケールさせる単位にもなるので、弾力性に関係します。
メッセージングで通信するところが非同期境界になり、一貫性はその中でしか保証できません。
では、どのようにマイクロサービスを分割すれば良いのでしょうか?
いくつかの方法がありますが、有力な方法の1つは DDDの境界付けられたコンテキストでマイクロサービスを分割する ことです。(※)
参考文献
- microservices.io - Decompose by subdomain
- DDDの構成要素とマイクロサービスの単位をどう合わせるべきか
- 「モジュールとしてのマイクロサービス」と 「分割単位としてのドメイン」について考える
DDDで一貫性の範囲を決める
強い一貫性を保ちつつ、障害にも耐え、いくらでもスケールすることもできる、というシステムは構築できません。
どこかでバランスを取るしかないですが、その調整可能なパラメーターの1つとして考えられるのが一貫性の範囲です。
システム全体で一貫性を保つことができなくても、「ビジネス要件的にこの範囲で一貫性が保証できていれば良い」と言う境界を探すのですが、
この一貫性を保証する境界としてDDDの「集約」を使うことができます。
たとえばシステム内に「アカウント集約」と「タスク集約」があるなら、それぞれの集約内では強い一貫性を保証しますが、アカウントとタスクをまたぐ時は結果整合性とします。
スケーラビリティと一貫性/可用性の両立
リアクティブマイクロサービスではスケーラビリティを満たしつつ、 一貫性/可用性 を両立する必要があります。
シャーディング
一貫性 と スケーラビリティ を両立するためのテクニックに「シャーディング」があります。
シャーディングでは、「因果一貫性」と同じように、因果関係のあるデータの集合を「シャード」と呼ばれるグループに分け、そのシャード内で強い一貫性を保証します。
先にDDDの集約を一貫性の単位とすることを紹介しましたが、集約の中でシャーディングを使うことで集約の処理能力をスケールできます。
| 性質 | 説明 |
|---|---|
| スケーラビリティ | シャード分割を増やすことでスケールさせることができます。 |
| 一貫性 | シャード内で強い一貫性を保証します。シャードを跨いだ一貫性は保証しません。 |
| 可用性 | あるデータの集合は1つのシャードにしか入っていないので、シャードが破損すると入っているデータが使えなくなります。 |
AWS Kinesisのシャード や Apache Kafkaのパーティション など、同様の概念を実装したサービス/ミドルウェアもあるので比較的導入しやすいと思います。
シャーディングのキー
シャーディングを使う際に重要なのは、データがどのシャードに入るのかを決定するキーに何を使うかです。
シャーディングでは同じキーを持つデータは必ず同じシャードに振り分けられるので、業務フローやユースケースから何単位に一貫性を保証したいのかを考えてキーを選択する必要があります。
DDDを採用している場合は、集約(集約ルート)のIDをキーとして使うのが一般的です。
これは、DDDが集約単位に整合性を保証することと符号します。
また、キーとなる値には連番やタイムスタンプ、意味のある文字列などではなく、ランダムな値(ハッシュ値やUUID、ULIDなど)を使います。
シャードへの振り分けはキー値の先頭N文字から決まったりするので、キー値の先頭N文字に偏りがあると特定のシャードにデータが偏ってしまいます。
CRDT
一貫性 と 可用性 を両立するためのテクニックとして「CRDT(Conflict-free Replicated Data Type)」があります。
可用性を高めるためには複数のノードに同じデータを冗長化(レプリケーション)します。
ノード間のデータ同期は順序保証しなければ最終的な結果が変わってきてしまいますが、この順序保証がスケーラビリティのボトルネックになります。
CRDTは順序保証しなくても最終的に同じ結果になるデータ構造です。(つまり、結果整合性になります)
複数ノードに冗長化するデータにこのCRDTを使うことで、同期を順序保証しなくても良くなります。
| 性質 | 説明 |
|---|---|
| スケーラビリティ | ノード間のデータを順序保証せずに同期できるので、スケールさせやすい。 |
| 一貫性 | ノード間に冗長化されたデータは結果整合性になります。 |
| 可用性 | 複数ノードにデータを冗長化するので、あるノードが使えなくなっても他のノードで機能を提供し続けることができます。 |
CRDTではデータの最新状態上書きしていくのではなく、データの変更履歴を追加・蓄積し、変更履歴から最新の状態をその都度導出します。(そういう意味では後述のイベントソーシングに似ています)
変更履歴の追加は時系列でなくても良いので、同期は順序保証しなくても良いことになります。(導出は時系列でないといけないですが)

問題は、最新の状態を導出するためにメモリ上に全ての変更履歴をロードしなければならない点です。
変更頻度が高いデータでCRDTを使うと変更履歴が肥大化してメモリを圧迫してしまうため、変更頻度が低く、高い可用性が求められる用途に適しています。
Akka ではいくつかのCRDTの実装が提供されていると共に独自のCRDT型を作ることもできるようです。
私個人的には使用した経験がなくてノウハウもないので、導入はちょっとハードルが高く感じます...
参考文献
隔離
マイクロサービスアーキテクチャでは、各マイクロサービスが互いに影響を受けずに独立して稼働し続けることが重要です。
そうでなければ、物理的には分かれていても論理的には一枚岩なシステムになってしまい、マイクロサービスのデメリットが強調されてしまいます。
そうならないように、各マイクロサービスは他のマイクロサービスからは隔離し、それ単独で機能の提供を完結できるようにします。
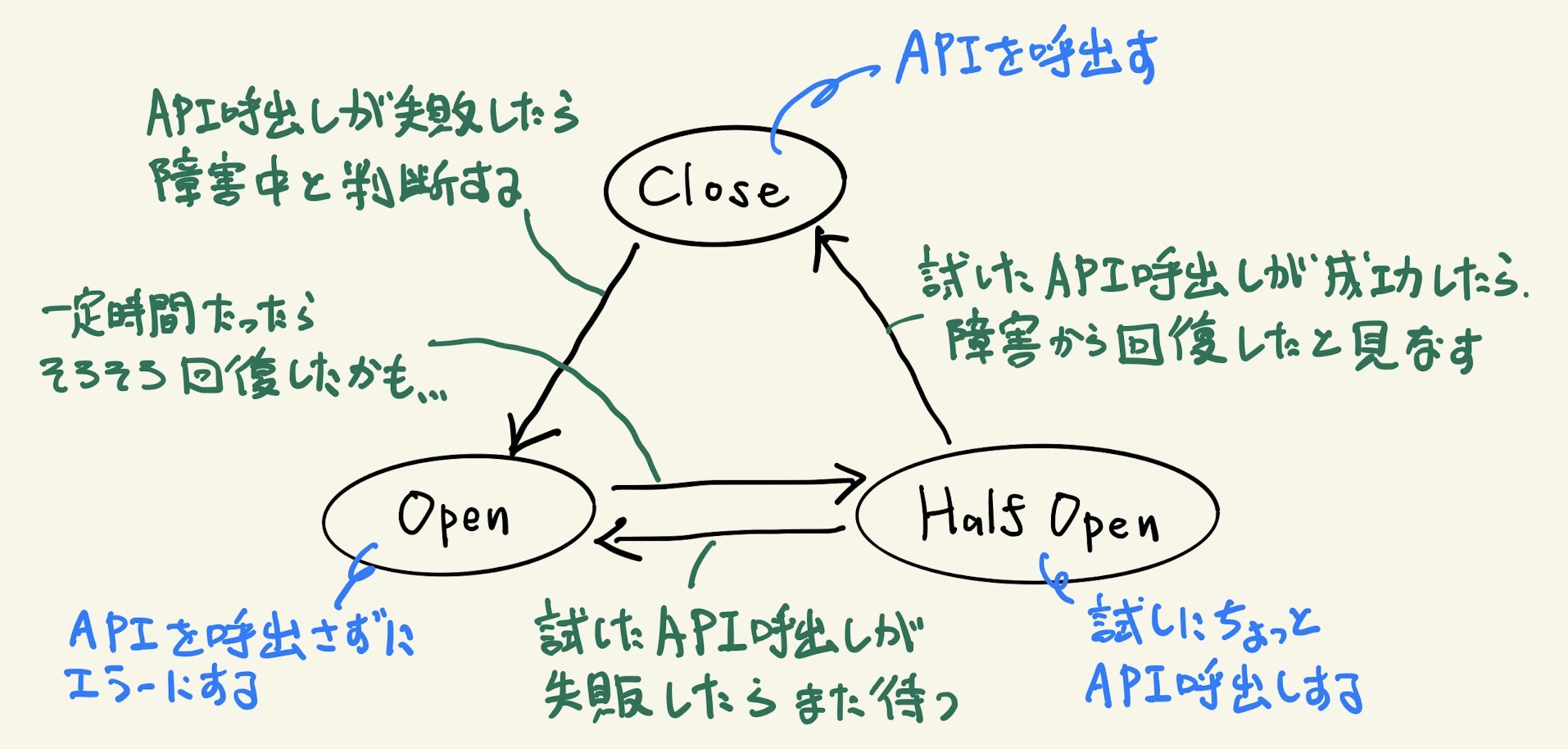
サーキットブレーカー
サーキットブレーカーは「カスケード故障」を防ぐための仕掛けで、主に同期的なAPI呼び出しによるマイクロサービス間通信で使用されます。
カスケード故障とは、複数ノードに負荷分散されている場合にあるノードで障害が発生すると、そのノードが引き受けていた負荷が他のノードにかかって連鎖的にノードが故障する現象を言います。
同期的なマイクロサービス間通信ではネットワークの瞬断などを考慮してリトライするのがセオリーですが、このリトライがカスケード故障に拍車をかけてしまいます。
サーキットブレーカーは、連携先サービスの障害などでAPI呼び出しに失敗した場合、連携先サービスが復旧するまではAPI呼び出ししないようにして、復旧すると自動的にAPI呼び出しを再開します。
これによって、API呼び出しのリトライによって障害を起こしている連携先サービスにさらに負荷をかけてしまうことを防止します。
参考文献
データコピーの保持
あるマイクロサービスが、他のマイクロサービスの影響を受けずに単独でも自律的に機能を提供し続けることができるようにするテクニックのひとつとして、機能を提供するために必要なデータのコピーを持っておく方法があります。
例えばECサイトで、商品を管理するマイクロサービス と 注文を受け付けるマイクロサービス があり、注文を受け付けるときに指定された商品が存在するかどうかをチェックするようなケースを考えます。
単純に考えると、注文サービス から 商品サービス のAPIを同期的に呼び出して存在チェックする方法が考えられますが、これでは 商品サービス が停止していると 注文サービス も機能を提供できなくなってしまいます。
このような問題への解決方法のひとつとして、注文サービス自身が 商品 の情報、つまり 商品サービス のデータのコピーを持っておくことができます。
こうすれば、注文サービス自身が持っているデータだけでチェックを行うことができ、商品サービス が停止していても単独で機能を提供することができます。
データのコピーは、スケジュールバッチでコピーすることもできますが、より望ましいのは相手のマイクロサービスが公開するイベントを購読することです。
前述の例であれば、商品サービスが「商品が登録された」「商品が変更された」「商品が削除された」のような イベント をキューに送信し、注文サービスがそのキューからイベントを受信して自サービス内にコピーを作成します。

なお、コピーは自マイクロサービスで必要な項目だけを扱いやすい構造で持つ(DDDの腐敗防止層の考え方)ことがポイントです。
コピー元の構造をそのままにすべての項目をコピーしてしまうと、コピー元での変更(項目追加など)の影響を受けやすくなってしまいます。
もちろん、この方法にも問題はあります。
データのコピーにはタイムラグがあり、最新の状態とは限らないのでそれが許容できる用途でしか使うことができません。
また、各マイクロサービスにデータのコピーを持つことで運用コストが増えます。
トランザクション管理
マイクロサービスアーキテクチャでは複数のマイクロサービスにまたがって分散トランザクションをかけることは困難です。
特にリアクティブマイクロサービスでは、処理が非同期に実行される、つまりいつ処理が終わるかが分からないので、トランザクションの開始から修了までが長い時間になる可能性を前提としなければなりません。
また、もし技術的には可能だとしても、トランザクションに参加するすべてのマイクロサービスが稼働してなければならなくなり、システム全体の可用性やスケーラビリティが大きく犠牲になってしまうので、分散トランザクション以外のデータの整合性を保証する仕組みが必要です。
Sagaパターン
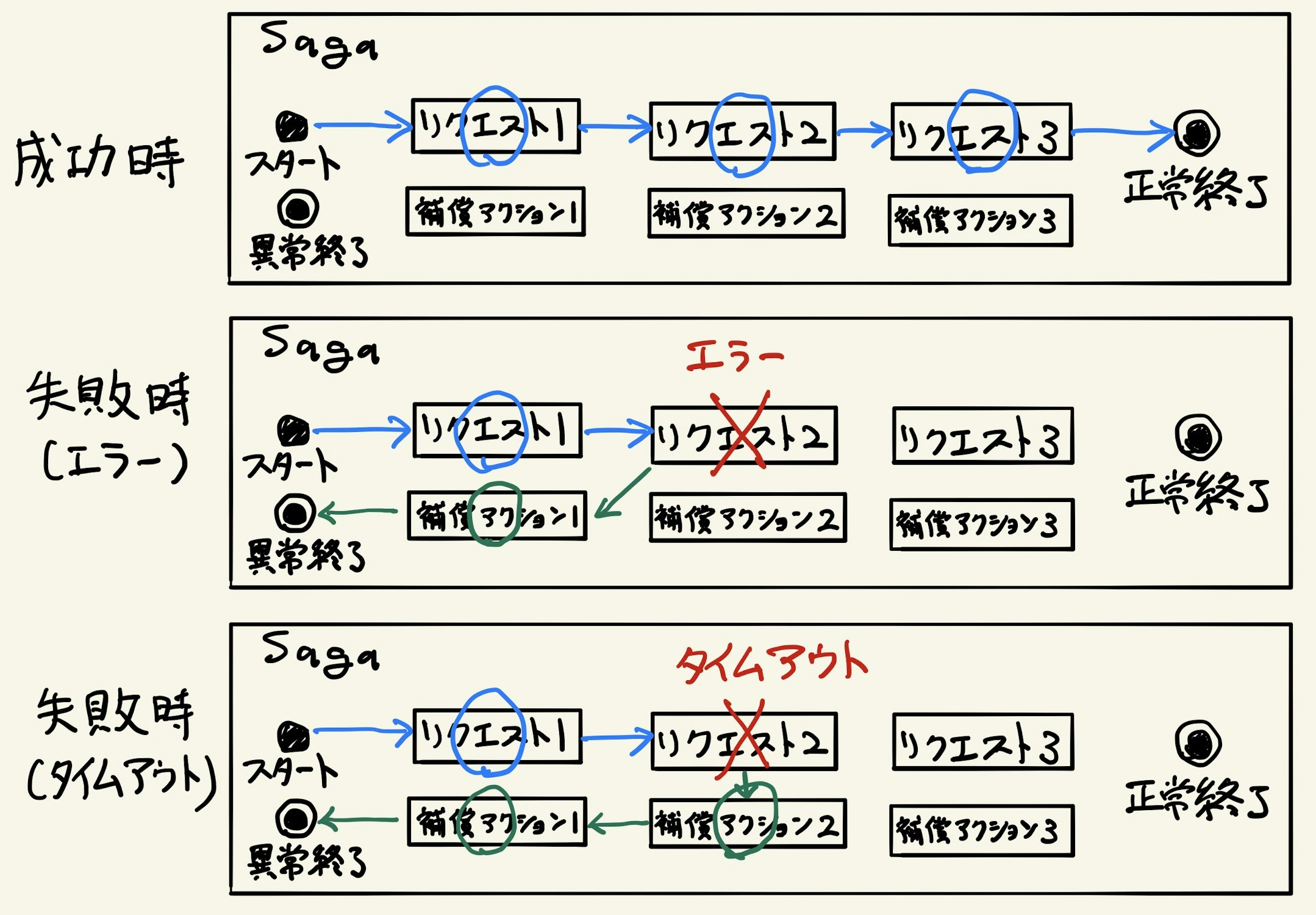
「Sagaパターン」は、長時間に及ぶトランザクションを表現する実装パターンです。
Sagaと呼ばれるトランザクションの中には複数のリクエストが含まれ、すべてのリクエストが成功すればSaga自体も正常修了します。
いずれかのリクエストが失敗した場合は、Sagaの中で実行されたすべての処理結果が取り消された上でSagaは異常終了します。
リクエストはそれを取り消すための「補償アクション」とペアになっています。
リクエストが失敗した場合は、それまでに成功していたリクエストの補償アクションを実行することでその処理結果が取り消されます。
エラーとタイムアウトの区別
Sagaにおいてはリクエストの失敗の仕方に注意が必要です。
リクエストがどのように失敗したかによって、そのリクエストに対して補償アクションを実行する必要があるかどうかが変わってくるからです。
| リクエストの失敗の仕方 | 補償アクションの実行 |
|---|---|
| エラーレスポンスが返ってきた | 補償アクションを実行する必要はありません。 |
| タイムアウトした | 補償アクションを実行する必要があります。 |
問題は、タイムアウトした場合は実はそのリクエストの処理自体は成功している(成功したがレスポンスを返せなかった)かもしれず、それをリクエスト元が判断することはできないと言う点です。
処理に成功している可能性がある以上、補償アクションを実行して取り消しを試みなければなりません。
補償アクションの実装
補償アクションを設計・実装する際はいくつかの注意点があります。
- 補償アクションが失敗した場合、
成功するまでリトライする必要があります。
補償アクションを実行しないとSagaが中途半端な状態で異常終了することになり、データの整合性が壊れてしまいます。 - リトライすると言うことは補償アクションは複数回実行される可能性があるので、
補償アクションは冪等でなければなりません。 - 前述のようにタイムアウトした場合にも実行されるので、失敗しているリクエストに対して実行されても大丈夫なようにしなければなりません。
- Sagaの中で順序が前にあるリクエストほど、以降のリクエストが失敗して補償アクションが実行される可能性が高くなるので、
補償アクションを実行したくないリクエストはできるだけSagaの最後に実行されるようにします。
参考文献
メッセージング
リアクティブマイクロサービスではマイクロサービス間 および マイクロサービス内のノード間 の通信(※)には非同期メッセージングが使用されます。
メッセージングにもパターンがあり、目的に応じて適切なパターンを選択する必要があります。
※ Akkaのようにアクターモデルのパラダイムを使う場合は、ノード内のコンポーネントの相互作用さえも、同期的なメソッド呼び出しではなく非同期なメッセージパッシングになり、システム内外のあらゆる相互作用が非同期メッセージングのパラダイムで統一されます。
配信保証のパターン
二人の将軍問題 のように、ネットワークをまたいだ複数のノード間でメッセージが確実に届いたことを確認することはできないので、メッセージが1回だけ確実に配信されることを補償することを実現することは困難です。
そのため、現実的な解としては「1度だけ配信される」か「確実に配信される」のどちらかを、目的に応じて使い分けることになります。
(多くのメッセージングミドルウェアやライブラリで、コンフィグレーションで切り替えることができると思います)
At most once
メッセージが1度だけ配信される(逆に言うと、複数回配信されない)ことを保証する替わりに、メッセージが配信されない(欠損する)可能性があるパターンです。
メッセージの配信に失敗した場合は、再送したりせずにエラーになります。(ユーザーに再実行を促すなど)
メッセージが欠損する可能性はありますが、挙動がシンプルであり、メッセージ受信側にも特別な考慮は必要ありません。
At least once
メッセージが確実に配信されれることを保証する替わりに、同じメッセージが複数回配信される可能性があるパターンです。
配信を保証するために配信に失敗した場合は再送を試みますが、前述の Sagaパターン と同様にタイムアウトした場合などは実は配信に成功している可能性もあり、その場合は同じメッセージが複数回配信されることになります。
メッセージを再送して配信に成功するまでの間に送信元が停止される(たとえば修正したモジュールをデプロイし直す、など)可能性があるので、送信側でメッセージを永続化しなければなりません。
一方、受信側では同じメッセージが複数回配信された場合に備えて、メッセージの処理を冪等にしておく必要があります。
あるいは、すでに処理しているメッセージであれば読み飛ばすこともできますが、この場合はどのメッセージが処理済みかどうかを受信側で覚えておかなければなりません。
参考文献
配信のパターン
メッセージの配信は、特定の宛先にメッセージを送るパターン と 不特定対数の宛先にメッセージを送るパターン に大別されます。
| 配信のパターン | 送信側と受信側の結合度 | 送信側と受信側の多重度 | メッセージキューの所有者 | 主な用途 |
|---|---|---|---|---|
| ピアツーピア | 高い | 1:1 | 受信側 | 非同期的に実行して欲しい要求を コマンド として依頼したい場合。 |
| パブリッシュ/サブスクライブ | 低い | 1:N | 送信側 | 自身の中で発生した事象を イベント として通知したい場合。 |
これもシステム全体でいずれかに統一されるものではなく目的に応じて使い分けが必要ですが、リアクティブマイクロサービスでは「パブリッシュ/サブスクライブ」を基本として、必要な場合にのみ「ピアツーピア」を使うのが良いです。
通常は、各マイクロサービスは1つ(または集約ごと)のイベント通知用のメッセージキューを持ち、必要ならコマンド受付用のメッセージキューも1つ持つような構成になるのではないかと思います。
また、私の経験上では意外と問題になりがち(それも運用に入ってから)なのがメッセージキューを送信側/受信側のどちらが管理するか(所有するか)です。
上記表のように配信パターンによってメッセージキューの所有者が異なってくるので、はじめからどちらの配信パターンなのかを合意しておく必要があります。
なお、いずれのパターンでも配信するメッセージの仕様(メッセージスキーマ)は、ビジネスの変化に応じて変更できるようにバージョン管理することをあらかじめ検討しておくことをおすすめします。
ピアツーピア
特定の宛先にメッセージを送りつけるパターンです。
受信側が要求インターフェースを公開(メッセージキューとメッセージの仕様)しておき、送信側がそこにメッセージを送信します。
特定の宛先に送信するので送信側は受信側を知っている必要があり、両者の結合度が高くなります。

パブリッシュ/サブスクライブ
メッセージが送信されるメッセージキューを、そのメッセージを必要とする不特定多数の受信者が購読しておくパターンです。
送信側が提供インターフェースを公開(メッセージキューとメッセージの仕様)しておき、受信者がそこからメッセージを受信します。
送信側は誰が受信するか(メッセージキューを購読しているか)を知らないので、送信側と受信側の結合度は低くなります。

参考文献
データの永続化
ここではデータの永続化の方法を紹介します。
スケーラビリティなどの性質にも影響しますが、データの履歴を残すか否か?が大きな違いです。
ステートソーシング
「ステートソーシング」は、一般的に最も多く使われている永続化方式で、データが操作されるたびにデータを最新の状態に上書きしていきます。
最新の「状態(State}」をデータの正とします。
| 操作 | データ | ||||
|---|---|---|---|---|---|
| ①注文の作成 |
|
||||
| ②注文の決済 |
|
||||
| ③注文の発送 |
|
-
メリット
- 広く用いられている方法であり、シンプルでわかりやすい。
-
デメリット
-
複数人による同時更新を考慮(悲観的/楽観的ロック)する必要があり、場合によってはそれがスケーラビリティのボトルネックになります。 - データを上書きしていくので、
過去のデータがどうであったかは失われます。- システムを運用しはじめてから新しいビジネス要件が発生した場合に、過去のデータがないことでそれが実現できない可能性があります。
- それだけでは監査のような要件に対応できず、別途監査ログを残す必要があります。
- プログラムのバグなどでデータが破壊された場合、復旧が大変です。
-
都度、データの最新状態を取得できるので、ステートレスなアーキテクチャに向いています。
イベントソーシング
「イベントソーシング」は、データが操作されるたびに いつ/どこで/誰によって/何が/どう操作されたのか のような記録を残していく方法です。
蓄積された操作履歴「イベント(Event)」をデータの正とします。
| 操作 | データ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ①注文の作成 |
|
||||||||
| ②注文の決済 |
|
||||||||
| ③注文の発送 |
|
-
メリット
- 操作記録を残していくので、データの追加(INSERT)しか発生せず、データの
ロックが発生しません。 - 将来新しいビジネス要件が発生しても、操作記録を使って
後から必要なデータを作り出せます。 - すべての操作記録が残るので
監査のような要件にも自然と対応できます。
- 操作記録を残していくので、データの追加(INSERT)しか発生せず、データの
-
デメリット
- まだ採用/運用の事例やノウハウが多くなく、学習が必要です。
- データの
最新状態を知るには、蓄積された操作履歴を時系列に評価(リプレイ)する必要があります。(データベースの中を見ただけではわかりません) - 操作履歴が大量に蓄積されると、リプレイして最新状態を導出するのに時間がかかるようになります。
- 操作履歴を最初からリプレイしなくて済むように、
一定のタイミングで最新状態を退避(スナップショットと呼ばれます)する方法があります。
- 操作履歴を最初からリプレイしなくて済むように、
基本的には、操作履歴をリプレイして得られた最新状態をメモリ上にキャッシュしておく必要があるので、`ステートフルなアーキテクチャ(アクターモデルなど)が前提になります。
なお、原則として記録された操作履歴を書き換えたり削除してはいけません。
変更や削除が必要な場合は、打ち消すための操作履歴(赤黒伝票のような)を作ります。
参考文献
コマンドソーシング
「コマンドソーシング」はイベントソーシングに似ていますが、イベントソーシングが操作の履歴、つまり過去に起こった事象を記録するのに対して、コマンドソーシングではこれから実行される操作の要求を記録します。
受け取った「操作要求(Command)」をデータの正とします。
具体的には、ユーザーからの要求を受け取ったら、妥当性をチェック(入力チェックなど)を行い、妥当であれば要求を永続化します。
永続化した要求は非同期的に処理します。
| 操作 | データ | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ①注文の作成 |
|
||||||||
| ②注文の決済 |
|
||||||||
| ③注文の発送 |
|
-
メリット
- 処理を非同期的に行うので、
時間のかかる処理を行うのに向いている。 - イベントソーシング同様、蓄積された操作要求を監査などに使うことができる。
- 処理を非同期的に行うので、
-
デメリット
- これも採用/運用の事例やノウハウが多くなく、学習が必要。
- 処理が非同期で実行されるので、処理結果を通知する方法が必要になる。
- 処理が非同期で実行されるので、場合によってはリトライする。リトライに備えて処理は冪等にしておく必要がある。
これも、イベントソーシングと同様にステートフルなアーキテクチャが向いています。
私個人的には特別な要件でもない限りは、あまり使わないかなと思います。
モデルの最適化
繰り返しになりますが、リアクティブマイクロサービスが満たすべきトレードオフな性質...つまりはユーザーの期待に応えるためのキーとなる考え方は関心事の分離です。
両立することができない性質でも、関心事を分離してそれぞれ必要とされる性質に最適化することができれば、システム全体としてそれを満たすことができるようになります。
逆に言えば、システムのある部分に両立できない性質があるとすれば、それは1つのモデルで複数の関心事を扱おうとしているサインとも考えられます。
こういうときに何らかの観点で関心事を分離することができれば、求められる性質を満たすことができるかもしれません。
CQRS
関心事を分離する方法のひとつとしてよく知られているのが「CQRS(Command Query Responsibility Segregation)」です。
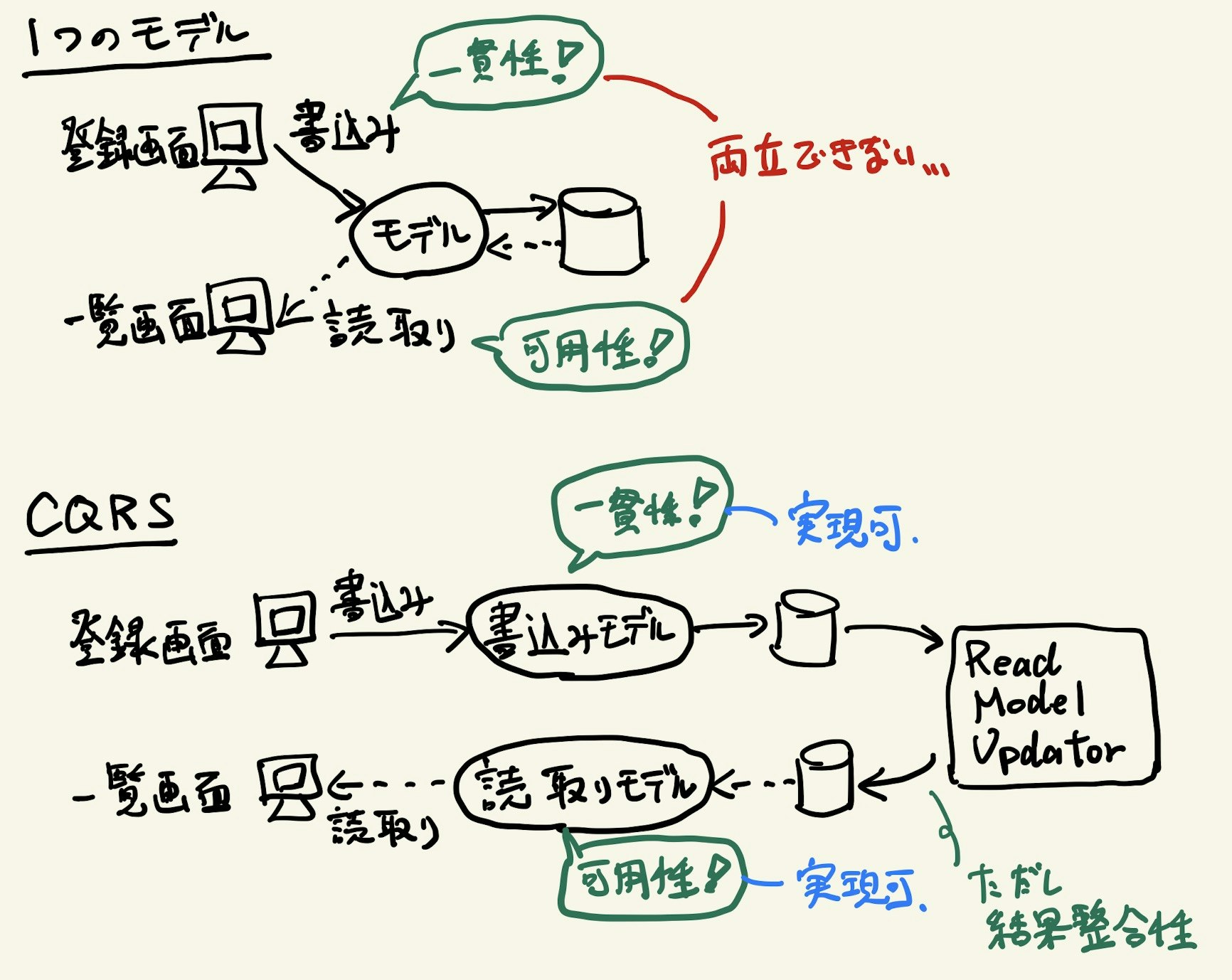
CQRSでは「Command」と「Query」、つまり書き込みと読み取りと言う関心事の違いでモデルを分離します。
書き込みには書き込み専用のモデル、読み取りには読み取り専用のモデルを使い、同じモデルで読み書き両方をしないようにします。
書き込みと読み取りの要件の違い
一般的に、書き込むときと読み取るときでは、求められる要件が異なります。
例えばECサイトでは、注文のたびに毎回支払い方法を入力したくはありませんので、注文とは別に支払い方法を登録したり編集したりできます。
注文のときは、注文の一部が欠落したり、同じ注文が複数回処理されたりしないように一貫性が必要です。
一方で、自身の過去の注文履歴を見たいときは、どの注文をどの支払い方法で決済したのかをまとめて確認したいかもしれません。
注文履歴を見るだけなの一貫性は必要なく、それよりは見たいときに見れないことのほうが問題(つまり可用性が求められる)だったりします。
このような異なる要件を1つのモデルで扱おうとすると、求められる性質を両立することが困難になります。
DDDを導入している場合は、書き込むときは「集約」単位に一貫性を保証しますが、読み取るときは「集約」単位とは限りません。
むしろ「集約」はできるだけ小さく、読み取りはできるだけ多くの情報をまとめて取ろうとするので相反する設計になります。
CQRSを使うことでこれを解決できるので、DDDとCQRSは組み合わされることが多いです。
未来のビジネス要件への対応
CQRSを使うとビジネスの変化にも対応しやすくなります。
変化はユーザーに近いところ(UI)から発生することが多いですが、UIに対する要件の大半はデータの見え方、つまり読み取りに関するものです。
(「一覧にあの項目とこの項目も一緒に表示して欲しい」のような仕様変更は現場ではよくあると思います)
このときに、書き込みと読み取りを1つのモデルで扱っていれば、このような仕様変更がビジネスロジック、ひいては業務フローにまで影響することがあります。
一方でCQRSではモデルが分離されているので、読み取りモデルに項目を追加しても、書き込みモデルには影響がありません。
このようにモデルが分離されていることで、仕様変更、つまりビジネスの変化にも対応しやすくなります。
さらに新しい要件にも対応しやすいです。
新しい要件として、システムの初期構築時にはまったく想定していなかったようなデータの見せ方・使い方が求められた場合、1つのモデルではそのような要件は想定していないので、変更の影響が大きすぎて対応に相当な時間を要したり、そもそも実現ができないかもしれません。
CQRSでは新しい読み取りモデルを追加するだけで、既存のモデルを変更せずに対応できる可能性が高いです。
マイクロサービスの分割
CQRSを使う場合は、書き込みと読み取りを別のマイクロサービスとすることも可能です。
前述のECサイトの例で言えば、「注文マイクロサービス(書き込み)」「支払い方法マイクロサービス(書き込み)」「注文履歴マイクロサービス(読み取り)」のように分けることができます。
あとから注文履歴からおすすめ商品をレコメンドするような要件が発生したら、新しく「レコメンドマイクロサービス(読み取り)」を作れば良いだけです。
書き込みと読み取りではデータベースに求められる性質も異なるので、書き込み系のマイクロサービスではRDBMSを、読み取り系のマイクロサービスではKey Value Storeや検索エンジンを使う、のようなことも可能です。
CQRSの実装
CQRSでは書き込みと読み取りでモデルが異なるので、基本的にはそれぞれでデータソースも別になります。
書き込みモデルでは、RDBMSなどの強い一貫性を保証できるデータストアに、正規化したデータ構造を使います。
読み取りモデルでは、大量の参照リクエストや検索の柔軟性に対応できるデータストアを使い、非正規化したデータ構造を使います。
データソースが異なるので、書き込まれたデータをもとにして、読み取り用のデータを作成しなければなりません。
これは「Read Model Updater」などと呼ばれるコンポーネントによって、非同期的に読み取り用のデータが作成/更新されるようにします。
よって、読み取り用のデータ(読み取りモデル)は必然的に結果整合性になります。
Read Model Updaterは、データが書き込まれたことを通知する「イベント」を購読するコンシューマとして実装されることが多いです。
CQRSとイベントソーシング
CQRSを実装する上でイベントソーシングは必須ではありませんが、組み合わせることで得られるメリットがあります。
1つ目は、Read Model Updaterがイベントソーシングのイベントを使って読み取りモデルを作ることができることです。
イベントソーシングを使わない場合は、DBのトリガーを使ったり、Read Model Updater用にわざわざデータ更新を通知する必要があります。
2つ目は、あとからどんな読み取りモデルでも作り出せる点です。
システムを運用しはじめてから、当初想定していなかったような新しい読み取り要件が発生したとします。
ステートソーシングでは最新のデータしか残っていない(過去のデータは上書きされてしまっている)ため、読み取り要件によっては必要なデータがすでに存在していないかもしれません。
一方、イベントソーシングを使っていれば過去のデータの履歴がすべて残っているため、それを遡ればあらゆる読み取りモデルを作りだすことができます。
読み取りモデルの結果整合性
上述のように、読み取りモデルは非同期的に更新されていくので結果整合性です。
書き込みモデルに対する変更が、読み取りモデルに即時に反映されることは保証されません。
となると、ユーザーがデータを変更しても、その変更内容がデータの検索結果や一覧画面にまだ反映されていない、と言うことが起こりえます。
このように書くと「それじゃ使いものにならないじゃないか」と思われるかもしれませんが、実はCQRSのような結果整合性ではなく強い一貫性であったとしても、画面に表示されているデータはすでに他のユーザーによって変更されている可能性があり、過去のデータを見ながら作業をしていると言う点では同じです。
結局は、データを書き込もうとした時点で整合性をチェックするしかありません。
また、そもそも他のユーザーがいつどのデータをどのように変更しているか、なんてことは知る由もないので気づきようがありません。
問題になるとしたら、自身が行った変更が即時に反映されない、と言うケースだと思われます。(注文したのになかなか注文履歴に出てこない、など)
これがビジネス上の重要な問題になる場合は、結果整合性であることを前提としてUI側で対処(動線を工夫したり、読み取りモデルに反映されたフリをするなど)が必要かもしれません。
CQRSを使うと、"見えているのは過去のデータ"と言うことが明示されるので、それを前提とした業務フローやUIデザインを促すことにもなります。
参考文献
実現方法の選択
前篇で解説しようにマイクロサービスに求められる性質はトレードオフであり、個々のマイクロサービスごとに求められる性質が異なります。
また、ここで紹介したようなテクニックや技術は強力ですが、複雑さが増したり運用コストが増えるなどのデメリットがあることも理解して採用しなければなりません。
よって、 各マイクロサービスのアーキテクチャ上の決定をシステム全体で無理に統一する必要はない と思います。
統一しないことで、各マイクロサービスは要件に最適化することができ、その時々の新しい技術を取り入れていくことも可能になります。
ただ、毎回マイクロサービスのアーキテクチャをゼロから考えるのも効率が悪いので、ビジネスの特性に応じたマイクロサービスの実装パターンを出しておくと良いように思います。
各パターンごとのリファレンス実装(サンプル)も用意できれば、なお良さそうです。
一方で、マイクロサービス同士をつなぐ メッセージング基盤だけは統一した仕組み・エコシステムを構築したほうが良い ように思います。
メッセージングのミドルウェアに何を使うのか、データ形式(JSONやXMLなど)は何を使うのか、メッセージのスキーマ定義はどう管理するのか、と言った取り決めや、メッセージの流れの可視化、メッセージを参照したり操作するための運用ツールなどの整備も必要です。
おわりに
ずいぶんと長い記事になってしまいました(笑)
どんな技術やテクニックがあるのか?をザッと知っておくことを目的に概要とポイントしか解説できていませんので、より詳しく知りたい方は Lightbend Academy を受講したり、個々の文献をあたっていただければと思います。
前編 とあわせて、ユーザーに信頼されるシステムを開発する助けになれば幸いです。