はじめに
リアクティブシステムを構築するためのライブラリ「Akka」を開発する Lightbend社 から、リアクティブシステムやマイクロサービスについて学習できる有償のオンライントレーニング「Lightbend Academy」を提供されていますが、2020年夏の間(※)は無償で受講できるようになっています。
※2020/07/14現在。当初は無償期間が6月末まででしたが、7月末 -> 夏いっぱいと期間が延長されています。
※「Lightbend Academy」の受講については、こちらのスライド「Lightbend Academyオンライントレーニングを受けてみた」もご参照ください。
この記事では「Lightbend Academy」を受講して学んだ、リアクティブな性質を備えたマイクロサービスを設計・開発するために知っておきたい知識や理論 を、私なりに整理・再編してご紹介したいと思います。
後編 では、ここで紹介したリアクティブマイクロサービスの性質を満たすために、どのようなテクニックがあるのかをご紹介します。
リアクティブマイクロサービスもあらゆるシステムに適用できる ”銀の弾丸” ではありませんが、ソフトウェアシステムを構築する際の引き出しとして知っておくと設計の幅が広がると思います。
私自信の理解もあやしいところもありますので、詳細まで正しくご紹介できていないかもしれませんが、皆さんの議論のタネになれば幸いです。
リアクティブシステムの必要性
まずは皆さんに「なるほど、リアクティブシステムを考えていきたいなー」と感じていただけるように、なぜ今リアクティブシステムが必要なのか?について触れたいと思います。
昨今のソフトウェア開発において、AWS や Microsoft Azure のようなクラウドプラットフォーム、Docker や Kubernetes に代表されるコンテナ技術、そして マイクロサービス や ドメイン駆動設計、クリーンアーキテクチャ などの設計・アーキテクチャ理論を良く聞きます。
私自信も、AWS上で稼働するマイクロサービスをドメイン駆動設計で開発・運用した経験があり、今まさにリアクティブマイクロサービスの開発に関わっています。
そんな中で「リアクティブシステム」については比較的議論されていることが少ないように感じています(あくまでも私のアンテナの感度の範囲でですが)が、今後のソフトウェア開発において非常に重要な要素になると考えています。
「リアクティブシステム」とはかなり大雑把に言ってしまえば、 "いつでも使えるシステム" です。
例えば、大きなニュースや災害の発生などによってトラフィックが大量に発生したとき、インフラストラクチャに障害が発生したとき、システムに不具合があったとき、システムメンテナンスをしているとき...どんなときでもユーザーが使い続けることができるシステムです。
私達の社会の中でソフトウェアが果たしている役割はどんどん大きくなってきています。インターネット上で使えるサービスがなければ生活で大きな不便を強いられます。
たとえば 5G が普及すればさらにその傾向は加速し、ソフトウェアは今まで以上に大量のトラフィックをダウンすることなく処理することが要求されるようになるのではないかと考えています。
特に、人ではなくデバイスが情報を収集して送信してくるようなサービスでは、サービスが停止してもデバイスは情報を送り続けようとします。
サービスが停止している間にも未処理のデータが溜まり続け、サービスが復旧してから溜まったデータを処理して追いつくことが難しくなることも考えられます。
インターネット上でさまざまなサービスが次々に生み出されている今の時代、この流れに対応できなければそのソフトウェアはビジネス上の競争力を失い、淘汰されていくかもしれません。
そのような 社会からのニーズ・期待の変化に応え、ビジネスを継続的に成長させていく ためには、クラウドプラットフォーム上で実行する、Kubernetesでコンテナオーケストレーションさせる、マイクロサービスに分割する...だけではなく、リアクティブシステムであることがソフトウェアの必須要件 にもなってくるはずです。
リアクティブシステムとは?
では、そもそも「リアクティブシステム」とは何でしょうか?
ReactiveX のようなライブラリや、Spring WebFlux、Akkaなどのフレームワークを使って実装しさえすれば良いのでしょうか??
答えは「No」です。
それは「リアクティブプログラミング」であり、社会から求められている「リアクティブシステム」とは違います。
リアクティブシステム
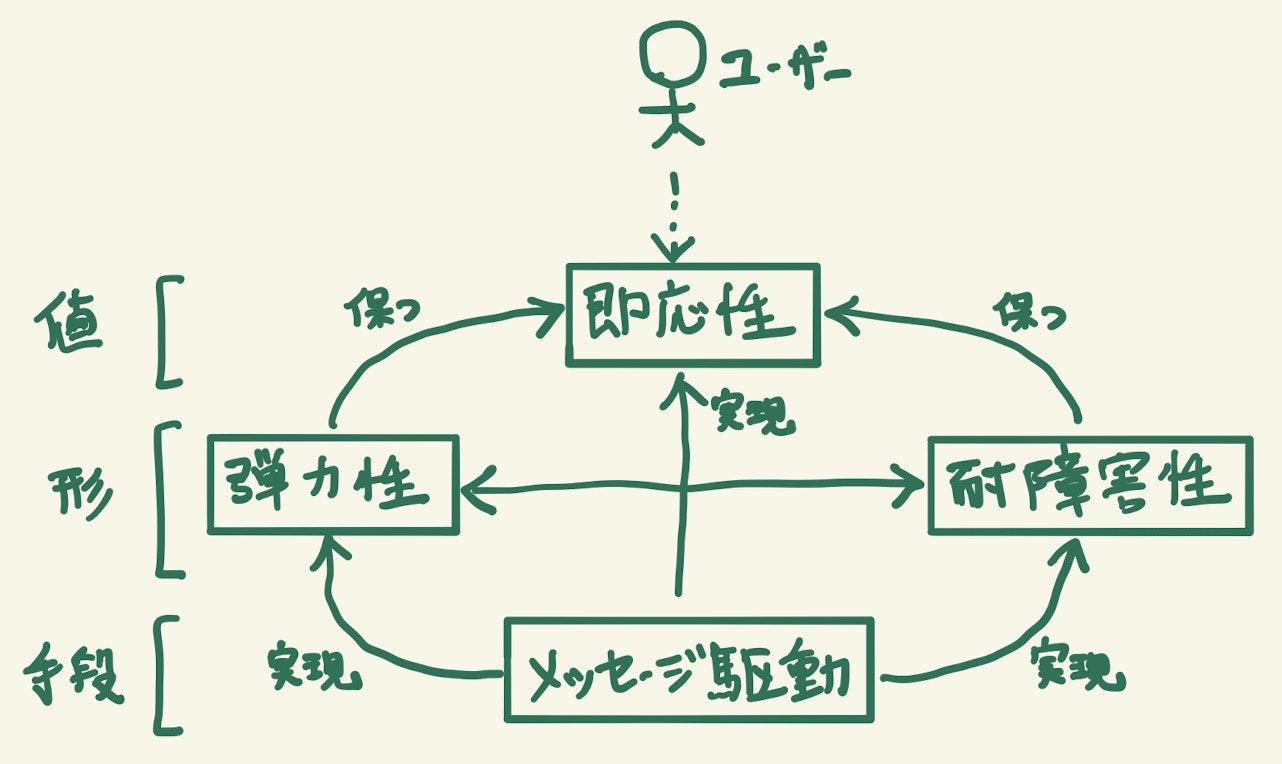
「リアクティブシステム」とは リアクティブ宣言(Reactive Manifesto)で、以下の性質を満たすものと定義されています。
| 分類 | 性質 | 説明 |
|---|---|---|
| 値 | 即応性 (Responsive) | 応答時間、応答内容に一貫性があること。 応答時間が遅かったり、エラーになったりするとユーザーからの信頼を失い、市場での競争力も失っていく。 |
| 形 | 耐障害性 (Resilient) | 障害が発生しても即応性を保つこと。 もしシステムの一部が使えなくなっても回復可能であり、その間も他の機能は使い続けることができる。 |
| 弾力性 (Elastic) | トラフィック・負荷が増えてもスケールして即応性を保つこと。 単一のボトルネック(主にデータベース)があるとスケールできない。 |
|
| 手段 | メッセージ駆動 (Message Driven) | コンポーネントが、非同期・ノンブロッキングなメッセージングによって通信すること。 |
ユーザーにとって直接的に価値があるのは「即応性」 であり、それを常に保つために「耐障害性」「弾力性」が必要であり、それらは「メッセージ駆動」を基盤とすることで実現される、と言うことになります。
これらの性質を満たせば、 障害が起こっても全体が停止せず、トラフィックが急激に増えても遅くなることもなく、安定して応答を返し続ける、社会のニーズと期待に応えるソフトウェア だと言うことができます。
リアクティブプログラミング
「リアクティブプログラミング」は、「リアクティブシステム」を効率的に実装する手段です。
前述の ReactiveX や Spring WebFlux、Akka などはリアクティブプログラミングのためのライブラリです。
注意しなければいけないのは、リアクティブプログラミングをしたからと言ってリアクティブシステムにはなるわけではないと言うことです。
リアクティブ宣言の性質を満たすには、アーキテクチャレベルでの設計が必要になります。
逆に、リアクティブプログラミングを使わなくてもリアクティブシステムを実装することは可能です。
「Akka」がベースとする アクターモデル のようなプログラミングパラダイムも、それを使わなければリアクティブシステムを作れないわけではありません。
リアクティブプログラミング や アクターモデル は比較的難易度が高く、最初の学習コストがかかったりプログラムが複雑になったり、運用が難しくなったりしがちなので、プロジェクトでリアクティブプログラミングを採用する際は ビジネスサイドの人たちも交えて「自分たちにそれ(リアクティブシステム)が必要なのか?」を議論 したほうが良いと思います。
一方で、必要に迫られてからでは遅いので、やりすぎを承知の上で学習を目的として小さなシステムで使ってみるのも良いかもしれません。
リアクティブシステムとマイクロサービス
リアクティブシステムの実現においてマイクロサービス化(※)は必須ではありませんが、リアクティブ宣言の「即応性」「耐障害性」「弾力性」「メッセージ駆動」を満たすことを考えれば、 自然とマイクロサービスになる のではないかと思います。
| リアクティブ宣言の性質 | モノリス | マイクロサービス |
|---|---|---|
| 即応性 | 即応性を確保できない場合がある。 例えばJOINを多用したクエリが要求される応答時間内に返せないなど。 |
マイクロサービスごとに個別の要件に最適化することで即応性を満たしやすい。 |
| 耐障害性 | 障害がモノリス全体に波及してしまう。 | 障害の発生をマイクロサービス内に隔離することで、他のマイクロサービスは機能を提供し続けることができる。 |
| 弾力性 | モノリスを複数並べてスケールさせることはできるが、単一のボトルネックによって限界がある。 | 単一のボトルネックはなく、マイクロサービスごとに個別にスケールできる。 |
| メッセージ駆動 | そもそも単一のモジュールなので、メッセージ駆動を使うところがない。 | マイクロサービス間の連携は、メッセージングで行う。 |
※マイクロサービスについては以下の記事もご参照ください。
- 書籍「マイクロサービスアーキテクチャ」まとめ(前編)
- 書籍「マイクロサービスアーキテクチャ」まとめ(後編)
ソフトウェアの形態
以上を踏まえて、ソフトウェアの形態として下表の3つを比較してみます。
| 形態 | 概要 | 即応性 | 耐障害性 (可用性) |
弾力性 (スケーラビリティ) |
一貫性 | 開発/運用コスト |
|---|---|---|---|---|---|---|
| モノリシック | 単一モジュールでシステム全体を構成。 データベースもシステム全体で共用。 |
△ | ☓ | ☓ | ◎ | ◎ |
| マイクロサービス | 機能を複数のサービスに分割し、データベースも各サービスで個別。 サービスごとに個別にデプロイ。 サービス間は同期的なAPI呼び出しで連携。 |
○ | ○ | ○ | ○ | △ |
| リアクティブマイクロサービス | 機能を複数のサービスに分割し、データベースも各サービスで個別。 サービスごとに個別にデプロイ。 サービス間は非同期メッセージングで連携。 |
◎ | ◎ | ◎ | △ | ☓ |
| ※表中の◎○△☓は私個人の感覚的な評価で厳密ではありません。 |
もちろんこれらにはそれぞれ一長一短があり、「リアクティブマイクロサービスが最強!!」と言うわけではありません。
自分たちが作ろうとしている ソフトウェアの要件やビジネスを取り巻く環境に応じて選択する ことになります。
このようなソフトウェアの形態は最初に決めたら変更できないわけではありません。
たとえば、最初はモノリシックからはじめてビジネスの成長にあわせて段階的にマイクロサービスに移行していく、と言ったことも可能です。
リアクティブマイクロサービスのインターフェース
ビジネス上の活動(アクティビティ)は、以下の3つに分類できます。
マイクロサービスが外部に公開するインターフェースも、この3種類に対応します。
| アクティビティ | 説明 | マイクロサービスのインターフェース |
|---|---|---|
| コマンド | データ(状態)を変更するためのリクエスト。 ビジネス上の制約から拒否されたり失敗することがある。 |
RESTなどのAPI。 レスポンスは処理したデータのIDや、「受け付けた」と言うことだけで、データの内容は返さない。 |
| イベント | データ(状態)が変更されたことを通知するメッセージ。 すでに起こった事象なので失敗することはない。 |
イベントキューに送信されるメッセージ。 Pub/Subメッセージングで不特定多数の購読者にブロードキャストされる。 |
| クエリ | データ(状態)を取得するためのリクエスト。 データを変更してはいけない。 |
RESTなどのAPI。 レスポンスとして要求されたデータを返す。 GraphQLとか使っても良いかもしれません。 |
- 例)コマンドのAPI
POST /orders
{
"Details": [
{
"ItemId": "AAAAAAAAAAAAAAAAAAAAAA",
"Quantity": 1
},
{
"ItemId": "BBBBBBBBBBBBBBBBBBBBBB",
"Quantity": 2
}
]
}
201
{
"OrderId": "XXXXXXXXXXXXXXXXXXXXXXX"
}
- 例)イベントのメッセージ
キュー order-events
{
"EventType": "OrderAccepted",
"EventSchemaVersion": 2,
"EventPublishedAt": "2020-07-01T00:00:00.000Z",
"EventBody": {
"OrderId": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"OrderedAt": "2020-07-01T12:34:56.789Z",
"Details": [
{
"ItemId": "AAAAAAAAAAAAAAAAAAAAAA",
"Quantity": 1
},
{
"ItemId": "BBBBBBBBBBBBBBBBBBBBBB",
"Quantity": 2
}
]
}
}
- 例)クエリのAPI
POST /orders/search
{
"OrderedAtFrom": "2020-07-01T00:00:00.000Z",
"OrderedAtTo": "2020-07-02T23:59:59.999Z"
}
200
{
"Results": [
{
"OrderId": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"OrderedAt": "2020-07-01T12:34:56.789Z",
"Details": [
{
"ItemId": "AAAAAAAAAAAAAAAAAAAAAA",
"Quantity": 1
},
{
"ItemId": "BBBBBBBBBBBBBBBBBBBBBB",
"Quantity": 2
}
]
},
{
"OrderId": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"OrderedAt": "2020-07-02T12:34:56.789Z",
"Details": [
{
"ItemId": "AAAAAAAAAAAAAAAAAAAAAA",
"Quantity": 3
}
]
}
]
}
リアクティブマイクロサービスの性質
ここからはこの記事の主題であるリアクティブマイクロサービスを掘り下げていきます。
リアクティブマイクロサービスには、マイクロサービス、つまり分散システムであるがゆえの性質とトレードオフが伴います。
これらの性質を理解した上で ビジネス要件に応じてアーキテクチャ上の判断をし、それを満たすための実現手段を採用していくことが重要です。

CAP定理
分散システムの性質として良く議論されるのが CAP定理 です。
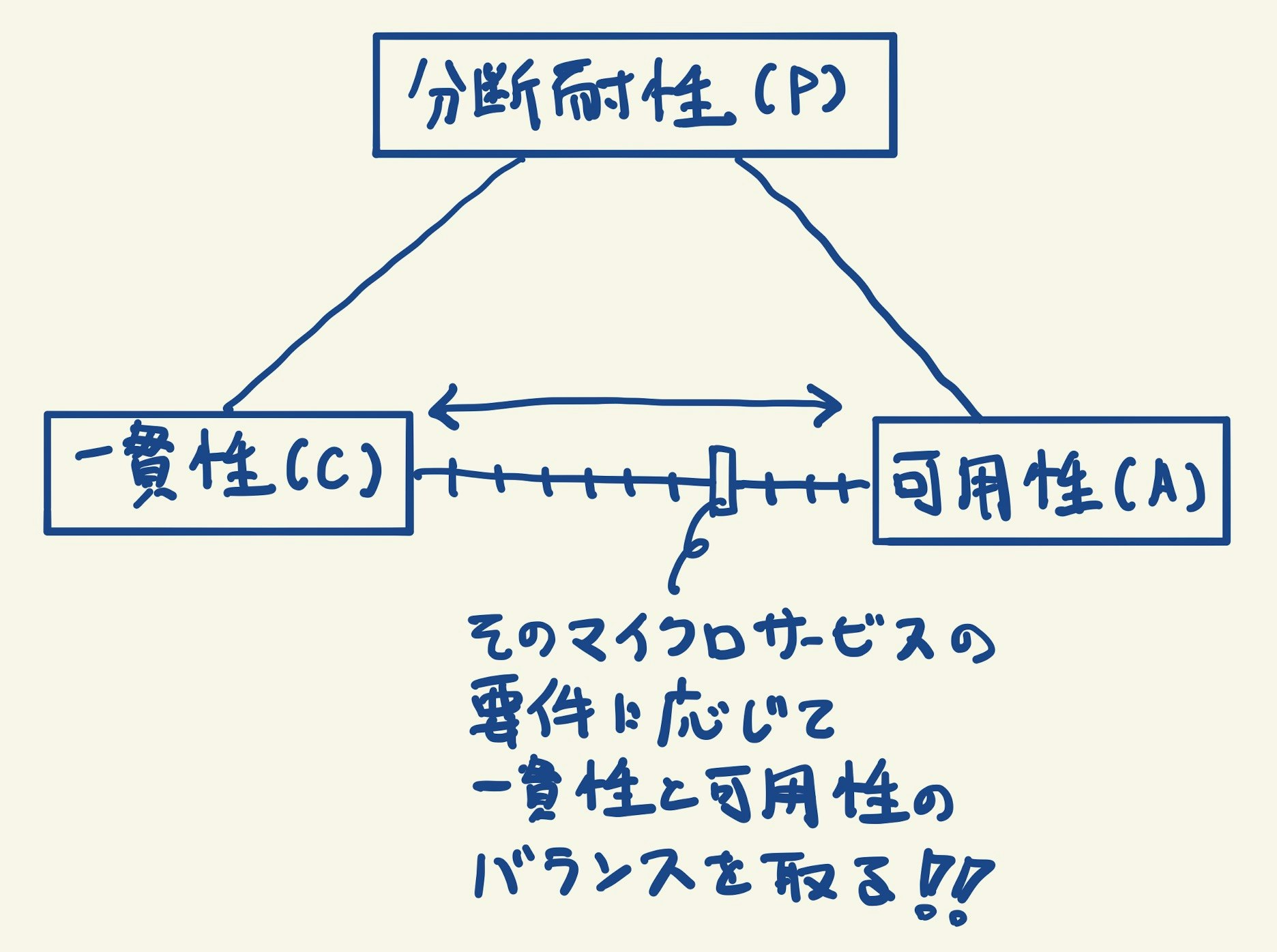
CAP定理では下表の3つの性質のうち、同時に満たすことができるのは2つだけとされています。(※)
| 性質 | 説明 |
|---|---|
| 一貫性(Consistency) | 読み込みリクエストが一貫して最新の情報を返すこと。 |
| 可用性(Availability) | あるノードで障害が発生しても、他のノードは機能を提供し続けること。 |
| 分断耐性(Partition tolerance) | ネットワーク障害などでノード間の通信が分断/遅延しても、各ノードは機能を提供し続けること。 スケーラビリティにも影響する。 |
※今では「2つだけ」と言う定義ではなく、「それぞれの性質をどこまで満たすかの
程度問題であり、ビジネス要件に応じてバランスを取るべし」と言うことになっているようです。Lightbend Academy の解説でも、ビジネスの観点からバランスを取ることの必要性を説いています。
リアクティブマイクロサービスにおいては 分断耐性 を満たすことを前提に、各マイクロサービスの要件に応じて 一貫性 と 可用性 のバランスをどこで取るかを考える ことになります。
たとえば、注文を管理するマイクロサービスでは誤った注文がされないように多少可用性を犠牲にしてでも一貫性を重視し、注文履歴からオススメ商品をレコメンドするマイクロサービスでは正確性よりも可用性を重視する、のようにします。
一貫性
ひとことで「一貫性」と言っても単純に保証する/しないではなく、何をどこまで保証するかによって種類があります。
一貫性 は 可用性 とトレードオフになるので、そのバランスでどの一貫性を採用するかを決める必要があります。
データ参照の一貫性
| 種類 | 一貫性 | 可用性 | スケーラビリティ |
|---|---|---|---|
| 強い一貫性 | 常にすべてのユーザーに同じ状態が見えることを保証する。 | ☓ 一般的にRDBMSのトランザクションなどを利用する必要があり、そこが単一障害点になる。 |
☓ RDBMSで競合(ロック)が発生し、ボトルネックになる。 |
| 結果整合性 | タイミングのズレはあれども最終的にはすべてのユーザーに同じ状態が見えるようになることを保証する。 言い換えれば、ある時点でユーザーごとに異なる状態が見える場合があります。 |
○ 障害箇所の状態が更新されず整合性が取れなくなる期間は生じるが、古いデータを使って機能を提供し続けることはできる。 |
○ 状態が同期していることを保証しなくて良いので、スケールさせやすい。 |
データ処理順序の一貫性
| 種類 | 一貫性 | 可用性 | スケーラビリティ |
|---|---|---|---|
| 因果一貫性 | 因果関係のあるデータの集合の中で、順序通りに処理されることを保証する。 | △ 処理できないデータがあった場合、そのデータと因果関係があるデータは処置が止まるが、因果関係がなければ影響を受けずに処理を継続できる。 |
△ 因果関係のあるグループを分けることでスケールできる。 |
| 逐次一貫性 | 因果関係に関係なく、すべてのデータが順序通りに処理されることを保証する。 | ☓ 1つでも処理できないデータがあると、全体の処理がそこで停止する。 |
☓ スケールできない。 |

スケーラビリティ
指標として、スループット(単位時間あたりに処理できるリクエスト数)を使います。
スケーラビリティは 一貫性 と 可用性 の両方とトレードオフがあります。
一貫性を重視すればするほどスケーラビリティは低下し、可用性を重視してもスケーラビリティが低下します。
一貫性とのトレードオフ
スケーラビリティ と 一貫性 の間には「アムダールの法則」が成り立ちます。
この法則は、システム内に並列化できる部分とできない部分が存在する場合、 並列化できない部分はスケールさせることができない ことを意味します。
前述の「強い一貫性」を使用した場合、一貫性を保証するためのRDBMSなどは並列化させることができず、スケーラビリティの制約になります。
また「逐次一貫性」を使用した場合も、データは直列でしか処理できなくなるのでスケーラビリティが制限されます。
このバランスを取るには、要件の許す範囲で 最小限の一貫性を使うようにしたり、一貫性を保証する範囲をできるだけ狭く します。
可用性とのトレードオフ
可用性を高めるためには、あるノードで障害が発生しても他のノードが機能を提供できるようにデータ(状態)を複数のノードに冗長化させますが、ここで「ガンザーの法則」が問題になります。
ノードの数を増やせば増やすほど可用性は高まりますが、その分ノード間でデータ(状態)を同期するためのコストが増えます。
ガンザーの法則では、このノード間の同期にかかるコストがノードを増やしたことによる処理能力の増分を上回ってしまうことを意味します。
つまり、ノード間同期のコストがスケーラビリティの制約になります。
このバランスを取るには、ノード間で 同期しなければならないデータを減らしたり、全てのノードが互いに同期し合うのではなく同期する相手を限定する ことが必要になります。
パフォーマンス
指標として、レイテンシ(1つのリクエストをどれくらい速く処置できるか)を使います。
どれだけスケールできても、リクエストの処理でユーザーを待たせていては意味がないので、パフォーマンスの考慮も重要です。
パフォーマンスの改善は、 どれだけ個々の要件に最適化できるか? がポイントになります。
例えばRDBMSを使っていてテーブルが書き込み用に最適化(正規化)されている場合、クエリを最適化することはできずに大量のJOINを伴うかもしれません。
このように複数の要件を同時に満たそうとするとパフォーマンス悪化の原因になります。
パフォーマンスはどれだけ速くなってゼロになることはないので、チューニングには限界があると言えます。
ただ、ゼロにすることが求められているわけではなく、 ユーザービリティの観点から必要十分なパフォーマンスが出ていれば良いわけなので 、必要以上のチューニングにコストをかけても費用対効果が薄くなります。
隔離
ここまで紹介したようなリアクティブマイクロサービスの性質を満たすためには、意識的に隔離してマイクロサービスの自律性を確保することが重要です。
隔離には以下の4つの観点があります。
| 観点 | 原則 | 効果 |
|---|---|---|
| 状態 | マイクロサービス内部の状態は隠蔽され、そのマイクロサービスが公開するインターフェース(APIなど)を介してのみアクセスできるようにします。 | インターフェースさえ変更しなければ、マイクロサービスの内部実装はいつでも変更できます。 |
| 空間 | 各マイクロサービスはお互いが物理的にどこにデプロイされているかを関知しないようにします。 | いつでも物理的な配置を変更したり、スケールアウト/スケールインできるのでスケーラビリティが向上します。 |
| 時間 | マイクロサービス間の通信は相手の応答を待たない非同期・ノンブロッキングを基本とします。 | 通信先に関係なくスケールすることができ、スケーラビリティが向上します。 また、自サービスのコンピューティングリソースを効率的に使うことができます。 |
| 故障 | 自サービス内で発生した障害が、他のマイクロサービスに影響しないようにします。 | あるマイクロサービスで障害が発生しても、他のマイクロサービスは機能を提供し続けることができ、可用性が向上します。 |
おわりに
ここまで、リアクティブマイクロサービスの必要性と、リアクティブマイクロサービスとは何なのかについて説明しました。
私自身もまだ理解がモヤッとしているところもありますし、この記事で細大漏らさず正確に説明もできていません。
詳細に関心を持たれた方は、冒頭にも紹介した Lightbend Academy のアーキテクチャトレーニングパスを受講することをおすすめします。
リアクティブマイクロサービスの実現については、後編 も参照ください。