元々のドキュメントを雑にChatGPTに添削してもらったので、一部、推察の内容が断定的な表現になっている箇所があります。
適宜解釈してください。
はじめに
2024年、AWSはAmazon ElastiCacheでRedis互換エンジン「Valkey」の提供を開始しました。これにより、従来のRedis OSSエンジンからValkeyへ簡単に移行できるようになり、最大33%のコスト削減が期待できます(ノードベースで最大20%、サーバーレス構成で最大33%)。
🔗 公式ブログ:Amazon ElastiCache for Valkey の紹介(AWS公式)
ValkeyはRedis 7.2をフォークしたOSSであり、完全なAPI互換性を持ちながら、以下のような追加的なメリットがあります:
- マルチスレッド対応によるI/Oとメモリ使用効率の改善
- フェイルオーバーの堅牢化
- シャード数の削減による可用性・レイテンシの改善
これらにより、パフォーマンス・コスト・運用性の三拍子がそろったアップグレードといえます。
対象とする前提
本記事では、**Cluster Mode enabled(シャード構成有効)**のRedisクラスターを対象とし、インプレースアップグレードにフォーカスします。
移行方式の検討
Valkey移行に際して検討できる方式は大きく2通りです:
-
Blue/Green方式(クラスター新設+データ移行)
別クラスターにValkeyで構成を作成し、同期+切り替えを行う。
→ 安全だが、構成管理や切替コストが高い。 -
インプレース方式(既存クラスターのエンジン切替)
既存のクラスター設定を保ったまま、エンジンのみをValkeyへ切り替える。
→ 最小コストかつ最小限のダウンタイムで移行可能。(30秒程度発生することがある)
本記事では、2.インプレース方式について詳しく深掘りします。
インプレース移行の実施方法
インプレース移行は非常に簡単です。以下の操作で完了します。
マネジメントコンソール上で「エンジンの変更」を選択
Redis OSS → Valkey を選択
「変更を適用」ボタンを押すだけ
CLI/APIでも modify-replication-group によって同様の変更が可能です。
🔗 ElastiCache Valkey移行手順(AWS公式ブログ)
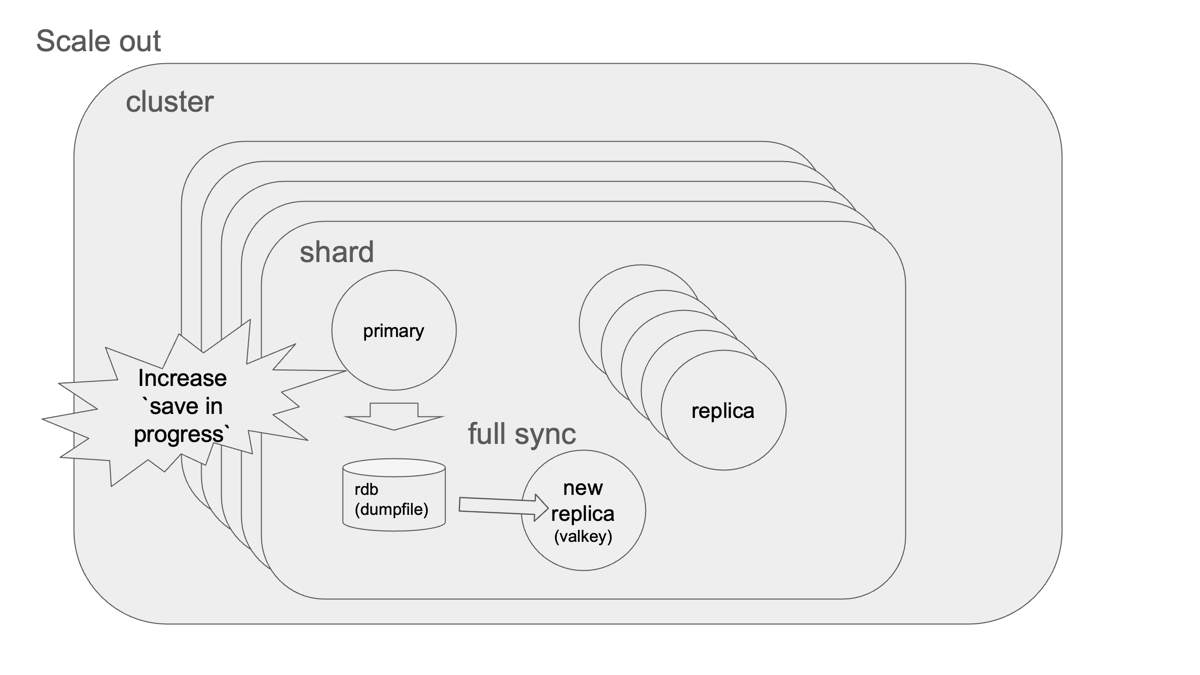
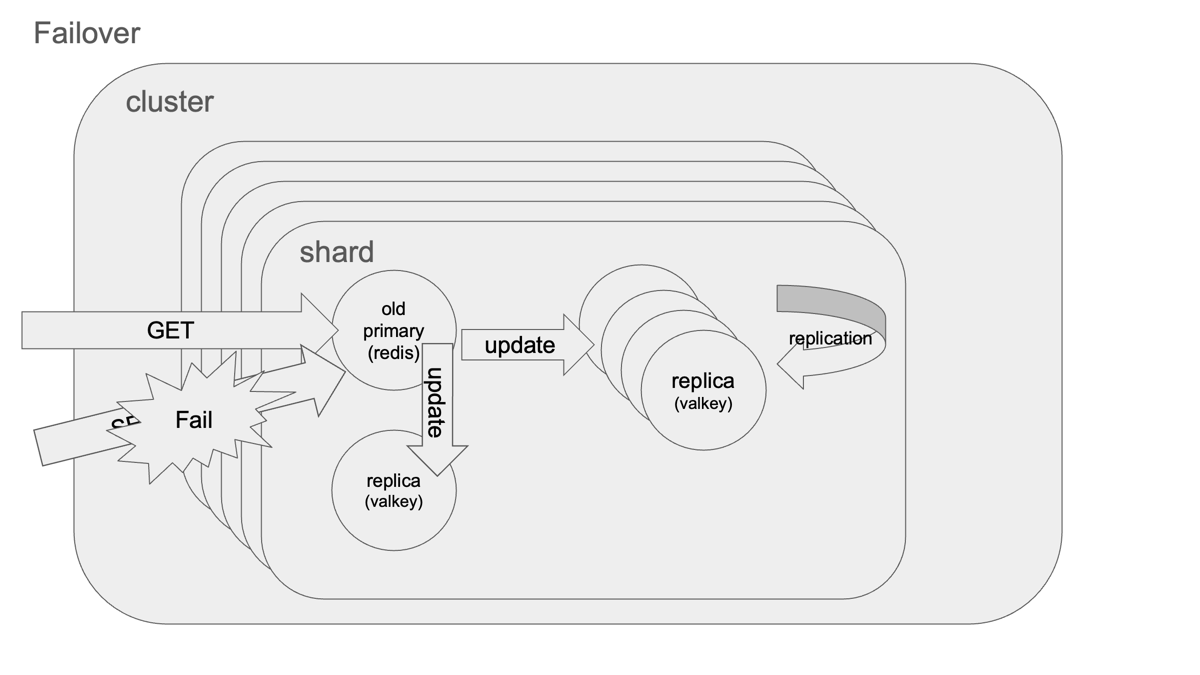
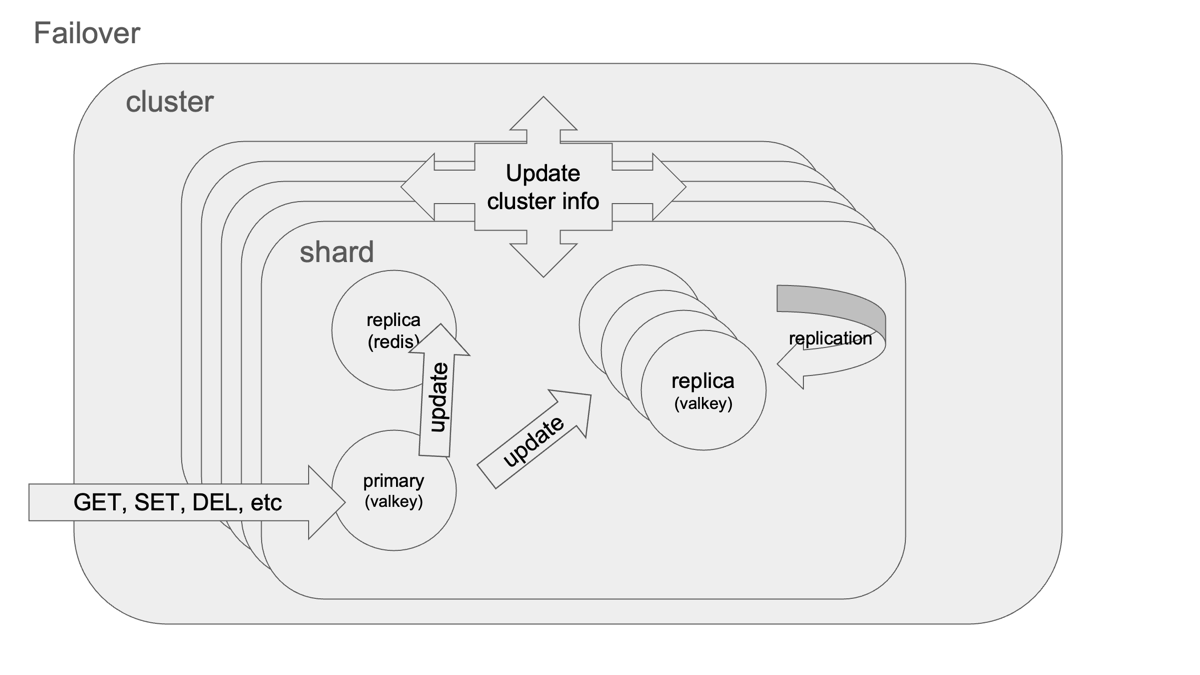
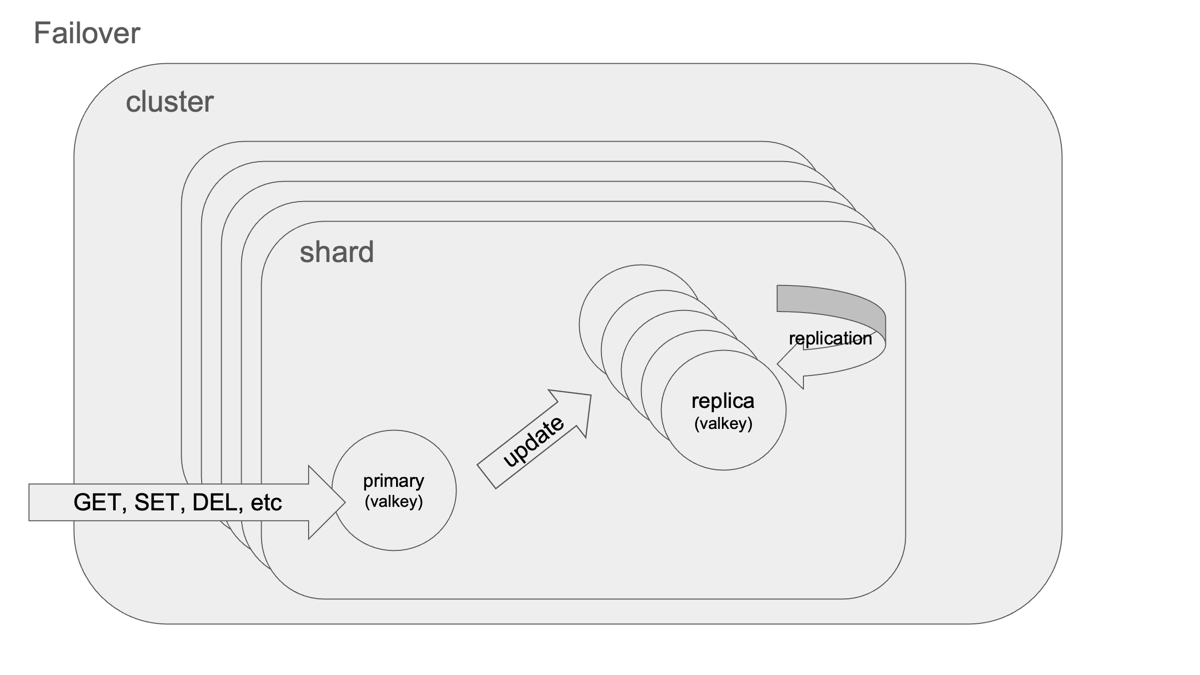
インプレースアップグレードの内部動作
このボタンひとつの背後で、ElastiCacheは各シャード単位で順次Failoverを実施しています。AWSのイベントログで確認すると、以下の挙動が見られます:
- 新ノードが立ち上がる
- 対象シャードでFailoverが発生し、リプリカがマスターに昇格
- 元マスターが停止、クラスター全体に変更が伝搬される
この流れはRedis公式ドキュメントで紹介されている 「extra node方式のローリングアップグレード」 に準拠しています。
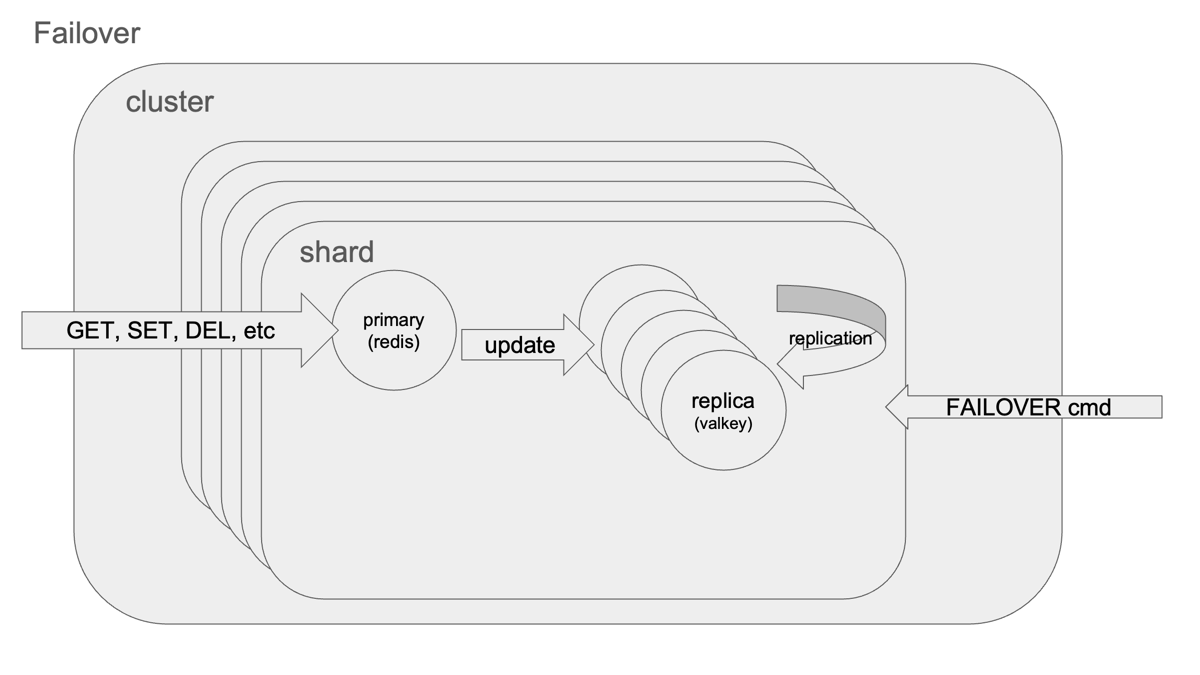
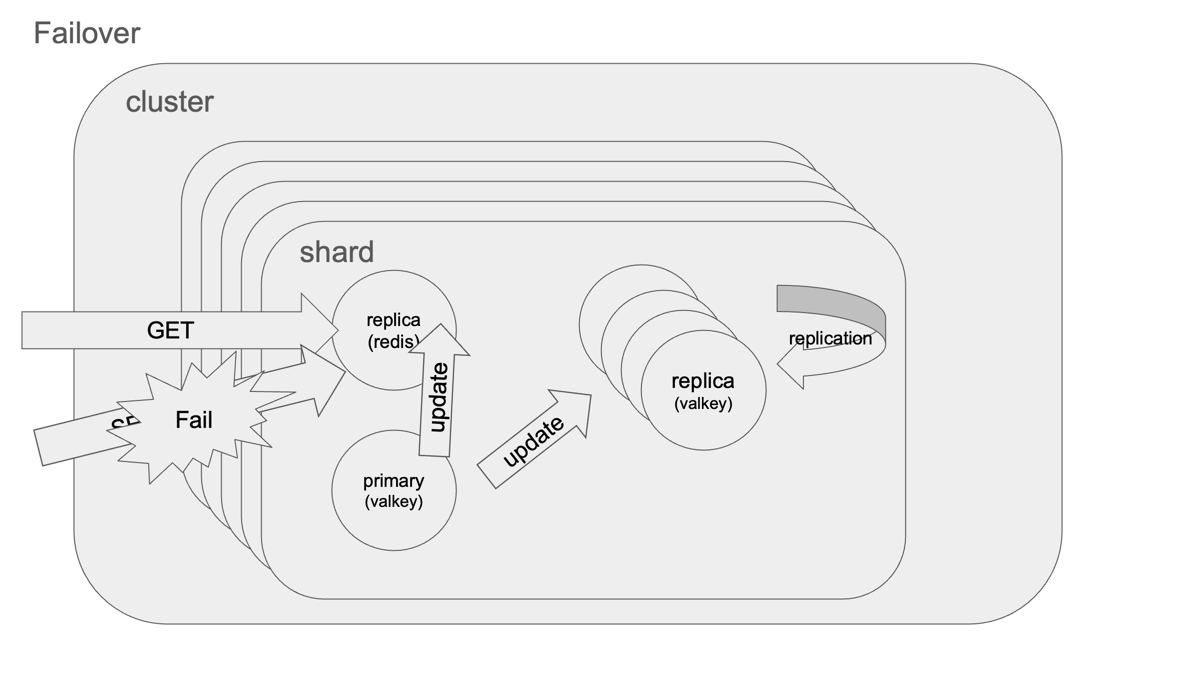
Failoverのしくみと安全性
Failover処理は CLUSTER FAILOVER コマンドにより、マスターとレプリカ間で安全にハンドオーバーされるよう設計されています。
🔗 CLUSTER FAILOVER(Redis公式ドキュメント)
主な流れ:
- レプリカがマスターに対してクエリの停止を要求
- マスターは現在のレプリケーションoffsetを返す
- レプリカがoffset一致を確認後に昇格
- 新マスターがクラスタ設定をブロードキャスト
- 旧マスターはMOVED/ASKリダイレクトで応答
このように、データ整合性を最大限保ちながらノードの切り替えが行われます。
実装コードから見る動作の詳細
FailoverのロジックはRedis OSSのコードに実装されており、以下で確認できます:
masterの切り替え実装:
cluster.c#L2915-L2933
クライアントへのMOVED/ASK応答:
server.c#L2592
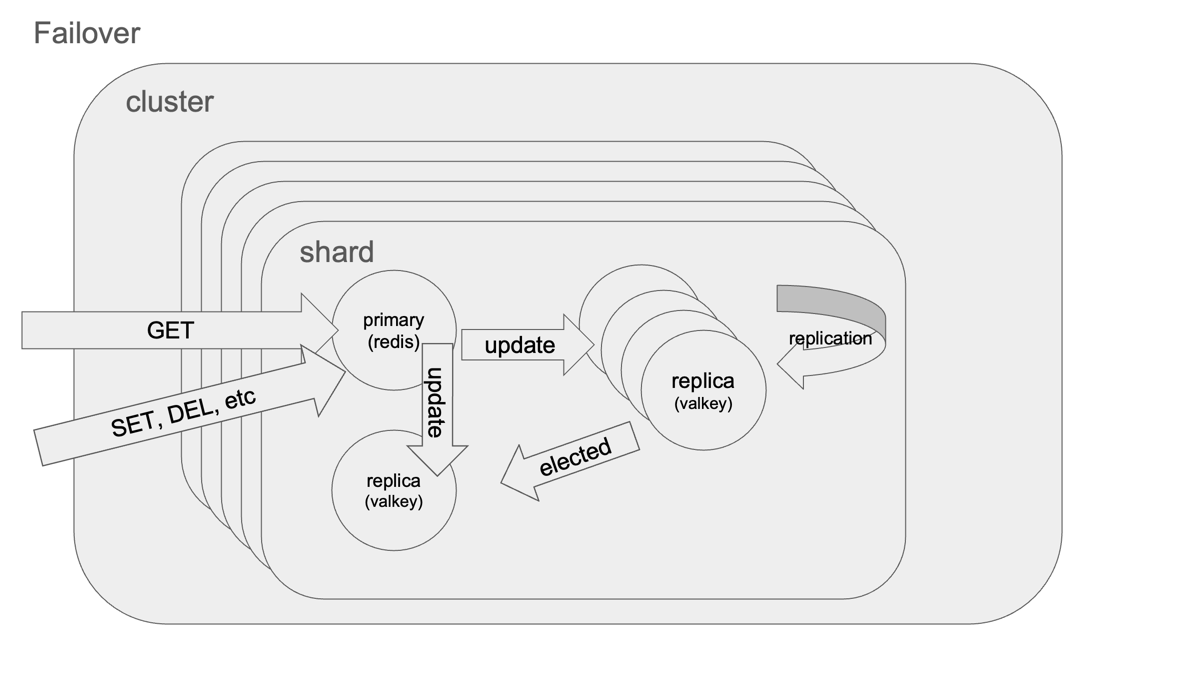
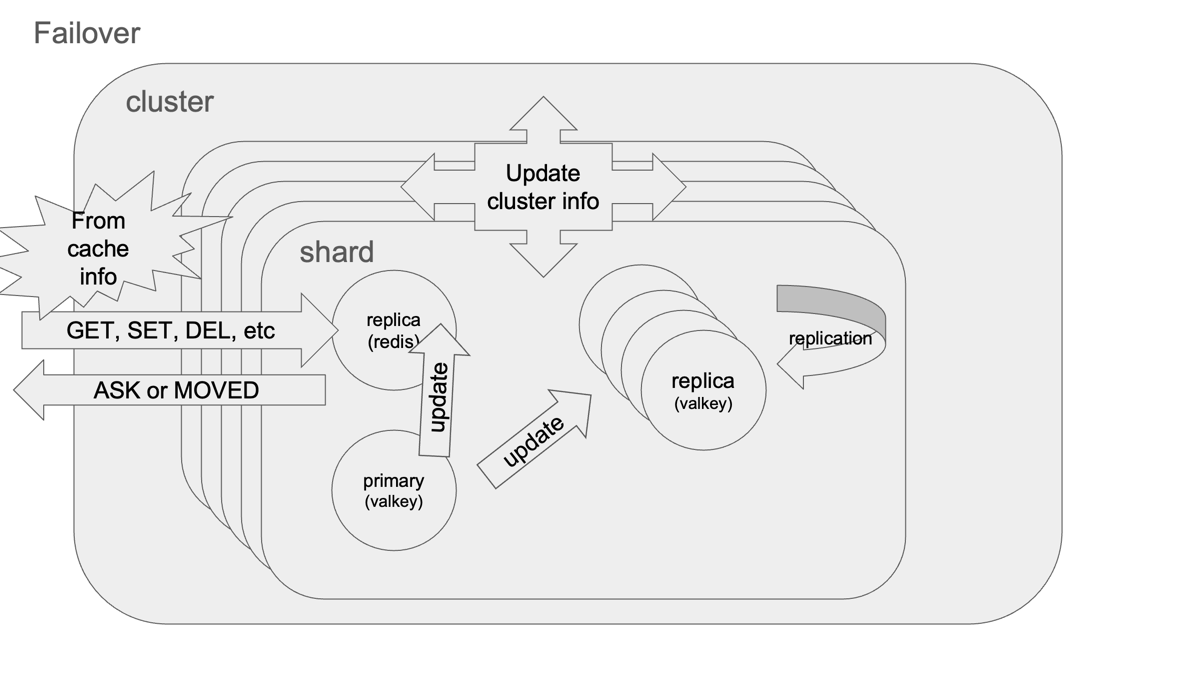
データロスのリスクとレプリケーション
Redisクラスターでは 非同期レプリケーション が採用されているため、原理上わずかに書き込みが失われる可能性があります。
🔗 Cluster Specification(Redis公式)
要点:
- 書き込みはまずマスターに適用され、レプリカへ非同期伝搬される
- マスターがクラッシュし、レプリカへ未伝搬だった場合、書き込みは失われる
ただし、多くのケースではクライアントACKとレプリカ伝搬がほぼ同時であり、観測できるデータロスは非常に小さい
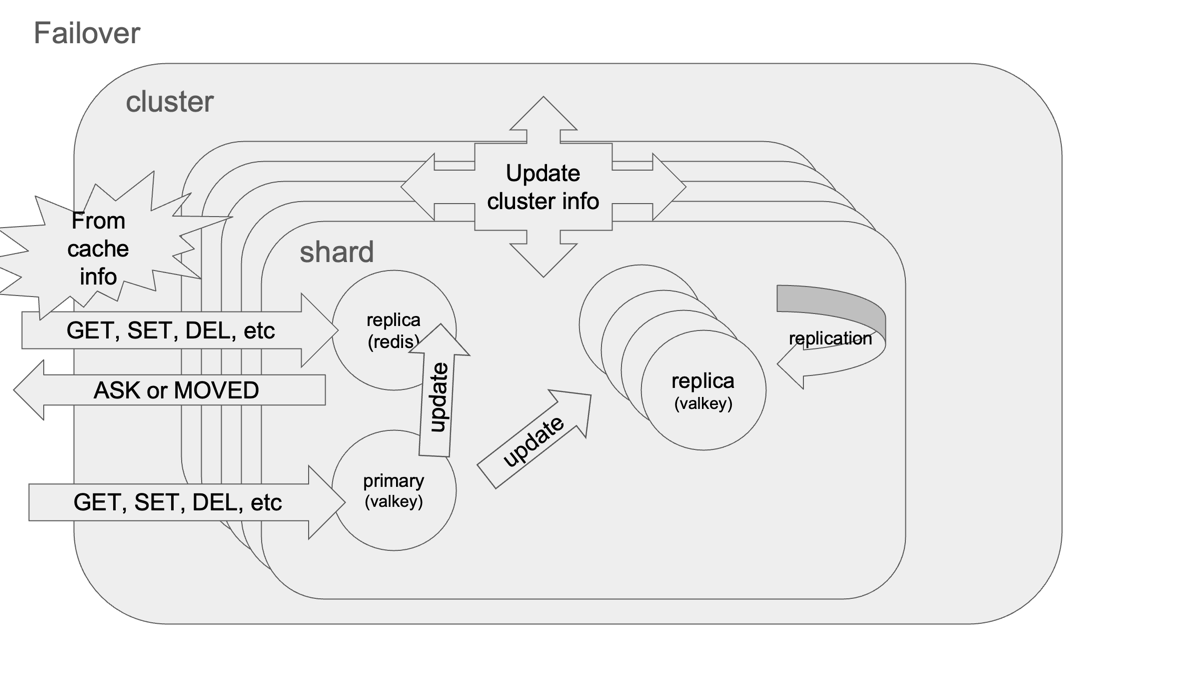
レプリケーションの内部動作と安全性の仕組み
🔗 Replication(Redis公式)
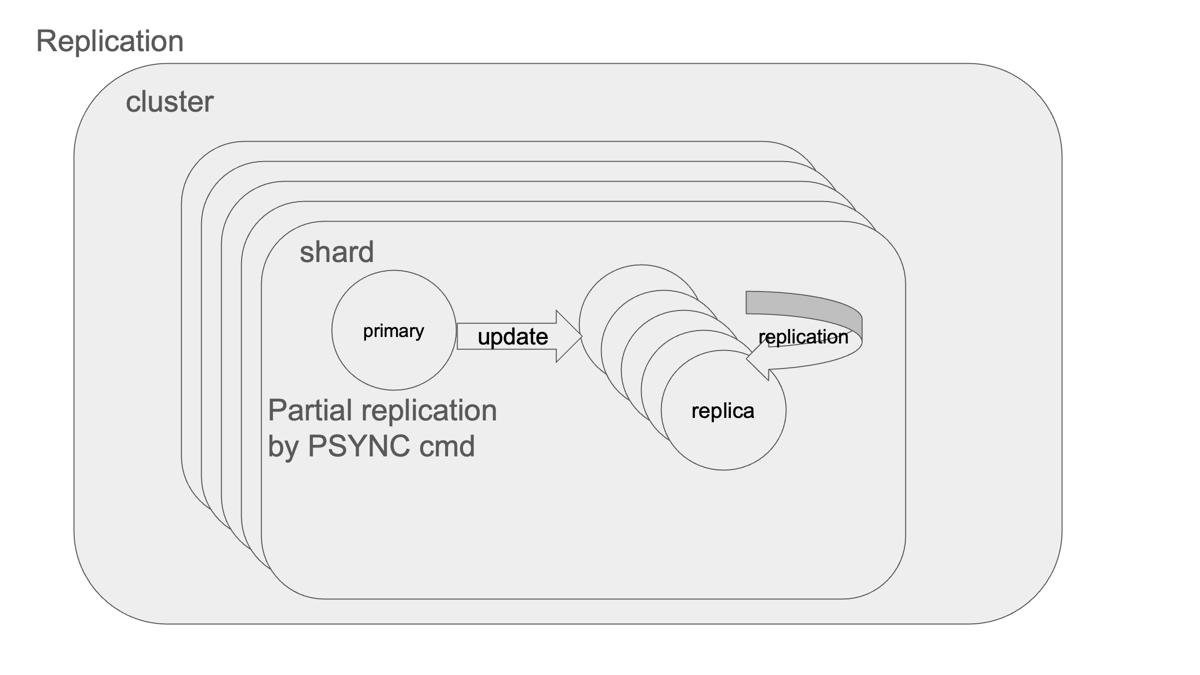
- 通常は PSYNC による 部分同期(オフセットベース)
- 不整合・バッファ切れ時は フル同期(RDBスナップショット+コマンドバッファ)
- Redis 2.8.18以降は ディスクレスレプリケーション により高速化
- replication IDとoffsetにより、新旧レプリカ間でも整合性が維持される
つまり、Failover後も他のレプリカは部分同期のみで済むため、再構成は極めて高速・安全です。
まとめ
| 項目 | 内容 |
|---|---|
| 🎯 方法 | インプレース方式(1クリック/CLI)で簡単に移行 |
| 💰 コスト削減 | ノードで最大20%、サーバーレスで最大33%削減 |
| 📈 性能向上 | マルチスレッド対応・I/O効率・レイテンシ改善 |
| 🔁 安全性 | シャード単位Failoverで最小のダウンタイム |
| ⚠️ リスク | 非同期レプリケーションによる最小限のデータロス可能性(理論上) |
| 🛠 補足 | Valkey用パラメータグループ作成・Redis 7.2との互換性確認が必要 |
追記
自分の中での理解を可視化したもの