COTOHA APIとは??
NTTが長年頑張って得たノウハウを詰め込んだ、NTTコミュニケーションズが提供する自然言語処理のAPIサービスになります!!
サービスの詳細 はこちらを見て頂くとして、これまでは構文解析やユーザ属性推定などのテキスト解析のサービスを提供していました。
- Python初心者

- COTOHA API 初心者
"自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた"で、テキスト解析で遊んでもらってからこの記事を見て頂くことをオススメします!!
さて本題に入りましょう!!
今回はテキストではなく... 音声認識 !!
今までCOTOHAは、テキストしか相手にしてくれませんでした... ![]()
しかし、音声認識APIが2019年3月にリリースされCOTOHA君が音声言語を理解するようになりました!!しかも、入力フォーマットが
- 音声ファイル形式
- ストリーミング音声形式
の2パターンで提供しているため、様々なユースケースで音声認識をお試し頂けます!

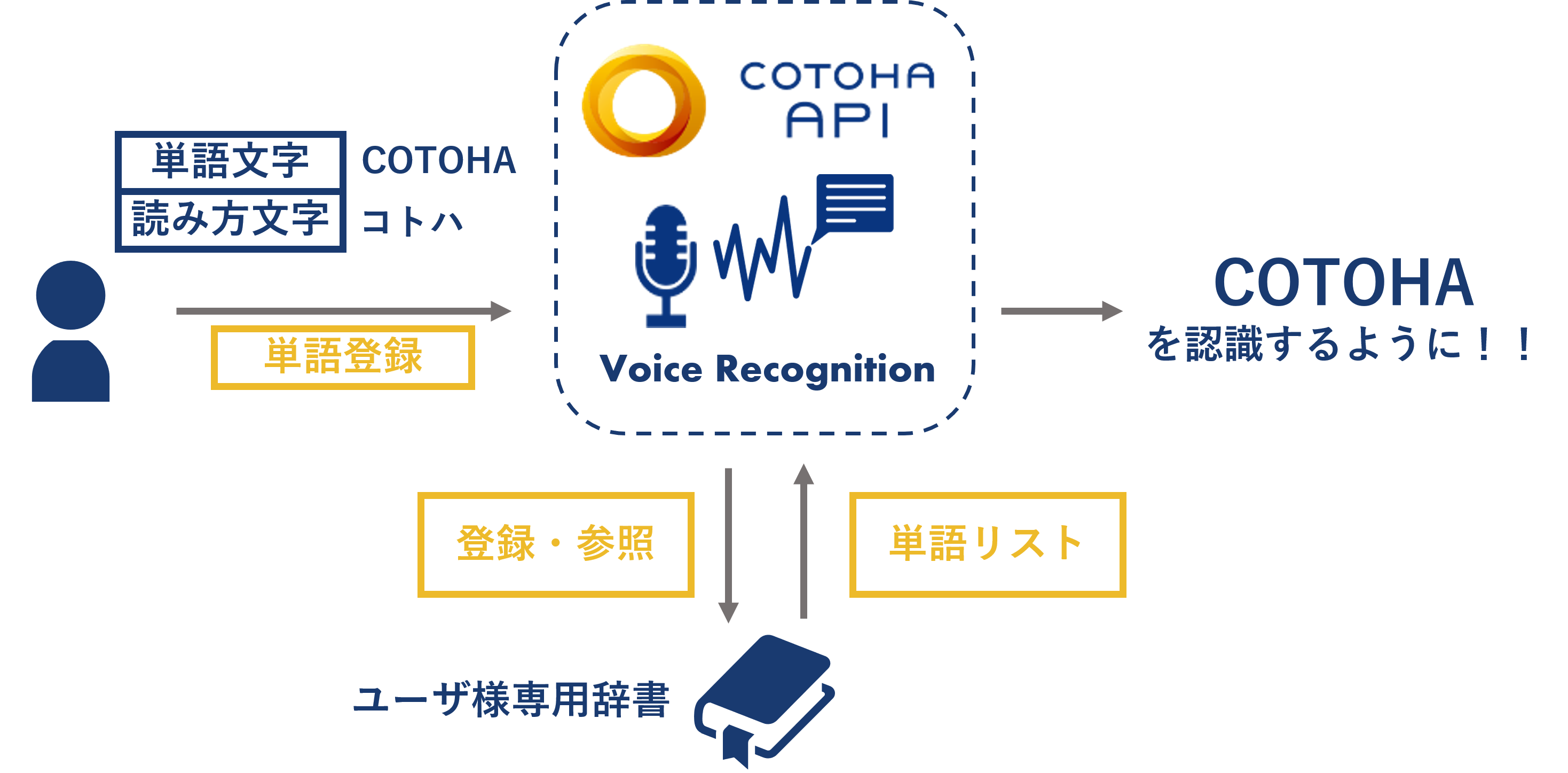
さらに! COTOHAは,固有名詞を覚えることも !!! 
このCOTOHA君単語登録ができるため、固有名詞を教えることもできます。
例えば,COTOHA と言って,音声認識しても,ことは・事は など,同音異義語で認識されてしまったりします.
そこに辞書登録を行うことで, COTOHA が出る確率を増やして,認識精度を向上させることができます.
実際のところ、
- 自社の商品名を認識させたい

- 思ったフレーズが出ないので出やすくしたい!

といった場面で、大活躍な機能となっています!!
しかも、この単語登録には実際の単語文字と読み方の文字(カタカナ)のペアがあれば良いので、わざわざ音声を収録して登録なんて面倒なことが必要ありません!!
音声認識やってみましょう !
では,実際にやってみましょう!!
今回は,Pythonを使ってファイル音声認識を行います.
サンプルコード on GitHub
GitHub にサンプルコードを
を公開していますので,そちらを参考にしてください!!
APIアカウント認証
認証情報ファイルは、json形式でまとめています。
Source Code | クリックしてください
{
"client_id":"XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"client_secret":"YYYYYYYYYYYYYYYY",
"domain_id":"ZZZZZZZZ"
}
ファイル音声認識
ライブラリのインポート & プロパティ情報
Source Code | クリックしてください
import requests
import json
import sys
import wave
args = sys.argv
audio_name = args[1] # 音声ファイルのパス
json_name = args[2] # 認証情報ファイルパス
oauth_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
model_id = 'ja-gen_tf-16'
hostname = 'https://api.ce-cotoha.com/api/'
url = hostname + 'asr/v1/speech_recognition/' + model_id
with open(json_name) as f:
credential = json.load(f)
client_id = credential['client_id']
client_secret = credential['client_secret']
domain_id = credential['domain_id']
Interval = 0.24 # 1メッセージあたり240msの音声データ
wf = wave.open(audio_name, 'rb')
rate = wf.getframerate()
wf.close()
アクセストークンの取得
Source Code | クリックしてください
headers = {"Content-Type": "application/json;charset=UTF-8"}
obj = {'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret}
data_json = json.dumps(obj).encode("utf-8")
response = requests.post(url=oauth_url, data=data_json, headers=headers)
access_token = response.json()['access_token']
Requestの作成 & 送信
Source Code | クリックしてください
### MIME_TYPE設定 & ヘッダー作成
MIMETYPE_JSON = 'application/json'
MIMETYPE_AUDIO = 'application/octet-stream'
headers = {'Authorization': 'Bearer '+access_token}
### パラメータパート作成: 音声認識開始要求パート
request_json = {
"msg": {
"msgname": "start"
},
"param": {
"baseParam.samplingRate": rate,
"recognizeParameter.domainId": domain_id,
"recognizeParameter.enableContinuous": True
}
}
### 音声データパート作成: バイナリ音声データを送信パート
wf = wave.open(audio_name, 'rb')
fileDataBinary = wf.readframes(wf.getnframes())
wf.close()
### コマンドパート: 音声認識終了要求パート
command_json = {
"msg": {
"msgname": "stop"
}
}
### マルチパートエンコード → 辞書型オブジェクトに変換
files = [
('parameter', (None, json.dumps(request_json), MIMETYPE_JSON)),
('audio', (None, fileDataBinary, MIMETYPE_AUDIO)),
('command', (None, json.dumps(command_json), MIMETYPE_JSON))
]
### POSTリクエスト
response = request.post(url, headers=headers, files=files)
認識結果の出力
Source Code | クリックしてください
# statusが200のときのみresponseにjsonが含まれる
if response.status_code == 200:
for res in response.json():
# type=2ではsentenceの中身が空の配列の場合がある
if res['msg']['msgname'] == 'recognized' and res['result']['sentence'] != []:
print(res['result']['sentence'][0]['surface'])
else:
print("STATUS_CODE:", response.status_code)
print(response.text)
辞書登録による精度向上
本記事のメインテーマです.
COTOHA君に,言葉を覚えていただきましょう!!
今,音声認識して,Slack Webhook APIで投稿する簡単なアプリを作ってます. ↓↓↓
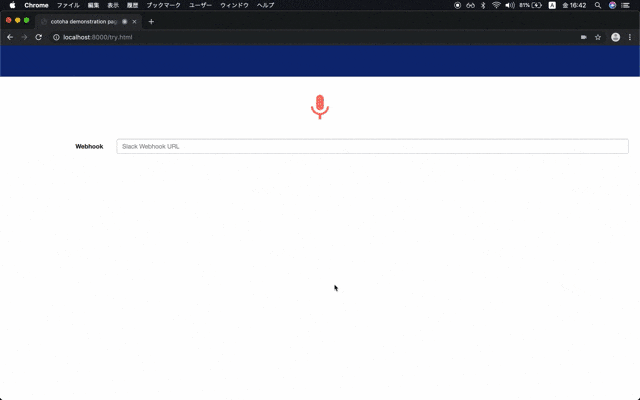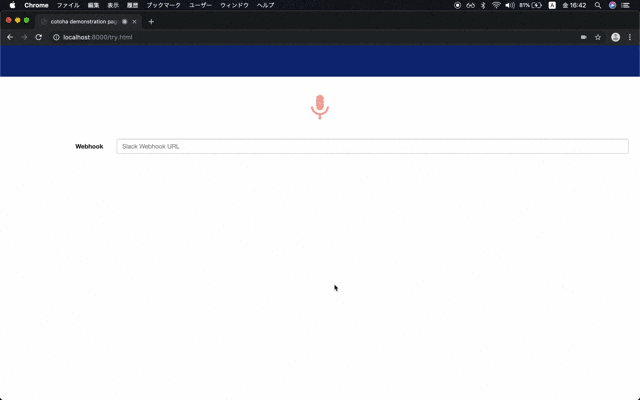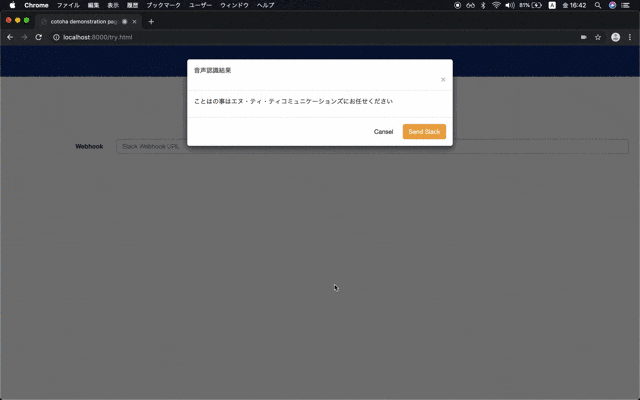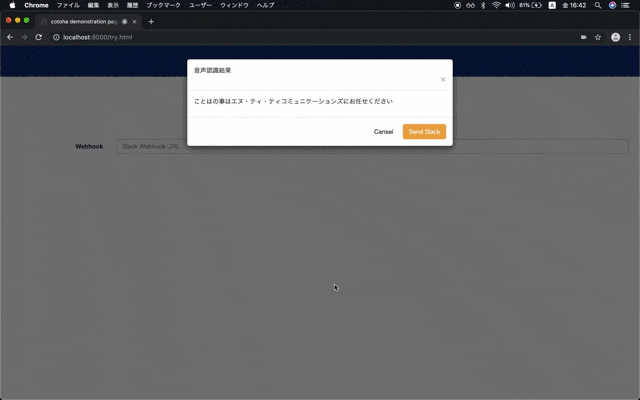
しかし,COTOHAが COTOHAという自分の名前すら認識しない...
そこで,辞書登録を使いましょう.
辞書登録
辞書ファイル
辞書データのフォーマットは TSVファイルで記述します.
[表示して欲しい文字列]`<TAB>`[読み方(全角カタカナ)]
の形式で以下のように記述します
COTOHA コトハ
エヌ・ティ・ティコミュニケーションズ株式会社 エヌティティコミュニケーションズカブシキガイシャ
辞書登録
実際に辞書登録します
Source Code | クリックしてください
url = "https://api.ce-cotoha.com/api/asr/v1/speech_words/upload?domainid=" + domainid
### ヘッダー設定
headers = {"Authorization":"Bearer " + access_token}
### tsv_name : 辞書TSVファイルのパスを指定
file = {"cascadeword": open(tsv_name, 'rb')}
### リクエスト送信
res = requests.post(self.url, files=file, headers=headers)
### レスポンス出力
print(res.text)
レスポンス結果
以下のように,登録が成功したらsuccessとレスポンスが返ってきます.
--Boundary_3_1519969759_1562293676854
Content-Type: text/plain
Content-Disposition: form-data; name="status"
code : 200
message : OK
detail : success
--Boundary_3_1519969759_1562293676854
Content-Type: text/plain
Content-Disposition: form-data; name="cascadeword"
COTOHA コトハ M -3.0
エヌ・ティ・ティコミュニケーションズ株式会社 エヌティティコミュニケーションズカブシキガイシャ M-3.0
--Boundary_3_1519969759_1562293676854--
辞書更新の結果
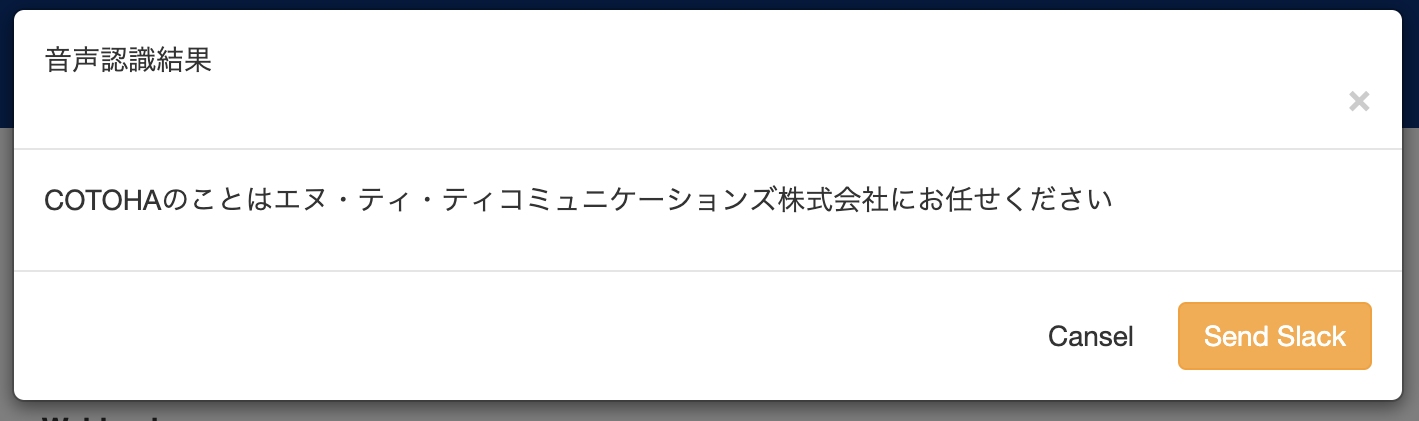
しっかり,COTOHAとエヌ・ティ・ティコミュニケーションズの固有名詞が出るようになりました!!
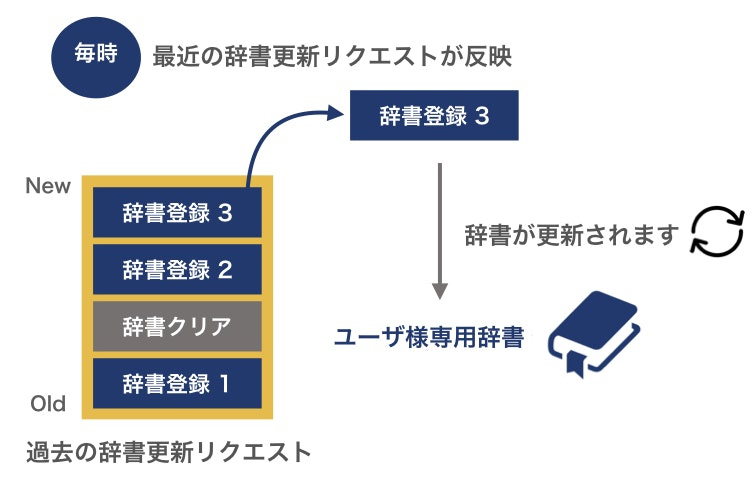
注意!! : 辞書の更新の仕組み・タイミング
COTOHA君は,1時間に1回更新のタイミングで行なっていますので,最後の辞書更新・辞書クリアのリクエストに応じて辞書更新が行われます.
まとめ
COTOHA音声認識に言葉を覚えさせてみました!!
それによって,専門用語や略称なども音声認識可能になります.
現在は,Enterprise版のみの提供となっておりますが,
3ヶ月無料枠があるので,そちらでお試しください!!