COTOHA音声認識を中の人が仕組みからサンプルまで軽く解説
COTOHA APIのラインナップに音声認識をリリースしました!!
しかし,いざAPIを動かそうと思っても,音声データは画像・テキストと比べて前処理が面倒...
そこで本記事では,実際にCOTOHA音声認識の中の人がPythonで音声認識APIを実行する方法を説明していきます!!
COTOHA APIとは
NTTが長年頑張って得たノウハウを詰め込んだ、NTTコミュニケーションズが提供する自然言語処理のAPIサービスになります!!
サービスの詳細 はこちらを見て頂くとして、これまでは構文解析やユーザ属性推定などのテキスト解析のサービスを提供していました.
- Python初心者

- COTOHA API 初心者
自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみたで、テキスト解析で遊んでもらってからこの記事を見て頂くことをオススメします!!
さて本題に入りましょう!!
今回はテキストではなく... 音声認識 !!
今までCOTOHAは、テキストしか相手にしてくれませんでした... ![]()
しかし、音声認識APIが2019年3月にリリースされCOTOHA君が音声言語を理解するようになりました!!しかも、入力フォーマットが
- 音声ファイル形式
- ストリーミング音声形式
の2パターンで提供しているため、様々なユースケースで音声認識をお試し頂けます!
現在,For Enterprise版の提供のみとなっていますが,3ヶ月のお試し期間があるためそちらを使ってお試しいただければと思います!!

音声認識APIってどうなってるの??
音声認識 → 音声データを入れたらテキストが返ってくる
っていうのは分かりました.
では,実際に音からどのように言語にしているのかをさらっと解説します.
音声認識API構成図
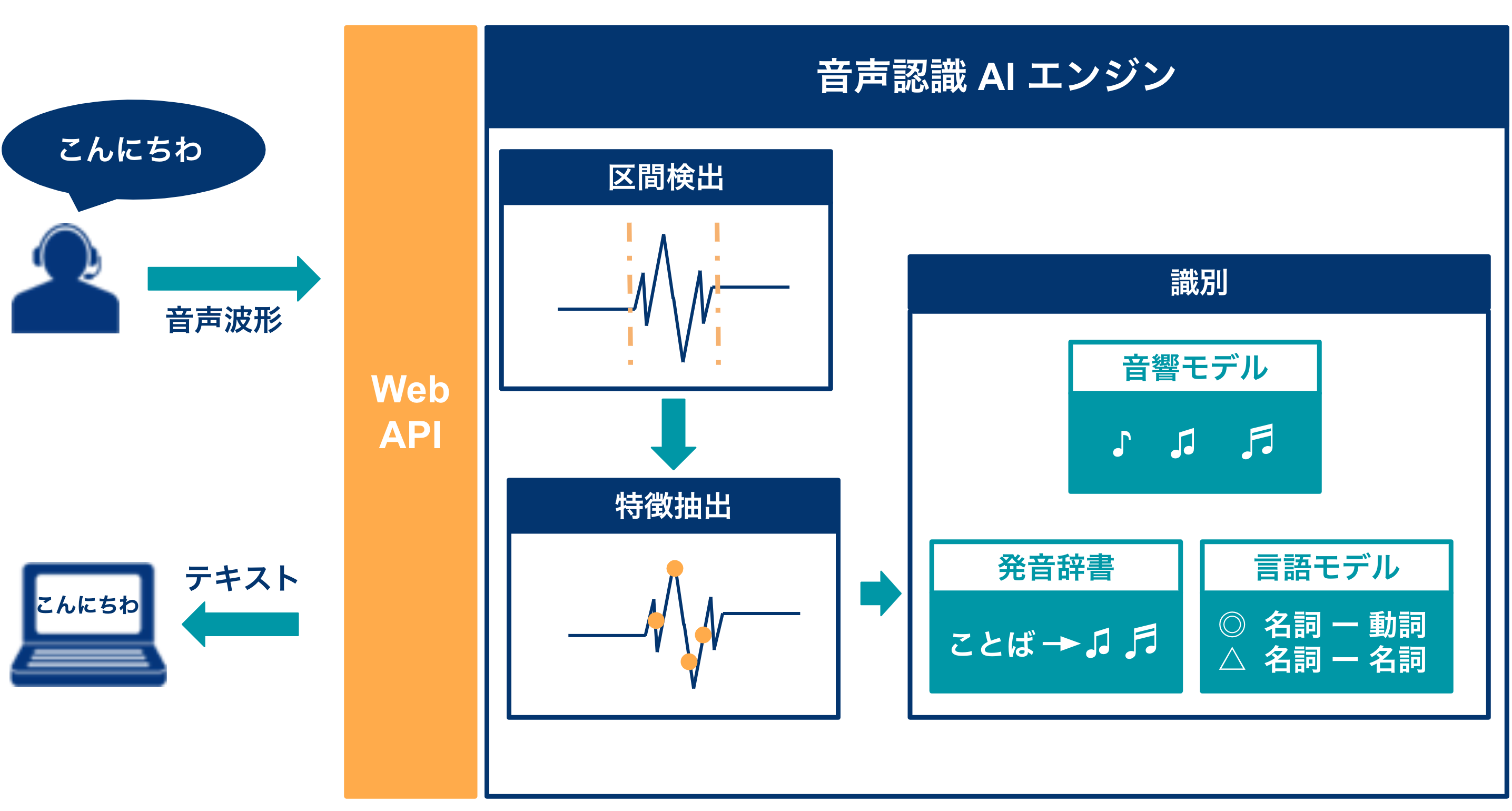
COTOHA音声認識APIは,上記のような構成をしております.
- 区間検出
入力された音の波形から,話をしている部分を抽出する部分.
抽出した部分だけが,認識処理の対象になります.
- 特徴抽出
音声認識特有の特徴を抽出する部分.
これを行うことで,言語認識の精度を向上させます.
- 識別
取得した特徴から,テキストを生成.
3つのモデルの結果を基に,最適なテキストを生成
3つのモデル
音響モデル - 音波を基に予測を行うモデル
発音辞書 - 音素 を基に予測を行うモデル
言語モデル - 文法 を基に予測を行うモデル
サンプルコード on GitHub
GitHub にサンプルコードを
を公開していますので,そちらを参考にしてください!!
APIの使い方解説
それでは,どのように音声認識APIを使えば良いのかを,GitHubに公開しているサンプル
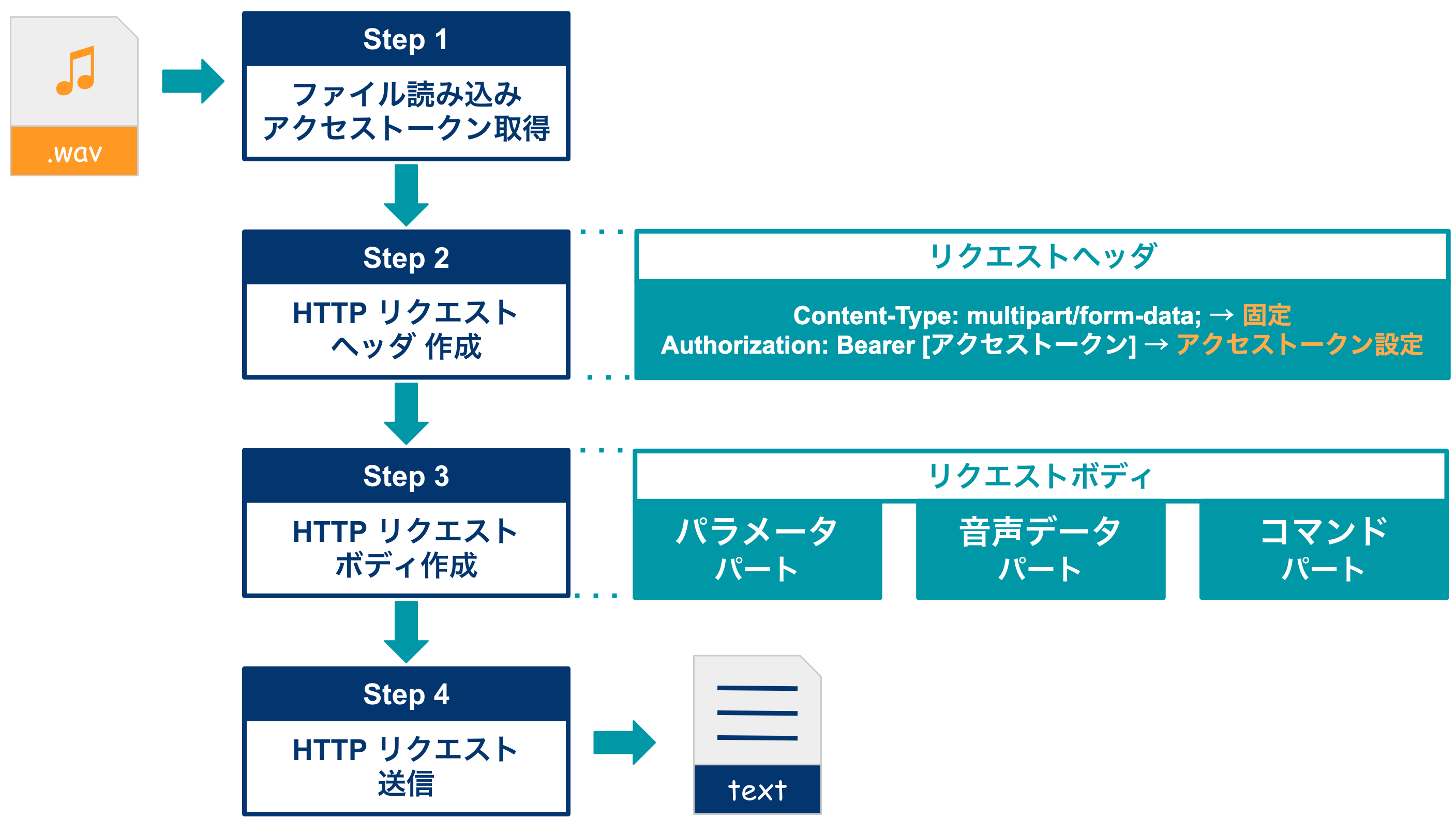
ファイル音声認識
API実行プログラムの大まかな処理フローは以下の通りです.
GitHub
ライブラリのインポート & プロパティ情報
Source Code | クリックしてください
import requests
import json
import sys
import wave
args = sys.argv
audio_name = args[1] # 音声ファイルのパス
json_name = args[2] # 認証情報ファイルパス
oauth_url = 'https://api.ce-cotoha.com/v1/oauth/accesstokens'
model_id = 'ja-gen_tf-16'
hostname = 'https://api.ce-cotoha.com/api/'
url = hostname + 'asr/v1/speech_recognition/' + model_id
with open(json_name) as f: # 認証情報ファイルの読み込み
credential = json.load(f)
client_id = credential['client_id']
client_secret = credential['client_secret']
domain_id = credential['domain_id']
Interval = 0.24 # 1メッセージあたり240msの音声データ
wf = wave.open(audio_name, 'rb')
rate = wf.getframerate()
wf.close()
認証情報ファイル
認証情報はjson フォーマットで管理しています.
{
"client_id": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX",
"client_secret": "YYYYYYYYYYYYYYYYY",
"domain_id": "ZZZZZZZZ"
}
アクセストークンの取得
Source Code | クリックしてください
ここでは,クライアントIDとシークレットから,アクセストークンを発行します.
headers = {"Content-Type": "application/json;charset=UTF-8"}
obj = {'grantType': 'client_credentials', 'clientId': client_id, 'clientSecret': client_secret}
data_json = json.dumps(obj).encode("utf-8")
response = requests.post(url=oauth_url, data=data_json, headers=headers)
access_token = response.json()['access_token']
リクエストの作成 & 送信
Source Code | クリックしてください
ファイル音声認識APIのリクエストは,マルチパートエンコードで構成されているため.
図のようなHTTPリクエスト(ヘッダ, パラメータパート,音声データパート,コマンドパート)を作成します.
### MIME_TYPE設定 & ヘッダ作成
MIMETYPE_JSON = 'application/json'
MIMETYPE_AUDIO = 'application/octet-stream'
headers = {'Authorization': 'Bearer '+access_token}
### パラメータパート作成: 音声認識開始要求パート
request_json = {
"msg": {
"msgname": "start"
},
"param": {
"baseParam.samplingRate": rate,
"recognizeParameter.domainId": domain_id,
"recognizeParameter.enableContinuous": True
}
}
### 音声データパート作成: バイナリ音声データを送信パート
wf = wave.open(audio_name, 'rb')
fileDataBinary = wf.readframes(wf.getnframes())
wf.close()
### コマンドパート: 音声認識終了要求パート
command_json = {
"msg": {
"msgname": "stop"
}
}
### マルチパートエンコード → 各パートを1つのリクエストとしてまとめる
files = [
('parameter', (None, json.dumps(request_json), MIMETYPE_JSON)),
('audio', (None, fileDataBinary, MIMETYPE_AUDIO)),
('command', (None, json.dumps(command_json), MIMETYPE_JSON))
]
### POSTリクエスト
response = request.post(url, headers=headers, files=files)
認識結果の出力
Source Code | クリックしてください
# statusが200のときのみresponseにjsonが含まれる
if response.status_code == 200:
for res in response.json():
# type=2ではsentenceの中身が空の配列の場合がある
if res['msg']['msgname'] == 'recognized' and res['result']['sentence'] != []:
print(res['result']['sentence'][0]['surface'])
else:
print("STATUS_CODE:", response.status_code)
print(response.text)
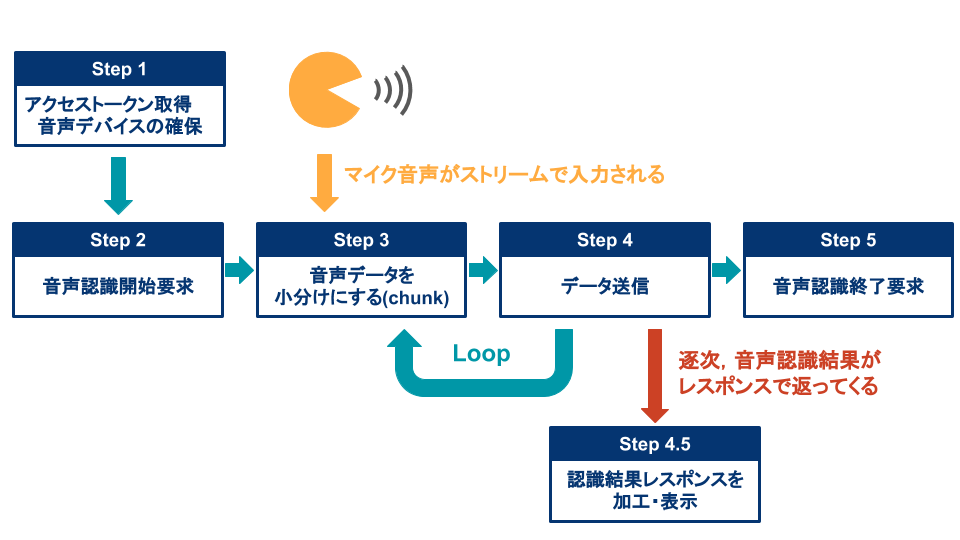
ストリーミング音声認識
API実行プログラムの大まかな処理フローは以下の通りです.
ライブラリのインポート & プロパティ情報
アクセストークンの取得
は,ファイル音声認識と同じなので,そちらを参考にしてください.
GitHub
パラメータ設定
ストリーミング音声認識に必要なパラメータは以下の通りです.
Source Code | クリックしてください
def __init__(self):
self.channels = 1 # モノラル指定
self.format = pyaudio.paInt16 #音声データをInt16で扱う
self.rate = 44100 # 入力のサンプリングレート(Macbookのマイク)
self.Interval = 0.24 # COTOHA APIの仕様により
self.nframes = int(self.rate * self.Interval) # 1秒あたりのフレーム数
"""
↓↓↓ ファイル音声認識と同様
"""
self.url = url
self.client_id = client_id
self.client_secret = client_secret
self.param_json = {"param": {
"baseParam.samplingRate": self.rate,
"recognizeParameter.domainId": domain_id,
"recognizeParameter.enableContinuous": 'true'
}}
音声認識開始要求
まず,COTOHA APIに今から音声認識を開始することを宣言します.
Source Code | クリックしてください
def start(self): # 開始要求
obj = self.param_json
obj['msg'] = {'msgname': 'start'}
data_json = json.dumps(obj).encode("utf-8")
headers = {"Content-Type": "application/json;charset=UTF-8",
"Authorization": "Bearer " + self.access_token}
self.requests = requests.Session()
self.response = self.requests.post(url=self.url, data=data_json, headers=headers)
self.check_response()
# uniqueIdはデータ転送、停止要求に必要
self.unique_id = self.response.json()[0]['msg']['uniqueId']
マイクから音声をストリーム形式で音声認識
マイク入力から,ストリーミング音声認識をしていきます.
Source Code | クリックしてください
マイクからの音声入力には,pyaudioというライブラリを使います.
ストリーミング音声 → 音声認識
import pyaudio
def listen(self):
# COTOHA APIのデータ送信リクエストヘッダ
self.headers = {"Content-Type": "application/octet-stream",
"Unique-ID": self.unique_id,
"Authorization": "Bearer " + self.access_token}
# Pyaudio インスタンス 作成
p = pyaudio.PyAudio()
# デバイス音声をストリーミング入力
stream = p.open(format=self.format,
channels=self.channels,
rate=self.rate,
input=True,
frames_per_buffer=self.nframes
)
print("Now Recording")
# 音声認識中
try:
while True:
self.data = stream.read(self.nframes, exception_on_overflow=False)
self._post() #### データ送信リクエスト
# "Ctrl+C" でプログラム終了
except KeyboardInterrupt:
stream.close()
p.terminate()
sys.exit("Exit Voice Recognition")
データ送信リクエスト
def _post(self):
self.headers = {"Content-Type": "application/octet-stream",
"Unique-ID": self.unique_id,
"Authorization": "Bearer " + self.access_token
}
self.response = self.requests.post(url=self.url, data=self.data, headers=self.headers)
self.check_response() ### 認識レスポンスが正常かチェック
self.print_result() ### 結果を表示
認識レスポンスチェック & 結果表示
def check_response(self): # エラー発生時の処理
if self.response.status_code not in [200, 204]:
print("STATUS_CODE:", self.response.status_code)
print(self.response.text)
exit()
def print_result(self): # レスポンスをパースし認識結果を標準出力
# statusが200のときのみresponseにjsonが含まれる
if self.response.status_code == 200:
for res in self.response.json():
if res['msg']['msgname'] == 'recognized':
# type=2ではsentenceの中身が空の配列の場合がある
if res['result']['sentence'] != []:
print(clean_response(res['result']['sentence'][0]['surface']))
音声認識結果出力例
↓↓↓ Macのターミナルで実行した場合の表示例です.
Now Recoding
組織論についても聞いたんですよ。
でも組織は問題にフォーカスしてもよくならない。
どういうことですか日本語はわかるけど具体的にあったりとわかんないで教えてくださいって教わったのが。
例えば今は店長がいてスーパーバイザーがいてその上の人だよねよね部長がいいのかそうだね部長の上に部長が
いて傾斜につながってるそう言う組織だよねマクドナルドと同じなんで分かるんですけどその場合例えば自分で
はぴったりと自分のいたとに動いてくれたら理想のエリア作れるようなところが例えば何だけ。
まとめ
COTOHAの音声認識APIをご紹介しました.
- ファイル音声認識API
- ストリーミング音声認識API
と,2つのフォーマットで提供しているので,用途に合わせて使い分けてみてください!