
この記事は bosyu Advent Calendar 2019 18日目の記事です。
久しぶりに音声認識の話がしたくなったので書いています。前回はDNNが流行る前の音声認識の全容について書きました。今回はその続きで、音声認識システムとか音声認識デコーダーって何やってんの?という話です。
リアルタイム音声認識
音声認識で自分が発話した後、しばらく応答が帰ってこなかったら「使えねー」ってなりますよね。最近のスマホのアシスタントアプリは、まさに会話のように、ある程度のスピードで推定が終わって返事が返ってきます。このように、素早く結果が返ってくる音声認識をリアルタイム音声認識と呼びます。
全ての音声認識にリアルタイム性が必要かというとそうでもなくて、例えば議事録の書き起こしだったり、即時テキストに書き起こされなくても不便のない音声認識もあります。バッチ型とか言ったりしますね。(もちろんリアルタイムに書き起こされたら便利ですけどね。)
さらにおまけとして、発話終了前に音声認識の仮説を絞り込んでどんどん結果を表示していく、早期確定と呼ばれるような技術もあります。フィードバックがすぐ返ってくるので、ユーザー体験的にも良くて、すごく気持ち良いです。
膨大な仮説空間
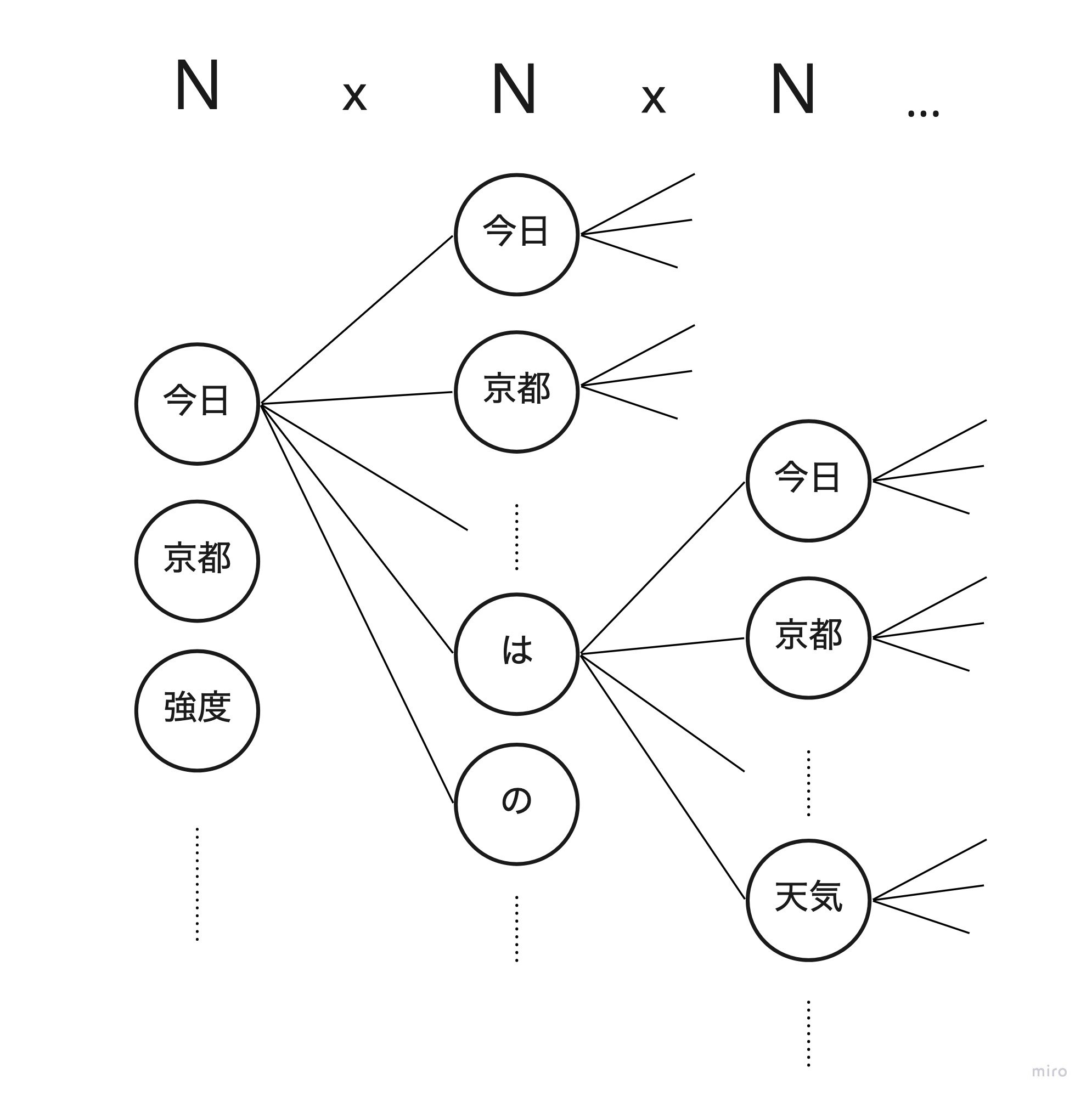
音声認識はハチャメチャな量の仮説空間から結果を絞り込む処理を行います。
音素 x 単語ぐらいなら全候補調べることも可能かもしれませんが、ここに文章が入ってくると途端に計算量が爆発します。
例えば1万語の文章に対する音声認識を動かしたいと考えましょう。
発話した文章の長さは1単語かもしれませんし、10単語かもしれません、100単語、いやもっと長いかもしれません。結局のところ単語数は事前にわからないのです。
1万語の10単語で考えると、考えられる認識結果の組み合わせは 10000^10 になります。
この組み合わせに対して、尤もな結果を求めるために 全探索を行うことは困難 です。
Googleのような超巨大な単語データベースを持つシステムであれば、扱う単語数は100万以上に膨らみます。
これが指数関数的に増えるとなると・・・恐ろしい話ですね。
音声認識デコーダーの役割
全探索が困難なら、絞り込んで検索するしかありません。
音響モデル x 単語辞書 x 言語モデル の理論的な認識性能が90%だとします。
音声認識デコーダーは、この90%の性能のモデルに対して、効率よく計算していかに90%に近しい結果を出すのが目的になります。
なお、テストセットによっては、仮説空間を絞ったことによって局所解に陥り、理論値より上の性能が出てしまうこともあります。それをシステムのおかげで性能があがったと勘違いしてはいけません。
計算量削減のアプローチ
マルチパス探索アルゴリズム
DNNよりも更に前、皆がクラウド!クラウド!言う前に流行った音声認識のスタイルです。
クラウドが台頭する前は、オフラインでかなり限られた計算量の下で動かすしかありませんでした。車載とか特に。
マルチパス探索アルゴリズムの基本戦略は
- 1パス目は粗めに探索してある程度の数の仮説に絞り込む
- 2パス目は1パス目で絞り込んだ仮説に対して精度の高い推定を行う
というものです。マルチパスなので3パス4パスでもいいのですが、まあ2パスが一般的ですね。
「粗め」「精度の高い」とかなんなの?となると思いますので、もう少し詳解すると
- 1パス目は 音響モデルにmono-phone、言語モデルに2-gram で推定する。
- 2パス目は 音響モデルにtri-phone、言語モデルに3-gram で精度をあげて推定する。
のような感じです。1パス目は発話と並行して前向きに探索して、発話が終わったタイミングで、後ろから前に対して再推定を行う。といった実装を知っています。戦略は色々ですね。
メモリの都合上、探索時に各フレームに対して順次仮説を残していくのですが、このときに残す仮説の数 = 探索の幅 = ビーム幅(Beam)と呼んだりします。また、仮説を残すこと = 不要な仮説を削ぎ落とすことなので、前編で説明したオートマトンの遷移を枝にみたてて「枝を刈る」という表現をすることが多いです。論文にBeamって単語が出てきたら枝刈りの話です。
この手法を採用しているデコーダーの内部構成は非常に複雑です。計算量を削減するまで、コードベースでカリカリにチューニングしたり、ヒューリスティック(発見的)な手法が導入されたりと、実装を読み解くのはかなり大変かもしれません。
WFST
クラウドの活用が一般的になってくると、オフラインで音声認識動かすよりも、**サーバーに膨大な計算資源確保しておいて、そこで音声認識動かしたらいいんじゃね?**という話が出てくるのは至極当然ですね。それこそ膨大な計算資源を保有するGoogleの音声認識なんかはこの手法が使われていたようです(今も?)。Google、NTT、東工大あたりがよく名前にあがっていましたね。
WFST = Weighted Finite State Transducer / 重み付き有限状態トランスデューサーといいます。これはオートマトンの1種です。重み付きがあるなら、重みなしのものはFSTと呼ばれます。むしろFSTがベースです。
FSTは入力に対して何かしらの出力を行うオートマトンのことをいいます。
FSTの遷移部分に重みがつくと、WFSTになります。詳しい解説はLAPRASさんの記事が分かりやすいかもしれません。
 cat -> dogに変換するFST(上記記事から引用)
cat -> dogに変換するFST(上記記事から引用)
前編で登場したHMMもWFSTで表現できますし、単語辞書もWFSTで表現できます。N-gramもです。つまり音響モデル、単語辞書、言語モデルは全てWFSTで表現できます。
すべて同じオートマトンにすると、オートマトンの合成ができるようになります。音響モデル、単語辞書、言語モデルを全て合成して、1つの巨大なオートマトンの上で探索しようというのがWFST型の音声認識デコーダーの考え方です。

雑な図ですがこんな感じ。
結局WFSTの何が良いかというと、オートマトンの最適化アルゴリズムが適用できるのと、デコーダーの構造がとてもシンプルになります。オートマトンを探索していくだけなので。以前の型の音声認識デコーダーは極端な計算量削減のために色々とテクニックを入れたのが原因で、アルゴリズムのブラックボックス化が進んでしまっていました。ある程度計算量の成約が緩和されたので、仕組みをシンプルにしてリソースで殴ろうという方法に移行したわけですね。
マルチパス探索とWFSTを一概に比較するのはできない(WFSTでマルチパスもできるので...)のですが、オフライン前提とオンライン・クラウド前提で仕組みが分かれているような気がします。
色々な音声認識システム
ところでどんな音声認識ソフトウェアがあるんでしょうか。
有名どころのソフトウェアを紹介します。
Julius
日本発です。数万語彙のオフライン音声認識ができます。GMM-HMMだけでなく(まだ触れてませんが)深層学習のアプローチを用いたDNN-HMMが扱えるようになっています。私もお世話になりました。Juliusは前述した2パス探索を採用しています。
kaldi
こちらはWFST型の音声認識です。作者の論文はよく見てましたが、ちょうどKaldiが話題になったごろで音声認識から離れてしまったのでちゃんと動かしておらず。今でも結構使われてるみたいです。
espnet
DNNベースの音声認識です。使ったこと無いです。
どうもこいつはText-to-Speechもできる優れものらしい。(音声認識の逆をやると音声合成なので)
たぶん後編で触れます。
その他
あと CMU Sphinx、RWTH ASR、HDecode(HTK)あたりはチョイチョイ名前を聞くかも。
なかなか音声認識エンジンってないんですよねー。もちろん企業主導で開発しているのはたくさんあって、Siriで使われているDragon Speech(Nuance社)なんかは超有名ですね。
まとめ
音声認識の仕組み(前編) → 実装の仕組み(中編)と説明してきました。
後編はDNNを用いた音声認識について書いてみますが、キャッチアップしながら書くので若干不安です。
お楽しみに!