この記事はNTTコムウェア Advent Calendar 2023の4日目の記事です。
こんにちは、NTTコムウェアの平塚です。今月は2023冬 Chill Seasonで手に馴染むブキを探しているところです。
大規模言語モデルが持っていない最新情報や企業内情報を補うためのRAG(Retrieval Augmented Generation、検索拡張生成)というアーキテクチャーがあります。ごく簡単に説明すると、外部データベースを用意してそこで検索した結果を大規模言語モデルに説明させるというものです。以下はRAGのイメージ図です。
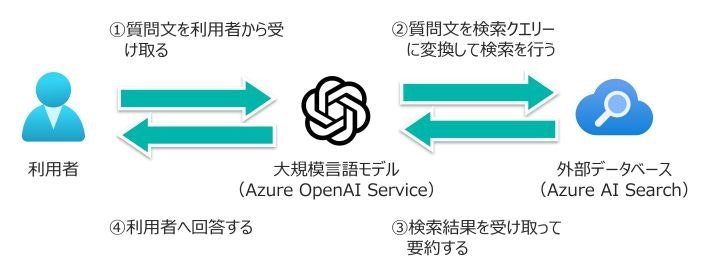
現在多くの企業さまがRAGの検証に取り組んでいるところかと思います。今回RAGを用いてPostgreSQLに詳しいアシスタントAIを試作したので、気づいたところをいくつ か共有いたします。
まとめ
- PostgreSQLアシスタントAIはある程度使えるものになりそう
- 回答品質を高めるためには、やはりドキュメントの前処理が重要
- 一問一答よりは、散在する回答群をまとめあげるユースケースに期待
PostgreSQLアシスタントAIの質問回答例
さっそく試してみましょう。PostgreSQLアシスタントAIにはPostgreSQL 15付属ドキュメントの日本語版を全編読み込ませてあります。まずは「PostgreSQL 15におけるPUBLICスキーマの仕様変更について教えてください」という質問を素のGPT-4(gpt-4-0613)に投げてみました。gpt-4-0613のカットオフは2021年9月なので、2022年10月にリリースされたPostgreSQL 15のことは知らないと言われてしまいます。

同じ質問をGPT-4 Turbo(gpt-4-1106-preview)に投げました。gpt-4-1106-previewのカットオフは2023年4月ですが、こちらもPostgreSQL 15のことは知らないようです。大規模言語モデルの知識は収集した学習データに依存するので、カットオフ以前のことなら何でも知っていると安易に期待することはできません。これはハルシネーションを起こさなかっただけまだ良かったというところです。

そして今回作成したPostgreSQLアシスタントAIに質問すると、このように適切な回答が返ってきます。きちんと動作しているようですね。

別の質問で試してみましょう。バージョンは指定せずに「PostgreSQLでクエリの性能が悪いです。どのように調査して改善することができますか」というふわっとした質問を投げてみます。最初はGPT-4 Turboの回答です。

続けて内容を掘り下げる質問をします。GPT-4 Turboなかなか賢いですね。
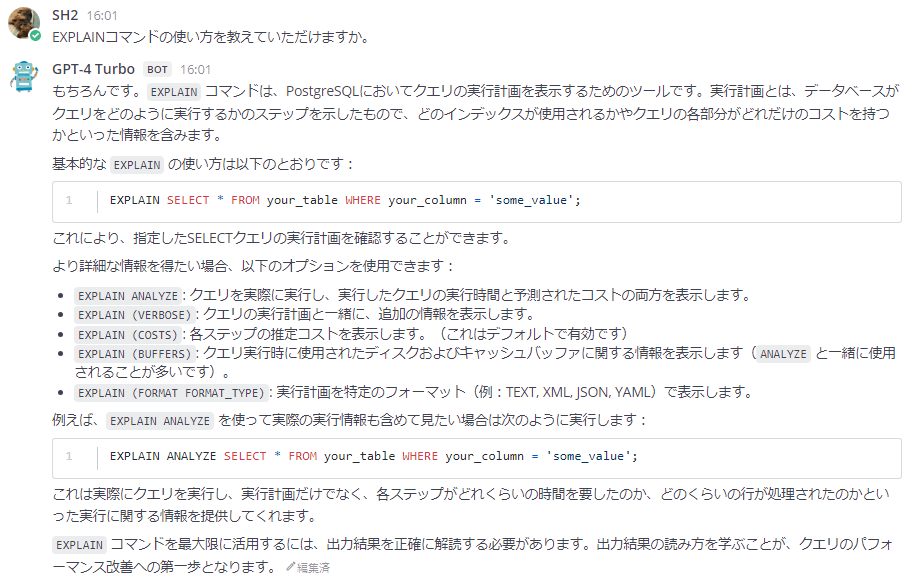
次に同じ質問をPostgreSQLアシスタントAIに投げます。やや雑な印象を受けますが、複数の検索結果を参照しながら回答を作成していることが分かります。

続けてこちらも内容を掘り下げる質問をします。適切な回答だと思います。

なお私が都合のよい質問と回答を選んで紹介していることは正直否定できないので、PostgreSQLアシスタントAIがどの程度使い物になるのかは機会があれば実際に構築して試してみていただければと思います。
RAGシステムの構成について
このPostgreSQLアシスタントAIは、Microsoft社が公開しているAzure-Samples/azure-search-openai-demoを参考にして作成しました。

中心となる処理はchatreadretrieveread.pyに集約されており、これを流用しつつシステムプロンプトを日本語に差し替えるなどの変更を加えています。
prompt_for_query = """以下はこれまでの会話の履歴と、ユーザーからの新たな質問です。
新たな質問にはナレッジベースを検索して回答する必要があります。
会話と新たな質問を元に、検索クエリーを生成してください。
検索クエリーは日本語で生成してください。
検索クエリーにinfo.txtやdoc.pdfといった引用元のファイル名やドキュメント名を含めないでください。
検索クエリーに[]または<<>>で囲まれた文字列を含めないでください。
検索クエリーに'+'のような特殊文字を含めないでください。
検索クエリーをダブルクォーテーションで囲わないでください。
検索クエリーを生成できない場合は、数字の0だけを返してください。"""
prompt_for_answer = """アシスタントはユーザーからの質問をサポートします。
詳細な回答を心がけてください。
日本語で回答してください。
以下にリストされた出典に記載されている事実のみを用いて回答してください。
以下の情報が十分でない場合は、分からないと回答してください。
以下の出典を用いない回答は作成しないでください。
ユーザーに明確化のための質問をすることが役立つ場合は、質問してください。
それぞれの出典は、名前の後にコロンと実際の情報が続きます。
回答で使用するそれぞれの事実については、必ず出典名を含めてください。
出典を参照するには大括弧を使用してください(例:[info1.txt])。
出典は結合せず、それぞれの出典を分けて記載してください(例:[info1.txt][info2.txt])。"""
注意点として、本記事執筆時点のchatreadretrieveread.py (2023-11-16)はライブラリopenaiとazure-search-documentsの古いバージョンに依存しており、ライブラリを最新バージョンにアップデートすると動かなくなります。構築される場合は以下のドキュメントを参考にしてプログラム側をライブラリの最新バージョンに対応させることをおすすめします。
- OpenAI Python v1.x に移行する方法 - Azure OpenAI Service | Microsoft Learn
- Azure AI Search Vector Search Code Sample with Azure OpenAI
フロントエンドにはMattermostを使っています。azure-search-openai-demoのフロントエンドにはユーザー認証機能や過去ログ閲覧機能がないこと、とはいえ自前でフロントエンドを実装する手間は避けたかったことがMattermostを選んだ主な理由です。Mattermost Botのベースとしてazure-openai-mattermost-botを利用しています。
Azureの構成は以下の通りです。
- 大規模言語モデル: Azure OpenAI Service
- Embeddingモデル: text-embedding-ada-002
- ChatCompletionモデル: gpt-4-1106-preview
- 外部データベース: Azure AI Search
検索対象テキストの前処理について
RAGで利用する外部データベースにおいては、検索対象テキストをほどよいサイズに分割して整理することが重要です。大きすぎても小さすぎてもRAGは適切に機能しません。いくつかの考慮すべき制約を以下に示します。
- 埋め込みモデルの制約
- text-embedding-ada-002の最大トークン数が8,191であまり大きくない
- 分割サイズを大きくしすぎると、文章の特徴が丸められてしまい適切な検索結果を得られにくくなる
- チャットモデルの制約
- gpt-4の最大トークン数が8,192であまり大きくない
- 分割サイズを大きくしすぎると、検索結果を数件しか大規模言語モデルに渡せなくなる
- 分割サイズを小さくしすぎると、検索結果が文章の断片になってしまい内容が把握できなくなる
RAGで扱う場合テキストの分割サイズは500~1,000トークン程度が良いとされています。今回は1,000トークンを目安にテキストを分割しました。なおチャットモデルの制約についてはgpt-4-32k、gpt-4-1106-previewで大きく緩和されています。
テキスト分割プログラム 初期版
RAGで行うテキスト分割にはLangChainのtext_splitter.pyを用いることが多いようです。最初は私もLangChainを使っていたのですがすぐに大きく改造することになると考え、より規模の小さなazure-search-openai-demoのtextsplitter.pyをベースにして機能を足していく方針にしました。初期版ではtextsplitter.pyに以下の機能を追加しています。
- 区切り文字に日本語の句読点を追加
- 文字数ではなくトークン数で数えるように変更
具体的な実装はdocument_preprocessor.pyを参照してください。また実際に「第26章 バックアップとリストア」を分割したchunked_ja.txtもご確認いただければと思います。この章は25個のテキストに分割されました。
テキスト分割プログラム 改良版
テキスト分割プログラムの初期版でもRAGはある程度機能するのですが、思わぬところでテキストが分割されていたり、テキストを分割してほしいところが繋がってしまっていたりとやはり希望通りにはいきません。
そこでテキスト分割プログラムの改良版では、PostgreSQLドキュメントがSGMLというマークアップ言語で書かれていることを利用して文章の構造に沿ってテキストを分割していくことにしました。PostgreSQLドキュメントは以下のような構造になっていますので、まず<sect2>の単位でテキストを分割し、<sect2>のサイズが1,000トークンを超える場合は初期版のアルゴリズムでさらに分割していきます。
<chapter><title>1.章タイトル</title>
<sect1><title>1-1.セクション(大)タイトル</title>
<sect2><title>1-1-1.セクション(中)タイトル</title>
<para>本文</para>
</sect2>
<sect2><title>1-1-2.セクション(中)タイトル</title>
<para>本文</para>
</sect2>
</sect1>
<sect1><title>1-2.セクション(大)タイトル</title>
<sect2><title>1-2-1.セクション(中)タイトル</title>
<para>本文</para>
</sect2>
</sect1>
</chapter>
具体的な実装はdocument_preprocessor_custom.pyを、「第26章 バックアップとリストア」の分割例はchunked_ja_custom.txtを参照してください。改良版では34個のテキストに分割されました。
また改良版では以下のようにそれぞれのテキストに対して文書タイトル、章タイトル、セクションタイトルを書き加えています。これによってベクトル検索の精度向上を狙っています。
# PostgreSQL 15 文書
## バックアップとリストア
### 継続的アーカイブとポイントインタイムリカバリ(PITR)
#### WALアーカイブの設定
(パス名は現在の作業ディレクトリ、つまりクラスタのデータディレクトリからの相対パスです。)
実際の%文字をコマンドに埋め込む必要がある場合は%%を使用してください。
最も簡単で便利なコマンドは以下のようなものです。
~
本記事の冒頭でご紹介した質問回答例は、このプログラムを用いて準備したものです。
テキスト分割プログラム 大規模言語モデル版 (失敗事例)
うまくいかなかったアイデアです。gpt-4-1106-previewで最大トークン数が128,000と大幅に増えたことから、こうしたテキスト処理自体をgpt-4-1106-previewに任せてしまえばよいのではないかと考えました。これは以下の理由で失敗しました。
- 入力には128,000トークンを使えるが、出力には4,096トークンしか使えない
- 分割したテキストを出力させると、元のテキストからわずかに改変されてしまう
- 別のアプローチとして分割する行番号を出力させると、でたらめな数字を返してくる
しばらくプロンプトエンジニアリングを頑張ってみたのですが、どうしても良い結果は得られませんでした。大規模言語モデルの仕組みをしっかり理解していれば、このタスクがうまくいかないことは試すまでもなく分かったのかもしれません。
RAGが役に立つユースケースについて
SNSで情報を集めていると「RAGはベクトル検索が本質であって大規模言語モデルは必要ないのでは?」という意見を目にすることがあり、確かにそうかもなあという気持ちになることがあります。
社内規程の検索といった一つの質問に対して一つの回答が紐づくタスクでは、多くの場合ベクトル検索だけで要件を満たせるのではないかと思います。一つの情報源にたどり着けるのであれば、わざわざそれを大規模言語モデルに嚙み砕いて説明してもらう必要はないですよね。
システム構成からの逆算になりますが、RAGが役に立つユースケースというのは一つの質問に対して複数の回答が存在するものになると考えています。そのようなユースケースでは、ベクトル検索を用いて少し緩めの検索条件で多くの情報をかき集め、大規模言語モデルが多種多様な情報をうまくまとめて伝えることが効果的です。

冒頭のPostgreSQLアシスタントAIはクエリ性能改善に関する質問に対して10件もの検索結果を参照しながら回答を作成しており、こうしたユースケースの一つと言えるかもしれません。思い付きレベルですが次のようなユースケースも面白そうです。
- 図書館の蔵書検索システム
「おいしいパンがでてくる絵本を教えて」
「主人公が異世界で人間以外に転生するファンタジー小説を教えて」 - 特許検索システム
「ジョイスティックを模した操作を行うためのタッチパネル制御に関する特許を教えて」
もう一つ、大規模言語モデルがマルチリンガルであることを活用したユースケースが考えられます。実は今回試作したPostgreSQLアシスタントAIは、英語版のドキュメントに対して日本語で質問を受け取り、日本語で回答することができます。英語の情報源しかなくても日本語で質問回答ができるというのは大規模言語モデルとベクトル検索の強みと言えそうです。
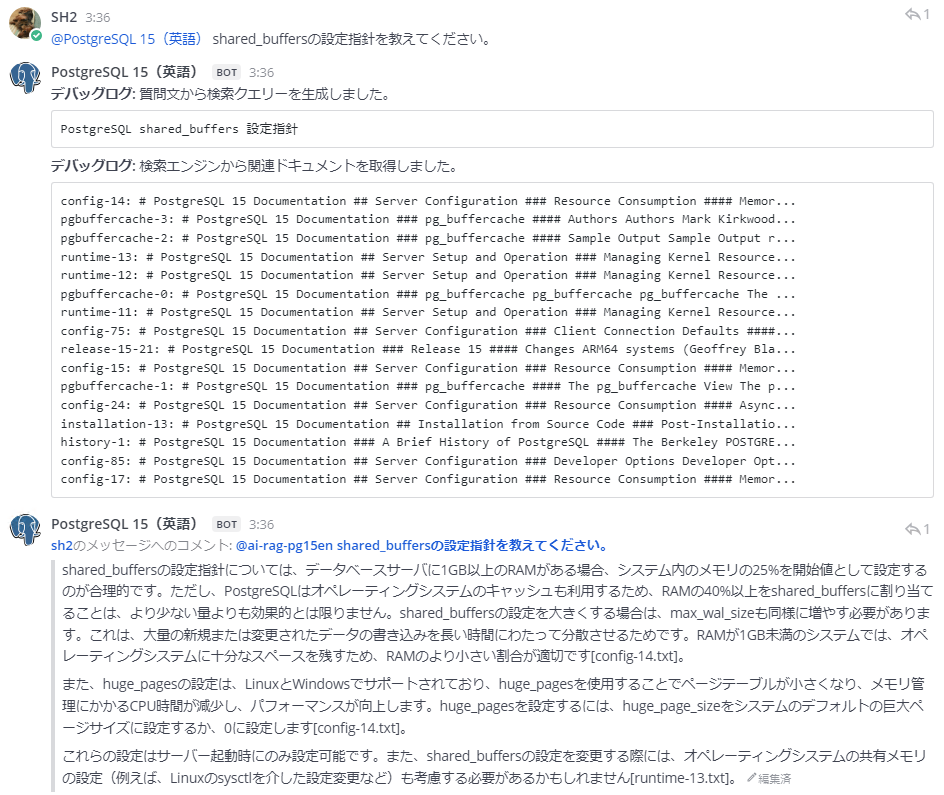
まとめの再掲
- PostgreSQLアシスタントAIはある程度使えるものになりそう
- 回答品質を高めるためには、やはりドキュメントの前処理が重要
- 一問一答よりは、散在する回答群をまとめあげるユースケースに期待
終わりに
高品質な翻訳ドキュメントを整備されている日本PostgreSQLユーザ会のみなさま、いつもありがとうございます。
記載されている会社名、製品名、サービス名は、各社の商標または登録商標です。