前回の記事:
「PyTorchで関数フィッティング」
https://qiita.com/cometscome_phys/items/61331dd2eedd0c846336
に引き続き、PythonでのPyTorchを試してみる。今回は、Batch Normalization (バッチ正規化)を使う。
TensorFlowでのバッチ正規化の記事は
「TensorFlowの高レベルAPIを使ったBatch Normalizationの実装」
https://qiita.com/cometscome_phys/items/6d5d3c74d7000382efef
にあるので、これと同様なことをやりたい。この記事と同じ流れでPyTorchでの実装を行う。
バージョン
PyTorch: 1.0
Python 3.6.4
再現すべき関数
再現すべき関数は
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
n = 10
x0 = np.linspace(-2.0, 2.0, n)
a0 = 3.0
a1 = 2.0
b0 = 1.0
y0 = np.zeros((n,1))
y0[:,0] = a0*x0+a1*x0**2 + b0 + 3*np.cos(20*x0)
nm = 300
xmany = np.linspace(-2.0, 2.0, nm)
ymany = np.zeros((nm,1))
ymany[:,0] = a0*xmany+a1*xmany**2 + b0 + 3*np.cos(20*xmany)
plt.plot(xmany,ymany )
plt.show()
plt.savefig("graph_many.png")
であり、
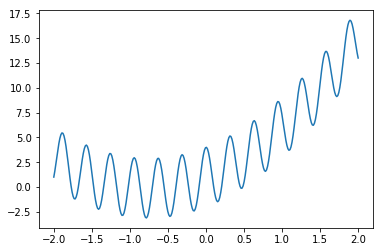
である。
ランダムバッチ:バッチ正規化なし
まずはじめに、バッチ正規化なしの場合を考える。
また、前回の記事では使わなかったランダムバッチを使ってみよう。
前回の記事では、PyTorchへ入れるテンソルは
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import torch.utils.data
input = torch.from_numpy(phimany)
target =torch.from_numpy(ymany)
のようにして、inputとtargetを使っていた。
ランダムバッチにしたい場合には、
train = torch.utils.data.TensorDataset(input,target ) #トレーニング用
train_loader = torch.utils.data.DataLoader(train, batch_size=20, shuffle=True)
test = torch.utils.data.TensorDataset(input, target) #テスト用
test_loader = torch.utils.data.DataLoader(test, batch_size=20, shuffle=True)
とすればよい。ここではトレーニング用とテスト用で同じinputとtargetを使っているが、
よりちゃんとしたければ異なるものを用意すべきである。上では、バッチサイズを20としている。
ここからミニバッチを取り出すには、
input_i,target_i = next(iter(train_loader))
とすればよい。
モデルは前回の記事と同じものを使うので、バッチ正規化なしの全体のコードは
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
n = 10
x0 = np.linspace(-2.0, 2.0, n)
a0 = 3.0
a1 = 2.0
b0 = 1.0
y0 = np.zeros((n,1),dtype = 'Float32')
y0[:,0] = a0*x0+a1*x0**2 + b0 + 3*np.cos(20*x0)
nm = 300
xmany = np.linspace(-2.0, 2.0, nm)
ymany = np.zeros((nm,1),dtype = 'Float32')
ymany[:,0] = a0*xmany+a1*xmany**2 + b0 + 3*np.cos(20*xmany)
plt.plot(xmany,ymany )
plt.show()
plt.savefig("graph_many.png")
def make_phi(x0,n,k):
phi = np.array([x0**j for j in range(k)],dtype = 'Float32')
return phi.T
k = 6
phi = make_phi(x0,n,k)
print(phi[0,:])
phimany = make_phi(xmany,nm,k)
d_input = k
d_middle = 10
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import torch.utils.data
class Net(nn.Module):
def __init__(self,d_inp,d_middle,d_out):
super(Net, self).__init__()
self.fc1 = nn.Linear(d_inp,d_middle)
self.fc2 = nn.Linear(d_middle, d_out)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
learning_rate = 0.001
d_out = 1
net = Net(d_input,d_middle,d_out)
print(net)
params = list(net.parameters())
print(params)
input = torch.from_numpy(phimany)
target =torch.from_numpy(ymany)
train = torch.utils.data.TensorDataset(input,target )
train_loader = torch.utils.data.DataLoader(train, batch_size=20, shuffle=True)
test = torch.utils.data.TensorDataset(input, target)
test_loader = torch.utils.data.DataLoader(test, batch_size=20, shuffle=True)
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
nt = 2000
vec_loss = []
for i in range(nt):
optimizer.zero_grad()
input_i,target_i = next(iter(train_loader)) #トレーニング用ミニバッチ
output_i = net(input_i)
loss = criterion(output_i, target_i) #トレーニングのloss
loss.backward()
optimizer.step()
input_test_i,target_test_i = next(iter(test_loader)) #テスト用ミニバッチ
output_test_i = net(input_test_i)
loss_test = criterion(output_test_i, target_test_i) #テストのloss
vec_loss.append(loss_test)
if i %100 is 0:
print(i,loss_test.item())
print(params[:])
print('Finished Training')
ye = net(input_test).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2.png")
plt.plot(vec_loss,label = "Test data")
plt.legend()
plt.show()
plt.savefig("loss.png")
となる。
得られる図は、
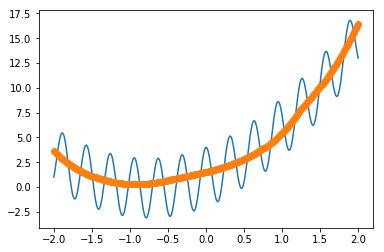
となる。lossは
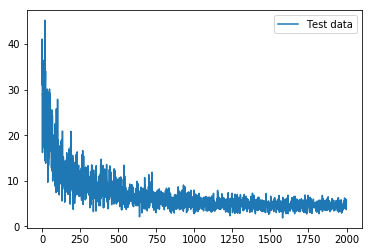
のように減っていく。
ランダムバッチ:バッチ正規化あり
PyTorchにおいてバッチ正規化を使うには、nn.BatchNorm1dを使えばよい。
モデルは、
class Net_BN(nn.Module):
def __init__(self,d_inp,d_middle,d_out):
super(Net_BN, self).__init__()
self.fc1 = nn.Linear(d_inp,d_middle)
self.bn1 = nn.BatchNorm1d(d_middle) #バッチ正規化
self.fc2 = nn.Linear(d_middle, d_out)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x) #バッチ正規化を行う
x = self.fc2(x)
return x
となる。先ほどのNetの代わりにこのNet_BNを使えば、コードは完全に同一となる。
つまり、
input = torch.from_numpy(phimany)
target =torch.from_numpy(ymany)
train = torch.utils.data.TensorDataset(input,target )
train_loader = torch.utils.data.DataLoader(train, batch_size=20, shuffle=True)
test = torch.utils.data.TensorDataset(input, target)
test_loader = torch.utils.data.DataLoader(test, batch_size=20, shuffle=True)
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
nt = 2000
vec_loss_BN = []
for i in range(nt):
optimizer.zero_grad()
input_i,target_i = next(iter(train_loader))
output_i = net(input_i)
loss = criterion(output_i, target_i)
loss.backward()
optimizer.step()
input_test_i,target_test_i = next(iter(test_loader))
output_test_i = net(input_test_i)
loss_test = criterion(output_test_i, target_test_i)
vec_loss_BN.append(loss_test)
if i %100 is 0:
print(i,loss_test.item())
print(params[:])
print('Finished Training')
ye = net(input_test).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2_BN.png")
plt.plot(vec_loss_BN,label = "Test data")
plt.legend()
plt.show()
plt.savefig("loss_BN.png")
plt.yscale("log")
plt.plot(vec_loss,label = "without BN")
plt.plot(vec_loss_BN,label = "with BN")
plt.legend()
plt.show()
plt.savefig("loss_BNlog.png")
でよい。
図は、
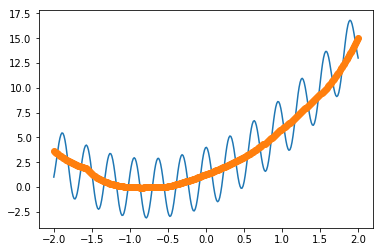
であり、lossは
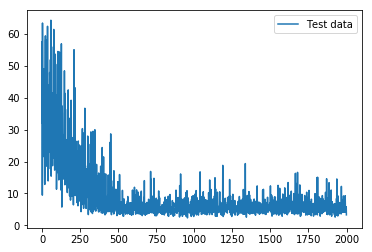
となる。
バッチ正規化なしとありを何回か実行し、logスケールで比較してみた。その結果、
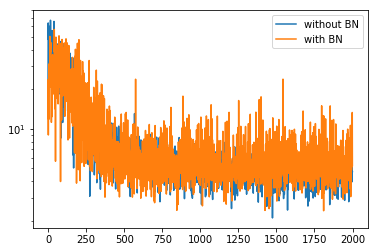
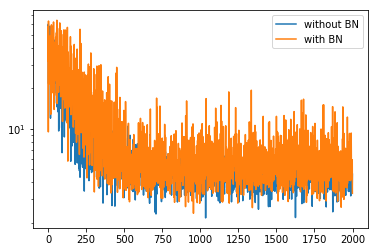
となった。このケースでは、TensorFlowの時と同様にあまり効いていないかも知れない。
全体のコード
最後に、トレーニング部分をひとまとめにする。
def train(net,train_loader,test_loader):
learning_rate = 0.001
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
nt = 2000
vec_loss = []
for i in range(nt):
optimizer.zero_grad()
input_i,target_i = next(iter(train_loader))
output_i = net(input_i)
loss = criterion(output_i, target_i)
loss.backward()
optimizer.step()
input_test_i,target_test_i = next(iter(test_loader))
output_test_i = net(input_test_i)
loss_test = criterion(output_test_i, target_test_i)
vec_loss.append(loss_test)
if i %100 is 0:
print(i,loss_test.item())
return net,vec_loss
のようにすれば、どちらが入ってきても同じようにトレーニングができる。
これを使う場合には、
def train(net,train_loader,test_loader):
learning_rate = 0.001
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
nt = 2000
vec_loss = []
for i in range(nt):
optimizer.zero_grad()
input_i,target_i = next(iter(train_loader))
output_i = net(input_i)
loss = criterion(output_i, target_i)
loss.backward()
optimizer.step()
input_test_i,target_test_i = next(iter(test_loader))
output_test_i = net(input_test_i)
loss_test = criterion(output_test_i, target_test_i)
vec_loss.append(loss_test)
if i %100 is 0:
print(i,loss_test.item())
return net,vec_loss
net = Net(d_input,d_middle,d_out)
net,vec_loss = train(net,train_loader,test_loader)
net_BN = Net_BN(d_input,d_middle,d_out)
net_BN,vec_loss_BN = train(net_BN,train_loader,test_loader)
print(params[:])
print('Finished Training')
ye = net(input_test).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2.png")
ye = net_BN(input_test).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2_BN.png")
plt.plot(vec_loss_BN,label = "Test data")
plt.legend()
plt.show()
plt.savefig("loss_BN.png")
plt.yscale("log")
plt.plot(vec_loss,label = "without BN")
plt.plot(vec_loss_BN,label = "with BN")
plt.legend()
plt.show()
plt.savefig("loss_BNlog.png")
とすればよい。
全体のコードは、
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
n = 10
x0 = np.linspace(-2.0, 2.0, n)
a0 = 3.0
a1 = 2.0
b0 = 1.0
y0 = np.zeros((n,1),dtype = 'Float32')
y0[:,0] = a0*x0+a1*x0**2 + b0 + 3*np.cos(20*x0)
nm = 300
xmany = np.linspace(-2.0, 2.0, nm)
ymany = np.zeros((nm,1),dtype = 'Float32')
ymany[:,0] = a0*xmany+a1*xmany**2 + b0 + 3*np.cos(20*xmany)
plt.plot(xmany,ymany )
plt.show()
plt.savefig("graph_many.png")
def make_phi(x0,n,k):
phi = np.array([x0**j for j in range(k)],dtype = 'Float32')
return phi.T
k = 6
phi = make_phi(x0,n,k)
print(phi[0,:])
phimany = make_phi(xmany,nm,k)
d_input = k
d_middle = 10
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import torch.utils.data
d_out = 1
input = torch.from_numpy(phimany)
target =torch.from_numpy(ymany)
train = torch.utils.data.TensorDataset(input,target )
train_loader = torch.utils.data.DataLoader(train, batch_size=20, shuffle=True)
test = torch.utils.data.TensorDataset(input, target)
test_loader = torch.utils.data.DataLoader(test, batch_size=20, shuffle=True)
def train(net,train_loader,test_loader):
learning_rate = 0.001
criterion = nn.MSELoss()
optimizer = optim.Adam(net.parameters(), lr=learning_rate)
nt = 2000
vec_loss = []
for i in range(nt):
optimizer.zero_grad()
input_i,target_i = next(iter(train_loader))
output_i = net(input_i)
loss = criterion(output_i, target_i)
loss.backward()
optimizer.step()
input_test_i,target_test_i = next(iter(test_loader))
output_test_i = net(input_test_i)
loss_test = criterion(output_test_i, target_test_i)
vec_loss.append(loss_test)
if i %100 is 0:
print(i,loss_test.item())
return net,vec_loss
class Net(nn.Module):
def __init__(self,d_inp,d_middle,d_out):
super(Net, self).__init__()
self.fc1 = nn.Linear(d_inp,d_middle)
self.fc2 = nn.Linear(d_middle, d_out)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
net = Net(d_input,d_middle,d_out)
net,vec_loss = train(net,train_loader,test_loader)
class Net_BN(nn.Module):
def __init__(self,d_inp,d_middle,d_out):
super(Net_BN, self).__init__()
self.fc1 = nn.Linear(d_inp,d_middle)
self.bn1 = nn.BatchNorm1d(d_middle)
self.fc2 = nn.Linear(d_middle, d_out)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.bn1(x)
x = self.fc2(x)
return x
net_BN = Net_BN(d_input,d_middle,d_out)
net_BN,vec_loss_BN = train(net_BN,train_loader,test_loader)
print('Finished Training')
ye = net(input).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2.png")
ye = net_BN(input).detach().numpy()
plt.plot(xmany,ymany )
plt.plot(xmany,ye,'o')
plt.show()
plt.savefig("graph_2_BN.png")
plt.plot(vec_loss,label = "Test data without BN")
plt.legend()
plt.show()
plt.savefig("loss_BN.png")
plt.plot(vec_loss_BN,label = "Test data with BN")
plt.legend()
plt.show()
plt.savefig("loss_BN.png")
plt.yscale("log")
plt.plot(vec_loss,label = "without BN")
plt.plot(vec_loss_BN,label = "with BN")
plt.legend()
plt.show()
plt.savefig("loss_BNlog.png")
となる。