概要
一般的にSEO効果を高めるためにクローラ対策をするが、あえてクローラに来てほしくない時の対策とその検証手順を残したいと思います。
クローラに来てほしくないケースとしては、インターネット公開されている業務用のWebシステムのログイン画面のURLが巡回してきたクローラによって、検索エンジンのインデックス対象となり検索結果でヒットしてしまう
やること
すでに検索エンジンでインデックスされたWebページをクローリング対象から除外することを目指す
なお、下記の手順でWebページをインデックス化するところから開始しますが、適宜読み飛ばしてください
対策方法
まずさっそく対策方法は以下の4つになります
ただし、これらの対策方法はあくまでもルールを守るクローラのみに効果があり、マナーの悪いクローラには強制力がないため、コンテンツのインターネット公開を制限しない限り解決にはなりません
metaタグ
- このmetaタグが書かれたページをクローリングしないようにする
<meta name="robots" content="noindex">
- このmetaタグが書かれたページにあるアンカータグ(aタグ)の先をクローリングしないようにする
<meta name="robots" content="nofollow">
- ページ内の特定のアンカータグ(aタグ)の先をクローリングしないようにする
<a href="xxxxxxx" rel=”nofollow”>
※Bing: https://www.bing.com/webmaster/help/which-robots-metatags-does-bing-support-5198d240
※Google: https://support.google.com/webmasters/answer/79812
.htaccess
WebサーバをApacheにしている場合で、利用できる制御ファイル
SetEnvIf User-Agent "Googlebot" ng_ua
SetEnvIf User-Agent "bingbot" ng_ua
order Allow,Deny
Allow from all
Deny from env=ng_ua
HTTPヘッダー
X-Robots-Tag HTTP ヘッダー
GoogleBot向けのクローラ走査指示
https://developers.google.com/search/reference/robots_meta_tag?hl=ja
robots.txt
クローラの走査規約としての役割を持つ
User-Agent: * 「*」ですべてのクローラを制限する
Disallow: /hogehoge/ ディレクトリが除外される
Allow: /fugafuga/ ディレクトリが対象になる
※https://ja.wikipedia.org/wiki/Robots_Exclusion_Standard
※https://blogs.bing.com/webmaster/2009/08/20/prevent-a-bot-from-getting-lost-in-space-sem-101
※robots.txt のディレクティブでは他のサイトで参照されている自サイトの URL をブロックできないため、
metaタグやレスポンスヘッダーで追加対策が必要
※robots.txtをサイトのルートに配置すること
設定の確認(Google)
対象のページのURLを入力し、「取得」することでブロックが表示されればOK
サイトマップで以下のようにブロックされた旨のメッセージが表示されればOK
(クローラが巡回してくるまでメッセージが表示されない)

すでにインデックス化されたページを削除するには
Search Consoleで「URL 削除ツール」で公開しているページのURLを登録することで、検索結果から削除されます
詳細はこちら
Bing
Webマスターツールで「コンテンツ削除」で公開しているページのURLを登録することで、インデックスから削除されます
ただし、リンク切れのページ及びキャッシュされたページのみが削除対象
詳細はこちら
公開中のページを一時的にアクセスブロックしたい場合は、「webマスター」-「自分のサイト設定」-「URL のブロック」で対象のURLを登録
検証手順
検証手順とは「テストサイトの公開」→「検索エンジン登録」→「インデックス化」→「クローラ対策」→「インデックス削除」の一連の手順
1. 外部公開用のWebサーバと公開するコンテンツを準備する
ディレクトリ構成と各種ページは以下の通りになります
/web-root --- index.html // インターネットに公開するページ
|--- robots.txt // robots.txt(最初は全許可)
|--- sitemap.xml // サイトマップ(手順2で説明)
|
|--- /dir1 // 公開したくないコンテンツ
| |--- login.html
|
|--- /dir2 // 公開するコンテンツ
|--- index.html
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>test page</title>
<head>
<body>
<p>Crawler Test Page</p>
<a href="http://xxxxx.co.jp/dir1/login.html" title="test login page">Login Page</a>
<a href="http://xxxxx.co.jp/dir2/index.html" title="child page">Child Page</a>
<body>
</html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Login page</title>
<head>
<body>
<p>Login Page</p>
<body>
</html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>Child page</title>
<head>
<body>
<p>Child Page</p>
<body>
</html>
User-Agent:*
Sitemap: http://xxxxx.co.jp/sitemap.xml
2. sitemap.xmlの作成
こちらのサイトで自動生成してくれるので、それをWebサーバの公開ディレクトリのルートに配置してください
3. 検索インデックスに登録する
-
Google Search Consoleで該当サイトを追加する

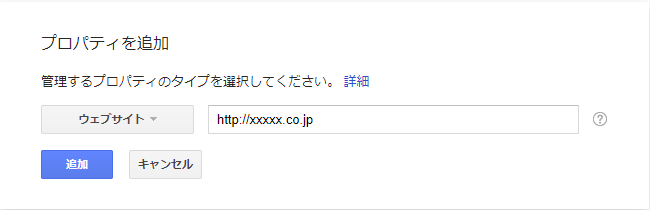
-
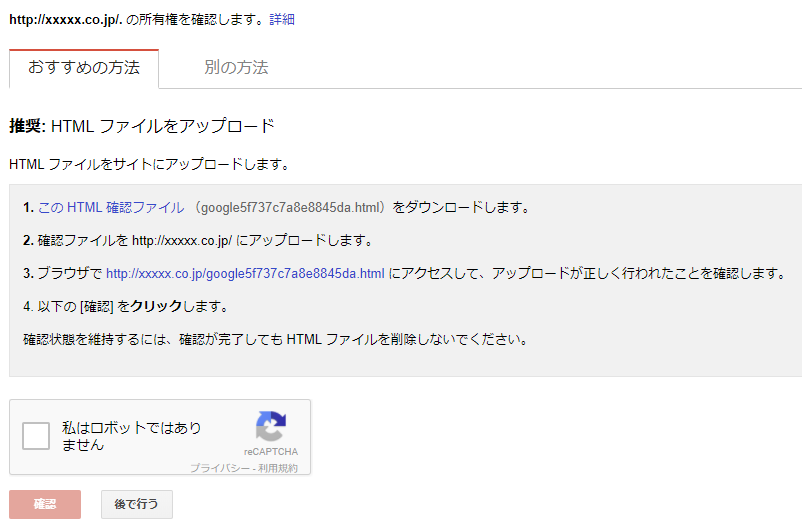
登録したサイトの所有権を確認するため、
この確認ファイルをDLし、手順1の公開ディレクトリのルートに配置し、確認してください
-
サイトマップの追加/テスト
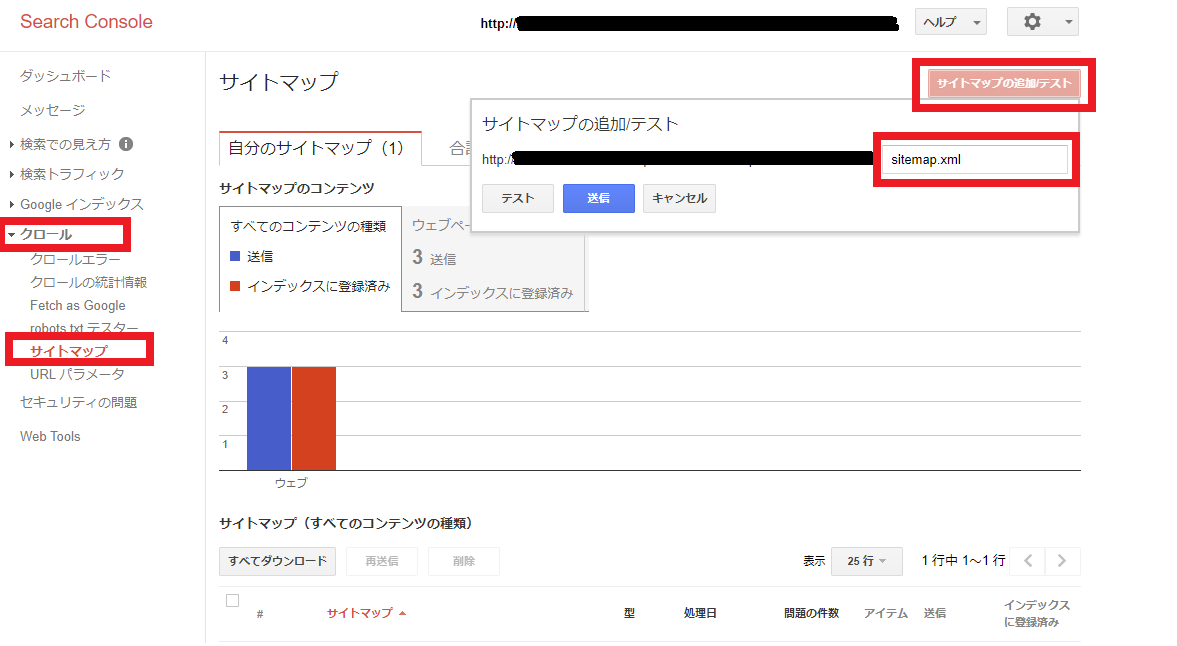
-
インデックス登録
トップページ(index.html)をインデックス登録をリクエストしてください
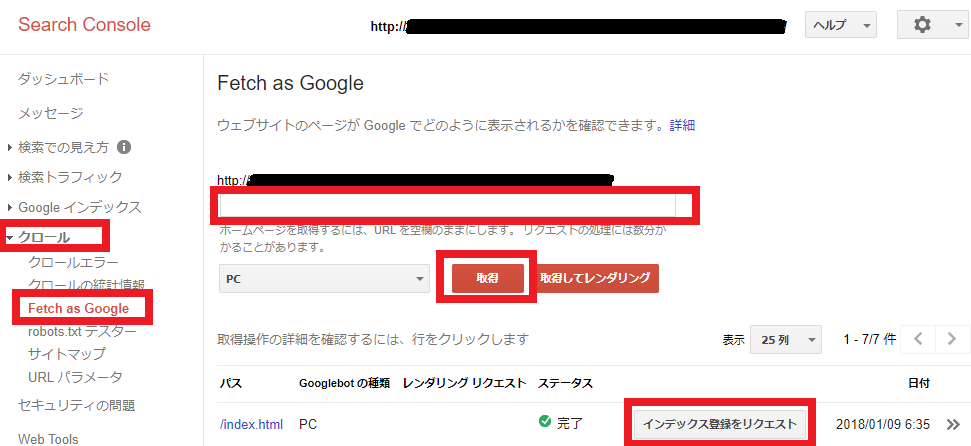
1~2日ぐらいでクローリングされ、検索結果に表示されるようになります
検索結果でヒットする単語はできるだけ具体的な単位が効果的だと思います(ググラビリティの高い言葉)
4. クローラ対策とインデックスの削除
前述のクローラ対策を施し、インデックスの削除をリクエストする