やりたいこと
業務で Azure OpenAI Service を使う機会があり、LangChain を使っていろいろとやってみたので複数回で記事にまとめます。今回は、ローカルのファイル内容を RAG で LLM から回答させる実装を行います。
すでに多くの方が情報発信していますが、その1つとして参考にしてもらえると幸いです!
他の記事
- Langchain を使って LLM から回答させてみる
- LangChain を使ってローカルファイルを RAG で回答させてみる ← イマココ
- LangChain を使って Azure Cognitive Search のデータを RAG で回答させてみる
前提
- WSL (Ubuntu 22.04) 上で行います
- Python で実装します
- LLM のモデルには、GPT-3.5 を使用します
- Azure OpenAI Service で gpt-35-turbo, text-embedding-ada-002 モデルのデプロイメントは作成済み
- Azure OpenAI Service を使うため、OpenAI 社のものを使う場合と異なる場合があります
- Azure OpenAI Service は作成済み
RAG とは
Retrieval Augmented Generation の略。GPT-3.5 のモデルの場合、2021年9月までの情報しか学習されていないので、それ以降の情報について質問しても回答は得られない。そういった場合に、未学習の情報をプロンプトに組み込むことでその情報を踏まえて LLM から回答してもらう手法。
社内文書の内容や FAQ データなどを RAG で回答させるなどのユースケースが多い。
実装
未学習のデータ
RAG 用に未学習のデータを作成する。テニスに関する内容なのはテニスが趣味だから ![]()
GPT-3.5 が未学習のデータならなんでも可。data/test.txt として保存しておく。
1. ロジャー・フェデラーは2022年に惜しまれながらプロテニスプレイヤーを引退しました。
2. ノバク・ジョコビッチは2023年の全豪オープン、全仏オープン、全米オープンを勝利し、グランドスラムの勝利数が24回になりました。
パラメータ設定
OpenAI 関連のパラメータを事前に .env ファイルとして定義しておく。コードの中で環境変数として読み込み使用する。今回は分かりやすさのために引数に設定する形にするが、DEPLOYMENT_NAME 以外のパラメータは環境変数に設定されていれば引数で与える必要はない。
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME は RAG を行う上で未学習の情報をベクトル化する際に使用するモデル。Azure OpenAI Service だと text-embedding-ada-002 が推奨されている。
OPENAI_API_TYPE=azure
OPENAI_API_VERSION=2023-05-15
OPENAI_API_BASE={YOUR_OPENAI_API_BASE}
OPENAI_API_KEY={YOUR_OPENAI_API_KEY}
DEPLOYMENT_NAME={YOUR_DEPLOYMENT_NAME}
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME={YOUR_EMBEDDINGS_DEPLOYMENT_NAME}
使用するライブラリ
バージョンは任意のもので可。pip install -r requirements.txt でインストールする。
python-dotenv==1.0.0
langchain==0.0.268
openai==0.27.8
tiktoken==0.4.0
chromadb==0.4.10
コード本体
import os
import dotenv
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import AzureChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.schema import AIMessage, HumanMessage
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
dotenv.load_dotenv()
OPENAI_API_TYPE = os.getenv('OPENAI_API_TYPE')
OPENAI_API_VERSION = os.getenv('OPENAI_API_VERSION')
OPENAI_API_BASE = os.getenv('OPENAI_API_BASE')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
DEPLOYMENT_NAME = os.getenv('DEPLOYMENT_NAME')
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME = os.getenv(
'OPENAI_EMBEDDINGS_DEPLOYMENT_NAME')
llm = AzureChatOpenAI(openai_api_version=OPENAI_API_VERSION,
openai_api_base=OPENAI_API_BASE,
openai_api_type=OPENAI_API_TYPE,
openai_api_key=OPENAI_API_KEY,
deployment_name=DEPLOYMENT_NAME,
temperature=0)
embedding = OpenAIEmbeddings(openai_api_version=OPENAI_API_VERSION,
openai_api_base=OPENAI_API_BASE,
openai_api_type=OPENAI_API_TYPE,
openai_api_key=OPENAI_API_KEY,
model=OPENAI_EMBEDDINGS_DEPLOYMENT_NAME)
loader = TextLoader('data/test.txt')
docs = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(documents=docs)
vector_store = Chroma.from_documents(documents=documents, embedding=embedding)
memory = ConversationBufferMemory(memory_key='chat_history',
return_messages=True)
qa = ConversationalRetrievalChain.from_llm(
llm=llm, retriever=vector_store.as_retriever(), memory=memory)
# 作成した Index が k (Default: 4)より少ないと余計なッセージが表示される
# 表示させたくない場合は k を小さくする
# qa = ConversationalRetrievalChain.from_llm(
# llm=llm, retriever=vector_store.as_retriever(search_kwargs={'k': 1}), memory=memory)
while (True):
prompt = input('Q: ')
if prompt == 'q' or not prompt:
break
answer = qa.run(prompt)
print('A: ', answer)
print('-- Chat History --')
for msg in memory.chat_memory.messages:
if type(msg) == AIMessage:
role = 'ai'
elif type(msg) == HumanMessage:
role = 'human'
else:
role = 'system'
print(role, '\t>> ', msg.content)
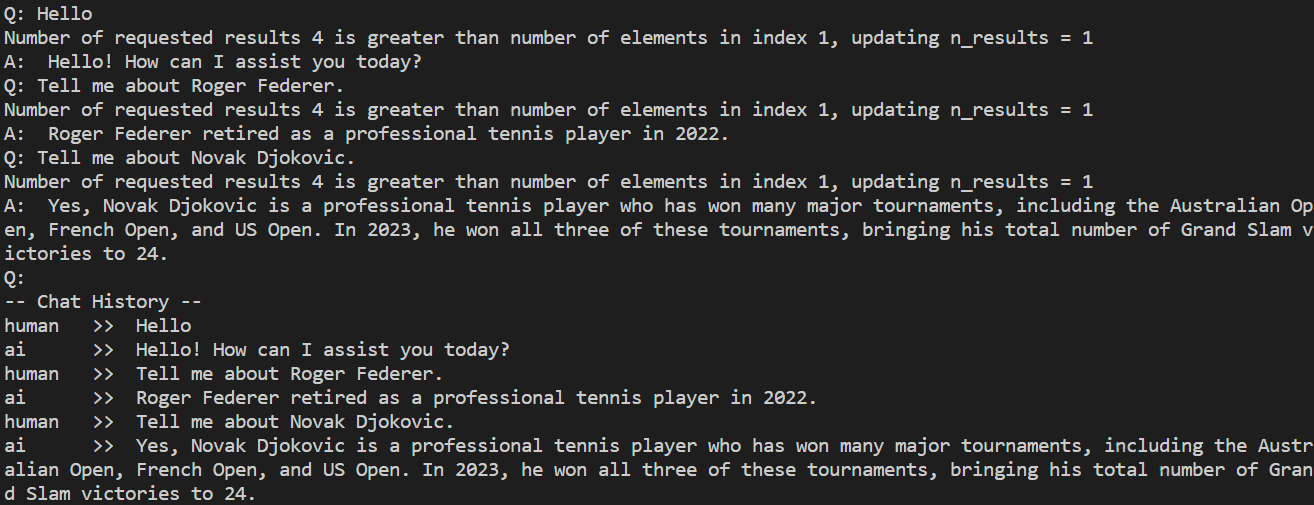
実行してみる
以下のような形で LLM とチャット形式でやりとりできる。test.txt の内容を踏まえて回答してくれている!
Number of requested results 4 is greater than number of elements in index 1, updating n_results = 1 というメッセージは作成した Index が k (Default: 4) より少ない場合に表示されるもの。表示させたくない場合は、k の値を小さくする (上記コード本体のコメントを参照)。
ということで
LangChain を使って、未学習のデータを RAG で LLM に回答させるコードを実装しました!
次回は、Azure Cognitive Search をベクトルストアにするケースを行います。
次回
LangChain を使って Azure Cognitive Search のデータを RAG で回答させてみる
以上です。