やりたいこと
業務で Azure OpenAI Service を使う機会があり、LangChain を使っていろいろとやってみたので複数回で記事にまとめます。今回は、Cognitive Search 内のデータを RAG で LLM から回答させる実装を行います。
すでに多くの方が情報発信していますが、その1つとして参考にしてもらえると幸いです!
他の記事
- Langchain を使って LLM から回答させてみる
- LangChain を使ってローカルファイルを RAG で回答させてみる
- LangChain を使って Azure Cognitive Search のデータを RAG で回答させてみる ← イマココ
前提
- WSL (Ubuntu 22.04) 上で行います
- Python で実装します
- LLM のモデルには、GPT-3.5 を使用します
- Azure OpenAI Service で gpt-35-turbo, text-embedding-ada-002 モデルのデプロイメントは作成済み
- Azure OpenAI Service を使うため、OpenAI 社のものを使う場合と異なる場合があります
- Azure OpenAI Service 及び Cognitive Search は作成済み
- Cognitive Search のインデックス作成もコード内で行います
Cognitive Search とは
基本的な内容はこちらの記事でまとめています。
今回は、プレビュー段階の機能であるベクトル検索を利用します。
実装
パラメータ設定
OpenAI 関連のパラメータを事前に .env ファイルとして定義しておく。コードの中で環境変数として読み込み使用する。今回は分かりやすさのために引数に設定する形にするが、DEPLOYMENT_NAME 以外のパラメータは環境変数に設定されていれば引数で与える必要はない。
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME は RAG を行う上で未学習の情報をベクトル化する際に使用するモデル。Azure OpenAI Service だと text-embedding-ada-002 が推奨されている。
今回はさらに Cognitive Search 関係のパラメータを追加している。
OPENAI_API_TYPE=azure
OPENAI_API_VERSION=2023-05-15
OPENAI_API_BASE={YOUR_OPENAI_API_BASE}
OPENAI_API_KEY={YOUR_OPENAI_API_KEY}
DEPLOYMENT_NAME={YOUR_DEPLOYMENT_NAME}
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME={YOUR_EMBEDDINGS_DEPLOYMENT_NAME}
SEARCH_ENDPOINT={YOUR_COG_SEARCH_ENDPOINT}
SEARCH_SERVICE_NAME={YOUR_COG_SEARCH_NAME}
SEARCH_API_KEY_ADMIN={YOUR_COG_SEARCH_ADMIN_KEY}
使用するライブラリ
バージョンは任意のもので可。pip install -r requirements.txt でインストールする。
python-dotenv==1.0.0
langchain==0.0.268
openai==0.27.8
tiktoken==0.4.0
azure-search-documents==11.4.0b6
azure-identity==1.13.0b4
chromadb==0.4.10
コード本体
import argparse
import os
import time
from azure.core.credentials import AzureKeyCredential
from azure.search.documents.indexes import SearchIndexClient
from azure.search.documents.indexes.models import (SearchableField,
SearchField,
SearchFieldDataType,
SimpleField)
from dotenv import load_dotenv
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import AzureChatOpenAI
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.retrievers import AzureCognitiveSearchRetriever
from langchain.schema import AIMessage, HumanMessage
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.azuresearch import AzureSearch
load_dotenv()
OPENAI_API_TYPE = os.getenv('OPENAI_API_TYPE')
OPENAI_API_VERSION = os.getenv('OPENAI_API_VERSION')
OPENAI_API_BASE = os.getenv('OPENAI_API_BASE')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
DEPLOYMENT_NAME = os.getenv('DEPLOYMENT_NAME')
OPENAI_EMBEDDINGS_DEPLOYMENT_NAME = os.getenv(
'OPENAI_EMBEDDINGS_DEPLOYMENT_NAME')
SEARCH_ENDPOINT = os.getenv('SEARCH_ENDPOINT')
SEARCH_SERVICE_NAME = os.getenv('SEARCH_SERVICE_NAME')
SEARCH_API_KEY_ADMIN = os.getenv('SEARCH_API_KEY_ADMIN')
INDEX_NAME = 'test-index'
def create_indexes(index_name: str, loader: TextLoader,
embeddings: OpenAIEmbeddings) -> None:
fields = [
SimpleField(
name='id',
type=SearchFieldDataType.String,
key=True,
filterable=True,
),
SearchableField(
name='content',
type=SearchFieldDataType.String,
searchable=True,
analyzer_name='ja.lucene',
),
SearchField(
name='content_vector',
type=SearchFieldDataType.Collection(SearchFieldDataType.Single),
searchable=True,
vector_search_dimensions=len(embeddings.embed_query('Text')),
vector_search_configuration='default',
),
SearchableField(
name='metadata',
type=SearchFieldDataType.String,
searchable=True,
),
]
vector_store = AzureSearch(azure_search_endpoint=SEARCH_ENDPOINT,
azure_search_key=SEARCH_API_KEY_ADMIN,
index_name=index_name,
embedding_function=embeddings.embed_query,
fields=fields)
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents)
vector_store.add_documents(documents=split_docs)
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--debug', action='store_true')
args = parser.parse_args()
is_debug = args.debug
if is_debug:
import langchain
import openai
openai.log = 'debug'
langchain.debug = True
index_client = SearchIndexClient(
endpoint=SEARCH_ENDPOINT,
credential=AzureKeyCredential(SEARCH_API_KEY_ADMIN))
indexes = index_client.list_index_names()
if INDEX_NAME in indexes:
print(f'{INDEX_NAME} already exists')
else:
print(f'creating {INDEX_NAME}')
loader = TextLoader('./data/test.txt')
embeddings = OpenAIEmbeddings(openai_api_type=OPENAI_API_TYPE,
model=OPENAI_EMBEDDINGS_DEPLOYMENT_NAME,
openai_api_base=OPENAI_API_BASE,
openai_api_key=OPENAI_API_KEY,
deployment=OPENAI_EMBEDDINGS_DEPLOYMENT_NAME)
create_indexes(INDEX_NAME, loader, embeddings)
time.sleep(5) # wait for index creation
llm = AzureChatOpenAI(openai_api_key=OPENAI_API_KEY,
openai_api_type=OPENAI_API_TYPE,
openai_api_base=OPENAI_API_BASE,
openai_api_version=OPENAI_API_VERSION,
deployment_name=DEPLOYMENT_NAME,
temperature=0)
cog_src_retriever = AzureCognitiveSearchRetriever(
service_name=SEARCH_SERVICE_NAME,
api_key=SEARCH_API_KEY_ADMIN,
index_name=INDEX_NAME,
content_key='content',
top_k=3)
memory = ConversationBufferMemory(memory_key='chat_history',
return_messages=True)
qa = ConversationalRetrievalChain.from_llm(llm=llm,
retriever=cog_src_retriever,
memory=memory)
while (True):
prompt = input('Q: ')
if prompt == 'q' or not prompt:
break
answer = qa.run(prompt)
print('A: ', answer)
print('-- Chat History --')
for msg in memory.chat_memory.messages:
if type(msg) == AIMessage:
role = 'ai'
elif type(msg) == HumanMessage:
role = 'human'
else:
role = 'system'
print(role, '\t>> ', msg.content)
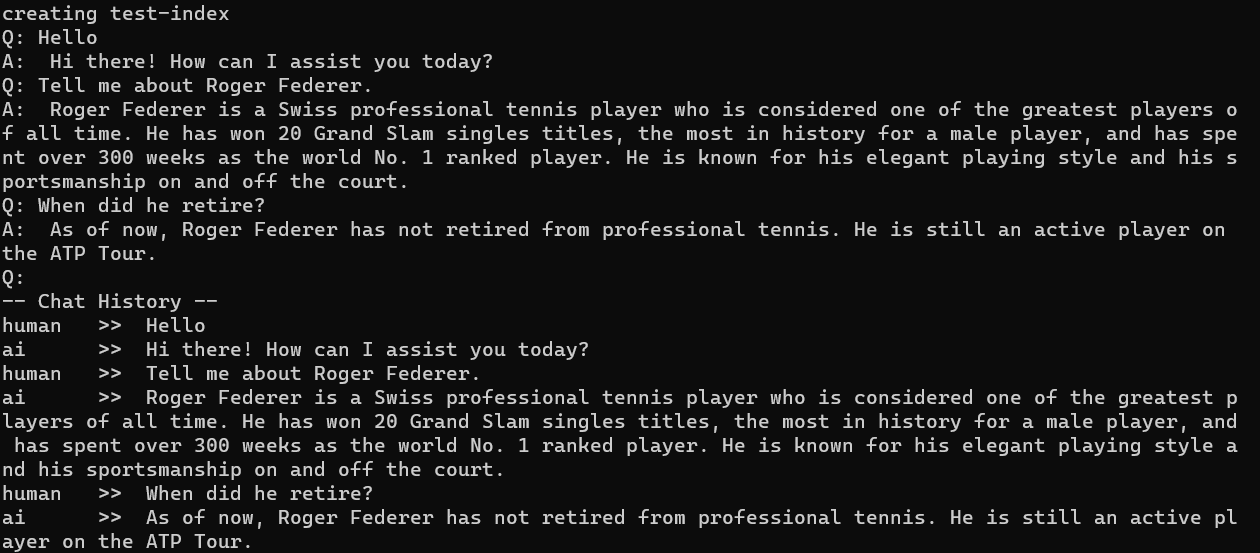
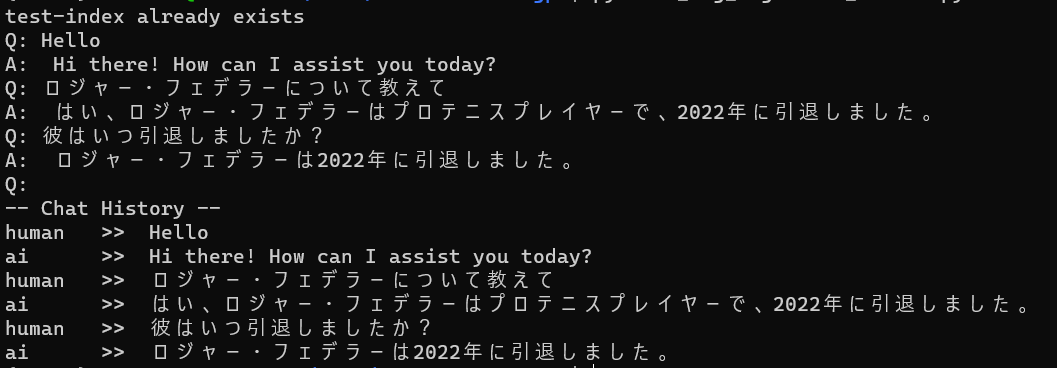
実行してみる
前回と異なり、英語で質問すると期待する回答が得られなかったが日本語で質問すると期待する回答が得られた!
未学習のデータとして与えているファイルは日本語で書かれているが、前回は英語で質問しても期待する回答が得られたので Cognitive Search 側で日本語・英語を区別して関連するドキュメントを検索しているのかなと思う。機会があれば別途検証してみようと思う
ということで
LangChain を使って、Cognitive Search 上のデータを RAG で LLM に回答させるコードを実装しました!
複数回で記事にしましたが、ひとまずこれで終了です!
以上です。