はじめに
TensorFlow2 + Keras による画像分類の勉強メモ(**CNN編**の第1弾)です。MLP編(多層パーセプトロンモデル編)については、こちらをご覧ください。
なお、題材はド定番である**手書き数字画像(MNIST)**の分類です。
今回は、ブラックボックスのまま、とりあえずCNNモデルを学習させて、それを使って予測(分類)をしてみます。
MLP版のプログラム
多層パーセプトロンモデルによる手書き数字画像(MNIST)分類は、TensorFlow2 + Keras を利用して、次のように書くことができました(詳細)。
%tensorflow_version 2.x
import tensorflow as tf
# (1) 手書き数字画像のデータセットをダウンロード・正規化
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# (2) MLPモデルを構築
model = tf.keras.models.Sequential()
model.add( tf.keras.layers.Flatten(input_shape=(28, 28)) )
model.add( tf.keras.layers.Dense(128, activation='relu') )
model.add( tf.keras.layers.Dropout(0.2) )
model.add( tf.keras.layers.Dense(10, activation='softmax') )
# (3) モデルのコンパイル・トレーニング
model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
# (4) モデルの評価
model.evaluate(x_test, y_test, verbose=2)
これを実行すると、正解率 $97.7%$ 前後の分類器をつくることができました。
CNN版のプログラム
**畳み込みニューラルネットワークモデル(CNN)**による手書き数字画像(MNIST)分類は、次のように書くことができます。多層パーセプトロンのモデルに、なんと3行追加するだけで畳み込みニューラルネットワークモデルに変えることができます。
# (1) 手書き数字画像のデータセットをダウンロード・正規化
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# (2) CNNモデルを構築
model = tf.keras.models.Sequential()
model.add( tf.keras.layers.Reshape((28, 28, 1), input_shape=(28, 28)) ) # 追加
model.add( tf.keras.layers.Conv2D(32, (5, 5), activation='relu') ) # 追加
model.add( tf.keras.layers.MaxPooling2D(pool_size=(2,2)) ) # 追加
model.add( tf.keras.layers.Flatten() ) # 改変
model.add( tf.keras.layers.Dense(128, activation='relu') )
model.add( tf.keras.layers.Dropout(0.2) )
model.add( tf.keras.layers.Dense(10, activation='softmax') )
# (3) モデルのコンパイル・トレーニング
model.compile(optimizer='Adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
# (4) モデルの評価
model.evaluate(x_test, y_test, verbose=2)
これを実行すると、正解率 $98.7%$ 前後の分類器をつくることができます(上記のMLPよりも正解率が約$1%$ほど高いモデルをつくることができます)。ただし、学習にかかる時間は長くなっています。
正しく予測できなかった事例
分類(予測)に失敗している具体的なケースを見てみます(これを出力するためのプログラムは「~分類に失敗する画像を観察してみる~」を参照)。
各図の左上に表示している赤文字は、誤って何の数字と予測したかという情報です(括弧内数値は、誤った予測に対するsoftmax出力)。例えば 5(0.9) は、「約 $90%$ の確信をもって $5$ と予測した」ということです。また、青色の数値は、テストデータ test_x のインデックス番号です。
正解値「0」について正しく予測(分類)できなかったケース 4/980件

正解値「1」について正しく予測(分類)できなかったケース 4/1135件

正解値「2」について正しく予測(分類)できなかったケース 8/1032件
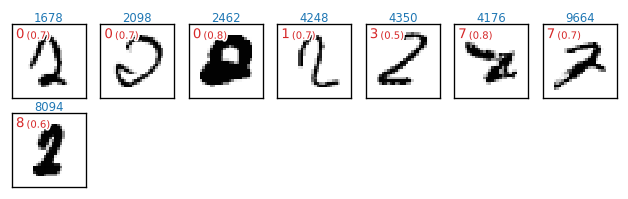
正解値「3」について正しく予測(分類)できなかったケース 12/1010件
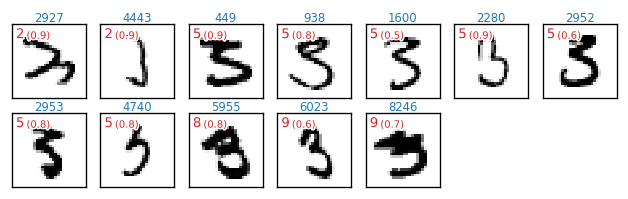
正解値「4」について正しく予測(分類)できなかったケース 15/982件
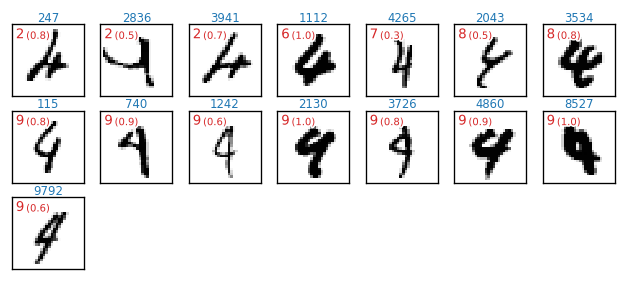
正解値「5」について正しく予測(分類)できなかったケース 6/892件

正解値「6」について正しく予測(分類)できなかったケース 13/958件
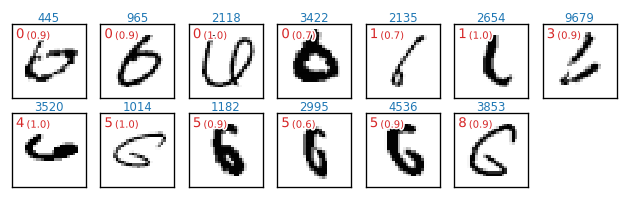
正解値「7」について正しく予測(分類)できなかったケース 15/1028件
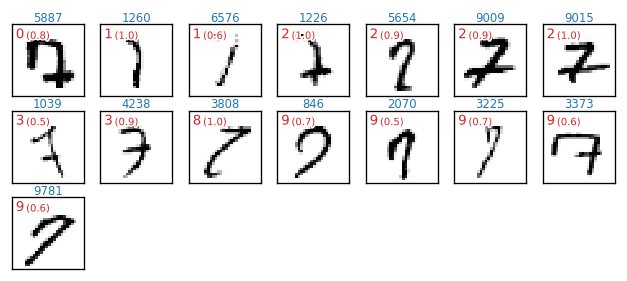
正解値「8」について正しく予測(分類)できなかったケース 27/974件

正解値「9」について正しく予測(分類)できなかったケース 26/1009件

次回
**畳み込みニューラルネットワークモデル(CNN)**は、なんで画像分類・画像認識に適しているのか、そもそも畳み込み(フィルタ)とは?といった内容を取り上げていきたいと思います。