はじめに
今回使うEmbulkとはバルクデータローダーです。
バルクロードとは、簡単に言うとデータをまとめてロードすることです。
bulkの意味が分かればなんとなくイメージつくかなと思います。(大量とか、まとめてとかそんなイメージ)
OSSなので、だれでも無料で利用することができます。
サイトに記載されている通り、Embulkはプラグインを利用することでさまざまなサービスと接続して、サービス間のデータ転送を行うことができます。
様々なデータベース、ストレージ、ファイル形式、クラウドサービスなどの間でのデータ転送をサポートします。
⚠注意点
Embulkはメンテナンスモードに移行しています。
今後のアップデートはあまり期待できない状況なので注意してください。
今回やること
- AWSのAmazon Linux2023にEmbulkを導入
- Embulkを今まで通り使えるようにエイリアスを作成
- Azure上の踏み台サーバを経由(SSH)して、プライベートのAzure SQL Serverのデータを抽出
- 抽出したデータをcsv形式でAmazon S3にアップロード
この記事の前提
この検証を行う際に、すでにAzure上の設定とAWSのEC2作成は完了していたので、説明を省きます。
以下を用意しておいてください。
- Azure 仮想マシン
- SSH接続用のユーザ作成
- SSH用の秘密鍵生成
- ネットワークセキュリティグループの設定
- AWSのEC2からSSHを許可(インバウンドルール)
- Azure SQL ServerへのJDBC接続を許可(アウトバウンドルール)
- Azure SQL Server
プライベートエンドポイント
- Amazon EC2
- パブリックIPv4アドレスの付与
- S3バケット操作用のIAMロールのアタッチ
- 2GB以上のメモリ
なお、Azureの仮想マシンとAWSのEC2はパブリックの通信を前提とします。
実際にやってみる
IAMロールの確認
一応IAMロールと、IAMロールに割り当てるIAMポリシーを確認しておきます。
S3バケットにファイルをアップロードするため、S3操作権限を割り当てる必要があります。
まずこちらがEC2にアタッチするロールです。
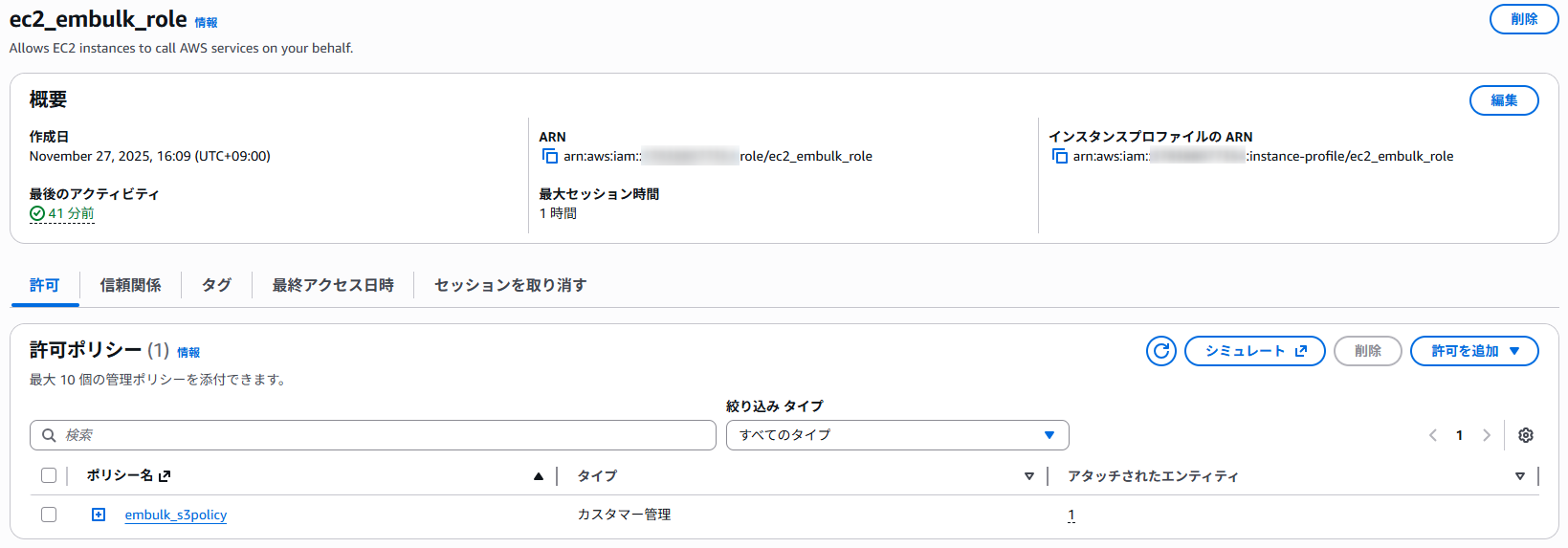
EC2がこのロールを使えるようにプリンシパルにEC2サービスを指定します。
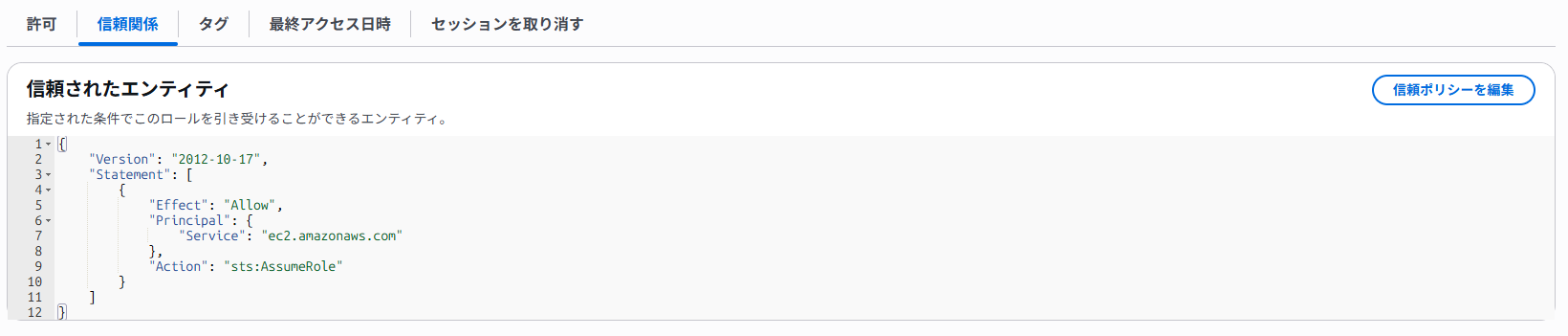
そして、こちらがIAMロールに割り当てているIAMポリシーです。
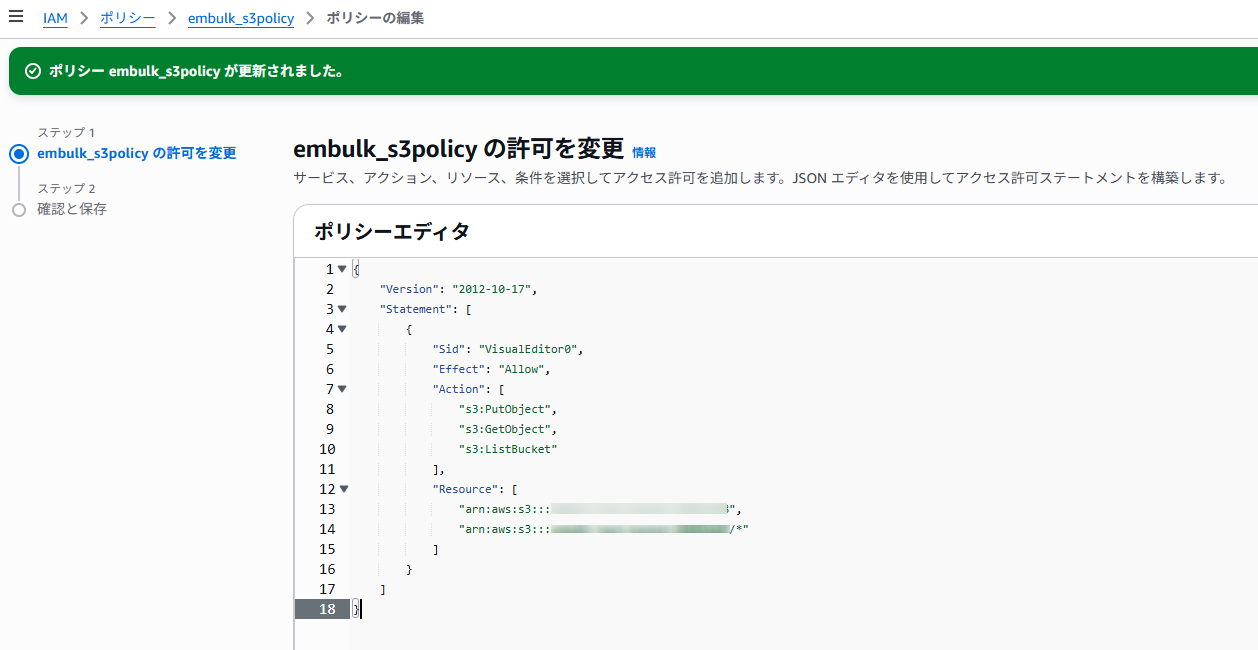
EC2インスタンスにもアタッチされていますね。これでEC2の設定は終わりです。

ユーザの作成
EC2の起動が完了したらユーザの作成をしておきます。
お好きなようにでOKです。
sudoできるように設定も入れておきましょう。
sudo useradd <ユーザ名>
sudo passwd <ユーザ名>
sudo usermod -aG wheel <ユーザ名>
sudo visudo
sudo visudoをしたら以下を末尾に追加しておきます。
<ユーザ名> ALL=(ALL:ALL) NOPASSWD:ALL
Javaのインストール
使うユーザにまずスイッチしておきましょう。
su - <ユーザ名>
dnf updateを実行します。
sudo dnf update
Javaをインストールします。
なお、ここでインストールするバージョンはJava8にしてください。
Embulk v0.11ではJava8を公式サポートしているためです。
それ以降のバージョンでも動くようですが、変なエラーが出ても嫌なので、いったん公式通りにしておきます。
sudo dnf install java-1.8.0-openjdk
以下コマンドでバージョンが表示されればOKです。
java -version
Embulkのインストール
mkdir -p ~/.embulk/bin
cd ~/.embulk/bin
curl -OL https://github.com/embulk/embulk/releases/download/v0.11.5/embulk-0.11.5.jar
chmod +x embulk-0.11.5.jar
エイリアスの作成
Embulkv0.9以降では、java -jar embulk-X.XX.X.jar ~~という呼び出し方法に変わっているのですがさすがに長すぎるので、エイリアスを作成しておきます。
vi ~/.bashrc
以下を最終行に追記して保存します。
一応、以下のように指定しておきます。
alias embulk='java -jar $(find $HOME/.embulk/bin -name "embulk-*.jar" | head -1)'
反映しておきましょう。これで「embulk」でコマンド実行できるようになりました。
source ~/.bashrc
jrubyのインストール
Embulk v0.9からjrubyプラグインがインストールされていません。
Embulk gemを利用したい場合は、jrubyを自身でインストールする必要があります。
Embulkでは9.Xのバージョンで動作できるようなので、9系の新しいバージョンをインストールすることにします。
jrubyが古いとEmbulkが正常に動作しない場合があります。
cd ~/
curl -OL https://repo1.maven.org/maven2/org/jruby/jruby-complete/9.4.14.0/jruby-complete-9.4.14.0.jar
Ruby gemもインストールしておきます。
embulk gem install embulk -v 0.11.5 # ここで指定するバージョンはEmbulkと同じバージョンを指定してください。
embulk gem install msgpack
embulk gem install bundler
embulk gem install liquid
embulkがjrubyを認識できるようにプロパティファイルを作成します。
vi ~/.embulk/embulk.properties
以下を定義ファイルに入力して保存します。
適宜調整してください。
JVMのオプションが必要であればここに記載してもOKだそうです。
jruby=file:///home/testuser/jruby-complete-9.4.14.0.jar
プラグインのインストール
プラグインはembulk gem install 'パッケージ名'もしくは、embulk install 'パッケージ名'でインストールします。
特に何も設定していないと、embulk installを実行した場合、リモートのMavenリポジトリを参照します。
今回は、SQL Serverから情報を取得したいのと、S3に情報を出力したいので、以下のプラグインを利用します。
インストールします。
embulk install 'org.embulk:embulk-input-sqlserver:0.13.2'
embulk install 'org.embulk:embulk-output-s3:1.7.1'
検証の中でSQL Server用のプラグインだけうまく認識できなかったので、プロパティに記載しておきます。
vi ~/.embulk/embulk.properties
以下を追記します。
plugins.input.sqlserver=maven:org.embulk:sqlserver:0.13.2
JDBCドライバーのインストール
JDBCドライバーをインストールします。
うまいこと持ってこれなかったので、S3を一度経由しました。
以下からダウンロードしてください。
ダウンロードが完了したら解凍して、jarファイルを配置します。
今回はjava8なのでjava8用のドライバーを作成します。
mkdir -p ~/.embulk/lib/drivers
cp <解凍後のファイルパス> ~/.embulk/lib/drivers/
chmod +x ~/.embulk/lib/drivers/*.jar
SSHトンネルの作成
SSH経由でSQL Serverへ通信を行うため、SSHの設定を行います。
踏み台サーバで作成した秘密鍵の内容をコピーしておいてください。
以下はEC2で作業します。
なお、ここまでの作業とは別のターミナルを起動しておいた方がすっきりします。
mkdir ~/.ssh
vi ~/.ssh/<暗号鍵名>
chmod 600 ~/.ssh/<暗号鍵名>
これでコピーしておいた内容を張り付けてSSH用の鍵を作成します。
ここまで完了したらSSHを行います。
ssh -f -N -L 1433:<SQL ServerのFQDN>:1433 -i ~/.ssh/<暗号鍵名> <踏み台サーバのユーザ名>@<踏み台サーバのIPアドレス>
embulkの実行
やっとembulkの実行です。
以下のQuick Startにある通りやってみましょう。
以下でサンプルファイルを生成します。
embulk example ./try1
seed.ymlを修正します。
seed.ymlの内容を推察していい感じにconfig.ymlを作成してくれます。
私はよくわからないまま触っていたので、ここでサンプルのまま出力させて直接config.ymlを修正していました。
embulk guess ./try1/seed.yml -o config.yml
情報はマスキングしますが、定義ファイルの内容はこのようにしました。
hostの部分はlocalhostを指定します。
ローカルポートフォワーディングを行っているためです。
auth_methodはinstanceを指定するとインスタンスプロファイル(IAMロール)の権限に従います。
それ以外では、アクセスキー/シークレットアクセスキーによる認証もサポートしています。
in:
type: sqlserver
driver_path: <ローカルのjarファイルパス>
host: localhost
port: 1433
user: <データベースユーザ名>@<SQL Serverのサーバ名>
password: "<データベースユーザのパスワード>"
database: <データベース名>
schema: <スキーマ名>
table: <テーブル名>
out:
type: s3
bucket: <S3バケット名>
path_prefix: <S3プレフィックス>
file_ext: .csv
formatter:
type: csv
auth_method: instance
以下で定義ファイルをプレビューできます。
内容が正しいか確認します。
embulk preview config.yml
正しければ、実際に実行します。
embulk run config.yml
しばらく待つとコンソール上に色々メッセージが出力されます。
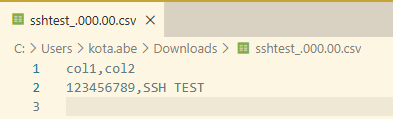
特段エラーがなさそうなので、S3を確認してみます。
無事にファイルが出力されていました。

中身も確認しましたが、テーブルの情報も取得できていました。
おわりに
今回は、Embulkを自分で設定して利用してみました。
Embulkは以前少し紹介したTROCCOでも利用されている技術です。
Embulkを知ることでTROCCOを利用する際にイメージが湧きやすくなりました。
今後のアップデートはあまり期待できない状況ではありますが、
閉域網での利用だったり、最大限コストを抑えたい場合などではまだまだ使えるかなと思います。
このエントリが誰かの役に立てば幸いです。