本記事はBeeX Advent Calendar 2025の11日目の記事です。
はじめに
今回はS3 Tablesをマネジメントコンソール上から構築します。
オープンテーブルフォーマットの一つであるApache Icebergを標準サポートしているオブジェクトストレージ。それがS3 Tablesです。
Apache Icebergは、ざっくりいうとオブジェクトストレージに存在しているデータをカタログとメタデータ使って管理することで、データの更新・削除、過去データの確認などが簡単に行える仕組みです。
さらにACID特性を備えているため、この仕組みを使うことで、トランザクションデータレイクとして運用できるようにもなります。
Apache Icebergを使うことで解消できること
例えば、ファイル内に10,000行のデータを持つcsvファイルをS3汎用バケットに格納して、Athenaを使ってテーブルとして参照するとします。
運用していく中で、そのうちの1行を削除する必要が出てきました。
この場合、Athenaはレコードの削除を許容していないため1行削除する場合は9,999行にしたcsvファイルを再度用意する必要がありました。
このケースでは、クエリ効率化などを考えるとパーティションを意識する必要があったり、S3汎用バケットのコストも気にしていく必要があります。
RedshiftなどのDWHを導入して運用していくのも手ですが、コスト的に高くなるのとRedshiftに接続できるツールを導入する必要がありますね。
こうした課題を解決できるのがApache Icebergです。
Apache Icebergを使えば、レコードレベルの削除ができるようになり、運用を効率化できます。
また、AthenaではApache Icebergテーブルに限りレコードレベルの削除も対応しています。
この機能を利用することで、データ自体を作成して再連携したり、クエリ実行時にパーティションなどを意識する必要がほとんどなくなります。
実際に作ってみる
まずは、S3のコンソール画面を開いてテーブルバケットを選択します。
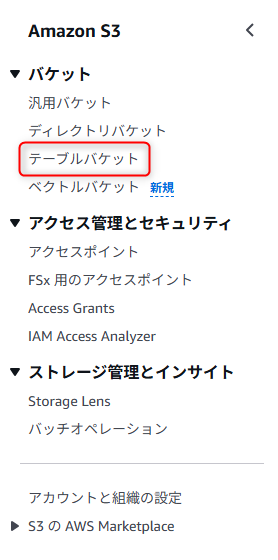
テーブルバケットでは、AWSの分析サービスと統合させる必要があるので、統合を有効化していない場合は有効化する必要があります。
カタログ、メタデータの管理にGlueのデータカタログを裏で利用していると思うので、ここは必須になりそうです。
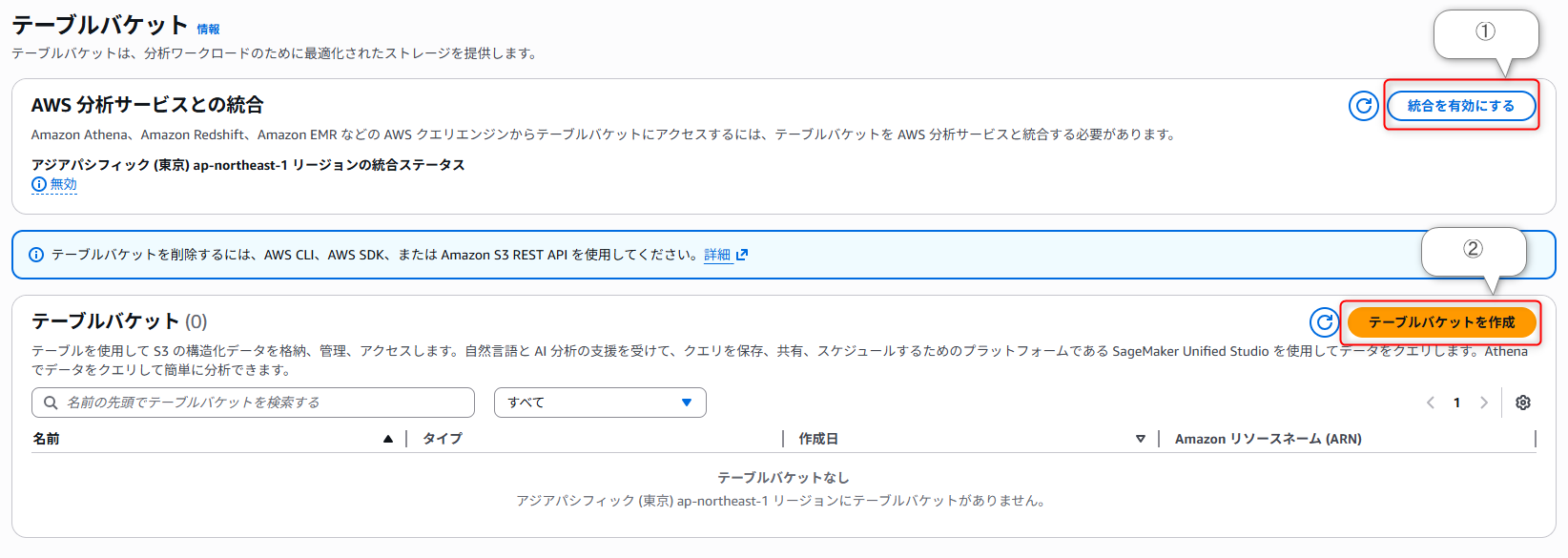

統合が有効化できたらバケットを作成していきます。
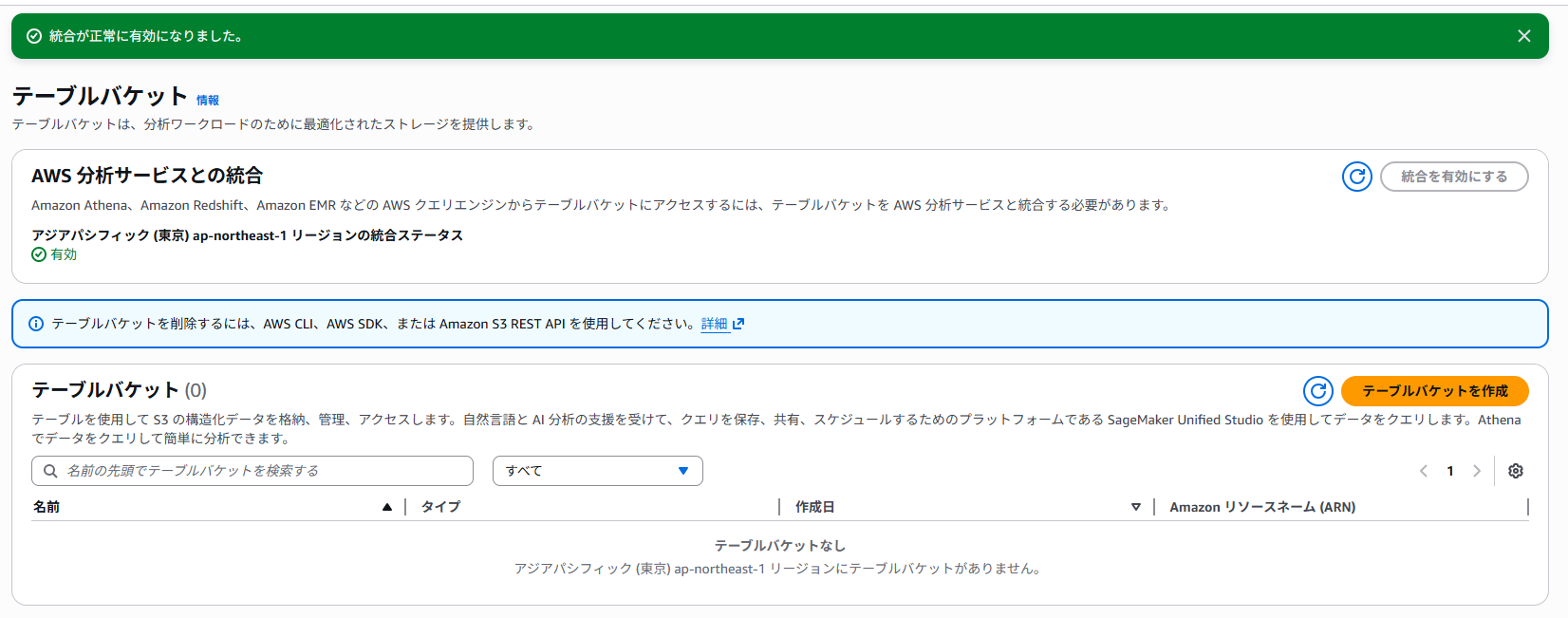
バケット作成画面は思ったよりもシンプルで、複雑な設定はありません。
一旦はバケット名だけ決めて作成してしまいます。

ちなみにApache Icebergでは更新のたびに裏でメタデータや実際のデータファイルなどが増えていくため、更新量が多い場合はコスト管理が重要です。
2025年に行われたre:inventでは「S3TablesのIntelliigent-Tiering」が発表されました。必要な場合にはこちらで有効化してください。
これでテーブルバケットは作成できました。
少し中身を見てみると、従来の汎用バケットと違い、オブジェクトを自分で入れることはできません。
自身でオブジェクトを管理する場合は、汎用バケットを使ってメタデータを連携させることでも実現可能なようなので別の機会に試してみます。

バケット名を選択するとAthenaでテーブルを作成できるようなので選択してみます。
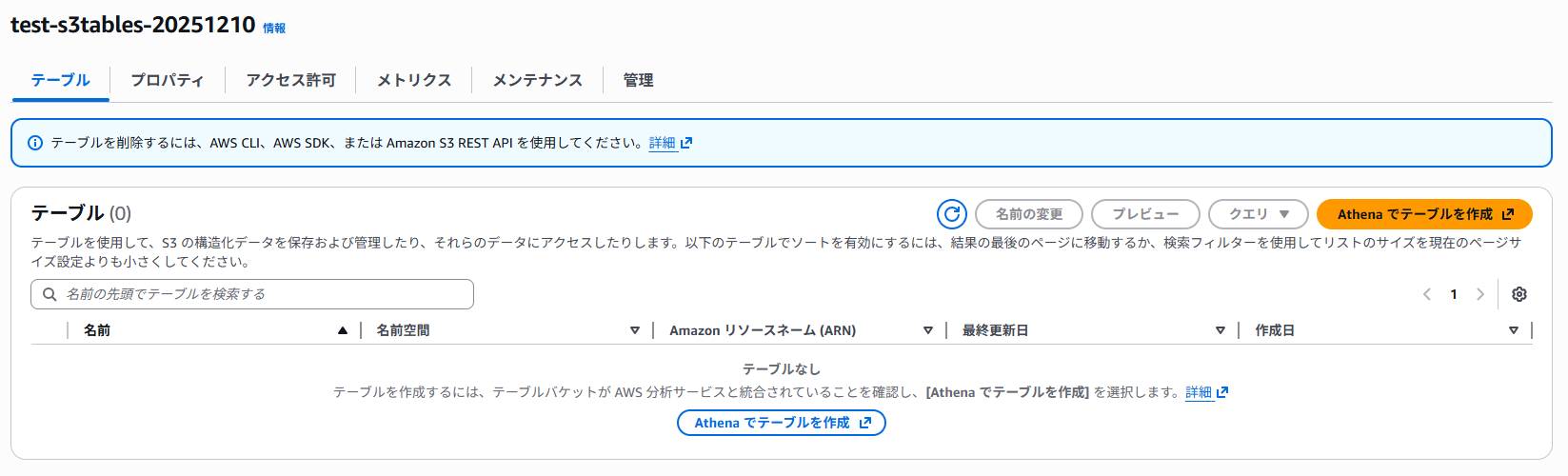
ここでは名前空間を入力します。
名前空間といわれるとなんだそれ?となるのですが、データベースという捉え方でよいと思います。(適切ではないかもしれませんが。)


次にAthenaの画面に遷移しました。
既にS3テーブルを作成するためのSQL文が入力されているので、そのまま実行したいと思います。
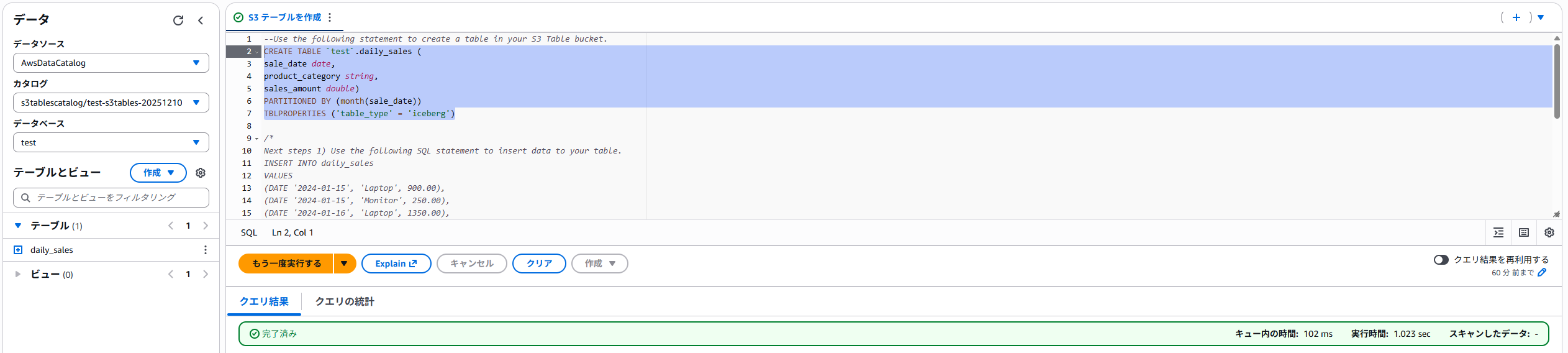
まずは、テーブルの作成です。
通常のCREATE文とほとんど一緒ですが、TBLPROPARTIESにicebergが指定されています。

実行すると、左ペインのテーブルが増えました。
ここはAthenaで普通にテーブルを作成した時と変わらないですね。
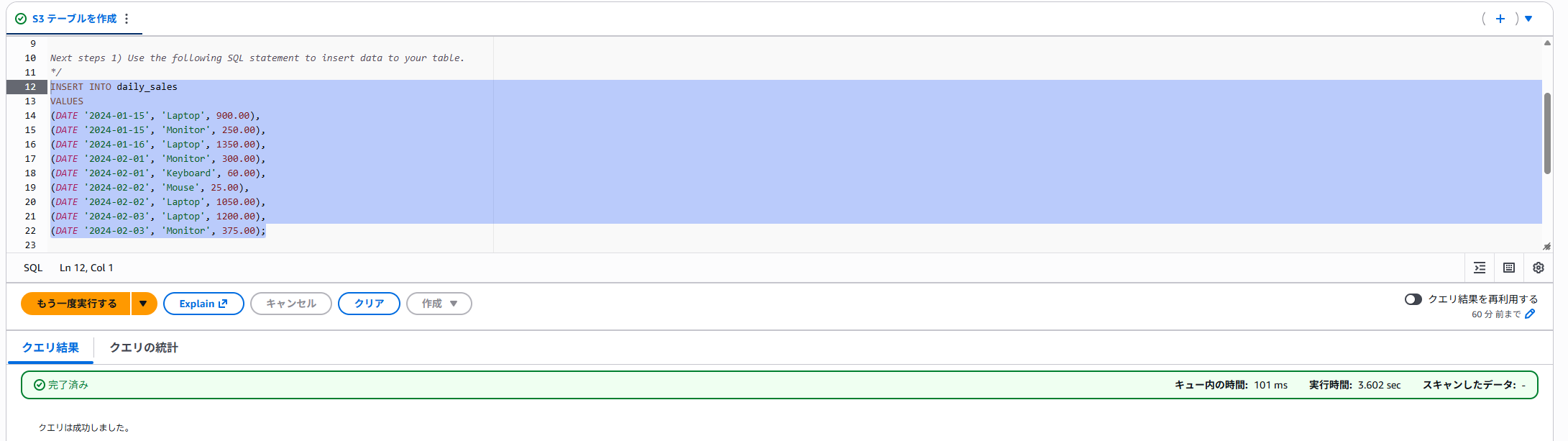
データも入れてみます。こちらも通常の操作でできましたね。
参照も通常の操作で行うことができます。

一応S3 Tablesの画面から先ほど作成した名前空間のプロパティも確認しておきます。
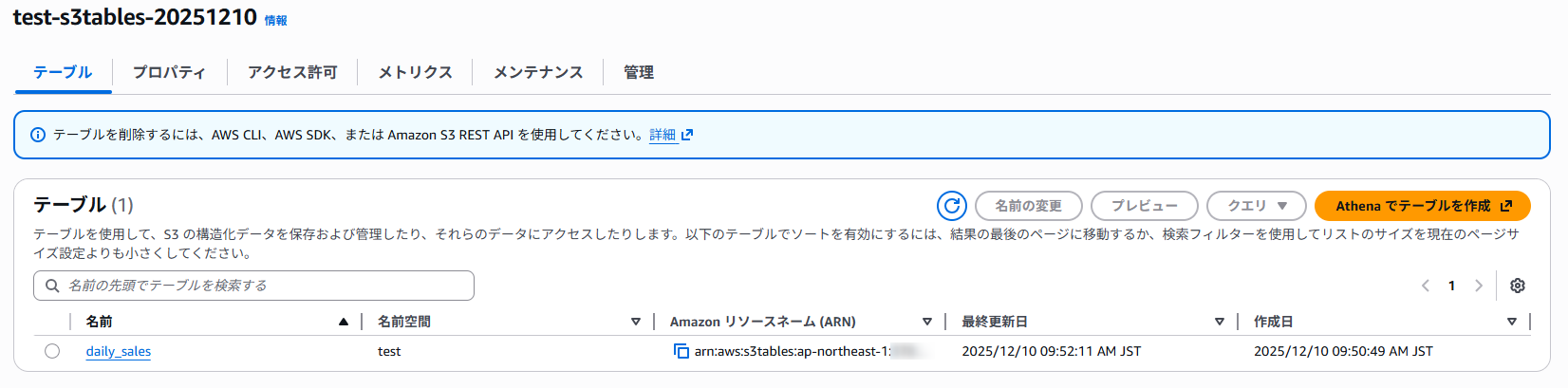
何やらメタデータの場所などの情報が記載されていますね。
s3://~~~…と書いているのですがこんなバケットは私のアカウントにはないので、AWSが管理している領域なのでしょう。

また、スキーマの欄を見ると先ほど作成したテーブルの情報が確認できます。
データベースの概念に当てはめるとカラムのような位置づけのようですね。

次は、Apache Icebergの魅力であるレコードレベルの操作を行います。
以下の赤枠内の値を書き換えようと思います。
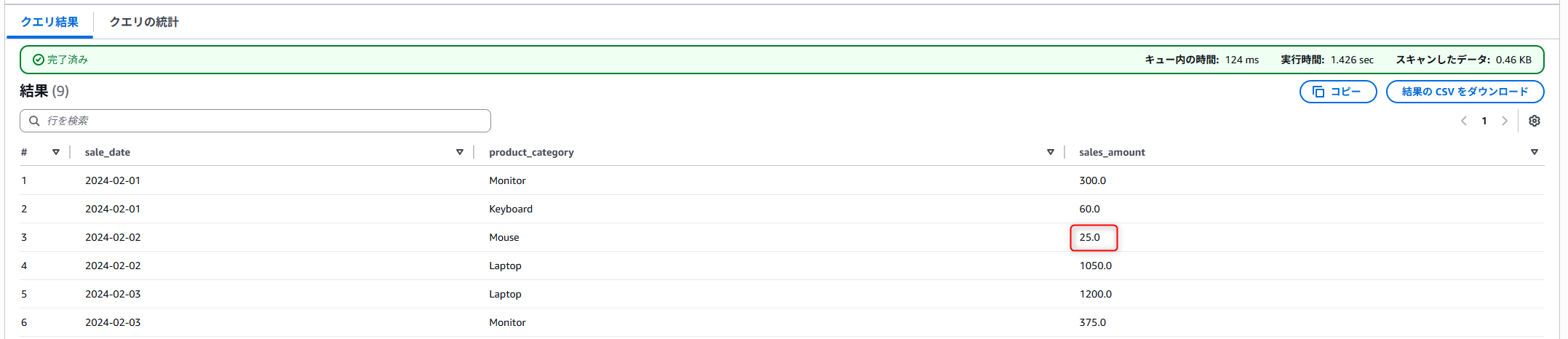
UPDATEを使って値を変更します。
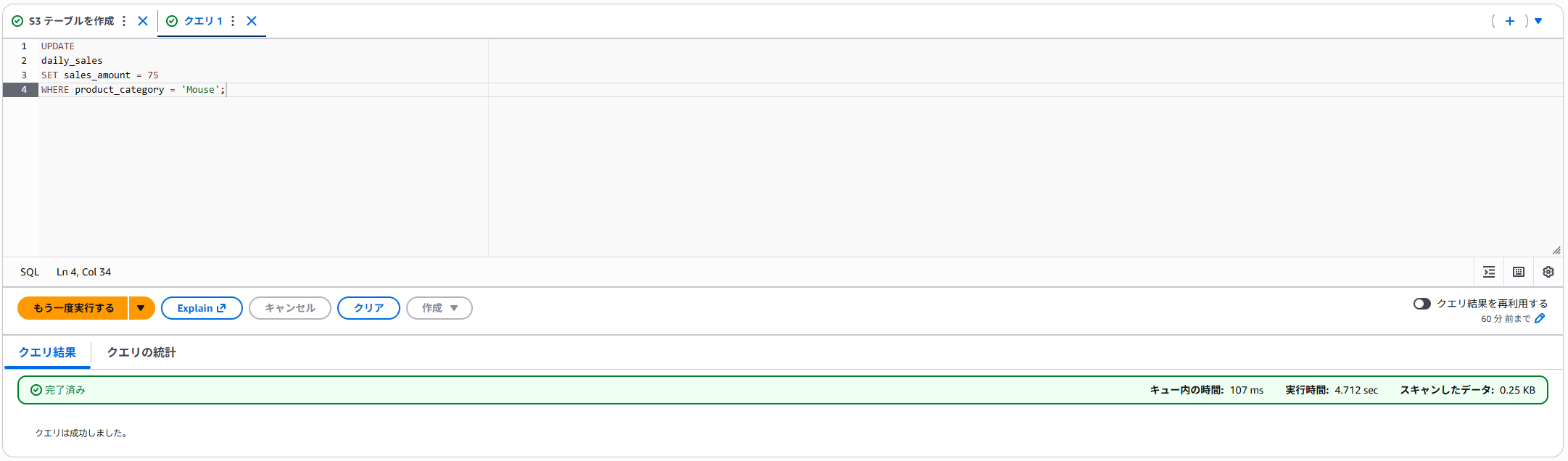
無事に変更できました。

Apache Icebergでは、データ層にあるデータファイルはDELETEでは削除されず、削除したという履歴を使って最新のデータを参照します。※詳しい話をすると難しくなるので割愛します。
これの何がいいというと、過去データの参照も行えるという点です。
では、実際に過去データを参照します。
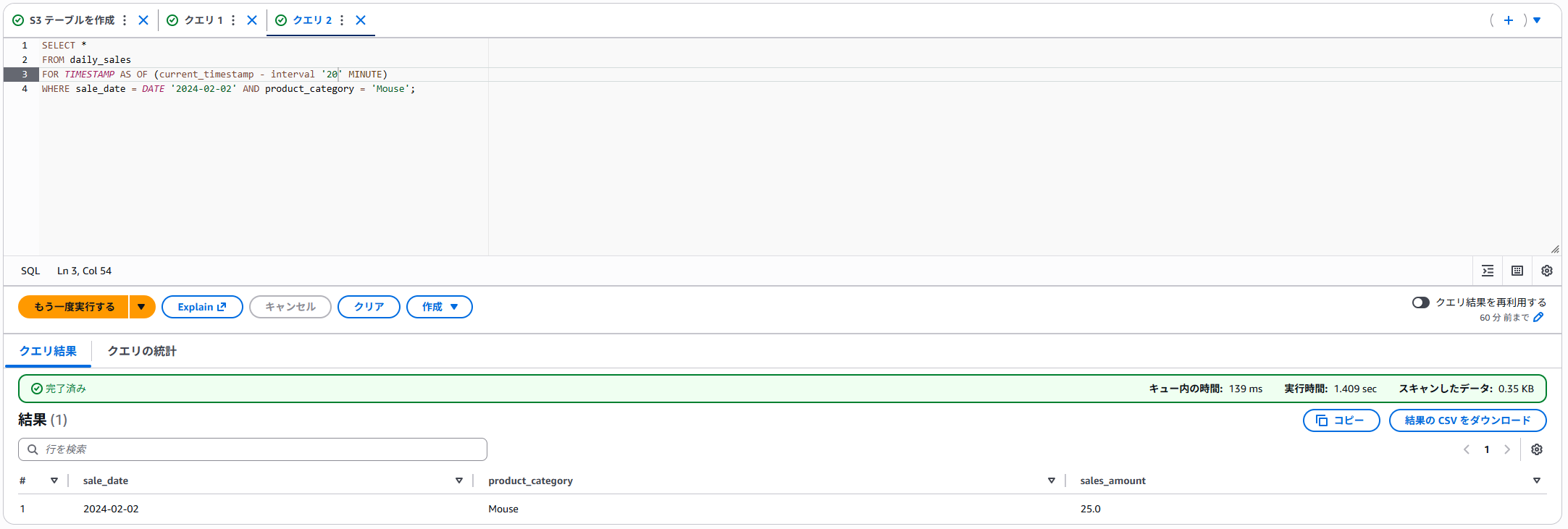
スナップショットIDなどを指定することでも過去データを確認することができるのですが、スナップショットIDの取得が必要になるので、今回はタイムトラベル機能を使って過去データを参照します。
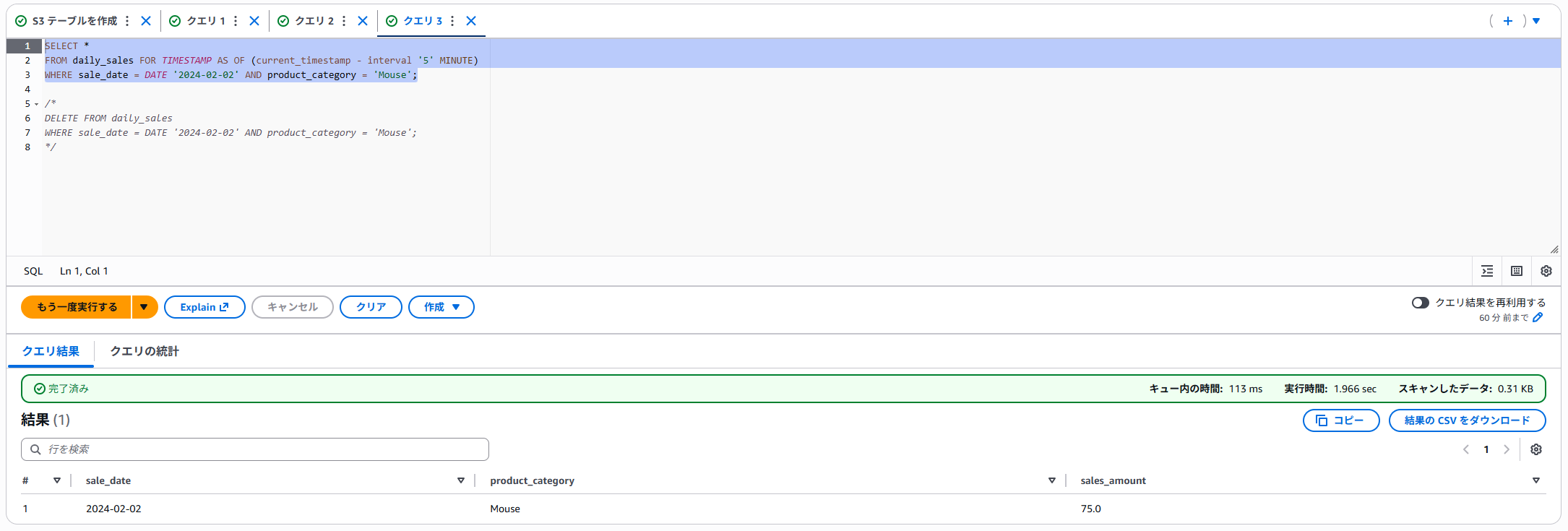
SELECT文で、FOR TIMESTAMP AS OF timestampを使うことで過去データが参照できます。
まず削除するレコードを確認しておきます。
DELETEで削除します。

無事に削除できました。
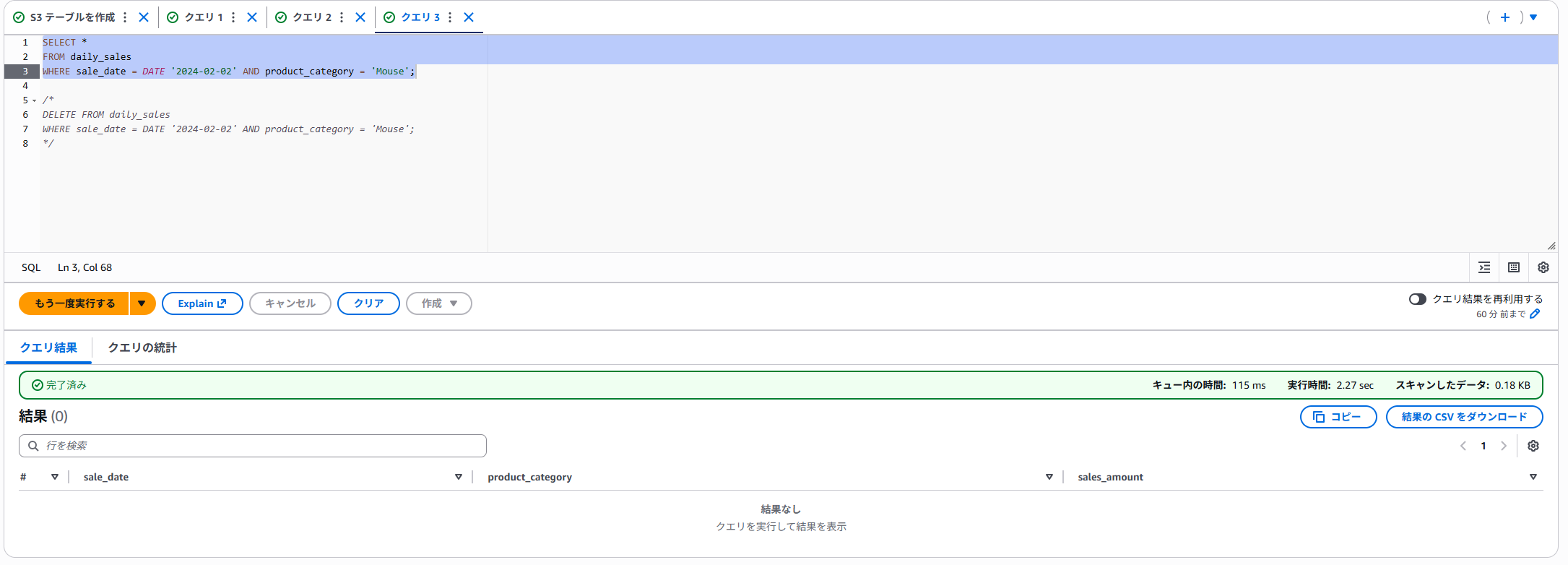
タイムトラベル機能を使ってクエリします。
無事に削除前のデータを確認することができました。
最後に、作成したバケットを削除しておきます。
バケットの削除は2025/12/10現在、AWS CLIもしくはApache Sparkセッションからでないと削除できません。
⚠各手順にリンクを載せていますが、テーブル自体を削除した場合などはタイムトラベル機能などで過去データを参照することができなくなります。ご注意ください。
今回はAWS CLIを使って削除します。
CloudShellでAWS CLIを利用します。
まずは、テーブルの削除を試してみましょう。
aws s3tables delete-tableで削除ができます。
特に何も出力されませんでしたが、コンソール画面を確認すると削除されていました。


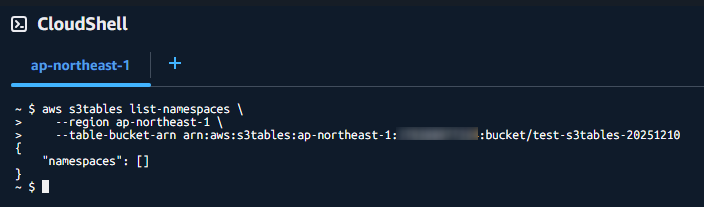
次に名前空間の削除を試します。
aws s3tables delete-namespaceで削除します。
名前空間の削除をしていないとバケットの削除もできないので注意してください。

aws s3tables list-namespaceで何も表示されなくなればOKです。
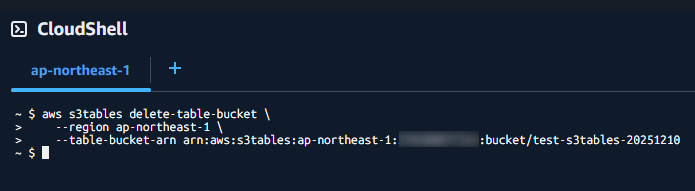
では、最後にバケット自体を削除します。
aws s3tables delete-table-bucketで削除できます。
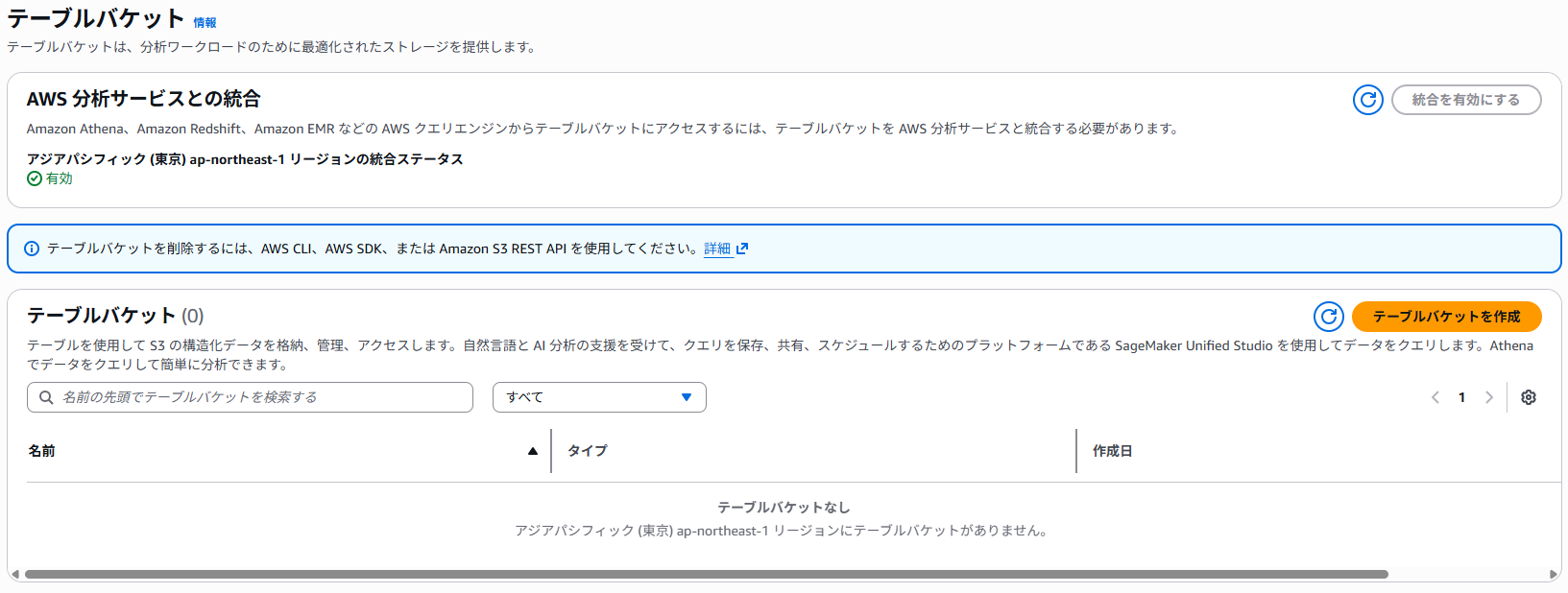
コンソール画面からもバケットが削除されました。
これで一通りの検証は完了です。
おわりに
今回はS3 Tablesの構築をして、利用するところまでを試しました。
厳密にいうとコンパクションなど紹介していない機能もあるので、どこかのタイミングでご紹介できたらと思います。
なお、本記事で紹介したS3 TablesはRDBやDWHを完全に置き換えるものではありませんのでご注意ください。(特性や利用できる機能などが異なる)
本記事がS3 Tablesの導入を検討している方の参考になれば幸いです。