はじめに
「データベース製品紹介」シリーズへようこそ!第1回のClickHouse編では、その圧倒的な分析速度をご紹介しました。
シリーズ第2弾となる今回は、同じくオープンソースのOLAPデータベースでありながら、全く異なる強みを持つ「Apache Doris」を深掘りします。Dorisは、リアルタイム分析基盤でありながら、ビジネスデータとの同期に不可欠なデータ更新(UPSERT)を極めて得意とするデータベースです。
対象読者
- リアルタイムダッシュボードを構築したい方
- RDBのデータを分析基盤へ高速に同期・反映させたい方
- 複雑なETL処理やLambdaアーキテクチャをシンプルにしたいと考えている方
- ClickHouseやBigQuery以外のOLAP DBの選択肢を探している方
この記事を読めば、Dorisのアーキテクチャから、その強力なデータモデル、そして高性能なデータ取り込みの仕組みまでを体系的に理解できます。
Apache Dorisとは?
Apache Dorisは、元々Baidu社で開発され、現在はApache財団のトップレベルプロジェクトとなっている、MPP(超並列処理)アーキテクチャに基づいたリアルタイム分析データベースです。
MySQLプロトコルと互換性があり、既存のツールやBI製品から接続しやすいのが特徴です。また、アーキテクチャがシンプルで運用しやすく、リアルタイムのデータ取り込みからアドホックなクエリまで、幅広い分析要件に単一のシステムで応えることを目指しています。
主な特徴
| 特徴 | 説明 |
|---|---|
| シンプルなMPPアーキテクチャ | FE(Frontend)とBE(Backend)という2種類のプロセスのみで構成され、デプロイやスケールアウトが容易です。 |
| リアルタイムなデータ取り込み | 数秒から数分という低遅延でデータを可視化できます。特にストリーミング取り込みに強みを持ちます。 |
| 柔軟なデータモデル | 用途に応じて4つの異なるデータモデルを選択でき、特にデータ更新(UPSERT)を効率的に処理できます。 |
| MySQL互換 | 標準的なMySQLクライアントやBIツールから直接接続し、SQLで操作できます。学習コストが低いのも魅力です。 |
| ベクトル化実行エンジン | ClickHouse同様、クエリ実行エンジンはベクトル化されており、集計クエリを高速に処理します。 |
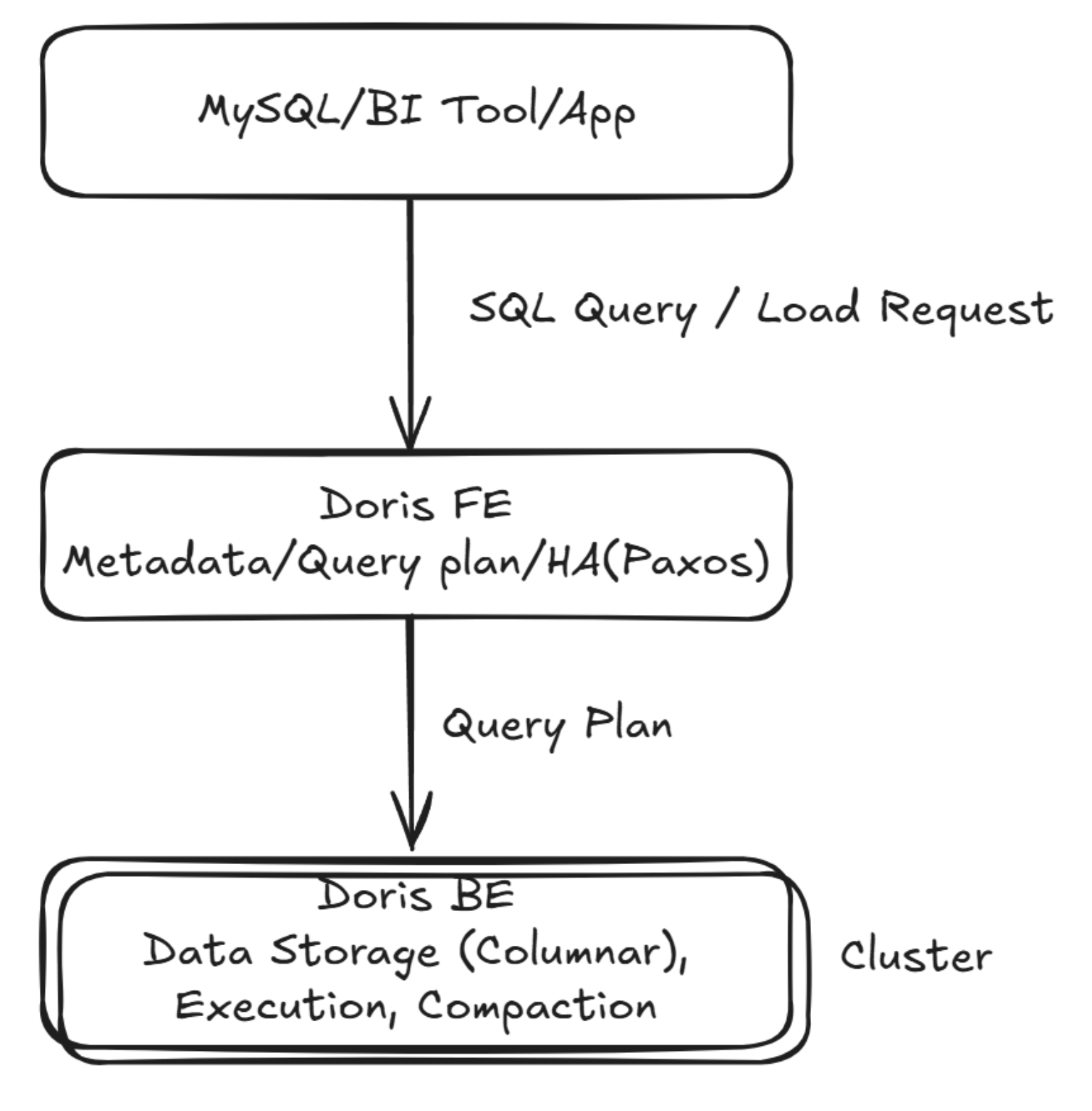
Dorisのアーキテクチャ:FEとBEの役割
Dorisのアーキテクチャは非常にシンプルです。システムの頭脳であるFEと、実作業を担うBEの2つのコンポーネントだけで構成されています。
-
Frontend (FE): メタデータの管理とクエリ計画
- 役割: いわば「司令塔」。テーブル定義などのメタデータを管理し、受け取ったSQLを解析して最適な実行計画を作成します。クライアントからの接続もFEが受け付けます。
- 可用性: 複数台でクラスタを組み、Paxosプロトコルを使ってメタデータを同期することで、単一障害点になるのを防ぎます。
-
Backend (BE): データ格納とクエリ実行
- 役割: いわば「働き手」。FEが作成した実行計画に基づき、実際にデータをスキャン・計算します。データはBEのストレージに列指向形式で分散して保存されます。
- スケーラビリティ: データの量やクエリの負荷が増えたら、BEノードを追加するだけで、システム全体の性能をリニアにスケールアウトできます。
このシンプルな構成により、Hadoopエコシステムのような複雑な外部コンポーネントへの依存がなく、運用管理が非常に容易になっています。
Dorisの強み:テーブル設計の勘所と4つのデータモデル
Dorisの性能を最大限に引き出すには、テーブル作成時の設計が非常に重要です。Dorisのデータ管理は、パーティション(Partition) と バケット(Bucket) という2層構造で行われます。
まずこの基本概念を理解し、その上で4つのデータモデルを見ていきましょう。
テーブル設計の基本:パーティションとバケット(Partition & Bucket)
1. パーティション (Partition) - 第1層のデータ分割
-
概念: テーブルのデータを、主に**時間軸(日付や月)**に基づいて大きな単位で分割・管理する仕組みです。
PARTITION BY RANGE句を使って、どの列を基準に、どのような範囲で分割するかを定義します。 -
目的:
-
パフォーマンス向上: クエリに時間範囲の条件(例:
WHERE event_time >= '2025-09-01' AND event_time < '2025-09-02')が含まれている場合、Dorisは関係のないパーティションをスキャン対象から完全に除外します。これをパーティションプルーニング (Partition Pruning) と呼び、大量のデータの中から必要なデータだけを効率的に読み出すための最も重要な仕組みです。 -
データライフサイクル管理の効率化: 古いデータを削除したい場合、
DELETE文で一行ずつ消すのではなく、古いパーティションをごと削除(DROP PARTITION)できます。これはメタデータ操作であるため、一瞬で完了し、システムに負荷をかけません。
-
2. バケット (Bucket) - 第2層のデータ分割
-
概念: 各パーティション内のデータを、さらに小さな単位である「バケット」に分割します。
DISTRIBUTED BY HASH(...)句を使って、どの列のハッシュ値を基準にバケットへ振り分けるかを定義します。 -
目的:
-
データの分散: データを各BEノードに均等に分散させることが主な目的です。これにより、クエリ実行時に複数のBEノードが並列で処理を行うMPPアーキテクチャの利点を最大限に活かすことができます。
-
データスキューの防止: 適切なキーで分散させることで、特定のノードにデータが偏る「データスキュー」を防ぎ、安定したパフォーマンスを維持します。
-
要約: 「パーティション」でスキャン範囲を絞り込み、「バケット」で処理を並列化する、とイメージすると分かりやすいでしょう。
パーティションの具体的な操作インスタンス
ここでは、access_logsテーブルを例に、パーティションの作成から追加、削除までの一連の操作を見てみましょう。
1. パーティションを含むテーブルの作成
2025年9月と10月のデータを格納するパーティションを事前に定義したテーブルを作成します。
SQL
CREATE TABLE access_logs (
event_time DATETIME,
user_id BIGINT,
request_url STRING
)
DUPLICATE KEY(event_time, user_id)
-- event_time列を基準にレンジパーティションを作成
PARTITION BY RANGE(event_time)
(
-- p202509 という名前で、2025-09-01から2025-10-01未満のデータを格納
PARTITION p202509 VALUES LESS THAN ("2025-10-01"),
-- p202510 という名前で、2025-10-01から2025-11-01未満のデータを格納
PARTITION p202510 VALUES LESS THAN ("2025-11-01")
)
DISTRIBUTED BY HASH(user_id) BUCKETS 10; -- user_idのハッシュ値で10個のバケットに分散
2. パーティションの追加
運用が始まると、将来のデータのために新しいパーティションを追加する必要があります。例えば、2025年11月用のパーティションを追加します。
SQL
ALTER TABLE access_logs
ADD PARTITION p202511 VALUES LESS THAN ("2025-12-01");
この操作は簡単で、サービスを止めることなくオンラインで実行できます。多くのシステムでは、このようなコマンドを定期的に実行するスクリプトを組んで、パーティションを自動で追加していきます。
3. パーティションの確認
現在どのようなパーティションが存在するかを確認します。
SQL
SHOW PARTITIONS FROM access_logs;
実行すると、以下のような結果が返ってきます。
+-------------+------------+----------------------+
| PartitionId | PartitionName | State | ...
+-------------+------------+----------------------+
| 10004 | p202509 | NORMAL |
| 10006 | p202510 | NORMAL |
| 10008 | p202511 | NORMAL |
+-------------+------------+----------------------+
4. パーティションの削除
データの保持期間ポリシーに基づき、古いパーティション(例: 2025年9月分)を削除します。
SQL
ALTER TABLE access_logs
DROP PARTITION p202509;
このコマンドは即座に完了し、p202509パーティションに属していたデータが全てクリーンナップされます。
データモデル
1. Aggregate Key モデル
-
概要: 事前集計モデル。主キー(
AGGREGATE KEYで指定)が同じ行が投入されると、指標となる列(メトリクス)を自動的に集計します。 - ユースケース: サイトのPV数、サービスの売上集計など、集計済みの指標を分析するダッシュボードに最適です。ストレージ容量を大幅に節約できます。
-
仕組み: データ書き込み後のバックグラウンド処理(Compaction)のタイミングで、キーが同じ行が集計関数(
SUM,MAX,MIN,REPLACEなど)に基づいてマージされます。 -
例:
CREATE TABLE site_metrics ( report_date DATE, site_id INT, pv BIGINT SUM -- pv列は自動的にSUMで集計される ) AGGREGATE KEY(report_date, site_id) DISTRIBUTED BY HASH(site_id);
2. Duplicate Key モデル
- 概要: 生データ(明細データ)をそのまま格納するモデル。
- ユースケース: ログ分析やイベントストリームなど、集計を行わず全てのレコードを保持したい場合に利用します。
-
仕組み:
DUPLICATE KEYで指定されたキーは、ソート順の指定にのみ使われ、データの重複排除や集計は一切行われません。 -
例:
CREATE TABLE access_logs ( event_time DATETIME, user_id BIGINT, request_url STRING ) DUPLICATE KEY(event_time, user_id) DISTRIBUTED BY HASH(user_id);
3. Unique Key モデル (Merge-on-Write)
-
概要: 主キー(
UNIQUE KEYで指定)の重複を許さず、常に最新の行だけを保持するモデル。事実上のUPSERT機能を提供します。 - ユースケース: MySQLなどのOLTPデータベースからCDC(Change Data Capture)で連携される商品マスタやユーザーマスタの同期に絶大な威力を発揮します。
-
仕組み (Merge-on-Write):
- 従来の多くの分析DBが採用していた
Merge-on-Read(クエリ時に古いデータと新しいデータをマージして最新版を返す)方式とは異なり、Dorisは**Merge-on-Write**というアプローチを採用しています。 - これは、データ書き込み後のバックグラウンドCompaction処理の段階で、同じ主キーを持つ行を新しい行で完全に上書きしてしまう方式です。
- このおかげで、クエリ(Read)時にはマージ処理が不要になり、主キーでの絞り込みや集計が非常に高速になります。
- 従来の多くの分析DBが採用していた
-
例:
CREATE TABLE user_profile ( user_id BIGINT, user_name STRING, city STRING, last_updated DATETIME ) UNIQUE KEY(user_id) -- user_idが同じ行は上書きされる DISTRIBUTED BY HASH(user_id);
高性能なストリーミングデータ取り込み:Stream Load
Dorisは様々なデータ取り込み方法をサポートしていますが、特にビッグデータ场景下で強力なのがStream Loadです。
これは、HTTPプロトコルを使って、クライアントから直接FEまたはBEにデータをストリーミングで書き込む方法です。
Stream Loadの高性能な特性
-
HTTPベースでシンプル:
curlコマンドや各種プログラミング言語のHTTPクライアントから簡単に利用できます。特別なSDKは不要です。 - マイクロバッチ処理: 数万〜数十万行単位の小さなバッチでデータを継続的に送信することに最適化されており、リアルタイム性とスループットを両立します。
- サーバー側でのリソース消費が少ない: データは直接BEのメモリに書き込まれ、処理された後にディスクに永続化されます。ディスクへのステージングファイル作成などが不要なため、効率的です。
- CSVやJSONをサポート: 大規模なデータ転送では、軽量なCSV形式がよく利用されます。
CSVファイルを使ったStream Loadの実行例
例えば、以下のようなuser_actions.csvファイルがあるとします。
1001,2025-09-12 10:00:00,login
1002,2025-09-12 10:01:00,view_item
1001,2025-09-12 10:02:00,add_to_cart
このCSVファイルを、curlコマンドを使ってmy_dbデータベースのuser_actionsテーブルに書き込む例は以下のようになります。
Bash
curl --location-trusted -u user:password \
-H "label:load_job_1" \
-H "column_separator:," \
-T user_actions.csv \
http://<FE_or_BE_HOST>:<HTTP_PORT>/api/my_db/user_actions/_stream_load
-
-u user:password: Dorisのユーザー名とパスワード -
-H "label:...": 各ロードジョブを識別するための一意のラベル。Dorisはこれを使って重複ロードを防ぎます。 -
-H "column_separator:,": CSVの区切り文字を指定します。 -
-T user_actions.csv: 送信するデータファイルを指定します。 -
http://.../_stream_load: Stream LoadのエンドポイントURLです。
このシンプルな仕組みにより、ETLツールやFlink/Sparkジョブ、あるいは単純なスクリプトからでも、毎秒数十万行といった非常に高いスループットでDorisにデータを送り込み続けることが可能です。
まとめ
今回は、リアルタイム分析とデータ更新の両立を得意とするApache Dorisをご紹介しました。
-
FE/BEから成るシンプルなMPPアーキテクチャで、運用とスケールが容易。
-
Aggregate/Duplicate/Uniqueという強力なデータモデルを使い分けることで、多様な分析要件に対応可能。
-
特にUnique Keyモデルの
Merge-on-Writeは、RDBからのデータ同期を劇的に効率化する。 -
HTTPベースのStream Loadにより、リアルタイムでの高性能なデータ取り込みを実現できる。
純粋な集計クエリの速度ではClickHouseに軍配が上がる場面もありますが、ビジネスデータの変更をリアルタイムに分析基盤に反映させたい、あるいは複数の分析システムをDoris一つに統合したいといったニーズがある場合、Dorisは非常に有力な選択肢となるでしょう。
次回予告
「データベース製品紹介」シリーズ、第3回はVertica。お楽しみに!
この記事が役に立った、続きが気になるという方は、ぜひいいねとフォローをよろしくお願いします!