はじめに
[ pires/kubernetes-elasticsearch-cluster - Github ] を参考にelasticsearchクラスタを立てます。
Kubernetesを使用して拡張性を高く(スケールしやすい等)、
冗長化とx-pack無しのBasic認証導入とデータの永続化までやります。
デフォルトの設定を加えるためGCPのelasticsearchイメージに設定ファイルやプラグインのインストールコマンド、環境変数を加えたものを使用します。
動作確認
- Docker CE for Mac(Edge): Version 18.02.0
- Kubectl: Version 1.8
- elasticsearch: Version 5.6
現時点(2018年2月)ではkubernetesを使うためDocker for Mac edge版を使います。
インストールしていない場合はDocker for Mac with Kubernetes - Qiita等を参考に
elasticsearchのノードの概要
- client
Master (eligible) node でも data node でもないノード
各種リクエストを受けるだけのロードバランサー的な何か- data
シャードを保管するノード
データにまつわる操作 (CRUD, search, etc...) を扱う- master (eligible)
Master node はクラスタ全体の処理(シャードの配置等)を行うノード
Master eligible node は master に候補になるノード
Master node が死んだときには master eligible node から新たな master が選ばれる
この3つの役割ごとにpodを分けて作成します。
イメージの準備
設定ファイルの用意
elasticsearchの設定ファイル等を用意します。
$ mkdir elasticsearch_k8s
$ cd elasticsearch_k8s
$ mkdir config; cd $_
作成したconfigディレクトリの中にelasticsearch.ymlとlog4j2.propertiesファイルを作成します。
http.host: 0.0.0.0
transport.host: 0.0.0.0
cluster:
name: elasticsearch
node:
master: ${NODE_MASTER}
name: ${NODE_NAME}
data: ${NODE_DATA}
ingest: ${NODE_INGEST}
max_local_storage_nodes: ${MAX_LOCAL_STORAGE_NODES}
network.host: ${NETWORK_HOST}
bootstrap:
memory_lock: false
discovery:
zen:
ping.unicast.hosts: ${DISCOVERY_SERVICE}
minimum_master_nodes: ${NUMBER_OF_MASTERS}
ノードの名前などはクラスタの中で一意である必要がありますが、ここで環境変数を使って設定することで全てのノードで同じファイルを使うことができます。
status = error
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = [%d{ISO8601}][%-5p][%-25c{1.}] %marker%m%n
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
ログに関する設定で、これはGCPのイメージと同じです。
$ tree
config
├── elasticsearch.yml
└── log4j2.propertie
configディレクトリのなかにこの2ファイルが無いとelasticsearchは動きませんでした…。
今回はビルドの中に入れてしまいましたが、開発時などこまめに変更して挙動を確認したい場合はKubernetesのconfigMapとして付けてしまうのも良いかもしれません。というかそちらのほうが正しいのかもしれません?
Dockerイメージ作成
元々はGKEで立てていたため、GCPのランチャーからElasticsearch 5のイメージを使用しています。
FROM launcher.gcr.io/google/elasticsearch5:5.6
MAINTAINER cmmmli
RUN yes | bin/elasticsearch-plugin install analysis-kuromoji
RUN yes | bin/elasticsearch-plugin install analysis-icu
RUN yes | bin/elasticsearch-plugin install org.codelibs:elasticsearch-analysis-kuromoji-neologd:5.6.1
ADD config /usr/share/elasticsearch/config/
ENV ES_JAVA_OPTS "-Xms256m -Xmx256m"
ENV CLUSTER_NAME elasticsearch
ENV NODE_MASTER true
ENV NODE_DATA true
ENV NODE_INGEST true
ENV HTTP_ENABLE true
ENV NETWORK_HOST _site_
ENV HTTP_CORS_ENABLE true
ENV HTTP_CORS_ALLOW_ORIGIN *
ENV NUMBER_OF_MASTERS 1
ENV MAX_LOCAL_STORAGE_NODES 1
ENV SHARD_ALLOCATION_AWARENESS ""
ENV SHARD_ALLOCATION_AWARENESS_ATTR ""
ENV MEMORY_LOCK false
ENV DISCOVERY_SERVICE elasticsearch-discovery
このDockerfileをconfigディレクトリと同じレベルに置いておきましょう。
プラグイン(kuromojiやneologd)のインストールとelasticsearchの設定ファイル等を加えて環境変数を設定しているだけです。プラグインは必要なければ消しましょう。
podの環境変数に同じキーを指定すると上書きすることが出来るので、ES_JAVA_OPTSやNUMBER_OF_MASTERSの値はここでは小さくしています。
$ docker build -t elasticsearch:local .
$ docker images
=> REPOSITORY TAG IMAGE ID CREATED SIZE
elasticsearch local 463f4c837920 2 hours ago 564MB
以上でイメージの作成は完了です!
ローカルでビルドしたイメージをDockerHubやGCRにプッシュせずそのまま使えるのは便利ですね!
Kubernetes
namespace
$ kubectl create namespace elasticsearch
deployment
deploymentはpodのテンプレートとそのレプリカの数を指定して作成することで、podとreplicaSetを自動で作成します。
今回はelasticsearchノードの役割ごとに以下の3種類を作成します。
- master-deployment
- data-deployment
- client-deployment
master-node
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: elasticsearch-master
namespace: elasticsearch
labels:
app: elasticsearch
role: master
spec:
replicas: 1
template:
metadata:
labels:
app: elasticsearch
role: master
spec:
initContainers:
- name: init-sysctl
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
containers:
- image: elasticsearch:local
name: elasticsearch-master
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: "NUMBER_OF_MASTERS"
value: "1"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "false"
- name: NODE_INGEST
value: "false"
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: "storage"
emptyDir:
medium: ""
$ kubectl apply -f deployment-master.yaml
spec.template.metadata.labelsで
- app: elasticsearch
- role: master
を指定しています。この2つのラベルを使うことで、elasticsearchのアプリケーションであることの判断、そのdeploymentが何の役割のものなのかを判断出来ることになります。
initContainers はelasticsearchが要求するvm.max_map_countを満たすために最初に走らせるコンテナです。以下コマンドを叩いています。
$ sysctl -w vm.max_map_count=262144
Virtual memory | Elasticsearch Reference [5.5] | Elastic
containersのelasticsearchの部分で環境変数をいくつか書いています。
NUMBER_OF_MASTERSはelasticsearch.ymlのminimum_master_nodesの部分に使われます。この値はマスター候補のノード数(ここではmaster-deploymentのレプリカ数)をnとすると、
( n/2 ) + 1 が適正値です。
ここで設定した値よりmaster候補のノードが少なくなるとelasticsearchは動かなくなります。
今回は1つしか動かさないので1にしています。
data-node
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: elasticsearch-data
namespace: elasticsearch
labels:
app: elasticsearch
role: data
spec:
replicas: 1
template:
metadata:
labels:
app: elasticsearch
role: data
spec:
initContainers:
- name: init-sysctl
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
containers:
- image: elasticsearch:local
name: elasticsearch-data
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: NODE_MASTER
value: "false"
- name: NODE_DATA
value: "true"
- name: NODE_INGEST
value: "false"
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: "storage"
emptyDir:
medium: ""
環境変数でNODE_DATA: trueにしている以外はmasterと同じです。
client-node
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: elasticsearch-nginx
namespace: elasticsearch
spec:
replicas: 1
template:
metadata:
labels:
app: elasticsearch
role: client
spec:
initContainers:
- name: init-sysctl
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
containers:
- image: launcher.gcr.io/google/nginx1
name: nginx
volumeMounts:
- name: site-conf
mountPath: /etc/nginx/conf.d
- name: site-top-html
mountPath: /usr/share/nginx/html
- name: htpasswd
mountPath: /etc/nginx/htpasswd
- image: elasticsearch:local
name: elasticsearch-client
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: NODE_MASTER
value: "false"
- name: NODE_DATA
value: "false"
- name: "ES_JAVA_OPTS"
value: "-Xms256m -Xmx256m"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: site-conf
configMap:
name: site-conf
- name: site-top-html
configMap:
name: site-top-html
- name: "storage"
emptyDir:
medium: ""
- name: htpasswd
secret:
secretName: htpasswd
clientのdeploymentはこれまでの2つと少し違っていて、
containersでelasticsearchとnginxのimageを指定しているため、このdeploymentによって作成されるpodではelasticsearchとnginxのコンテナが1つずつの計2つ動いています。
そしてnginxのコンテナではconfigMapとsecretを使って設定ファイル等を付けているので、それらを作成します!
apiVersion: v1
kind: ConfigMap
metadata:
name: site-conf
namespace: elasticsearch
data:
site.conf: |
server_tokens off;
server {
listen 80;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
location /search/ {
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/htpasswd/.htpasswd;
proxy_pass http://localhost:9200/;
}
}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: site-top-html
namespace: elasticsearch
data:
index.html: |
<!DOCTYPE html>
<html>
<head>
<title>elasticsearch</title>
<style>
body {
width: 35em;
margin: 0 auto;
}
</style>
</head>
<body>
<h1>HealthCheck OK!</h1>
<p>elasticsearch is <a href="/search">here</a></p>
</body>
</html>
$ kubectl apply -f configmap.yaml
.htpasswdファイルを作成して、それを基にsecretを作ります。
.htpasswdファイルの作り方はこちらを参考にしました。
$ kubectl create secret generic htpasswd -n elasticsearch --from-file=.htpasswd
nginxコンテナはGCPランチャーのイメージを使っています。
このコンテナでは、volumeMounts でnginxの設定ファイルが入ったディレクトリとリダイレクト前のトップページのhtmlを読み込んでいます。このディレクトリとhtmlはconfigMapで作成したものです。
そもそもnginxを受け手として付けた理由ですが、今回はelasticsearchのプラグインであるx-packを入れていません。
そのため公開したelasticsearchにはどこからでもアクセスして編集可能な状態になってしまうため、一応認証としてbasic認証を付けています。
elasticsearchコンテナでもstorageをemptyDirのvolumeとしてマウントしています。
これによって、podがリスタートしてもデータを保持出来ます(再生成はダメ)。
clientのpodではserviceからnginxコンテナでリクエストを受け取り、basic認証を通ったものを同podのelasticsearchコンテナにリダイレクトしています。
service
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: elasticsearch
labels:
app: elasticsearch
role: client
spec:
type: LoadBalancer
selector:
app: elasticsearch
role: client
ports:
- protocol: TCP
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: elasticsearch
labels:
component: elasticsearch
role: master
spec:
type: NodePort
selector:
app: elasticsearch
role: master
ports:
- name: transport
port: 9300
protocol: TCP
外部からnginxのコンテナまで繋ぐためのサービスと、
elasticsearchが内部で通信に使うサービスを作成しています。
docker-for-macではtype: LoadBalancerとすることでブラウザからlocalhostで繋がるみたいです。
Docker for Mac にKubernetesがやって来た!(ちょっと追記)
これまで作成した以下のファイルを作成すると、http://localhost:80 にアクセス出来ます!
- deployment-master.yaml
- deployment-data.yaml
- deployment-client.yaml
- configmap.yaml
- services.yaml
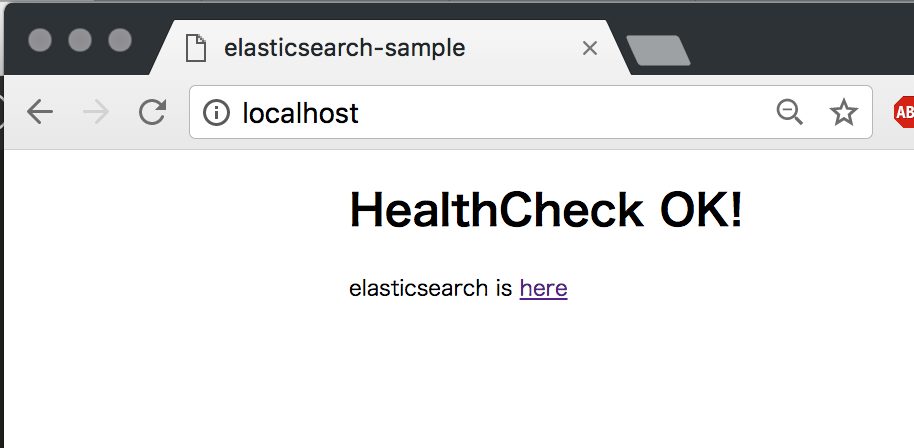
elasticsearchにアクセスするにはhttp://localhost/search です。
basic認証としてユーザ名とパスワードを求められます。
user: elastic
pass: changeme
このパスワードなどはnginxコンテナにつけているconfigMapの.htpasswdを変更することで変更できます。
$ kubectl get pod -n elasticsearch
NAME READY STATUS RESTARTS AGE
elasticsearch-data-db656cf4c-zpbc4 1/1 Running 0 3h
elasticsearch-master-f94b866f4-kjzlf 1/1 Running 0 2h
elasticsearch-nginx-c76c7cc6b-twrrl 2/2 Running 0 2h
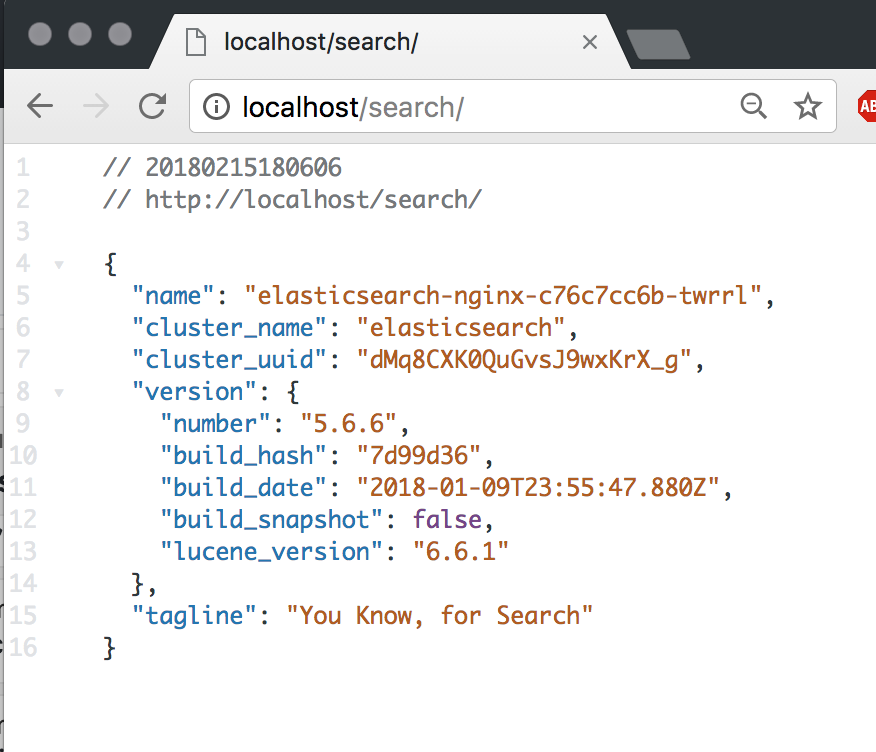
$ curl -L http://localhost:80/search/_cat/nodes -u 'elastic:changeme'
10.1.0.9 27 97 12 0.79 0.65 0.67 d - elasticsearch-data-db656cf4c-zpbc4
10.1.0.11 49 97 12 0.79 0.65 0.67 i - elasticsearch-nginx-c76c7cc6b-twrrl
10.1.0.12 30 97 12 0.79 0.65 0.67 m * elasticsearch-master-f94b866f4-kjzlf
data, ingest, masterそれぞれのノードが動いていることが確認できます。
$ curl -L 'http://localhost:80/search/_cluster/health?pretty' -u 'elastic:changeme'
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 3,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
良さそうですね。
冗長化はそれぞれのdeploymentのレプリカ(spec.replicas)を増やせば出来ます!
データの永続化
statefulSet
ここまででelasticsearchは動きましたが、データの永続化が出来ていません。
imageの変更などでdeploymentをapplyし直すとデータが飛んでしまう状態です。
これを解決するためにdeploymentではなくstatefulSetを使ってみようと思います。
statefulSetはdeploymentで作成されるpodに一意性と状態を持たせることが出来るようにしたものです。
podの名前が ***-0 のようになり順番に作成されます。
podはvolumeClaimTemplatesによってpvcを作り、そのpvcがpersistentVolumeを作る事によってデータの永続化が出来ています。storage-classを定義して適用すれば様々なストレージを使うことが出来ます。
deploymentではdata, master, clientとそれぞれの役割ごとに作成しましたが、statefulSetでは全部入りのpodを作成しようと思います。
必要なクラスタが小規模であれば全部入りを数台構成で運用可能であるため、それに対応するためです。
statefulSetを作成する前に先程作ったdeploymentを消してしまいます。
$ kubectl delete deployment -n elasticsearch --all
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: elasticsearch-full-sample
namespace: elasticsearch
labels:
app: elasticsearch
spec:
replicas: 1
serviceName: elasticsearch-discovery
updateStrategy:
type: RollingUpdate
rollingUpdate:
podManagementPolicy: Parallel
template:
metadata:
labels:
app: elasticsearch
spec:
initContainers:
- name: init-sysctl
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
containers:
- image: launcher.gcr.io/google/nginx1
name: nginx
volumeMounts:
- name: site-conf
mountPath: /etc/nginx/conf.d
- name: site-top-html
mountPath: /usr/share/nginx/html
- name: htpasswd
mountPath: /etc/nginx/htpasswd
- image: elasticsearch:local
name: elasticsearch-full
env:
- name: NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: "NUMBER_OF_MASTERS"
value: "1"
- name: NODE_MASTER
value: "true"
- name: NODE_DATA
value: "true"
- name: "ES_JAVA_OPTS"
value: "-Xms1024m -Xmx1024m"
ports:
- containerPort: 9200
name: http
protocol: TCP
- containerPort: 9300
name: transport
protocol: TCP
volumeMounts:
- name: storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: site-conf
configMap:
name: site-conf
- name: site-top-html
configMap:
name: site-top-html
- name: htpasswd
secret:
secretName: htpasswd
volumeClaimTemplates:
- metadata:
name: storage
annotations:
volume.beta.kubernetes.io/storage-class: hostpath
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 5Gi
$ kubectl apply -f statefulSet-full.yaml
$ kubectl get pod,sts -n elasticsearch
NAME READY STATUS RESTARTS AGE
po/elasticsearch-full-sample-0 2/2 Running 0 1m
NAME DESIRED CURRENT AGE
statefulsets/elasticsearch-full-sample 1 1 1m
作成出来ましたがlocalhostにアクセスしてもコンテナまで繋がらないと思います。
これは作成したサービスがroleも見ているためです。そこだけ編集します。
kind: Service
apiVersion: v1
metadata:
name: elasticsearch
namespace: elasticsearch
labels:
app: elasticsearch
spec:
type: LoadBalancer
selector:
app: elasticsearch
ports:
- protocol: TCP
port: 80
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-discovery
namespace: elasticsearch
labels:
component: elasticsearch
spec:
type: NodePort
selector:
app: elasticsearch
ports:
- name: transport
port: 9300
protocol: TCP
$ kubectl apply -f services-full.yaml
service "elasticsearch" configured
service "elasticsearch-discovery" configured
以上で繋がるようになっています。
statefulSetを使うことで、ノードが再起動する等してもデータを永続化することが出来ます。
image更新の際にもデータは引き継がれます。
GKE(Google Kubernetes Engine)で動かすために
基本的にはそのまま動くと思います。バージョンによってapiが違っていたりするので、そこは使用しているバージョンのリファレンスを見ましょう。
GKEでのHTTPS化
https化はまた別の記事にでも書こうかなと思っていますが、
ingressとkube-legoを使ってlet's encryptの証明書を取得することで出来ます。
GKE でサービスを HTTPS と HTTP/2 に対応する(kube-lego 編) - Qiita
更に、helmを使ってhttps化をより簡単にすることが出来ます。
しかしkube-legoは開発終了してしまったみたいなので、引き継がれたcert-managerを使ったほうがいいのかもしれません(試してないです)。
そしてelasticsearchの検索クエリでは、パラメータ付GETが使われているのですが、GCPのロードバランサがそれを弾いてしまうため、POSTで検索クエリを投げるようにする等結構面倒でした。
そしてGCEのingress controllerを使ってingressを作成するとBackend serviceのヘルスチェックが行われます。
ここでやっかいなのはデフォルトではserviceへのアクセスで200を返さなければ、そのサービスは停止しているとみなされingressが機能しません。
livenessProbe等を用いると解決できそうですが、elasticsearch単体でx-packを用いてbasic認証をかけると全てのアクセスで認証が必要になるため、ヘルスチェックが通らずingressを使うことが出来ませんでした。
今回nginxを通したのはそのヘルスチェックへの対応策でもあります。
片付け!
$ kubectl delete -n elasticsearch cm,svc,pv,pvc,sts --all
$ kubectl delete namespace elasticsearch
おわりに
インフラとelasticsearchについてほぼ無知な状態から始まり、なんとか動かすことが出来ました。
elasticsearchのconfigディレクトリをイメージのビルド時に付けているので、辞書の更新時にイメージを更新してapplyする必要があり、その際にダウンタイムが発生してしまっているのでそこをどうにか出来れば良いなと思っています。
加えて、共通部分が多いyamlファイルが複数出来てしまっているので、管理の手間を何とかしたいです。