この投稿では、シーザー暗号について解説いたします。シーザー暗号と聞くとなんだか難しそうですが、実は非常に簡単な考え方の暗号なのです。
シーザー暗号とは
<シーザー暗号の名前の由来>
ローマの紀元前1世紀頃、ジュリアス・シーザー(ユリウス・カエサル)が利用していた暗号といわれています。
シーザー暗号は、平文の各文字をアルファベット順的に特定の量だけシフトしたものを暗号文とする暗号になります。
暗号化前の誰にでも読むことができるデータを平文と呼びます。
一方で、その平文を何らかの手法で暗号化したデータを暗号文と呼びます。
<シーザー暗号の例>
・「a」は右に5文字シフトして「f」に変換する
・「b」は右に3文字シフトして「e」に変換する
・「c」は右に23文字シフトして「z」に変換する
このようにシフトすることでシーザー暗号となります。
・Pythonで実装
今回の平文は「ugviumqakpcbism」です。これだけ見ると訳の分からない文字列ですが、シーザー暗号で暗号化されていることが分かれば、簡単に復号化することができます。では、やってみましょう。
def caesar(strInputText, intKey):
strResult=[]
for char in strInputText:
if(ord(char)+intKey<=ord('z')):
strResult.append(chr(ord(char)+intKey))
else:
strResult.append(chr((ord('a')-1)+(ord(char)+intKey-ord('z'))))
print('key: '+str(intKey)+'>'+''.join(strResult))
for i in range(1,26):
caesar('ugviumqakpcbism',i)
このコードの関数caesarは、シーザー暗号によって暗号化されたものを平文に復号化する関数です。
引数には暗号化された文と、シフトする回数の2つです。for文で繰り返し実行することで、平文を見つけます。アルファベットは全部で26文字ですので、25回繰り返します。
実行結果
key: 1>vhwjvnrblqdcjtn
key: 2>wixkwoscmredkuo
key: 3>xjylxptdnsfelvp
key: 4>ykzmyqueotgfmwq
key: 5>zlanzrvfpuhgnxr
key: 6>amboaswgqvihoys
key: 7>bncpbtxhrwjipzt
key: 8>codqcuyisxkjqau
key: 9>dperdvzjtylkrbv
key: 10>eqfsewakuzmlscw
key: 11>frgtfxblvanmtdx
key: 12>gshugycmwbonuey
key: 13>htivhzdnxcpovfz
key: 14>iujwiaeoydqpwga
key: 15>jvkxjbfpzerqxhb
key: 16>kwlykcgqafsryic
key: 17>lxmzldhrbgtszjd
key: 18>mynameischutake
key: 19>nzobnfjtdivublf
key: 20>oapcogkuejwvcmg
key: 21>pbqdphlvfkxwdnh
key: 22>qcreqimwglyxeoi
key: 23>rdsfrjnxhmzyfpj
key: 24>setgskoyinazgqk
key: 25>tfuhtlpzjobahrl
この25個の実行結果の中で読むことができるのが key:18 の my name is chutake です!
さいごに
古い時代に使われていたシーザー暗号ですが、現代では簡単に破られてしまう暗号です。暗号解読は、はじめは頻度分析や単語パターンなどの、一般的な解読手法を使用します。ですがシーザー暗号は特徴的なアルゴリズムであるため、解読者はすぐに法則性に気づき、解読もしくは推測される可能性が高いです。
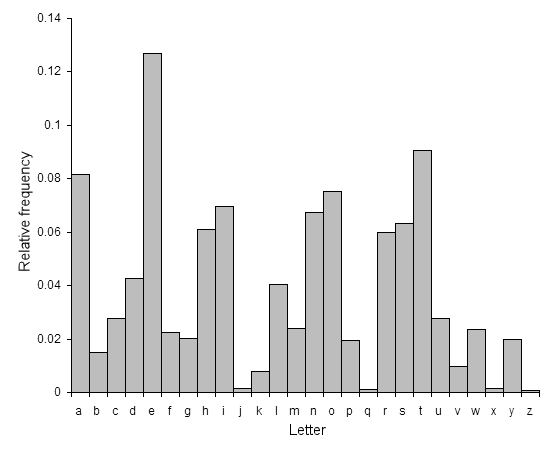
(図:https://ja.wikipedia.org/wiki/%E3%82%B7%E3%83%BC%E3%82%B6%E3%83%BC%E6%9A%97%E5%8F%B7 より)
これは典型的な英語の文章における文字の出現頻度分布図です。英語の平文ではEやTが最も出現頻度が高く、QやZが最も出現頻度が低いといった特徴が図から読み取ることができます。英語の平文をシーザー暗号で暗号化するのは注意が必要ですね!