ブラウザ上で文字を手書きすると字の読みやすさを AI が自動採点してくれる、という web サービスを趣味で個人開発し、 2 週間ほど前にリリースしました![]()

コア技術は、DeepLearning の画像認識と Preact によるフロントエンド実装です。
この記事では、開発したアプリに関して、サービス概要・技術詳細・所感を記載いたします。
サービス概要
機能紹介
ページ数が少なく軽量なため、機能に関してはアプリを見ていただいたほうがおそらく早いのですが、使用した技術の概要も含めた機能紹介をスクリーンショットと共にご説明します。
トップページからの手書き文字採点

- トップページでは文字が書ける枠が表示され、文字を書くことができます。
- HTML5 の Canvas で文字を書けるようにしています。
- 文字を書いて、「採点ボタン」をクリックすると候補が表示されます。
- Canvas に書かれたものを PNG ファイルに画像化し、サーバ上に送信
- サーバ上では受信した画像に対して、機械学習の推論を実行
- 推論結果の、書かれた確率が高いものをクライアントに返信
- 書いた文字を選択すると、採点結果(100点満点)が表示されます。
- 推論結果の確率の値を元に、直感的な点数になるような計算式を適用し点数を算出
- 丁寧で読みやすい字を書いたほうが高得点が出る可能性が高いです。
- 書く線の太さを変えることもできます(線の太さによって採点結果が大いに変わることもあります)
これまで書いた文字の採点実績表示

- これまで書いた文字(採点した文字)の一覧を見ることができます。
- 書いた文字一覧はサーバ上にログとして保管している
- cookie をキーに書いた文字一覧を取得
- 別の端末・ブラウザを使用した場合や、シークレットブラウザを使っている場合は、cookie が変わるため書いた文字の履歴は残りません
- 他のユーザには書いた文字自体・書いた文字の一覧は一切見えないようになっています。
高得点の例の表示

- なかなか高い得点がだせない場合、どういう文字を書くと高得点が出るのかという例を表示することができます。
- 実際にサーバ上で実行される推論処理によって高得点が出る例を、学習データ、テストデータから抽出し、推論された際の点数と共に画像を表示しています。
開発の背景・目的
今回の開発の目的は 2 つあります。
- 手書き文字を採点してくれるアプリがあったら楽しそう
- DeepLearning を応用した Web アプリケーションを作りたかった
開発してみた結果としては、とりあえずどっちも満たしたので満足です。
今回開発したものと同等の機能を提供しているようなサービスは現時点ではまだ存在しないのでは…と思っています。(いや、そこまで他のサービスのことは調査していません…)
こだわりポイント
軽快な動作
基本的にスマホやタブレットで使用されることを前提としているため、初期表示などをサクサクと動くように頑張りました。
具体的には、なるべくフロントエンドのファイル群が軽量になるようにする等の対応をしています。
採点可能文字の種類数の担保
採点対象は、日本語において多く用いられる、ひらがな・カタカナ・漢字・ローマ字・数字の合計 3175 文字で、日本で日常的に使われている文字をほぼ網羅するようにしました1。
数字だけであれば MNIST のデータセットを使えれば容易に用意できるし、英数字だけでも様々なデータセットがありますが、ひらがな・カタカナ・漢字を含んだ上で英数字も混ぜ合わせ、さらに英数字の大文字/小文字も含めたデータセットは若干作るのが面倒でした。
技術詳細
アーキテクチャ概要
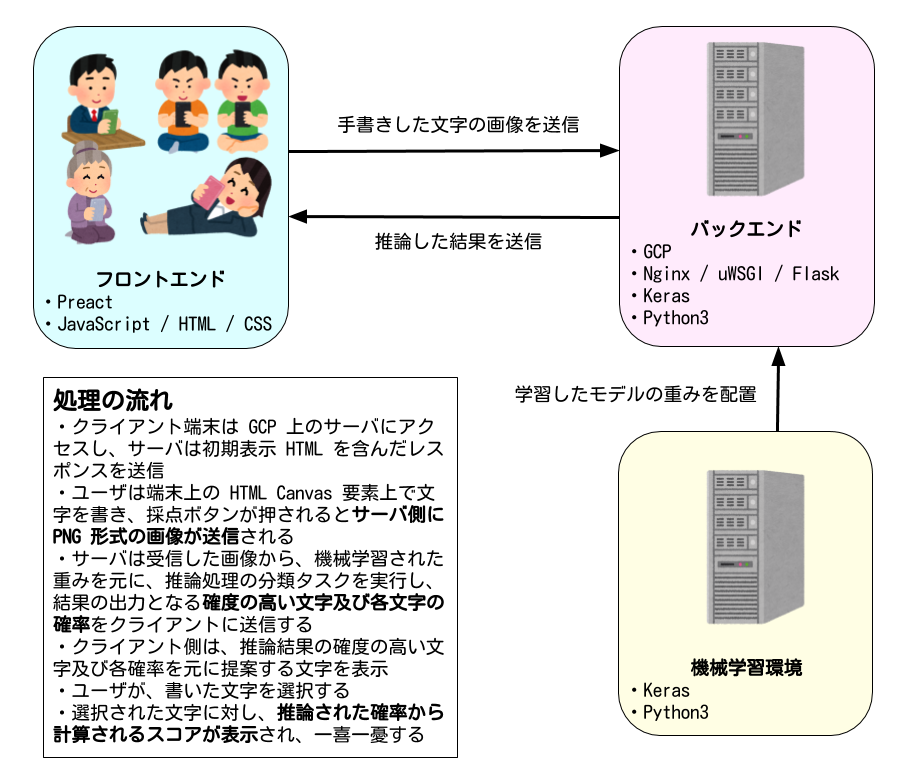
使用した技術・言語・ツール
フロントエンド
- Preact
- JavaScript / HTML / CSS
Preact は React の軽量版みたいなフレームワークです。React の主要な API をほぼそのまま使用できつつ、めちゃくちゃ軽量に実装されています2。
僕は React を使い倒しているというほどでもないので Preact で困ることは全くありませんでした3。
バックエンド
- Nginx
- uWSGI
- Flask
- Python3
機械学習部分は Python3 + Keras を使用しているため、リアルタイムで推論処理を実行する必要のあるバックエンドは親和性と利便性から Python を選定しています。
Flask は単純に軽快で使いやすいという理由で選定していますが、Python 上のアプリケーションサーバでも非同期処理を行いたいことがあるので、FastAPI へのリプレースも考えています。
Nginx, uWSGI の選定理由は特にありませんが、基本的に Flask のようなアプリケーションサーバは、本番環境の Web のフロントエンドの動作には最適化されていないため、それらの用途に最適なものかつ Flask と親和性が高いものを使用しているというだけです。
機械学習部分
- Keras
- Python3
学習・推論ともにディープラーニングフレームワークの Keras を使用しています。
実行環境などのインフラ
- Google Cloud Platform (GCP)
- Google Domains
- Docker
全般的に GCP を使っています(GCP 以外のクラウドサービスは使用していません)。
バックエンドのサーバは Google Compute Engine、画像ファイルなどの保存場所は Google Cloud Storage、ロードバランサーとして Google Cloud Load Balancing を使っています。
Google Cloud Load Balancing は、基本的な使用料だけで月額約 2700 円(2020/03/23 現在)とわりとお高いためかなり悩んだのですが、証明書の管理を自動でやってくれたり、万が一アクセスが多くなった場合にインスタンスを増やせる安心感が大きかったため、いったん使ってみることにしています。
デプロイは Docker コンテナをリリース単位として、下記の流れで実行します。
- 開発環境でフロントエンドをビルド
- ビルド済み・実行可能なコードを含んだコンテナイメージを作成
- 作成したコンテナイメージを、プライベートのコンテナレジストリにプッシュ
- プッシュしたコンテナイメージをベースにし、インスタンステンプレートを作成
- インスタンステンプレートを元に、インスタンスグループを更新
カタカナが多い…w
学習データに関してはいまのところアップデートは考えていないため、すでに学習済のモデルを使用しています。
その他お世話になったツール・サービスなど
Inkscape
Adobe Illustrator とほぼ同等の機能が提供されているフリーのソフトです。
ロゴやアイコンの作成で用いました。
ファビコン favicon.icoを作ろう!
色々なサイズ・形式に対応した favicon の一括作成の際、とても便利です。
EZGIF.COM - Animated GIF editor and GIF maker
アプリのデモ動画を Twitter に Qiita 上にアップロードしたい際に GIF 化するのに便利なサービスです。
いくつか同様のサービスを試していますが、変換の柔軟性や処理時間などより、個人的にはこのサービスが一番使い勝手がよいと思いました。
Wikitionary
漢字の一覧表を作成するために、学校で習う学年などで分類したかったため、データを収集しました。
読みや総画数・部首などのデータも取得済なのですが、現状それらを使っての表示分類・検索機能は実装していません。
機械学習モデルの学習に使用したデータ
ETL Character Database(ETL CDB)
手書き文字(+少量の印刷文字)画像データのデータセットです。
日本で使われている文字 3200 種類ほどからなるデータセットで、画像データとしては 111万5065枚 あります。
文字の種類はひらがな・カタカナ・漢字・英数字・記号からなりますが、ラテンアルファベット(ローマ字)の小文字は含んでいません。
また、ETLCDB は下記の点から若干扱いづらいデータセットです。
- 各データセットは、モダンな JSON や XML などではなく、固定長の決められたフォーマットを持つバイナリデータ
- 内部的に保持されている文字コードが JIX X 0201 だったり CO-59(六社協定新聞社用文字コード) というナゾイ文字コード
ETLCDB 全データセットの画像を取り出す Python スクリプトを作成して公開しています。データセット上のバイナリデータから生の画像データを取得して、Unicode のコードポイントラベルとして扱えるよう、各コードをディレクトリとして PNG で保存します。
データセットは無料で使用可能ですが、商用使用を目的とする場合は条件についてお問い合わせください と記載がありますので、ご注意ください
The EMNIST Datset
NIST(アメリカ国立標準技術研究所)の提供している手書き文字のデータセットです。
ローマ字の大文字小文字と数字を含む全 62 種の文字に関して 81万4255枚の画像があります。
なお、ディープラーニングのチュートリアルでよく登場する MNIST は、このデータセットのサブセットです。
上述の ETL CDB は多くの文字を含んでいますが、ローマ字の小文字のデータがありません。しかし、英数字全ても採点対象としてどうしても含めたかったため、すべてのローマ字を含んだデータセットを学習データとして追加しました。
ソースコードなど
基本的なソースは GitHub のレポジトリにて公開しています。
ただし、学習済のモデルなどアプリケーションの実行に必要な一部のファイルは GitHub 上には置いていないため、実行環境をそのまま開発環境として再現させることはできません。
所感
アプリで遊んでいて感じたこと
さて、突然関係のない話題ですが、次の文章の意味を解読できるでしょうか。
(※投稿時からちょっとだけ変更しました)
「卜口 卜 力二 力工夕」

※再度表示するので、じっくり見て読んでいただくと分かるかもしれません。
「卜口 卜 力二 力工夕」


すぐに正解が見えないように、無駄な画像を貼り申し訳ございません![]()
そして画像は完全なる引掛けで「とろ と かに かえた」のカタカナ表記だと思われた方は一文字もあっていません…
正解は下記の通りで、実は文章として全く成り立たない文字の羅列に過ぎません。
卜:水卜アナの**「卜」**
口:口内炎、口角の**「口」**
力:力士、チカラの**「力」**
二:二子玉川、二項分布の**「二」**
工:工事中、工場、斎藤工さんの**「工」**
夕:夕方、夕刊、夕食の**「夕」**
(コピペして Google 検索にかけると全て漢字であることが分かります。)
おそらく全ての文字を正しく認識できた方は多くないのではないかと思います。
もしそうだとすると**「ちゃんとした活字ならば、どんな文字でも人間には認識可能で読み分けることができる」というのは真ではない**、ということがわかります4。
例えば「工」という表示に対して読みあげて下さい、と言われた際に、何もヒントがなければ、「工事の『工』かカタカナの「エ」(え)のどちらか」としか答えられないかと思います5。つまり、文字単体での判別はとても難しい場合がある、ということです。
また、本節の冒頭の「次の文章の意味を解読できるでしょうか」が**「次の文字列の各文字はそれぞれ何が書いてあるでしょうか」** という問いであればまた見方がまた違った方も多いと思います。
よく言われることではありますが、機械学習、特に深層学習分野を勉強したり試したりしていると、人間の認識は文脈への依存が多分にあるということを強く感じることが多々あります。今回の文字認識はその代表的な例で、我々は文字を読む時、その字単体の図形のみを認識して判別しているわけではなく、「周辺にはどのような文字が書かれているのか」「どういった単語や形態素の要素となるか」「そこにはどういった単語が書かれていることが自然か」という「文脈と呼べる情報」に大いに依存している、ということが分かります。
今回開発したアプリでは、文脈情報を全く使わずに画像認識をして採点しているため、高得点が出にくい文字が少なからず存在します。その代表例が上記の5文字ですが、その他にも 0 (数字のゼロ)と O (ラテンアルファベットのオー)などのように、文字単体での認識が難しいために高得点が出にくい文字はそれなりの数があります。
機械学習関連の開発では「人間はどうやって認識しているのか」ということを考えつつ取り組むことが多いのですが、それを純粋に掘り下げることはとても興味深く、人間の脳の出来の良さに驚くことがしばしばあります。また「現時点での AI には何が出来て何が出来ないのか」というのも、そういった側面から考えるとヒントのようなものもたくさんあると思います。
なお個人的には、単語のみではない文脈情報も自然言語処理では解析可能なレベルになってきていますし、マルチモーダルの深層学習なども今後数年のうちに大きく発展するのではないかと思いますので、文脈を読んだ上での精度の高い推論も AI には自然にできるようになっていくと考えています。それらの進歩により、いわゆる「気が利く AI」も遠からぬ未来に実現されていくと思っています。
個人開発におけるリリースの難しさ
個人開発において「どこまで作ったらリリースするべきか」という判断は、業務のように契約等で納期が決まっている場合と異なり、とても難しいものです。
業務にせよ趣味にせよ、ソフトウェア開発をがっつりやったことのある方なら分かるかと思いますが、開発途中では、直さなければいけないバグ以外にも、改良点やあった方がいいだろうなと思う機能が無数に出てきます。今回の個人開発でも、追加した機能や改良した方がよい点がいまだにたくさんあります…
そのような中で「どこまでできた時点でリリースするか」というのはとても決めがたいものです。そのような状況で最も大切なのは**「絶対に世に出す」という強い意志**ではないかと思います。
Facebook 社内の標語として使われるらしい "Done is better than perfect" は、**「ソフトウェアが完璧な状態になることなんてない。だからこそスピード感を持って世に出し、少しずつずっと改良し続けていくことが大切だ」**という意図が背景にあるそうです6。
この言葉に代表されるように、リリースの際にはある程度の見切りが必要です。
が、その一方、一度離れたユーザは戻ってくるまでに長い時間がかかるとよく言われますし、品質が低いものを気軽に世に出すというのも、技術者としてのプライドなども邪魔してなかなか難しいものです。
それらを踏まえると結局のところ、個人開発においても リリースは日付を決めてしまう(あらかじめリリース日を決めて、なにがなんでもそこにリリースするようにするようにするのがベストなのではないかと近頃は考えています。(それ以外にもよい方法があるかもしれません…もし知っていたら本当に知りたいので教えていただければと思います…!)
この「リリースタイミングの難しさ」に関しては他にももっと色々考えている・思うこともあるので、そのうち別途ポエムとして記事にまとめたいなーと思っています。
最後に
東京では外出の自粛要請の上に大雪と、家からなかなか出にくい環境のさなかですし、もしよければちょっとだけでも遊んで頂けると幸いです。
まだまだ不完全な点も多々あり機能的にも不十分かもしれませんが、ぜひぜひ楽しんでいただければと思います!
なお最近 Twitter も細々とやり始めていますので、もしよければTwitterアカウントのフォローなどお願いします m(_ _)m