TwinGAN論文まとめ
- 2018年8月にsubmitされた論文で異なるドメイン間の画像変換手法を提案しています。
- arXivはこちら
この記事で説明すること
- モデルのArchitecture
- 損失関数について
- Batch Renormalizationについて
この記事で説明しないこと
- ドメインの詳細な概念
- 関連手法の詳細な説明
ザックリとまとめていきます。サクッと見ていきましょう。
Architecture
まず、入出力について確認していきます。
入力は二つのドメイン(例 人とアニメ)から一枚ずつ画像を入力し、「人ドメイン」の画像から「人ドメイン」と「アニメドメイン」の画像を出力します。同様にして「アニメドメイン」の画像から「人ドメイン」と「アニメドメイン」を出力します。(不要に思われる人→人、アニメ→アニメの出力は損失関数の計算に利用されます。損失関数の段で詳述します。)
TwinGANの大まかなモデル構造は以下のような図になります。
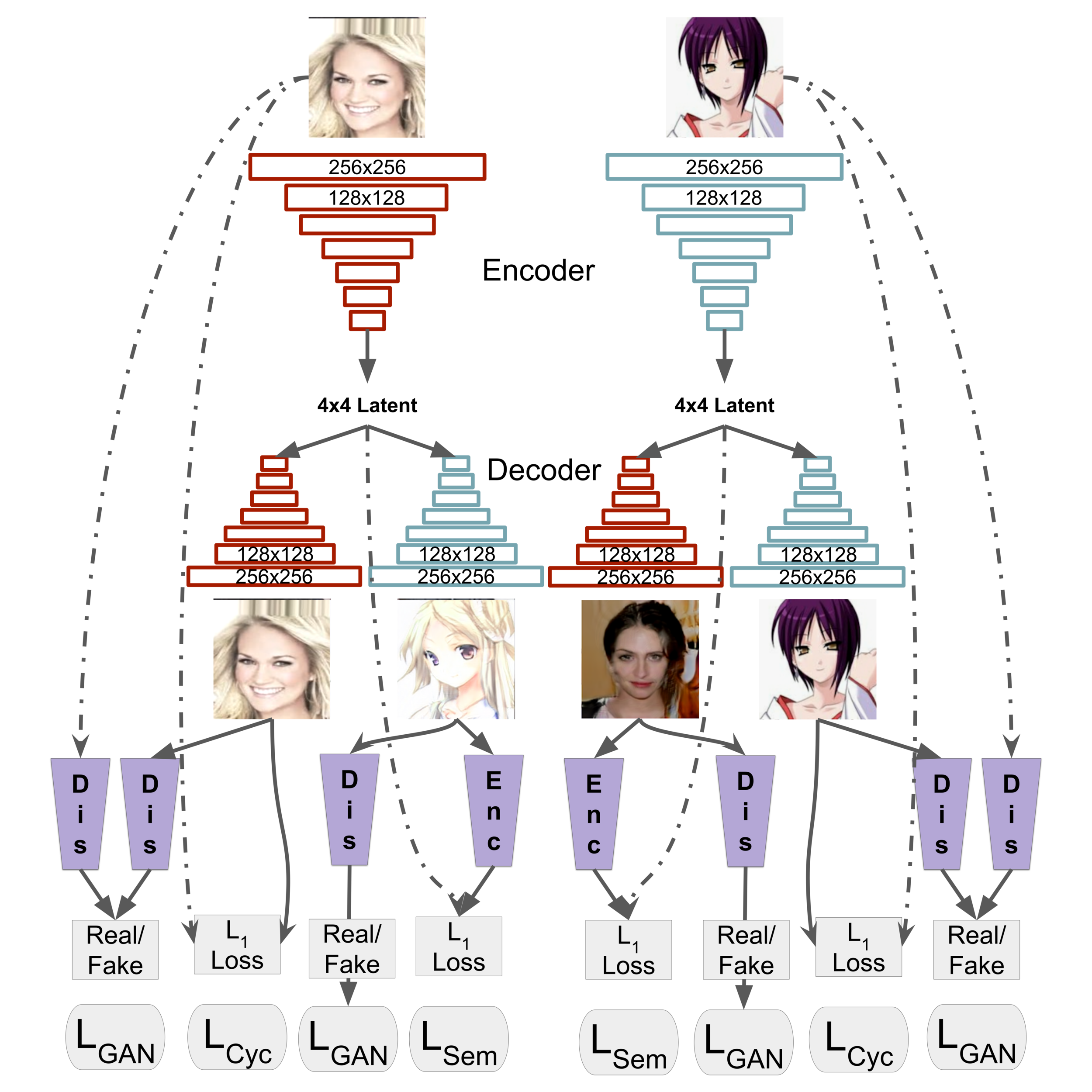
TwinGAN論文著者のGithubより画像を引用しました。結構ややこしいので一つずつ見ていきましょう。
まず、TwinGANはEncoder/Decoderモデルになっています。Encoderで画像の特徴量を抽出し、Decoderで目標とする画像を出力します。このDecoderの出力に対してDiscriminatorが判別をしていくことで敵対的に学習を進めていきます。(つまりEncoder,DecoderがGeneratorを担うような形になっています。)
Encoder/Decoderモデルは PGGAN (Progressive GAN)を元にしたモデル構造になっており、この手法はgrowing stageとreinforcement stageの二段階で学習を行います。
↑
PGGANはGeneratorとDiscriminatorの学習の仕方であり、Encoderは関係ありません。また、「モデル構造」という表現も不適切な気がします。
PGGANは低解像度の学習から進めて、次第に高解像度の処理を重ねていく感じです。(下図参照。PGGAN論文より引用しました。)
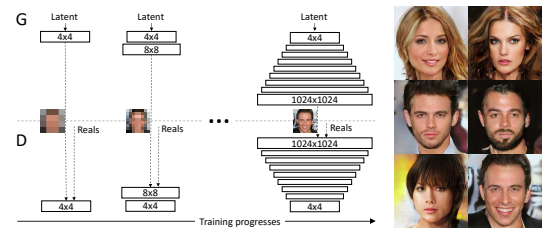
growing stageでは低解像度の画像を高解像度の画像にある割合で注入していくことで、徐々に画像の構造を捉えていくような仕組みになっており、学習がうまくいくことが知られています。(以前の記事で見たモデルでも利用されている考え方です。)
reinforcement stageでは低解像度の学習で使われなかったレイヤが捨てられていきます。(この辺はあんまり理解してないです...)
また、このモデルではU-Netというモデルも参考にしています。
U-NetはGANのダウンサンプリングで情報量が落ちてしまうことに対応するための手法であり、ダウンサンプリング直前のEncoder layerをアップサンプリング直後のlayerにskip connectionで接続します。
そして、この論文で提案されている最も特徴的な点はDomain-adaptive Batch Renormalizationという構造です。(batch renormalizationはbatch normalizationの発展版です。具体的な計算については後述します。)
従来の画像変換手法ではAdaptive instance normalizationが、スタイル画像とターゲット画像を近づける手法として有力とされて来ました。この手法に基づき、本論文では二つの異なるドメイン間のスタイルの違いに対してbatch renormalizationを行います。(それぞれのドメインに対して正規化パラメータを1セットずつ学習させる。人からアニメ画像のスタイル変換なら、「人ドメインの正規化パラメータ」と「アニメドメインの正規化パラメータ」を設定します。)
この手法は、二つのドメインのそれぞれのEncoderが、「異なるスタイル」の「同じsemantic object representation」を学習することを目指します。これは重み共有しているEncoderを使うことで達成されますが、正規化パラメータだけはそれぞれのドメインで持たせることで、ドメイン間のスタイルの違いを捉えるようにしています。(両ドメイン間で必要な、「画像のsemanticな特徴の学習」はEncoderの重み部分に任せ、ドメイン間のスタイルの学習を正規化パラメータに任せるようなイメージ。)
従来の手法ではEncoderの一部分のみを重み共有していましたが、本論文では正規化レイヤ以外の全てのレイヤの重み共有していることが大きな特徴です。また、Decoder部分も同様な構造になっており、従来の手法よりも少ないパラメータでの学習が可能になっています。
以上がモデル構造の大まかな説明になります。ポイントをまとめると以下のようになります。
- PGGAN手法により高解像度の画像生成が可能
- U-Net手法によりダウンサンプリングによる情報の脱落を防ぐ
- 重み共有とbatch renormalizationでsemantic/styleの情報を効率よく学習
では以下では損失関数について説明していきます。
損失関数について
TwinGANでは以下の三つの損失関数を利用しています。
- Adversarial Loss
- Cycle Consistency Loss
- Semantic Consistency Loss
それぞれについて見ていきましょう。
Adversarial Loss
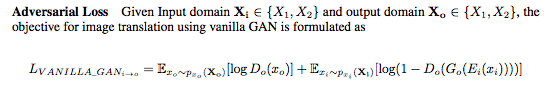
TwinGAN論文より抜粋しました。この損失関数は出力された画像の由来のドメインに対するDiscriminatorの損失になります。
Encoder,Generatorはこの損失の最小化を、Discriminatorは最大化を目指します。
右辺の第1項はターゲットドメイン(人→アニメなら、アニメドメイン)の画像をターゲットドメイン由来と判断する場合を、第2項は元ドメイン(人→アニメなら人ドメイン)から出力された画像に対するDiscriminatorの判断を示しています。これはよくあるGANの「Generator由来か否か」を判断するのとよく似ています。
Cycle Consistency Loss
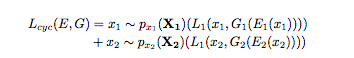
この損失関数は出力画像が入力画像と同様の特徴を捉えることを担保するものです。
右辺の第1項はドメイン1から生成されたドメイン1の画像と、入力のドメイン1の画像とのL1ノルムを計算しており、第2項ではドメイン2に対して同様の計算をしています。
この損失を加えることで、同ドメインでの画像特徴量抽出・生成が学習されていきます。(人→人、またアニメ→アニメの生成が必要なのはこの損失関数で利用するためです。)
Semantic Consistency Loss
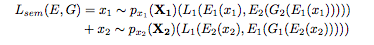
上記で見たCycle Consistency Lossによって、同じドメインでの入出力のsemantic consistencyが保証されています。そこで、次は異なるドメイン間のsemantic consistencyを保証することを目指します。
右辺の第1項は「ドメイン1からのデータ」の「Encoderの出力」と「ドメイン1からのデータ」の「ドメイン1へのEncoderの出力」を利用して生成されるドメイン2画像の「ドメイン2へのEncoderの出力」のL1ノルムを計算しています。
かなりややこしいので、「人ドメイン」をドメイン1、「アニメドメイン」をドメイン2として具体例を見ていきます。
まず、「人ドメインの生データ」から「人ドメインのデータ生成」を考えます。(人→人)
この時に人ドメインデータを入力とするEncoder1の出力は「その画像データ(人)の特徴量」を出力し、これを保持しておきます。(特徴量A)
続いて、その特徴量を利用して「アニメドメイン」のデータを生成します。これは人→アニメ変換そのものです。そして、この生成された画像データに対して「アニメドメインを入力とするEncoder2」に流し込みます。これはつまり「生成されたアニメデータ」を利用して「元の人データ」の復元を試みる際に取り出される特徴量と言えます。(特徴量B)
※オートエンコーダのように実際に復元を試みるわけではありません。
この特徴量Aと特徴量BのL1ノルムが右辺の第1項であり、第2項も同様の計算です。
これを最小化することを目指すことで、人→アニメとアニメ→人の変換の際のEncoderの出力(特徴量抽出)が近くなることが担保されます。
ここで入出力の画像ではなくEmbeddingの損失を考えるのは、異なるドメイン間では厳密に1対1で対応する関係があるとは考えにくく、ピクセルレベルで損失を取ると、チグハグな画像生成がされてしまう可能性があります。
それに対してEmbeddingは両ドメインにまたがるsemantic informationを獲得していることが予想されるので、より有用な学習になります。
以上がモデル構造と損失関数についての説明になります。かなりややこしいですが、モデル構造図と照らし合わせて見ていくとわかりやすいかなと思います。
Batch renormalizationについて
モデル構造のところで出てきたBatch renormalizationについて紹介します。
この手法の特徴は以下のようなものになります。
- batch_sizeが小さい、もしくはデータ間に相関がある場合に有効なバッチ正規化手法
- 学習時と推論時で同じモデルを用いる
具体的な計算は以下の式によって行われます。
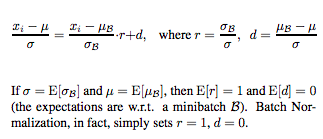
Batch renormalization論文より引用しました。上記の図からもわかるように、Batch renormalizationではバッチ全体の分散と平均の期待値に対して、バッチごとの分散と平均の期待値を計算し、係数として正規化を更に補正します。(Batch normalizationはr=1,d=0を仮定します。これはすなわちデータ全体とバッチは同じ分布から独立に生成されていることを仮定していることになります。)
Batch normalizationでは学習の際はバッチごとの正規化を行いますが、推論時はそれまでの学習全体での分散と平均の移動平均を用いる(バッチごとの正規化を利用すると最後の学習に使ったバッチの影響を強く受けてしまうので)ため、学習時と推論時で異なるモデルを利用することになります。
それに対してBatch renormalizationでは学習時からデータ全体の分散と平均の期待値を推定しながら補正をかけるため、学習時と推論時で使うモデルが同じものになります。
これによりbatch_sizeが小さい、もしくはデータ間に相関がある場合にバッチに極端な偏りが生じていても補正されるようになります。(データ全体とバッチに大きな差がある場合は係数の絶対値が1から離れるので強く補正されます。)
関連論文
Batch renormalizationに関して 2017年発表 Batch Renormalization: Towards Reducing Minibatch Dependence in Batch-Normalized Models
補足・イメージ・教訓
- Batch renormalizationにスタイル部分を、semantic部分を重み共有に分担させるようなイメージ。
- 損失関数をアレンジすることで目的達成を目指した。
- 生成される画像の制御についてはfuture workとしていますが、Style Embeddingを利用することでいくつかの特徴を制御することができるようです。
生成結果
生成された結果は以下のようになります。かなり「それらしい」画像になってる気がします。(海外だとエマ・ワトソンが女優の代表例になるんでしょうか...?)

最後までお読みいただきありがとうございました!
ご質問等あればお気軽にコメントください!