Full-body High-resolution Anime Generation with PSGAN論文まとめ
- 本論文はDeNAさんが発表した論文です。arXivはこちら。
- 2018年の9月にsubmitされたもので、アニメキャラの全身動画(サイズが1024×1024,高品質)の生成に成功しています。
- こちらのDeNAのページで生成された動画(結果)が確認できます。
- PSGANはProgressive Structure-conditional Generative Adversarial Networksの略です。
この記事で説明すること
- 上記論文の特徴
- 関連する論文
この記事で説明しないこと
- GANの仕組み
- 結果・実験の詳細
ザックリとまとめていきます。サクッと見ていきましょう。
本論文の特徴
この論文のもっとも大きな特徴は
「階層的にキャラクターの全身の情報をConditional dataとして注入している」
ということになります。
ちょっとわかりにくいと思いますので、論文内で示されている概念図を見ていきます。
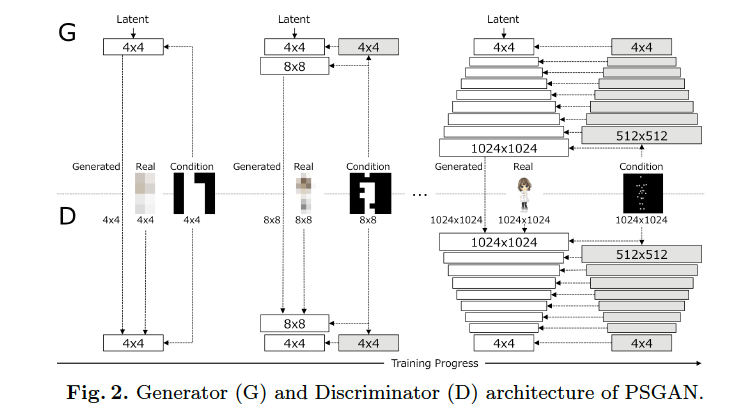
白色の四角は学習パラメータを持つレイヤで、灰色の四角は学習パラメータを持たないレイヤになっています。
この論文のGANの構造自体はよくあるDCGANであり、少しずつ生成する画像のサイズを大きくしています。
その際にモーションキャプチャで撮れるような図を注入することで、アニメキャラクターを「自然な姿勢」で生成することに成功しています。
このモーションキャプチャの情報(論文ではkeypointsと表現されています)はどうやって手に入れるかと言うと、Unity3DだったりOpenposeと言う手法を使うことで取得しています。
関連論文
- keypointsの取得に関して(Openpose) 2016年発表
Realtime multi-person 2d pose estimation using part affinity fields. - モデル構造に関して 2017年発表
Progressive growing of gans for improved quality,and stability,and valiation.
補足・イメージ・教訓
- 「Progressive」と言うのは少しずつ解像度を上げてく、みたいな意味なのかなと思ってます。(※関連論文読んでないのであくまで想像です)
- ConditionalGANの情報の入れ方は色々あるんだなぁと言う感じです。また入れる情報自体もタスクごとに色々と試すのはありなのかなと思います。
- Qiita初投稿記事になります。これから論文まとめをちょくちょく挙げれたらなと思うので、よかったら今後も見ていただけると嬉しいです。
最後までお読みいただきありがとうございました!
間違い等あればご指摘のほどよろしくお願い致します!