Fast Interactive Object Annotation with Curve-GCN
- 2019年の3月にsubmitされた論文です。
- arXivはこちら
概要
- インスタンスセグメンテーションのラベル作りを自動で行う手法です。
- 物体をGraph(vertexとedge)で表現し、GCN(Graph Convolutional Network)で処理します。
- 頂点の結び方は、直線で結ぶPolygonと曲線で結ぶSplineの2通りが可能。
- それぞれPolygonGCN,SplineGCNと呼ばれています。
- アノテーターによる手動の修正も高速でできます。
- 修正を考慮するモデルはInteractiveGCNと呼ばれています。
- 学習のデータセットはCityscapesを利用。
- ドメイン間の汎用性も高い。
ザックリとまとめていきます。サクッと見ていきましょう。
学習の枠組み
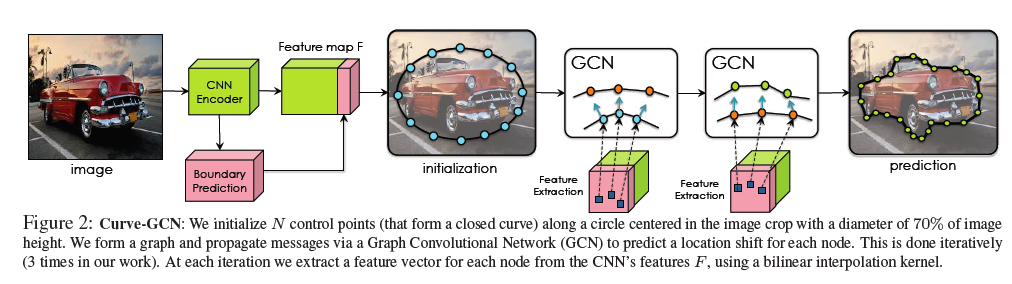
上図は本論文から引用したものです。
Curve-GCNは以下のような処理を行います。
- 画像入力
- 特徴量抽出
- 頂点予測
- 頂点修正
それぞれ順に見ていきましょう。
画像入力
まずはCurve-GCNのパイプラインに画像を入力します。この際に入力される画像は、物体検出のようにバウンディングボックスがインスタンスごとに載っていることが期待されます。
Curve-GCNに入力された画像は、バウンディングボックスでcropされ、その後の処理はそれぞれのバウンディングボックス(それぞれのインスタンス)ごとに進みます。
つまり、Curve-GCNは与えられたバウンディングボックスの数だけ、セグメンテーションを行うように予測します。
したがって、入出力の対応は以下のようになります。
入力:一枚の画像(N個のバウンディングボックス)
出力:N個のインスタンスセグメンテーション結果
特徴量抽出
画像処理系ではおなじみの工程になります。本論文の実験ではベースラインとして利用しているPolygon-rnn++と合わせて、resnet50を利用しています。
モデルが物体の境界を判断するのを助けるために、EncoderからEdge branchとVertex branchに分岐させ、それぞれで28×28のグリッドで、Edge,Vertexが存在するかを予測します。
どちらのbranchも3×3の畳み込み層と全結合層から構成されています。(詳細は記述なし。)
これは28×28のグリッドに対する2値分類の問題になるので、最終的な活性化関数はシグモイド関数・損失はbinary-cross entropyを利用します。
ここで予測された頂点・辺はbilinear interpolation(双一次補間,バイリニア補間)によって補正されます。
bilinear interpolationは画素の補間でよく使われる計算手法で、物体検出等でも利用されます。こちらの記事がわかりやすいです。
頂点予測
この部分がメインの部分であり、Graph Convolutional Networkが利用されています。
このグラフでは以下のような順伝播が行われています。

実際は、既存の手法が利用しているように、Graph-ResNetという残差接続を追加した以下のような計算になります。
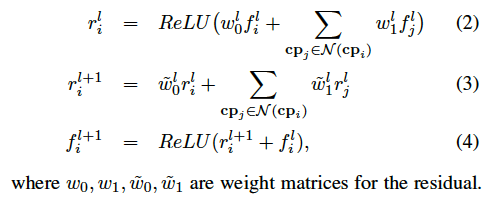
頂点修正
上記の頂点予測で、入力の頂点iの座標(xi,yi)を、(xi+△xi,yi+△yi)とし、これを新しい入力として利用します。
これを繰り返すことで少しずつ修正していき、最終的な予測を出力します。論文内ではこの修正を三回繰り返したモデルを作成したと述べられています。
損失関数
上記で見た処理は以下の二つの損失関数によって学習に利用されます。
- Point Matching Loss
- Differentiable Accuracy Loss
それぞれ以下で見ていきましょう。
Point Matching Loss
これは名前の通り、予測した頂点と正解の頂点のズレを定義する損失関数です。これを最小化することで、各頂点のズレが小さくなり、精度の高いセグメンテーションのラベルが作成されます。
具体的な計算は対応する頂点の組みのL1-ノルムの総和として計算されます。
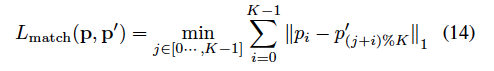
p,p'はそれぞれ正解・予測された頂点の集合を指し、Kはサンプリングされる頂点の数を指しています。
min演算子とKで割った余りによって、「対応する頂点の関係」同士で損失を計算するように工夫されています。(p,p'は時計回り or 反時計回りとして順番も規定されている集合です。)
Differentiable Accuracy Loss
Point Matching Lossのみを最小化すると、過度にスムースな予測になってしまいます。
→これよくわかりませんでした。各頂点の予測は近傍の頂点の計算結果も関係するから、シビアな予測ができない?
より良い予測を達成するには、予測した頂点から生成されるPolygonのマスクと、正解のPolygonから生成されるマスクが一致していることが求められます。
上記のような理由より、予測・正解の頂点の集合から生成されるマスクのL1-ノルムも損失関数に加えます。この損失のことをDifferentiable Accuracy Lossと言います。

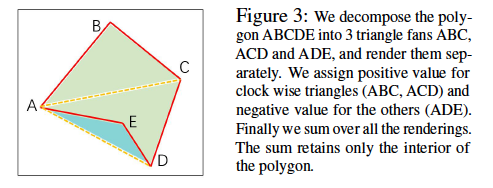
順伝播の計算
多角形のマスクの計算は、正負の面積を仮定した三角形の組み合わせによって行われます。(高校物理の重心の計算の感じです。)
逆伝播の計算
マスクをかける演算は微分できないので、この論文ではテイラーの定理から一次関数として近似して逆伝播を可能にしています。
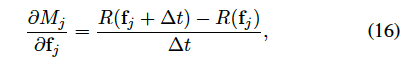
Annotator in The Loop
上記の計算は、最初から最後まで自動で行うケースを想定したものでした。
しかし、全てのラベルを完璧に生成することは難しいので、人(Annotator)の手による修正も簡便に行えることが望ましいです。
Annotatorによる修正も組み込んだ場合のアルゴリズムは以下のようになります。

簡単に言ってしまうと、モデルの出力→Annotatorによる修正→モデルによる関連する頂点の位置の再計算→Annotatorによる修正→...
というように処理が進むようになっています。
Polygon-rnn++では、一つの頂点を修正すると全ての頂点を計算し直す必要があったため、実験者が自分で決められる近傍点数のみ計算すれば良いCurve-GCNでは、モデルが行う修正の計算が高速化されています。
実験結果
本論文ではIn-Domainでの実験結果とCross-Domainでの実験結果が記載されています。まずはIn-Domainでの結果から見ていきます。
In-Domainでの結果
In-Domainというのは、学習に利用したデータセットとテストに利用したデータのドメインが同じであることを言います。
In-Domainでの実験は全自動(Automatic mode)とAnnotatorの修正あり(Interactive mode)の結果が載せられています。
IoUによる評価
IoUはIntersection over Unionの略です。
こちらの指標では以下のような結果になりました。

Spline-GCNが高い精度を達成していることがわかります。Trainに関しては、用いたデータにOcclusion(一つの物体が別のものにより遮られていること・被り)が多かったためにDeepLabよりも精度が低かったのではないかと述べられています。
Boundary-F-Scoreによる評価
IoUは正解マスクの全体領域を重視する指標なので、セグメンテーションのラベル作りを目的とする場合は物体の境界部分の精度を重視する指標の方がふさわしいと言えます。
そこでBoundary-F-Scoreを指標として利用します。Boundary-F-Scoreはprecision/recallとして計算されます。
IoU,precision,recallについてはこちらの記事がわかりやすいです。
Boundary-F-Scoreでの結果は以下のようになります。
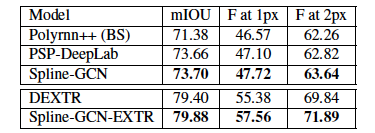
上記結果より、物体の境界面の精度ではSpline-GCNに分がありそうなことが分かります。
推論時間について
Curve-GCNとPolygon-rnn++の大きな違いは、ラベルの精度よりも推論時間の差にあるのではないかと個人的には思います。
以下が実験で得られた推論時間です。(実行環境についての言及はありませんでした。)
→Githubで言及されていました。
※Githubからコードのクローン・ダウンロードはできないようになっています。著者たちの作成したWebページからフォームを埋めて申請する仕組みになってます。
All the code has been run and tested on Ubuntu 16.04, Python 2.7.12, Pytorch 0.4.1, CUDA 9.0, TITAN X/Xp and GTX 1080Ti GPUs だそうです。
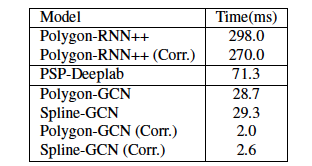
上記の表の(Corr)はAnnotatorによる一つの頂点の修正によって生じる計算時間です。
Polygon-rnn++が全ての頂点を計算し直すのに対し、Curve-GCNは関連部分のみを計算し直せば良いので、修正にかかる時間が初期の推論に対してかなり短くなっています。
Cross-Domainでの結果
本論文ではCityscapesで学習を行い、他のデータセットに対してファインチューニングした場合での実験も行われました。
ファインチューニングでは、新しいデータセットの10%を利用して学習しています。
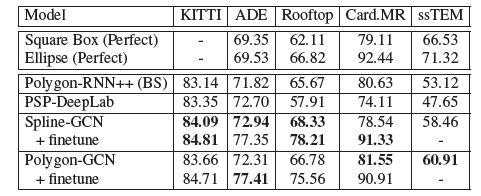
こちらも比較手法に比べてCurve-GCNの方が優れた成績を残しています。
まとめ
- Curve-GCNは、高速・修正容易という点でPolygon-rnn++,PSP-DeepLabといった既存手法よりも実用的なアノテーション技術である。
- ファインチューニングによって学習に利用したデータセット以外にも適用することができる。
- Occlusionにはそこまでロバストでないので、利用するデータには注意する必要がある。
コメント
- Polygon-rnn++,PSP-DeepLabについてはRelated-worksで読んだ部分程度の理解なので、時間あるときにちゃんと読みたいと思います
- 似た目的の論文としてReDO(私の過去記事です)という手法もあります。こちらは完全にEnd2Endなので実用性は本手法よりも低いかもしれませんが、面白い手法でした。