Unsupervised Object Segmentation by Redrawing論文まとめ
- 2019年の5月にsubmitされた論文です。
- arXivはこちら
概要
- セグメンテーションはピクセルレベルでのクラス分類であり、教師データの作成コストが高いタスクです
- 本論文の手法は完全にデータからのみの学習を行うため、アノテーションは何もいりません
- 「セグメンテーションモデルが正しいならば、それぞれの物体をセグメントされたものに置き換えてちょっと変化させても、リアルな画像に近くなるはず」という仮説に基づいています。そしてこの仮説がセグメンテーションのタスクにおいてうまくいったことが示されています。
- Scene compositionとAdversarial learning手法を利用しています。
- 本モデルは論文内でReDO(ReDrawing of Object)と呼ばれています。
ザックリとまとめていきます。サクッと見ていきましょう。
学習の枠組み
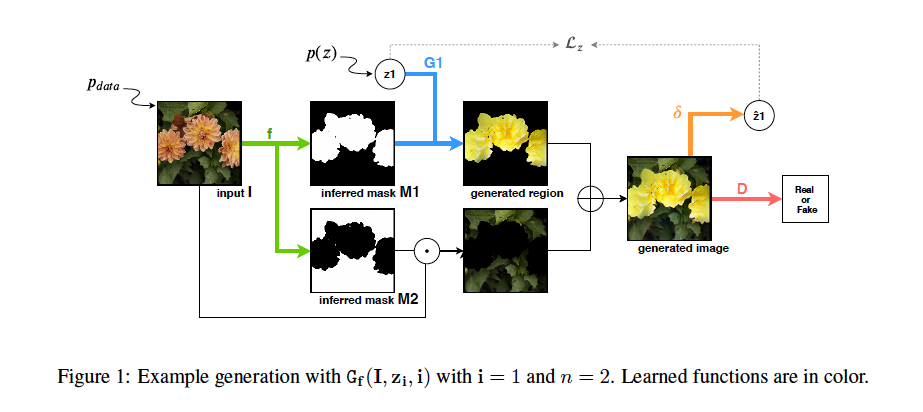
上図は本論文から引用したものです。
ReDO(ReDrawing of Ofject)は以下のステップで学習を行っていきます。
- Composition step
- Drawing step
- Assembling step
それぞれ順に見ていきましょう。
Composition step
このステップは画像をcompositionするステップです(そのまま)
具体的には、それぞれのクラスごとにマスクを作成することを指しています。上図の
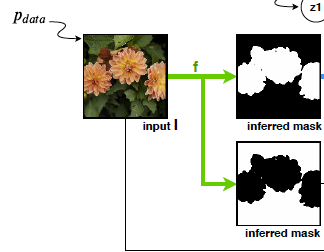
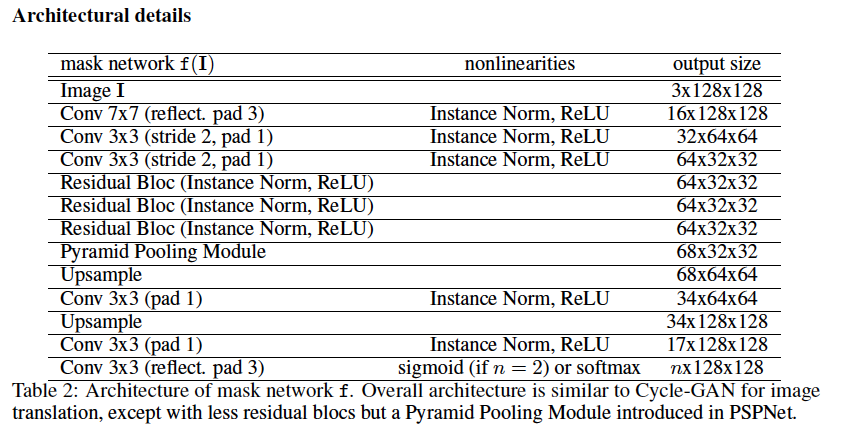
この部分に該当します。具体的な実装はPSPNetと言うモデルをベースにしたArchitectureになっています。
ここで注意する点は
- 背景(非物体)も一つのクラスとして扱うこと
- 1ピクセルはちょうど1クラスに分類されること
です。したがって、入力画像の全てのピクセルは、背景を含む何かしらのクラスに分類されることになります。
Drawing step
このステップは上記のステップで作成したマスクのうち、Redrawするマスクのみに編集を加えるステップになります。
上図の
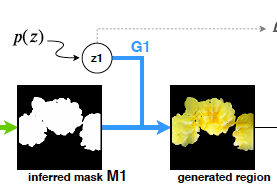
この部分に該当します。具体的な実装は以下のようになっています。

上図に現れる確率分布$p(z)$は、考えているregionのクラス$k$とマスク$M^k$が与えられた時の条件付き確率分布として表現されます。
$p(z)=p(V^k | M^k,k)$
つまり、学習が進むにつれて、クラス(花、車、人の顔...)とマスク(丸っぽいマスク、四角いマスク...)に有り得そうな特徴を乗せていくことになっていきます。(例 チューリップの形をしたマスクかつチューリップというクラスが与えられると、黒い色・ゴツゴツした質感をのせるのではなく、赤や黄色・花っぽい質感になるような編集になっていきます)
ここでは、**「物体のクラスごとに色・質感は異なる」**という仮説に基づいて処理を行います。
クラスが違っても似てる物体は(恐らく)有りますし、光の加減等で質感も変わってきますが、セグメンテーションのタスクにおいては上記のようなシンプルな仮説で十分にうまくいくそうです。
Assembling step
このステップは上記で作成したクラスごとのマスクと、背景のマスクを合わせて一つの画像にするステップになります。
上図の
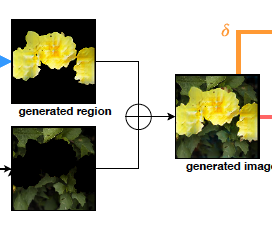
ここの部分に該当します。
この処理は単純にマスクをかける処理なので特筆すべきことはありません。
おさらい
ここまで見てきた処理の数式表現は以下のようになります。
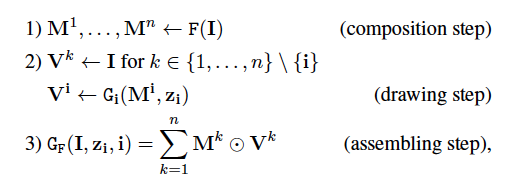
ニューラルネット$F$で入力画像$I$からマスクを作成し(composition step)、$i$番目のクラスの物体をRedrawするマスクを作成し(draw step)、全てのマスクを掛けて最終的な出力を得ます(assembling step)。
補足ですが、Redrawするクラスは離散一様分布$u(n)$からサンプリングします。
損失関数
最終的な損失関数は以下の数式で表現されます。

ここで$\lambda_z$と$\delta_i$について補足します。両者はRegionの情報が消えてしまわないようにするための係数・処理になっています。
$\lambda_z$はハイパーパラメータで、$p(z)$からサンプリングされた、その物体のRedrawの情報を保持する強さをコントロールします。
そして$\delta_i$はEncoderの働きをするニューラルネットで、生成された画像から特徴量空間への埋め込みを行います。
したがってGeneratorの最大化したい式の中の
$||\delta_i(G_F(I,z_i,i))-z_i||_2$
上記の数式は「画像生成に利用された特徴量」と「生成された画像から特徴量空間への写像」の距離ということになります。
$\lambda_z$を大きくすると、Discriminatorの判別誤差に対する特徴量のズレの影響を大きくすることになります。
$\delta$のArchitectureは以下のようになります。Discriminatorも同じ構造を利用しているそうです。

学習全体のアルゴリズムは以下のようになります。アルゴリズム自体はよくあるGANのアルゴリズムになっています。

コメント
- アノテーション完全不要はすごいなぁと思いました(小並感)
- セグメンテーションに特化した手法ですが、GANを使った教師なし学習は他のタスクでも応用が効きそうな気がします。