はじめに
この記事は、3/26から27日にかけて開催された全国医療AIコンテストでの、チーム🦾😢の参加記録です。
メンバー
- chizuchizu
- Twitter: https://twitter.com/chizu_potato
- GitHub: https://github.com/Chizuchizu
- abap
- Twitter: https://twitter.com/abap34
- GitHub: https://github.com/abap34
書いたこと
- コンペ概要
- 具体的なsolution
- コンペ実況
- 感想
全国医療AIコンテスト
東京医科歯科大学の学生グループが主催となって、医療xAIの関心を高めるべく、日本循環器学会に実質的に付属(?)するような形で開催されました。
1日目午前: 講演会
1日目午後: チュートリアル・コンペティション開始
2日目午後: コンペティション終了・表彰、解法発表
というスケジュールで、約1日間という非常に短い期間のコンペティションでした。
参加された方は医学系の方(医学部生, 院生, 医師の方)が多く、初日午前の講演ではお互い「...?」となる場面も多かったです。(が、門外漢でも楽しめる内容が多かったので楽しかった)
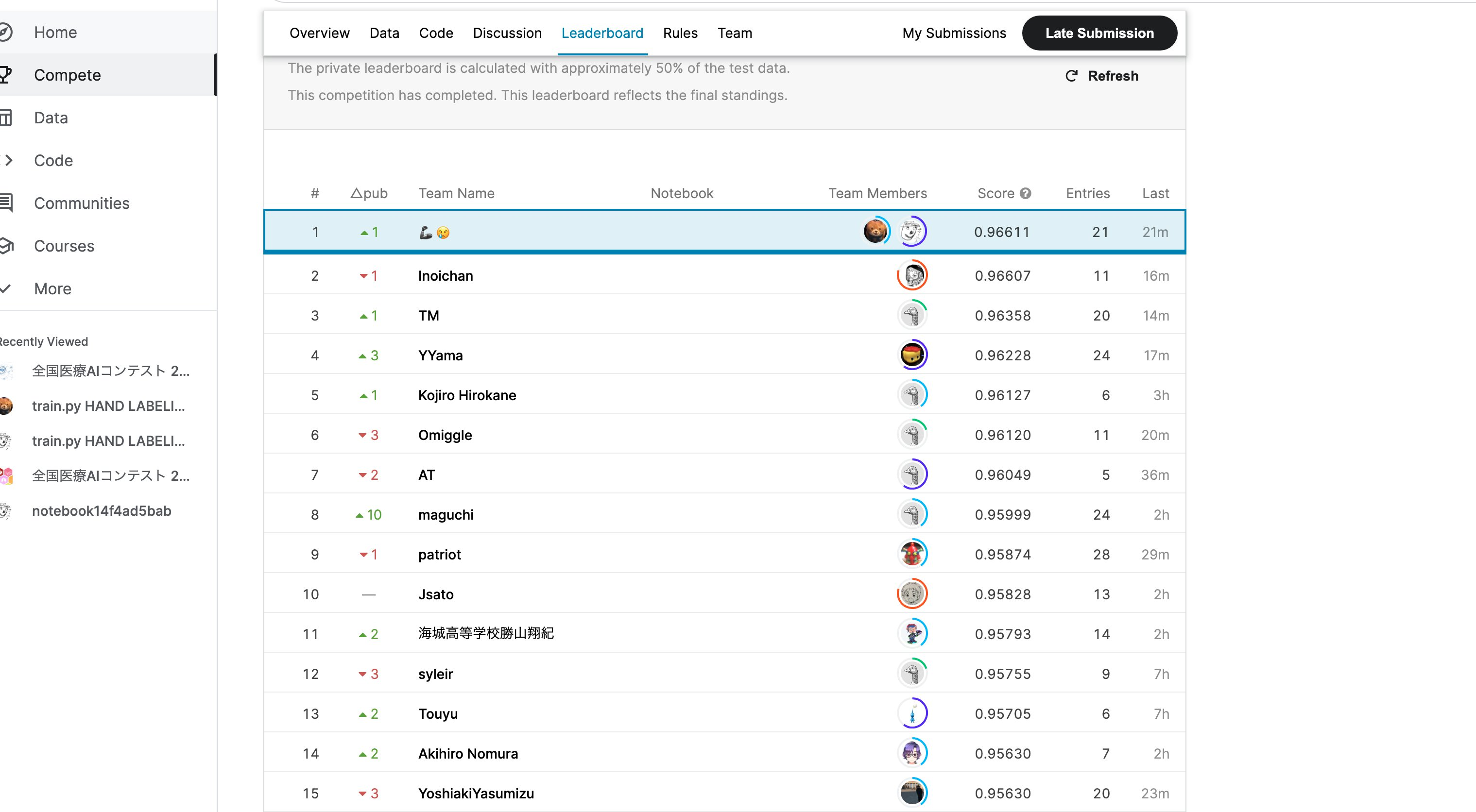
コンペ結果
優勝しました。 (∩´∀`)∩ワーイ
<中高生が優勝するなんて!
という声を多くいただいて大変調子に乗っています。
コンペ概要
タスク
12誘導心電図(12方向から計測した心電図)、及び患者のデータから心筋梗塞を判定するものです。
従って、一人当たり12個の波形データが与えられることになり、何もない状態からモデルを作るのはやや煩雑でした。

(与えられた心電図の例)
データ
各人について、
- 心電図の波形データ(12個) と、
- 性別
- 年齢
- ラベル付をしたのが人間か機械か
というデータが与えられました。
心電図は8秒間, 100Hzのデータだったので、NN以外で取り扱うのは少し難しかったように感じます。
評価指標
ROC AUCです。正例と負例の分布の重なり具合をみるような指標なのでAUCハック(Post Process)は考えつきませんでした。
賞金
どこから出てるんだろう👀👀👀
1位 3万
2位 2万
3位 1万
その他ルール
- 事前学習済みモデルを含め、外部データは禁止
というルールがありました。
このような波形データをあつかう場合は、データを画像に変換するアプローチがしばしば取られるのですが、事前学習済みモデルは禁止ということでこの選択の可能性は随分狭まったように感じます。
Solution
発表時のスライドは以下から閲覧できます。

abap34君という高校2年生の人(犬)とチームを組んで仲良くコンペに取り組みました。
(設定だとチズチズの飼い犬となっているが検閲によって削除)
彼はJuliaと機械学習の申し子で、正体は不明ですが天才です。
チーム名の意味
考案者のabap34曰く, 「この力のせいで友達ができない.....クソっ!こんな力なんて、なければいいんだ....!」と言っている人の絵文字だそうです。
理由は後付けのはずですが、よくわからないなりに良いチーム名だったと思っています。
要点
二人とも医学系のドメイン知識は他の参加者に比べれば皆無に等しいので、
- 理屈の前にとにかく実験(理由付は後からもできる)
ということを心がけました。
ですが、実験には信頼できるCVが不可欠なので、CVを工夫して信頼性を高めました↓
CV
謎分布
例えば年齢層の分布をラベル付の方法ごとにplotすると以下のようになります。

他にも、性別に関して
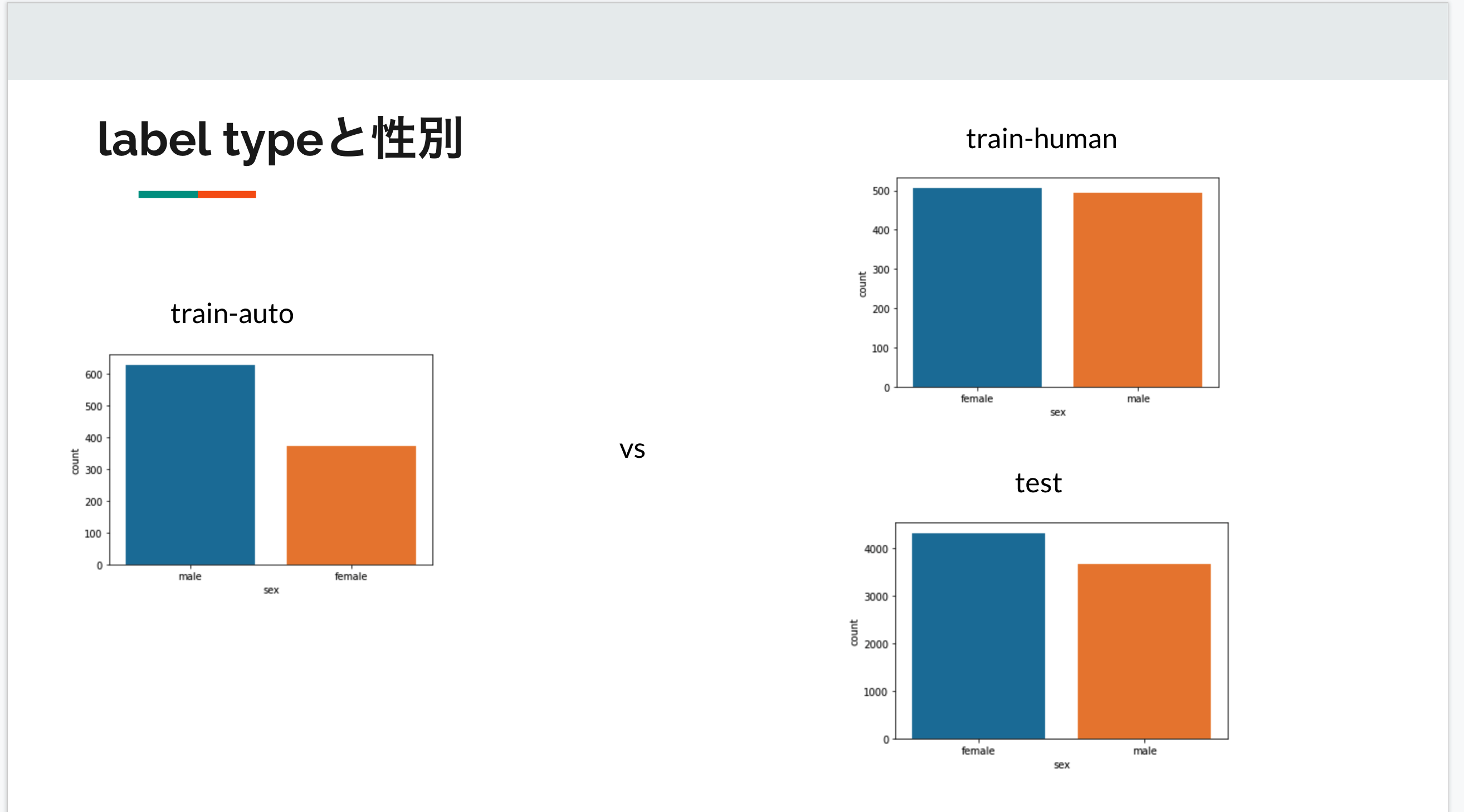
となっています。
そのためラベル付の方法によってデータの性質が異なる可能性があります。
ここで注意が必要なのがテストデータは全て人によってラベル付されていることです。
そのためナイーブなCVではバリデーションデータとテストデータの性質が乖離し、適切な性能評価ができない懸念がありました。
ラベル付に基づくCrossValidation
そこで次のようなアプローチを取りました。
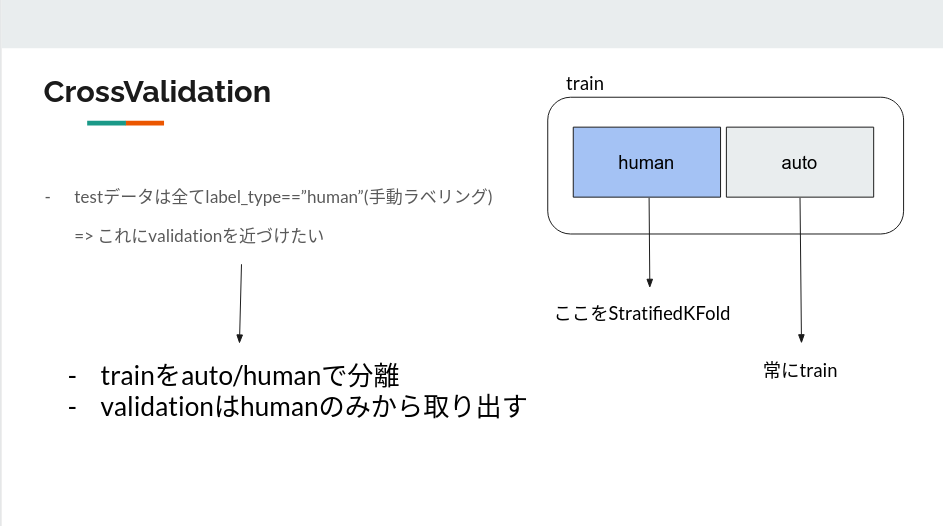
まずデータをラベル付の方法によって二つに分けたのち、人によってラベル付されたデータのみをStratifiedKFold(n_splits=5)によって切り分けます。
そして各foldに関して自動ラベルのデータをtrainに連結することによってvalidationは人がラベル付したものから取り出されることになります。
モデル紹介
さて、最終的な提出は6個ほどのモデルの加重平均でした。
ここからは提出に使用したモデルを個別に紹介します。
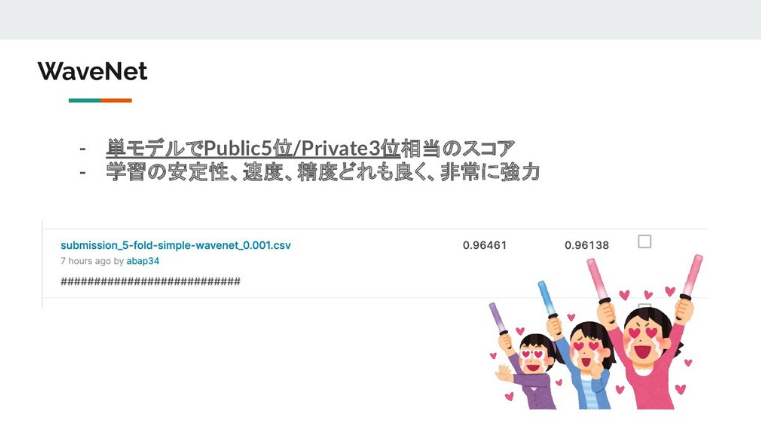
WaveNet(MVP)
abap君が捨て猫(埋もれてたWaveNet)を拾って大事そうにしてました。でも怪我の治療(このタスクに落とし込むための修正)に苦戦してました。僕は無理なら諦めるのも手だと口にしましたが、彼はその猫を信じて治療を続けてついに治すことができました。
彼は健康を確認するためにKaggleへ提出すると、なんとシングルモデル(PseudoLabelingなし)で当時2位相当のスコアを叩き出しました。
あ、でもabap君は犬だった……
こいつが優勝。(最強のモデルという意味で)
発光データに関するコンペのsolutionから発掘されたもので、
WaveNetまとめ | Qiita をみてくれたら雰囲気が味わえます。

簡単にいうと、層が深くになるにつれて「とびとび」で畳み込みを行うモデルです。
Pseudo Labelingしてないのにこのスコアは強すぎる。
事実上これが組めれば入賞圏内でした。
A Deep Transferable Representative Model
- ECG分類用
- ResNet的
- そこそこ深い
これだけでもそこそこ戦える。
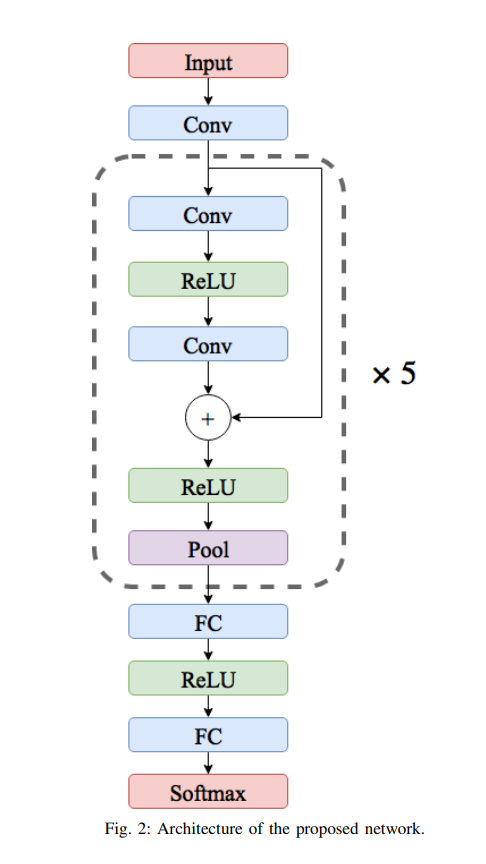
Model from ArXiv 1805.00794 というKaggle Notebookから拾ってきたコードを良い感じに書き換えました。
最初は変数名が謎すぎてしょうがなかったのですが、ブロックごとのindexと何をしているかを明記しているようです。(後から分かった)

これにLabelSmoothing, PseudoLabeling等の工夫を施すことでPrivate4位相当のスコアを出すことができました。
また、当時はPublic2位だったのでこのときから完全燃焼がはじまったと思っています。

ResNet的なConv1dモデル
- Resnet感
- Convが決め手
- どうやら12誘導心電図の分類に使ったモデルらしい

まあ、やるだけ。
kernel_size とUnitの数を減らすなど少し調整は施しました。
def get_model_paper(inp, last_layer='sigmoid'):
kernel_size = 5
kernel_initializer = 'he_normal'
signal = inp
x = signal
x = Conv1D(64, kernel_size, padding='same', use_bias=False,
kernel_initializer=kernel_initializer)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x, y = ResidualUnit(256, 196, kernel_size=kernel_size,
kernel_initializer=kernel_initializer)([x, x])
x, y = ResidualUnit(64, 64, kernel_size=kernel_size,
kernel_initializer=kernel_initializer)([x, y])
x, y = ResidualUnit(32, 128, kernel_size=kernel_size,
kernel_initializer=kernel_initializer)([x, y])
x, _ = ResidualUnit(16, 256, kernel_size=kernel_size,
kernel_initializer=kernel_initializer)([x, y])
x = GlobalAveragePooling1D()(x)
diagn = Dense(10, activation="relu")(x)
# model = Model(signal, diagn)
return diagn
そうですね〜

LSTM
アンサンブル用に最終盤で急遽実装しました。何もチューニングしていないのですが、そこそこのスコアが出ました。
x = Conv1D(filters=32, kernel_size=5, strides=1)(input1)
x = Conv1D(filters=32, kernel_size=5, strides=1, padding='same')(x)
x = Activation("relu")(x)
x = Dense(32)(x)
x = Bidirectional(LSTM(64, return_sequences=True))(x)
x = Dropout(0.2)(x)
x = BatchNormalization()(x)
x = Dense(32)(x)
x = Dropout(0.2)(x)
x = BatchNormalization()(x)
x = Dense(16)(x)
後にGRUのほうが精度が高かったとか聴いたので、やればよかったな〜とか思ってます。
Baselineは超えてるけどめっちゃ良いわけではないですね。これ確か朝起きて9時頃とかに作成したものでもうチューニングとかしてる暇がなかったので、このまま何もしていませんでした。
それでもそこそこのスコアは担保されてたのでアンサンブルに使いました。

モデリング
メタ情報を加える
どのモデルも基本的に最終層でConcatする形で性別と年齢の情報を入れました。やはり精度は上がりました。
正直次元関係のバグを治すのが大変でした。使っていたKerasはPyTorchと違って静的に計算グラフを構築するイメージなので、デバッグは面倒です。
その分、モデルの構築時に多くのエラーが検出できるので、一長一短ですね。
SWA
モデルのパラメータを定期的に抽出してそれらを平均化させることでより大域的な解に収束させることができます。
Tensorflow_addonsで実装されていたので、インドカレー屋のオプションのチーズナン感覚で1行実装できました。
SAM
全人類はこれを読んでほしいです。最小かつ平坦になるパラメータを探索するので局所解に陥りにくいです。shake upの機運が高まりますね。
短所は学習時間が少し長くなることですが、別のコンペでも汎化性能の向上に大いに貢献したこともあってとりあえずやるのは大事だと思いました。
TFに関数が用意されてるので、インドカレー屋のオレンジラッシーを頼む感覚で1行実装できました。(上と同様)
Pseudo Labeling
読み方は「スード」or「シュード」のようです。abap君はずっと「ピーセウド」と呼んでました。(本人曰く、「読み方は知ってるけど違和感がすごい」)
ラベルがないデータにラベルを付与して、疑似教師あり学習をやろうというものです。一般的にKaggleではテストデータにラベルを付与して水増しっぽいことをします。
これをやることで、単純にデータの水増しと、"よりテストデータにoverfitした"モデルを作成できると言われています。<-ほんと?
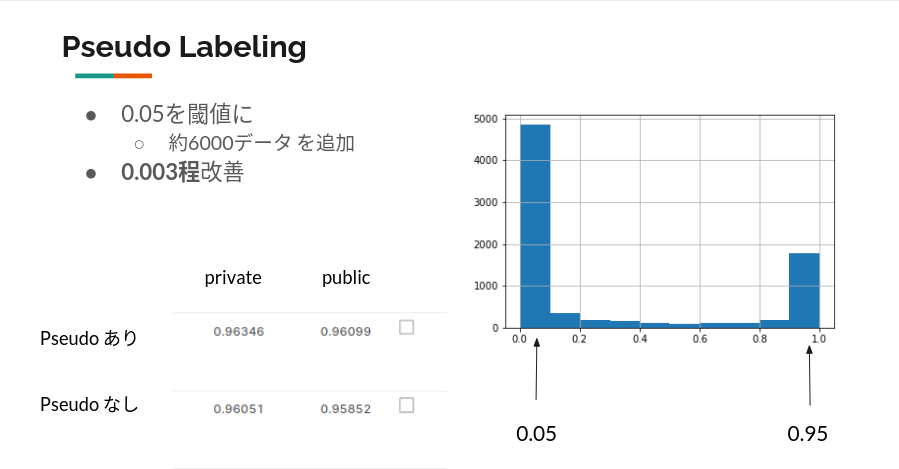
確実性が高いモデルの出力を信じて疑似ラベル付(Pseudo Labeling)をします。一般的には0.5みたいな中途半端な出力は使いません。
どこまでPseudo Labelingするか悩ましいのですが、モデルの出力を可視化させてみてそこそこ厳し目な閾値を設定するのが良いと思っています。
閾値は0.005、テストデータのおよそ70%を使って再学習しました。
Label Smoothing
きっかりとした0と1のラベルではなく、0.1と0.9というように優しさを与えるという表現がよくされます。
Label Smoothingに関する日本語の解説が少ないのですが、唯一わかりやすそうな東大の論文輪読会のスライドがあったので共有します。

https://www.slideshare.net/DeepLearningJP2016/dlwhen-does-label-smoothing-help
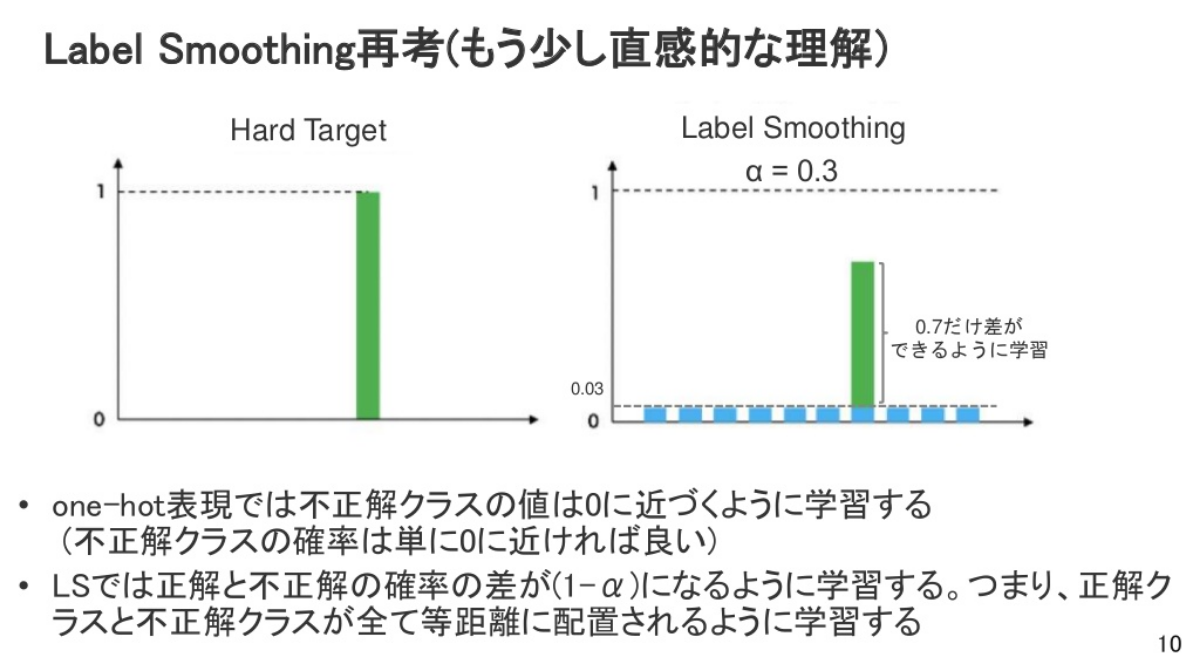
- Hard Target: 正解ラベルを1, それ以外を0とする
- 離散値で与えられる
- 正解と不正解の距離が遠いほうが良い
- SmoothなLabel
- 正解と不正解の確率の差を調節する
- 結果として過学習を防ぐアプローチ
TFのBinaryCrossentropyには引数にlabel_smonothingというものがあって簡単に実験ができます。
0.001と0.01と0.1で試しましたが、0.001が最良でした。abap34が提案しました。やはり天才か.....
勝因
shake up対策
- ロバストなモデリング
- testデータにoverfit
- 多様なモデルのアンサンブル
疑心暗鬼
ずっと「ほんとか??」って言ってました。
うまくいくかなんて実験してからわかることなのでとにかく実験を回すことを意識していました。机上の理論、一般論が正しいとは限らないです。
もちろん仮説を立てる段階で一般論や理論を使うことはありますが、必ず対照実験して裏を取りました。
寝ないでずっと通話
コンペは金曜日の17時から土曜日の12時まで続きました。
普通に夜やらないと間に合わないだろということでずっと起きて通話を繋げていました。
自分は生まれてはじめて徹夜をするのでマジで不安でしたが、5時頃まではどうにかやってました。深夜テンションのおかげで二人とも思考や言動がおかしくなりましたが。
短期間のコンペでは実験をどれだけ回したかが重要になってくる(と思ってる)のでずっと実験をしていました。
また、通話を繋げて連続的に進捗管理、やることをまとめていたのでかなり効率的だったと思っています。
隣の部屋で寝てる親に徹夜で通話していることがバレていないようで良かった。
とはいっても自分は5時から6時半まで仮眠をとりましたがw実質徹夜です。
椅子に座り続けることによる身体的な疲労は感じていませんでしたが、ベッドで横になってから頭がぽわーってしたり体が熱くなってることを実感して疲れてるんだなーとか思ってました。
とりあえず、チームを組んでなかったら徹夜するはずもなかったわけで最高のチームマージだったと振り返っています。
タスクに囚われない
コンペが終わってから指摘されてなるほどなと思わされたのですが、どうやら僕たちは先入観がないピュアな心で取り組んでいたようです。
今回のタスクは心電図の分類ですが、波形で使えるモデルやアプローチを探していました。結果WaveNetとかいうお宝も発掘できました。
楽しむ
- ダジャレをいう
- チーム名を変える
- 面白くなくても笑う → それが面白い
反省点
コード共有
ずっとKaggleに貼り付けてましたがGitHubでやってればもっと楽だったなと思っています。
短期間のコンペなので、わからないところがあったらチームメイトに聞かないとと時間だけが消費されて作業効率が下がってしまいます。
ことばでの情報共有はうまくやってたのですが、コードはうまくいってませんでした。
きれいなコード
TFが1回しか呼び出されてなくて不安なのですが
ここに注目してください。
そうです。僕のコードはTFを5回呼び出すコードをはじめ、全体的に汚いままでした。
カスタムvalidationを書くときなど添字周りでバグを作ってしまったのも、綺麗なコードを書いていればもっと早く解決できたかもしれない。
短期コンペだからといって焦ってコピペするだけじゃいけないようです。
時系列で振り返るコンペ
マジであんまり覚えてない上にDiscordもKaggleのsubmissionも詳細な時刻が消えてしまったのでアバウトで書きます。
9時半〜5時半
1日目のメインプログラムである日本循環器学会の講演を聴講することになっていました。
abap君がTwitterで一緒に通話繋げて聴く人探してたから僕が 仕方なく 手を挙げて、Discordで通話を繋げてワイワイした記憶があります。
後半になるとabap君によるJuliaの講座も開かれててとても勉強になりました。
5時半〜9時
ぼく
- PyTorch Lightningに書き換える
- 画像アプローチ
- 優勝するぞ
abap
- どうせNNは組むので、アンサンブル用にLightGBM行くか
- 優勝するぞ
その後
ぼく
- やべぇ、baselineより精度低い
- 何もわからない
- 画像アプローチ無理やん
AUCが0.64! 機械学習の天才!!!!(ひどすぎる)
TFが動かない! 死!!!
abap君がおまじないを教えてくれました。これで上手くいった。これがなかったら優勝は無理。
import tensorflow as tf
physical_devices = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
abap
- 特徴量重すぎて死
- 間に合え
- 某コンペで培った知識、使ってやるよ(波形系)
- EDA
あれれ、おっかしーなー。分布が違うぞ???(ここからはじまるCV戦略)

9時〜11時
ふたり
- TFでやるか
- このタスクのコード探す
- ResNet系のアプローチが見つかる
- やるだけ(とりあえずやろう)
しかし当時は最下位から数えて2番目の順位だったのでモチベは最悪でした。とても悲しかったんですけどabap君は諦めたらうんたらかんたら言ってきたのでギリギリやってました。
僕はBaselineの実装を改良させてアーキテクチャを色々いじってました。Papers with Codesとか駆使して論文実装色々試したんですけど、すべてうまくいって海賊王になった気分でした。
11時〜2時
論文の少し深いConvolution NNモデル書いたら10位以内に入りました 多分11時過ぎ
そのせいで超やる気になりました。
- Label Smoothing
- SAM
- Pseudo Labeling
- CV戦略
くらいはやったのかな〜?
CVのデバッグに明け暮れていてabap君に応援をお願いしたのですが自分のコードがあまりにも汚くて怒られました。
tensorflowを5回importしてた事件は忘れられない。
チーム名で遊んでました。

深夜テンションでした。脳汁ドバドバ出てて気持ちよかったです。
2時〜5時
- stacking
- 新アーキテクチャの発掘
をしてたのかな 正直全然覚えていません。
いのいちさんっていうpublic LB1位の方が序盤に飛び抜けすぎてて僕ら優勝できるんかな…… とか不安そうに話してたような。
僕は生まれて初めての徹夜体験だったので体が心配すぎて5時から6時半まで1時間半仮眠をとることにしました。寝坊したら怖いのでチームリーダーをabap君にしてぐっすり寝てました。
5時〜6時半(abap34)
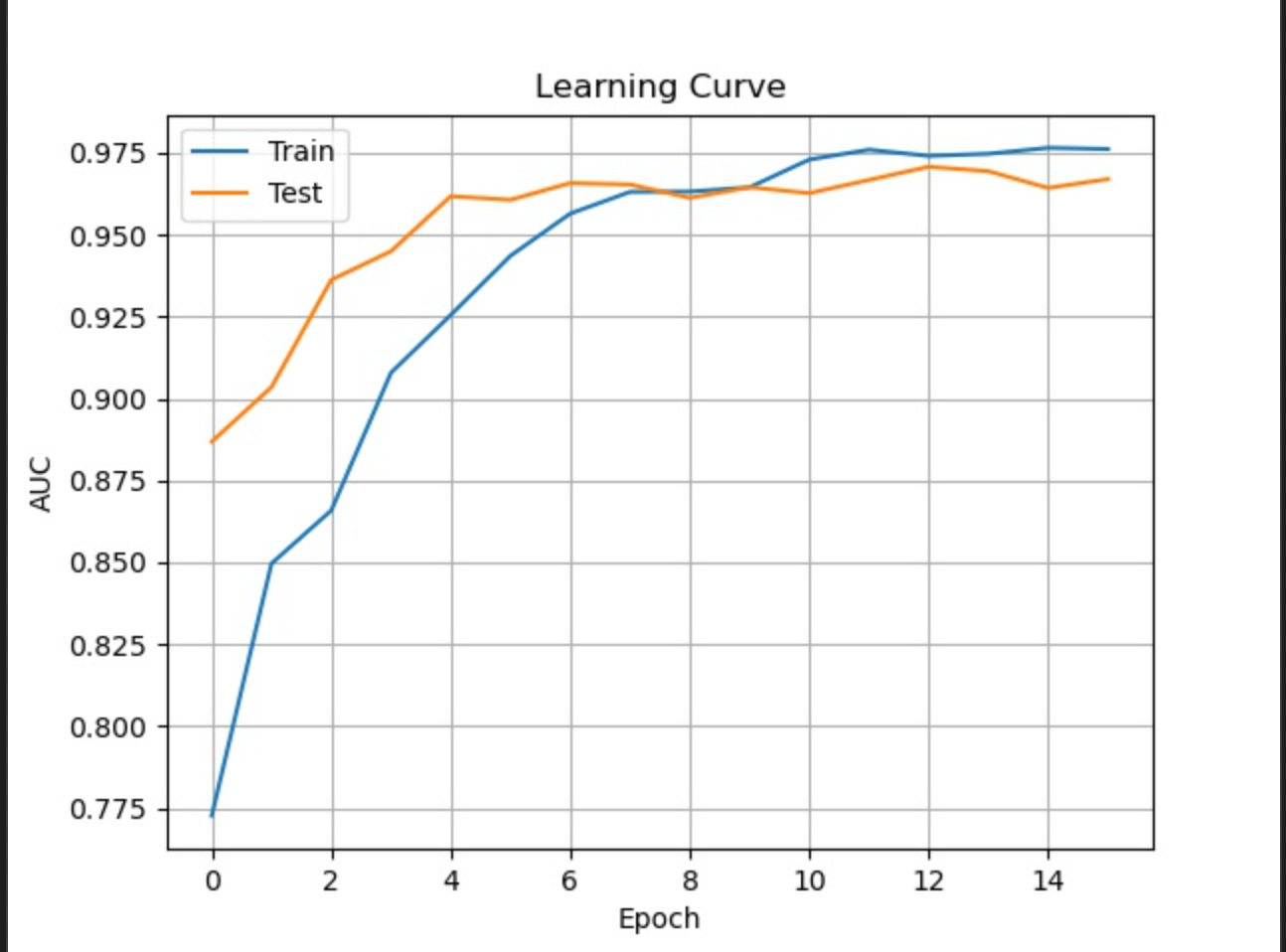
チズチズが寝ている間にWaveNetのバグ取りと学習を済ませ、サブミットしたところ圧倒的精度を叩き出し一人で盛り上がっていました。
圧倒的安定感
その頃チズチズが起きてきたので、朝ごはんを作っていた記憶があります。
6時半から(abap34)
お互い最終サブミットに向けてアンサンブル、スタッキング等の作業をしていました。
(が、僕の環境で動いたコードがチズチズの環境で動かず、結局ただの職人芸加重平均となってしまいました。)
6時半から(chizuchizu)
起きたらabap君が朝ごはんを作っていたのですが、かなり疲れているようでした。かわいそうに。
先日Colab Proに入ったのでGPU並列してたくさんモデルを回してました。下に書いてある通り、12時に終わってしまったので一部モデルは優勝決定後に学習終了して不思議なお気持ちになりました。
もちろん終わったものは12時前の最終提出に間に合ってます^^
マジで職人芸危険すぎやろ!!!w って思ってたので数理最適化しなさいって念じてたんですけど結果からいうと職人芸してなかったら勝てなかったのでぐうの音も出ません。
12:00(abap34)
アンサンブルの重みを計算するコードを書いていたら突然「え!コンペ終わってる!優勝!!」と通話で叫んでいる人がいました。
最初はタチの悪い冗談だなぁと思ったんですが、なんとガチで終わっていて、(connpass上の時間を間違えていた?)優勝していました.....
なので、お互いツイートに"たぶん"と入っている
15:00(abap34)
すごく慌ててsolutionを書きました。お互いわかるところを分担して作成・発表しました。
今考えるともう少し見通しがよくなるように見出し等ちゃんとやればよかった....
発表自体は滞りなくできたと思います。
いわゆる「素人質問」が飛んでこなくてよかったです。
15:00(chizuchizu)
家の近所の100円自販機で三ツ矢サイダーを買ってプレゼンに備えました。
賞金で三ツ矢サイダー pic.twitter.com/HhQNqKUirn
— チズチズ (@chizu_potato) March 27, 2021
当時は徹夜明けなので疲労が限界に達していたのでプレゼン作るのに精一杯でした。
コンペ始まる前からsolution作っておけば良かったと後悔しています。
とはいえプレゼンは頑張ったのでどうにかなりました。
いのいちさんがマジで半端なくて、CNNとLSTMとTransFormerを詰め込んだpseudo labeling無しのモデルで2位取っててどんな計算環境だよ!!とか突っ込んでやりたかったんですけど、さすがいのいちさんだけあってあと1時間あったら越されてただろうなとか思ってます。

https://docs.google.com/presentation/d/1bPCP5poQL8OuAu3CFpKwozEx6Ra-YHTJBICw4uWXsnU/edit#slide=id.p
3位の方は東京大学の方で、LSTM系に重点をおいていたのが印象的でした。
LSTMとGRUとCNNの混合モデルアンサンブル(PseudoLabelingあり)でした。
まとめ(abap34)
自分で言うのは恥ずかしいんですが、お互いに大きく貢献して医学部・院生、医師の方々を倒せたのはめちゃくちゃ嬉しかったです。
受験生ということもありしばらくコンペからは離れることになりそうですが、いい結果が出せてよかったです。
WaveNetありがとう。
まとめ(chizuchizu)
久しぶりに"何か"に本気で取り組んだのでマジで楽しかったです。肉体的に苦しいコンペだったのでこれから筋トレに励んでKaggleに備えたいと思っています。
受験生ということもありしばらくコンペからは離れることになりそうですが、いい結果が出せてよかったです。
俺…… 泣いちゃうよ……