[明治大学総合数理学部 Advent Calendar 2017](https://qiita.com/advent-calendar/2017/meiji-ims) 19日目の記事です. はじめまして. 現象数理学科3年の江口です. Qiita初投稿です. この記事では, WaveNetについてまとめました. 時間があれば, 最近発表されたParalell WaveNet についてまとめたいと思います.
前提知識
- Neural Network
- Convolutional Neural Network
- Recurrent Neural Network
- ResNet
背景
唐突ですが, データサイエンティストたるものデータサイエンティストを目指すなら, deep learningの最新動向は随時追っていなければ, と思いDeep Learning Weeklyを読み始めました.

ここには最近話題のCapsule Networkについても紹介されています. deep learningに関する最近の動向についてある程度知ることができると思います.
今回は中でもNovember 26 - issue#66に載っていたこの記事に注目しました.

音声生成をするけど, 個々のサンプル無しにセンテンス全体を生成出来て凄いようです(どういうことだ?).
「WaveNetを使ったハイファイ1音声合成」という題の記事ですが, そもそもWaveNetとは何か. 調べてみるとこれ, 思っていた以上に凄かったんですね.
まずWaveNetを開発した会社DeepMind. こちらは2014年にGoogleに買収されたイギリスの人工知能企業で, AlphaGoのプログラムを開発した会社です.
次にWaveNetは既にGoogle製品, 「Googleアシスタント」に搭載されているそうです. 英語だけでなく日本語も対応!そして驚いたのが, この情報を得たGigazineに載っていた, 既存のTTS2音声とWaveNetによる音声のサンプル. これを聴き比べると, 明らかにWaveNetの方が自然に感じます(音声の出典元は[4]).
で, Deep Learning Weeklyの記事で紹介されているParallel WaveNetというのは, オリジナルのWaveNetと比べて1,000倍早く音声生成が行われ, しかも同様の自然な音声が流れるそうです.
前置きはこれくらいにして, ここからはWaveNetについて紹介します.
目的
WaveNetの仕組みを説明する.
WaveNetの紹介
WaveNetを一言で
PixelCNN3をベースにした音声波形を生成するためのディープニューラルネットワークの一つ.
音声波形の生成モデル
音声波形のデータセットを, $\boldsymbol{x} = \{ x_{1}, x_{2}, \cdots, x_{T} \}$とすると, 以下のように条件付き確率で生成されると仮定する. つまり, 音声サンプル$x_{t}$は前時点の全てにおけるサンプルに条件づけられる.
p(\mathbf{x}) = \displaystyle \prod_{t=1}^{T}p(x_{t}\ |\ x_{1}, \cdots, x_{t-1})
Dilated Causal Convolutions
WaveNetのメイン部分は, 時系列データセットに対し, Convolutionをかませている点である.
Causal Convolutions
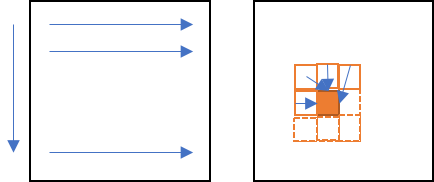
下図のように, 予測分布$p(x_{t+1} | x_{1}, \cdots, x_{t})$は将来の時間ステップ$x_{t+1}, x_{t+2}, \cdots, x_{T}$には依存しない(=Masking).
図を見てわかる通り, Reccurent Neural Networkに見られるような回帰的な接続が無いので, RNNより学習が速い.
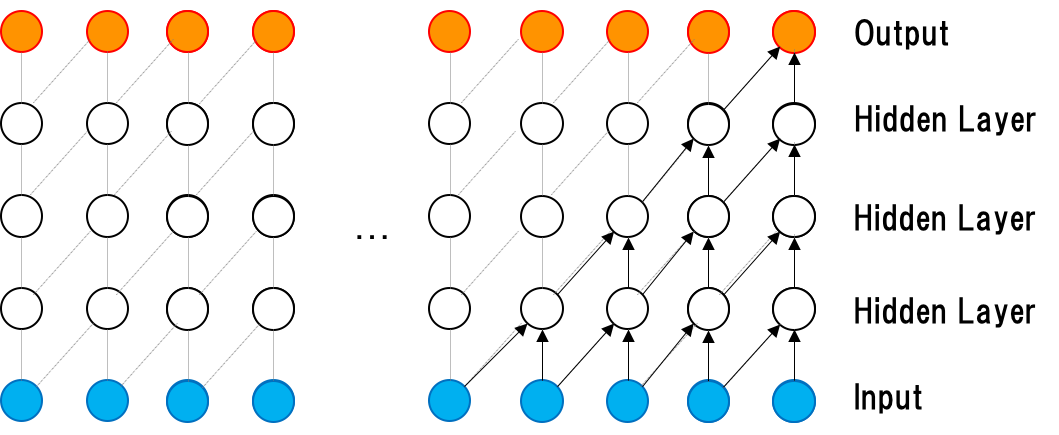
Dilated Causal Convolution
先ほどのCausal Convolutionとは異なり, 層が深くなるにつれて, 畳み込むノードを離す(=Dilation). 論文[6]では, $1, 2, 4, 8, \cdots, 512$と指数的に大きくしている. 下図(Deep Mind[5]より引用)では, InputからOutputにかけて, $\rm{Dilation} = 1, 2, 4, 8$となっている.

Softmax分布
典型的な音声は1タイムステップあたり16-bitの整数値で保存される. つまり取りうる値を生成するために, 1タイムステップあたり65,536個の確率をアウトプットできるようにする必要がある. よってsoftmax layerで値を限定する必要がある. すなわち, 以下の計算を実行する($\mu$-law companding transformation)ことで, 256の取りうる値に圧縮する.
f(x_{t}) = sign(x_{t}) \displaystyle \frac{\log \{1 + \mu |x_{t}|\}}{\log \{1 + \mu \}}\\
\begin{align*}
但し, -1 < x_{t} < 1, \mu = 255
\end{align*}
Gated Activation Units
畳み込みのフィルタ以外に, gated activation unitを使う.
\mathbf{z} = \tanh (W_{f, k} * \mathbf{x}) \odot \sigma (W_{g, k} * \mathbf{x})
$*$は畳み込みの演算. $k$はlayer index, f, gはそれぞれfilterとgateであることを示す. $\sigma$はsigmoid関数. $\odot$は要素毎の乗算を表す. $W$は学習可能なconvolution filter.
注) gated activation unitですが, 論文[6]には「gated Pixel CNNで使われているのと同様のもの」の記載しかありませんでした. 私の見解では$W_{f, k}$と区別するために名付けただけで, フィルタと大差無いものと考えていますが, 分かり次第更新します.
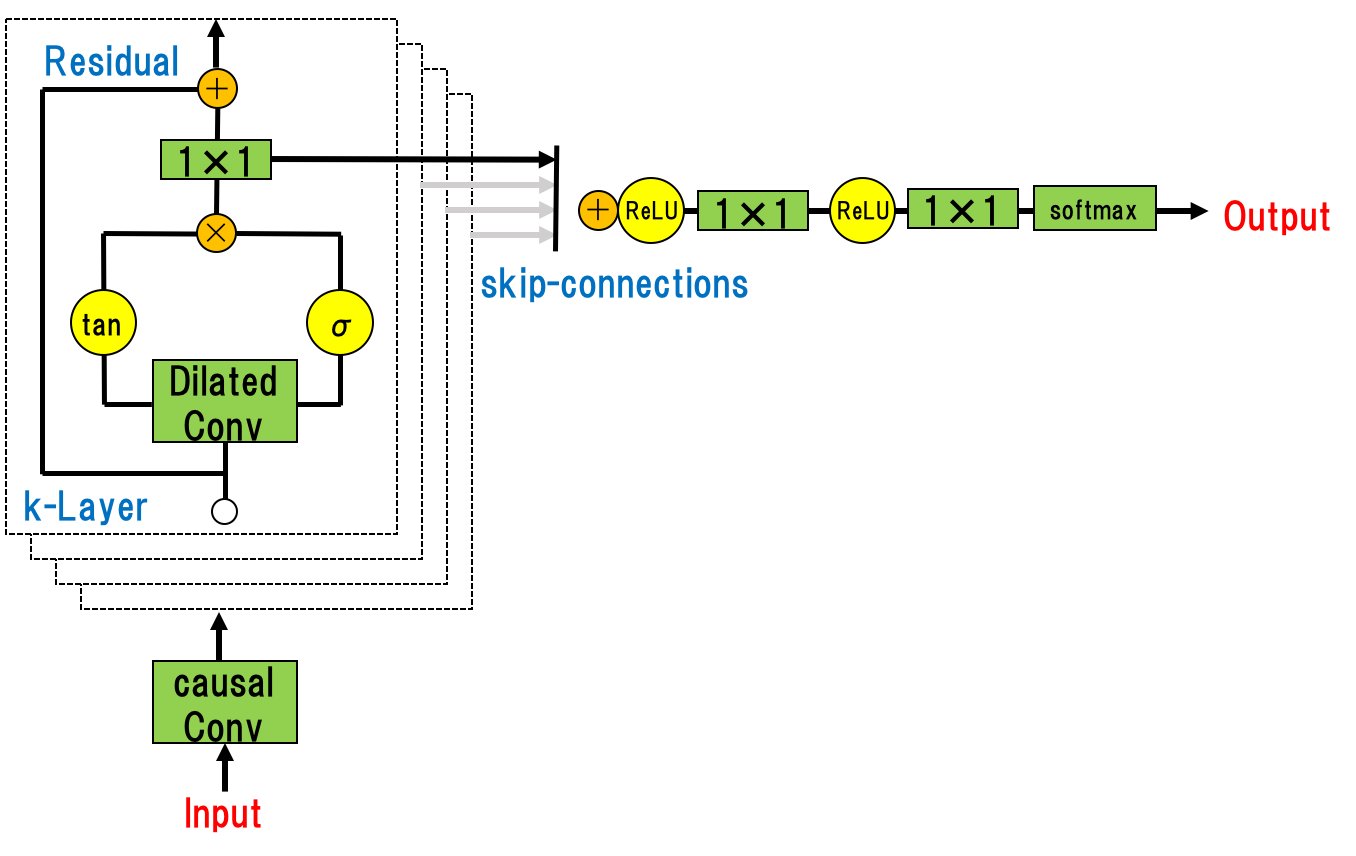
Residual and skip connections
ResNetのように, 収束を早めるための工夫がNNを通して使われている. その概要を以下の図で示すだけで説明は省略する(論文[6]参照). ResNet同様, 勾配消失を避けることが目的となる.
Conditional WaveNet
さらにインプット$\mathbf{h}$を加えることを考える. これは生成された音声の特徴を特定することを目的とする.
例えば, 複数の話し手の音声が含まれる音声データセットについて, インプット$\mathbf{h}$として話し手の特徴をモデルに加えることによって, その複数の話し手の中から特定の話し手を選択することができる.
またTTSの場合, $\mathbf{h}$をテキストに関する情報として与えることが必要になる.
p(\mathbf{x}\ |\ \mathbf{h}) = \displaystyle \prod_{t=1}^{T}p(x_{t}\ | \ x_{1}, \cdots, x_{t-1}, \mathbf{h})
この追加したインプット$\mathbf{h}$に対し, 制約をかける2つの方法, Global conditioningとLocal conditioningがある.
Global conditioning
全体の時間においてアウトプットの分布に影響を与える$\mathbf{h}$によって特徴付けられる場合.
例えば, TTSにおける話し手. 活性化関数は,
\mathbf{z} = \tanh (W_{f, k} * \mathbf{x} + V_{f, k}^{T}\mathbf{h}) \odot \sigma (W_{g, k} * \mathbf{x} + V_{g, k}^{T}\mathbf{h})
$V_{* ,k}$ は学習可能な線形射影, ベクトル $V_{*, k}$ は時間次元上.
Local conditioning
音声シグナルよりも低いサンプル頻度の確かさについて.
例えば, TTSにおける言語的な特徴など.
音声シグナルと同じ解決のために$\mathbf{y} = f(\mathbf{h})$というように, 新しい時系列に写像することで, 現在の時系列を変換する(=transposed convolutional network).
\mathbf{z} = \tanh (W_{f, k} * \mathbf{x} + V_{f, k}^{T} * \mathbf{y}) \odot \sigma (W_{g, k} * \mathbf{x} + V_{g, k}^{T} * \mathbf{y})
($V_{f, k} * \mathbf{h}$を使う方法も考えたが, 実験においてあまり良くなかったらしい)
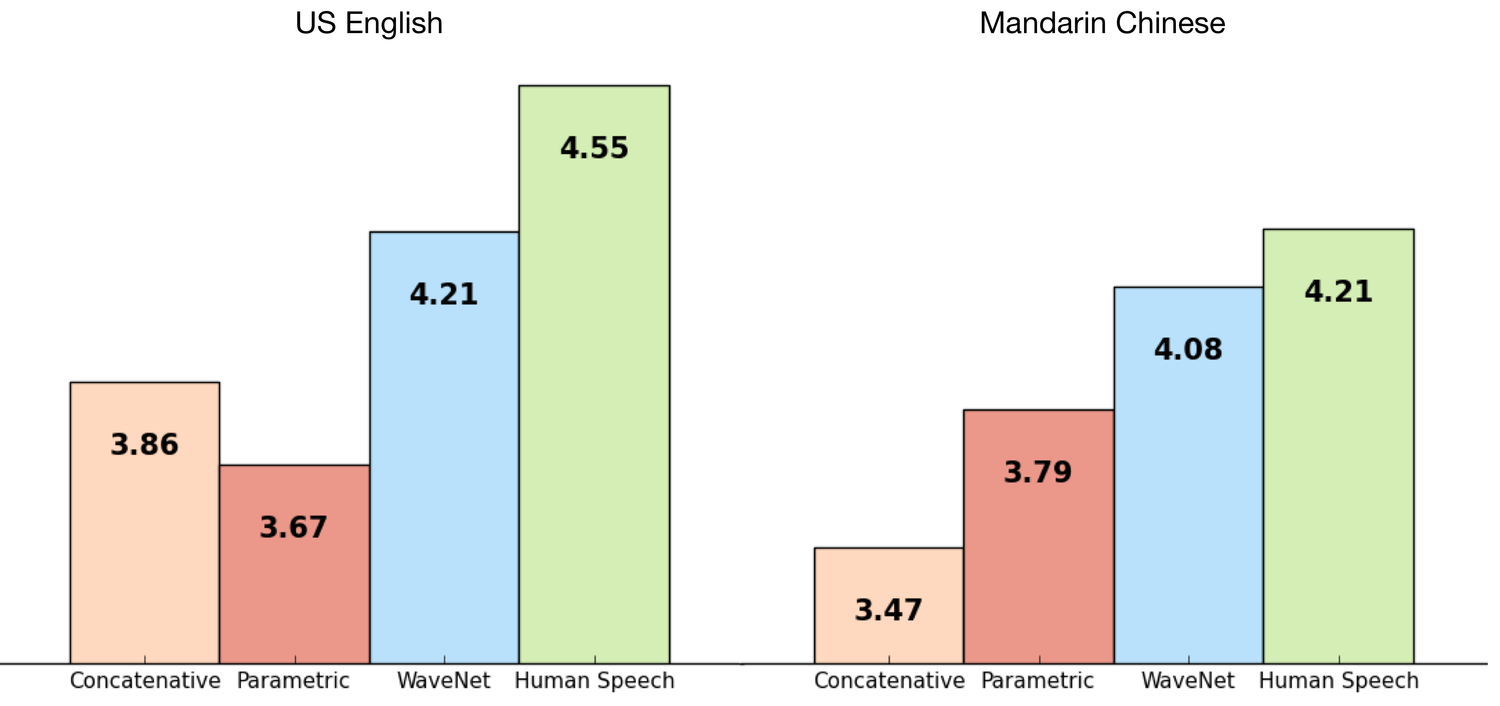
評価(記事[5]より)
背景の中で, WaveNetの音声が自然で凄いと驚いたと述べたが, きちんと指標を用いてどれほど凄いのかを示す必要がある.
MOS(Mean Opinion Scores)という, 人間の話し方とのギャップを計測する客観的な評価方法が存在する.
結果, 従来の方法に比べ, 人の話し方とのギャップを50%以上縮めることに成功した.
おわりに
WaveNet実装できると良いですね(する予定はありません)
Parallel WaveNetのまとめまでいけませんでした.
眠いです.
おまけ: Parallel WaveNet概要(12/19, 17時追加)
時間があれば原論文も読んできちんと記事にしたいと思います. ここでは箇条書きで記事[2]のまとめをします.
- ヒューマンパフォーマンスとのギャップを従来のTTS技術に比べて50%削減.
- Original wavenetより1000倍早く、かつクオリティを保つTTS技術
- Teacher(オリジナルのwavenet)に対してNNモデルのStudentを用意.
- Probability Density と呼ぶ方法
- より小さく並列処理を行うので今日のハードウェア向けである.
- StudentはTeacherとやっていることは似ているが, 入力がノイズであることと, 各入力を並行して順伝搬する点で異なる.
- KLダイバージェンスをloss関数として計算して最小化.
- GANに近いが, 異なる部分は騙すのに対し, 協調してTeacherのパフォーマンスに合わせる点である?
- 他にperceptual loss(発音の悪さを避ける), contrastive loss(ノイズを減らす), power loss(人のスピーチのエネルギーに合わせる)もコスト関数に加える
参考文献
[1] Deep Learning Weekly 2017/12/18 accessed,
http://digest.deeplearningweekly.com/?utm_campaign=Issue&utm_content=profileimage&utm_medium=email&utm_source=Deep+Learning+Weekly
[2] Deep Mind, High-fidelity speech synthesis with wavenet 2017/12/18 accessed,
https://deepmind.com/blog/high-fidelity-speech-synthesis-wavenet/?utm_campaign=Revue%20newsletter&utm_medium=Newsletter&utm_source=Deep%20Learning%20Weekly
[3] ディープラーニングで人間のような自然な音声を話す「WaveNet」がGoogleアシスタント搭載の新ハードウェアに搭載|Gigazine 2017/12/18 accessed,
https://gigazine.net/news/20171005-wavenet-launch-in-google-assistant/
[4] Deep Mind, WaveNet launches in the Google Assistant 2017/12/18 accessed,
https://deepmind.com/blog/wavenet-launches-google-assistant/
[5] Deep Mind, WaveNet: Generative Model For Raw Audio 2017/12/18 accessed,
https://deepmind.com/blog/wavenet-generative-model-raw-audio/
[6] Aaron van den Oord et al.(2016) wavenet: a generative for a raw audio
https://arxiv.org/pdf/1609.03499.pdf
注釈
- PixelCNNの説明画像