はじめに
こんばんわ (おはようございます),
創発システム研究室博士課程1年の長谷川翔一です.
空間の意味理解に関するSemantic Mappingの研究を主にしています.
また最近では,サービスロボット競技会のRoboCup@Homeなどにも出場したりしてます.
(Twitterもやっています.)
基盤モデル×RoboticsのAdventCalendarの17日目では,
「Housekeep:Tidying Virtual Households using Commonsense Reasoning」について紹介します.
論文著者には,Dhruv Batra先生 (Vision and Language Navigation (VLN)でよく使用されるHabitatの著者の一人)がいらっしゃいます.
arxiv:https://arxiv.org/abs/2205.10712
プロジェクトページ:https://yashkant.github.io/housekeep/
※ 本来はもう一本紹介予定でしたが,まとまりが良くなかったため,またの機会に書きます.
※ 投稿が7時間遅れになってしまいました..申し訳ございません...
目次
Housekeepとは
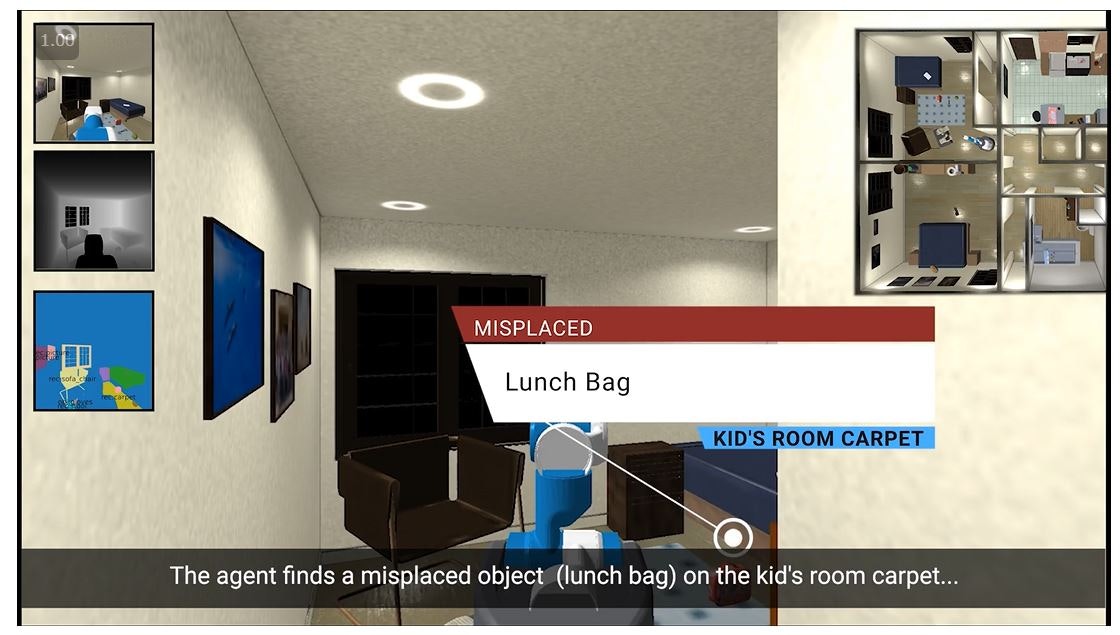
Housekeepは「エージェントを部屋が物で散らかった未知環境へ投入し,明示的な指示無しで,物体を適切な場所へ再配置するタスク」と論文で定義されています.
この論文の何が凄いのか
以下がこの研究のポイントです.
-
シミュレーション環境上で,大規模言語モデルを活用することで,明確な指示を必要とせず,未知環境の未知物体を片付けることが可能.
-
人間の嗜好のサブセットで大規模言語モデルの埋め込みを微調整することで,よく汎化され,新しい物体に対する正しい再配置を推論するのに役立つことを見出した.
大規模言語モデル (Large Language Model, LLM)とは,大規模なコーパスを使用して学習され,単語列が与えられたときに,ある単語の確率分布を与える確率モデルのことです.
基盤モデル (Foundation Model)の中では,言語に特化したモデルのことを指します.基盤モデルの説明は,TRAILの小林聖人先生の記事で説明されているため,ご参照ください.
論文の概要
タスクの仕様
シーンと部屋
・ iGibsonデータセットで提供されている14シーン
・ 17個の部屋のタイプ
・ 1シーンに平均7.5部屋
物の配置場所 (receptacles)
・ 家庭内の家具や家電などの平らな水平面のうち,
物体が置かれている場所をReceptacleと定義
・ 32カテゴリ,395個のReceptacles
物体
以下のデータセットから構成
・ Amazon Berkeley Objects
・ Google Scanned Objects
・ Replica CAD
・ YCB Objects
椅子やテレビなどのサイズが大きい物,ゴミ箱など家庭内であまり移動しないものは除外.
268の物体カテゴリ,1799個の物体を使用.
さらに268の物体カテゴリを文房具,食品,家電など19の高度な意味カテゴリに分類
エージェント
・ Fetch
・ 前進 (0.25m),ベースを左右に10°回転,頭部カメラを上下に10°回転 (ピッチ)の5つ
・ Magic pointer abstraction (Habitatで使用される仮想マウスで画面中の物体を選択したり,前方に光線照射して物体把持が可能かを判定させる方法)
Human Preferences Dataset
Housekeepの中心課題
整理された家と乱雑な家の中で,人間が日常的に使う物体をどのように置くことを好むかを理解すること
Amazonのメカニカルタークを用いて,372人に物体の配置に関する調査をした.
学習用に提供される物体は全体の40%で,残りはエピソードの生成に使用されています.
(Housekeepのエピソード:シーン内に7〜10個の物体を配置し、そのうち3〜5個の物体が誤って配置され,残りは正しく配置されたもの.)
調査方法
参加者に,一つの物体(e.g., 塩入れ)と一つの部屋(e.g., 台所)を見せて (画像と言語),以下に回答してもらいます.
- (Misplaced) 部屋を綺麗にする前は,その物体は「見せた部屋のどの置き場」で見つかるか
- (Correct) 部屋を綺麗にした後は,その物体は「見せた部屋のどの置き場」で見つかるか
- (Implausible) 部屋を綺麗にする前後でも,見つかりそうにない置き場はどこか
またMisplacedとCorrectに関しては,順位付けもしてもらっています.
1回のアノテーションタスクでは,ランダムに抽出された10組の物体と部屋のペアに対して,置き場所を選択し、ランク付けするよう被験者に依頼しています.
1人の参加者が1つのアノテーションタスクを完了するのに要した時間は平均21分,参加者全体で1633時間をかかった記載されています.
以下の動画で,実際にアノテーションをする様子を見ることができます.
アノテーションの品質評価
Fleiss' kappa指標
項目を分類する際の評価者間の一致の信頼性を評価するのに広く用いられる指標
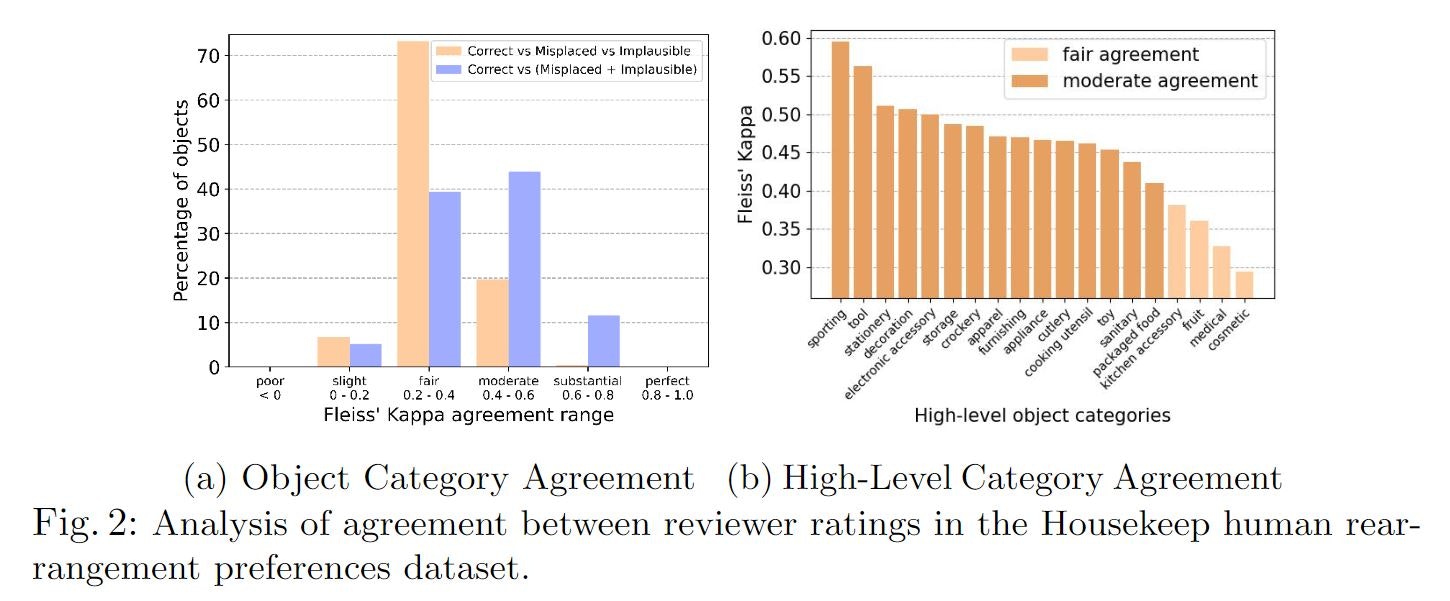
Fig2 aでは,収集したデータの約90%がアノテーター間で,FairからModerate程度の一致を示すことを示しています.
Fig2 bでは,高次の物体カテゴリに対する一致度を示しています.
スポーツ,工具,文房具のカテゴリでは,特定の場所(オフィスのデスク,ガレージなど)に配置されるため,一致率が高いそうです.
一方で,果物,薬,包装された食品などは,人によって置き場所が異なるため,一致率が低くなった報告されています.
モジュール式のベースライン
Housekeepに対処するために,この研究では3つのモジュールを組み合わせ,
ベースラインを構築しています.
構成モジュール群
Exploration and Mapping
・ 環境の探索手法はFrontier-based explorationを使用
・ Semantic Segmentation,Instance Segmentationを活用したMapping
※Segmentationはこの研究のフォーカスでないため,いくつかの前提.
・各画素を物体や容器のクラスに割り当てることができ,
各画素には一意のインスタンスIDが割り当て.
・物体IDと置き場(receptacle)IDが与えられると,
物体が置き場の上に乗ってるかどうかは二値で判定.
・発見された置き場の部屋名を提供するマッピングへのアクセスを仮定.
Navigation and Pick-Place
・ エージェントに地図とゴール位置を入力としたナビゲーション (PointNav)
・ Magic pointer abstraction
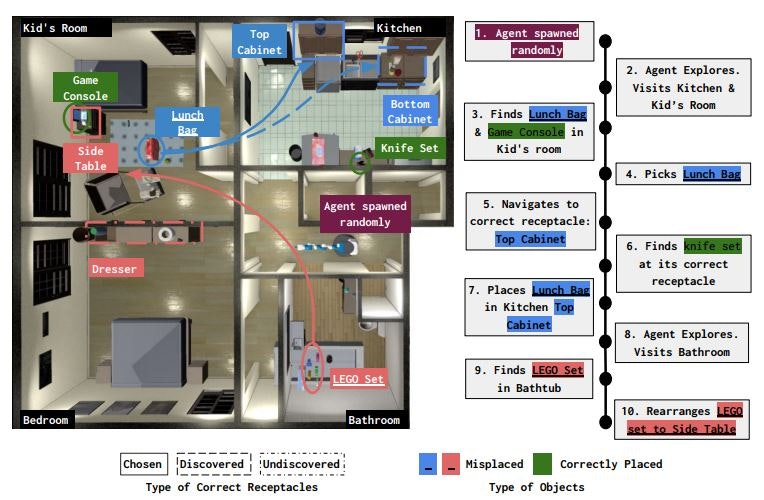
Planning (この研究のメイン)
・ Rearrange submodule
エージェントが発見した物体と置き場の位置を保存し,
物体と置き場のペアのリストを作成し,物体の片付けを行う順番を決める.
・ Ranking submodule
物体-置き場の組の片付けの順番を決めるために,
同時分布$P(receptacle,room | object)$をモデル化し,確率値が最大のものを使う.
・ Planner submodule
物体の片付けをするか環境の探索するかの行動を管理する.
固定されたステップ数($n_e$)の間,探索を行う.
$n_e$が大きいとエピソードの初めは環境の探索をするが,$n_e$が小さいとエージェ
ントがより良い置き場を見つけると,片付けを行うようになる.
置き場所と部屋の同時分布について
モジュール式のベースラインのPlanningでは,物体を片付ける順番を決めるために,
$P(receptacle, room | object)$をモデル化すると説明しました.
この同時分布をこの研究では,
$P(receptacle, room | object) = P(receptacle | room, object) P(room | object)$
と分解できると説明してます.
(Object Room (OR):P(room | object))
(Object Room Receptacle (ORR):P(receptacle | object, room))
これにより著者らは,以下の手順で片付けの手順を決めています.
-
探索中に作成した物体リスト中のどの物体が誤って配置され,正しく配置されたかを決定し,これを分類タスクと捉え,物体と部屋の名前を与えたときのORRのスコアが閾値以上の物体を選択
-
間違った場所にある物体に対する置き場の順位を決めるために,ORで部屋のランク付け
-
ランク付けされた部屋リストにおける物体-部屋のペアについて,その部屋にある正しい置き場をORRでランク付け
-
間違っている置き場のランク付けリストを作成
使用する基盤モデル
使用された基盤モデルは,RoBERTa (Robustly optimized BERT approach)です.
BERTはTransformerのEncoderを使用したモデルで,RoBERTaはBERTに使用されるハイパーパラメータ調整や事前学習用データセットを増やしたものです.
(Transformerの解説記事)
(BERTの解説記事)
(RoBERTaの解説記事)
RoBERTaは事前学習済みのものが使用され,ORとORRの確率スコアを得るために,
物体と置き場をペアにしたテキストの埋め込み表現を抽出しています.
ORとORRを得るために,2種類のアプローチを行っています.
Finetuning by Contrastive Matching (CM)
3層の多層パーセプトロンを言語埋め込み表現の上に配置.
ORRの学習:Constrative Lossを用いてobject-roomの類似を促進するように学習.
ORの学習:バイナリークロスエントロピー誤差を使用
Zero-Shot Ranking via MLM (ZS-MLM)
RoBERTaに使用されるマスク言語モデルを使用し,以下のようなテキストを与え,ORとORRを取得.
ORの場合:
in a household, it is likely that you can find <object> in the room called [mask]
ORRの場合:
in <room>, usually you put <object> <spatial-preposition>[mask]
(spatial-prepositionにはinやonが入る)
実験
実験環境
・ シミュレーション環境にHabitat
・ 使用する物体をseen,val-unseen,test-unseenの3つに分割し,
それぞれには8,2,9個の高次の物体カテゴリが含まれる.
・ 14シーンをtrain (8),val (2),test (4)に分割.
以下のエピソード構成.
train:9000エピソード (seen objects,train scenes)
val-seen:200エピソード (seen objects,val scenes)
val-unseen:200エピソード (unseen objects,val scenes)
test-seen:800エピソード (seen objects, test scenes)
test-unseen:800エピソード (unseen objects,train scenes)
評価項目
再配置の質,効率,探索の3つの観点で評価しています.
再配置の質
・ Episode Success (ES):エピソード内の全て物体が正しく置かれた割合.
・ Object Success (OS):正しく置かれた物体の割合.
・ Soft Object Success (SOS):物体が正しく配置されたことに同意した人の割合.
・ Rearrange Quality (RQ):人間の嗜好から収集した順位付けに基づき,[0,1]の
正規化された値が各object-receptacleに与える.
効率と探索
・ Map Coverage (MC):地図上を探索した割合.
・ Misplaced Object Coverage (MOC):誤った場所にある物体を見つけた割合
・ Pick and Place Efficiency (PPE):必要なPick and Placeの最小数を,そのエピソードでエージェントが行ったPick and Placeの数で割ったもの
実験結果
ORとORRの計算のためにどれが有効か
以下は検証手法です.
・ RoBERTa + CM
・ GloVe + CM
・ ZS-MLM
・ Random
人間のアノテータによって正しいとみなされた部屋-置き場所のリストと,
この研究のランキングモジュールから得た部屋-置き場所のリストを比較するために,
物体間でmAPを評価しています.
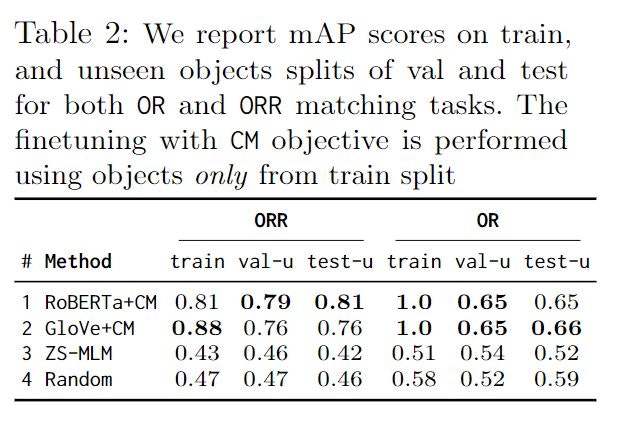
この結果から,RoBERTa + CMの組み合わせが汎化性が良いことを示しています.
Housekeepのシーンで検証
ランキングモジュールにはRoBERTa + CMを使用し,
再配置の順番と探索のそれぞれでOracle Rankerを用いたときと比較しています.
(Oracle Ranker:実際の人間嗜好のデータを用いて発見した物体と置き場所の順位付け.環境の完全な地図を持つ.全ての物体,置き場所の位置を知っている.)
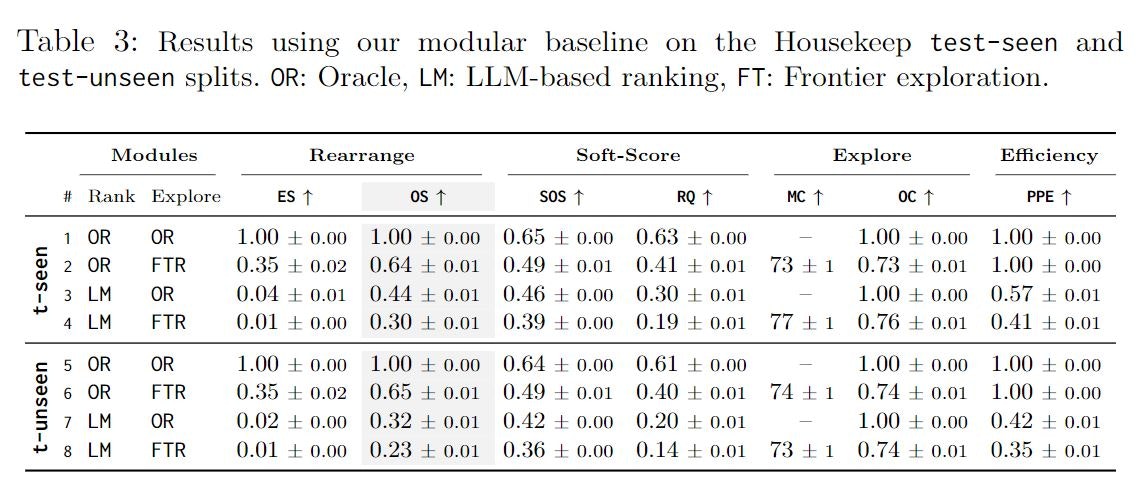
test-seen,test-unseenにおけるLM + FTRの結果から,OSとSOSに関しては,
seenからunseenにうつっても,あまり精度は落ちなかったことが分かります.
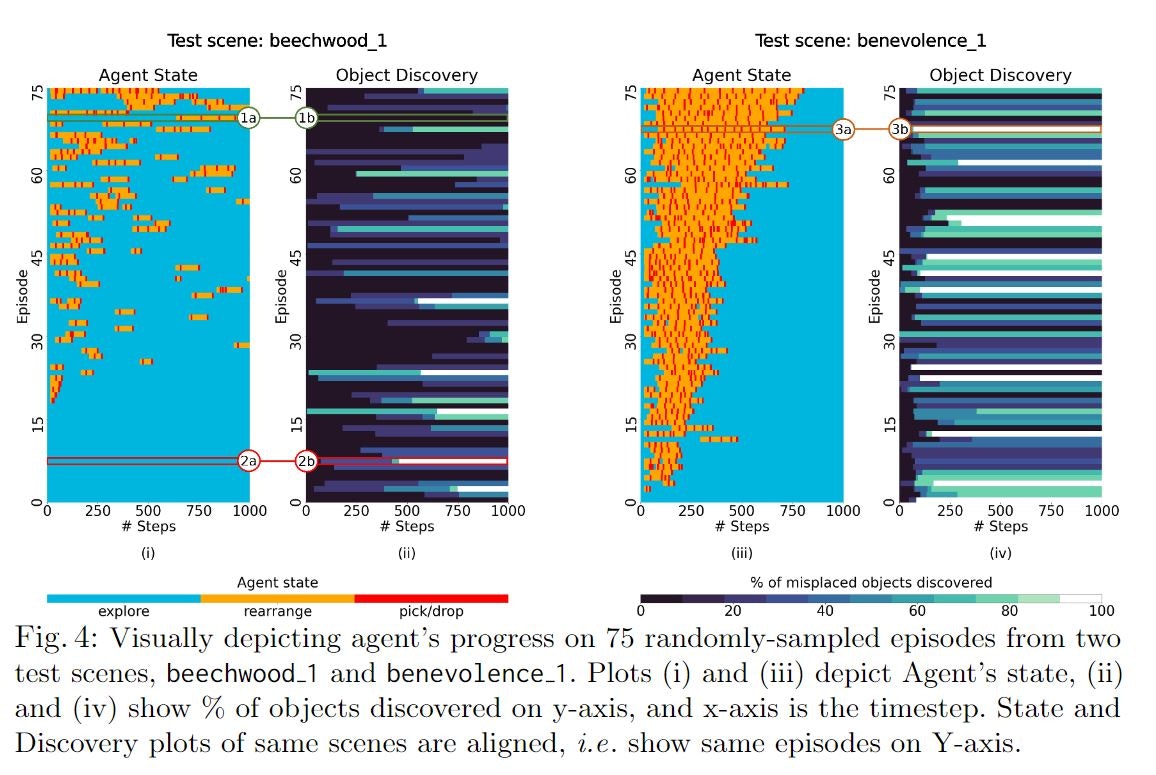
また上のグラフは,2つのtestシーンのエピソードにおけるエージェントの進捗を可視化したものです.
・誤った配置がされた物体があるのに探索 (2a-2b)
・正しく配置された物体の再配置 (1a-1b)
・シーンのレイアウトによって物体の発見に影響 (3a-3b)
と述べられています.
著者らの分析
全体のエピソードにおいて,成功率が低い.
(プランニングや常識推論で必要になるセンサは追加しているが)
-
探索モジュールの改善
学習されたモジュールを使えば,散らかった場所へよく訪れるようになり,地図の範囲ではなく,物体の範囲を最適化できる -
推論モジュールの改善
推論モジュールの適合率と再現率を改善できれば,タスクのパフォーマンスは改善できる -
センサーを学習済みのものに置換する
まとめ
今回は家庭環境の片付けタスクに基盤モデルを活用したHousekeepについて紹介しました.
片付けタスクの研究は人からの指示 (e.g.,コップをキッチンに片付けて)が与えられるケース,
テーブルトップのタスクなど制限された環境で行われることがありますが,Housekeepは大規模なシミュレーション環境で検証されており,挑戦的な研究だと感じました.
タスクの成功率こそは低いですが,test-seenとtest-unseenでタスクの精度があまり変化しなかったのは興味深かったです.
大規模言語モデルに入力するテキストを工夫することで,有用な特徴量を得て,ロボットの空間の意味理解に活用する試みは今後も増えていくのかなと思います.