はじめに
割と素人寄りの人が調べて書いてるので、正しくない情報もあるかもですm(__)m
※追記: 有識者のコメントを反映して、デフォルト値等の記述を一部修正しました。ご指摘ありがとうございます。
2個前くらいの記事で、Proxmoxクラスタを支える「クォーラム(多数決)」の基本的な仕組みについてまとめました。自宅サーバー(Homelab)で便利に使うための「ルール」の話でしたね。
あの記事では「本番環境ならネットワークは冗長化すべき」と軽く触れるに留めていました。
しかし最近、大規模クラスタ(数十ノード)が、一斉に再起動してしまうという恐ろしい現象の原因を深掘り調査する機会がありました。
そこで見えてきたのは、Homelabの感覚ではまったく想像がつかない、Corosyncの時間(タイムアウト)に関する非常に厳格な仕組みと、大規模構成ならではの落とし穴でした。
今回は、この経験をベースに、前回の「ルール」編に続く「仕組み」編として、Corosyncの深いところを掘り下げます。
クラスタはどうやって「死」を検知するのか
前回の記事で、「クォーラムを失うとフェンシング(再起動)される」というルールの話をしました。
では、そもそもどうやって「あいつがクラスタからいなくなった」とか「クォーラムを失った」と判断しているんでしょうか?
今回の調査の核心は、まさにこの「仕組み」の部分でした。
Totemプロトコル - クラスタの神経系
Proxmoxクラスタの裏側では、Totem(トーテム) というプロトコルが動いています。これは、クラスタメンバーシップとメッセージ配信の順序保証を担当する、Corosyncの心臓部です。
Totemは1990年代前半(1991年や1993年)には初期バージョンが発表されていたプロトコルで、トータルオーダードメッセージング(全ノードが同じ順序でメッセージを受信することを保証)を実現しています。
論文抜粋ですがこんな感じ↓ よくわからないですよね
 https://corosync.github.io/corosync/doc/tocssrp95.pdf
https://corosync.github.io/corosync/doc/tocssrp95.pdf
Token Ringの仕組み
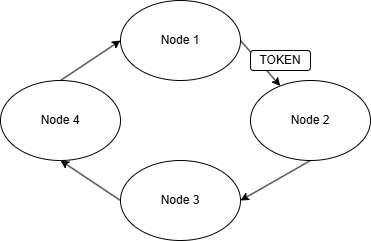
Totemの核心はToken Ringという仕組みです。これは物理的なリング型ネットワークではなく、論理的なリングトポロジーです。
具体的には以下のように動作します:
-
トークンの巡回: クラスタ内で1つの「トークン」が、ノードIDの順序に従って論理的に巡回します。
-
メッセージの送信権: トークンを保持しているノードだけが、クラスタ全体にメッセージを(マルチキャストまたはユニキャストで)送信できます。
-
生存確認: 各ノードは、トークンが定期的に自分のところに戻ってくることで、クラスタ全体が健全であることを確認します。
-
障害検知: トークンが一定時間内に戻ってこない場合、ネットワーク障害またはノード障害が発生したと判断します。
ほんとにざっくりこんな感じ ※図がひどすぎるのでいつかもっといいのに差し替えます。。
この仕組みにより、Totemは以下を実現しています:
- メッセージの順序保証: トークン保持者だけが送信できるため、送信順序が自然に決まる。
- 公平性: すべてのノードが平等にトークンを受け取る。
- 障害検知の確実性: トークンの巡回が止まれば、必ず何かがおかしい。
そして、この「トークンが時間内に戻ってこない」という判断が、厳格なタイムアウト値によって制御されています。これが今回の調査で見えてきた、大規模クラスタが突然再起動する現象の根本的な引き金でした。
クラスタの命綱:「見えない」タイムアウト値
「そんな大事な時間設定、どこで見るの?」と思いますよね。
普通、/etc/pve/corosync.conf を見ます。
root@pve2:~# cat /etc/pve/corosync.conf
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: pve2
nodeid: 3
quorum_votes: 1
ring0_addr: 192.168.100.98
}
# ... (他のノード) ...
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: homelab-cluster
config_version: 22
interface {
linknumber: 0
}
ip_version: ipv4-6
link_mode: passive
secauth: on
version: 2
}
...そう、どこにも書いてないんです。
token なんていう設定、Proxmoxが自動生成するこのファイルには(デフォルトでは)存在しません。
デフォルト値の罠
※2025年10月28日更新: 有識者の方からご指摘をいただき、デフォルト値について修正しました。貴重な情報をありがとうございます!
これが最初の落とし穴でした。corosync.conf に明記されていないパラメータは、Corosyncが内部的に持っている「デフォルト値」 が使われるんです。
Proxmox公式ドキュメントには「クラスタネットワークは5ミリ秒以下のレイテンシが必要」と記載されていますが、その根拠となるタイムアウト値については明示されていません。
現在のCorosyncで使われている「見えないデフォルト値」は、実は以下の通りです:
(A) token: 3000 (ms)
トークンが一周して戻ってくるまでの期待時間(タイムアウト)。デフォルトは3秒(3000ms)です。
(B) token_coefficient: 650 (ms)
重要: 3ノード以上のクラスタでは、実際のtoken値は以下の計算式で自動的に調整されます:
実際のtoken = token + (ノード数 - 2) × token_coefficient
例:3ノードクラスタの場合
実際のtoken = 3000 + (3 - 2) × 650 = 3650 ms(約3.7秒)
この仕組みにより、ノード数が増えてもトークン巡回時間に対して適切なタイムアウト値が自動的に設定されます。
(C) token_retransmits_before_loss_const: 4 (回)
タイムアウトした後、「完全にロストした」と見なすまでの試行回数。デフォルトは4回です。
実際の設定値を確認する方法
現在の設定値は以下のコマンドで確認できます:
# 関連する設定をまとめて確認(推奨)
corosync-cmapctl | grep token
# 実行中のtoken値をピンポイントで確認
corosync-cmapctl runtime.config.totem.token
# 実行中の再送回数を確認
corosync-cmapctl runtime.config.totem.token_retransmits_before_loss_const
ノード数によって、tokenやtoken_retransmitの値が異なることが確認できるはずです。
例:私の4ノードクラスタの場合
私の環境は4ノードクラスタです。上記の計算式に当てはめると、token は以下のようになるはずです。
実際のtoken = 3000 + (4 - 2) × 650 = 4300 ms
そして、これが実際に私の環境で corosync-cmapctl | grep token を実行した結果です↓
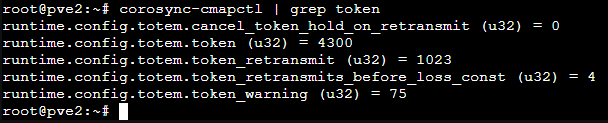
runtime.config.totem.token (u32) = 4300 となっており、計算結果と実行結果が完璧に一致しました。
また、token_retransmits_before_loss_const (u32) = 4 であり、デフォルトの4回が使われていることも確認できました。
フェンシング発動までの猶予時間
実際のtoken値と再送回数から、「ノードが完全に死んだと判断され、フェンシングが発動するまでの、おおよその猶予時間」が計算できます。
フェンシング発動までの猶予 ≒ 実際のtoken × token_retransmits_before_loss_const
私の4ノードクラスタ・デフォルト設定の場合:
4300 ms × 4 回 = 17200 ms = 約17.2秒
つまり、私の4ノードProxmoxクラスタは、corosync.conf には何も書いてなくても、内部的には「トークンの巡回が約17.2秒間(継続的または断続的に)失敗し続けたら、障害と見なし再起動(フェンシング)する」という設定で動いているわけです。
(以前の調査で「約50秒」と想定していましたが、実際のデフォルト設定ではその3分の1以下の、より厳しい時間設定であることが判明しました)
参考:3ノードクラスタ・デフォルト設定の場合:
3650 ms × 4 回 = 14600 ms = 約14.6秒
つまり、3ノードのProxmoxクラスタは、corosync.conf には何も書いてなくても、内部的には「トークンの巡回が約15秒間(継続的または断続的に)失敗し続けたら、障害と見なし再起動(フェンシング)する」 という設定で動いている、というわけです。
(厳密には、token タイムアウトが4回発生するとそのノードはリングから除外され、その結果クォーラムを失うとフェンシングが実行されます)
クラスタサイズと推奨事項
Proxmox VE(PVE)のクラスタノード数には技術的な上限はありませんが、以下の点に注意が必要です:
- Corosyncのtoken値はノード数に比例して自動的に増加(token_coefficientによる調整)
- デフォルト設定での利用は20-25ノード程度までが推奨
- それ以上の大規模クラスタではCorosyncの手動チューニングが必要
これは、token_coefficientによる自動調整だけでは大規模クラスタの複雑な要因(ネットワーク遅延の累積など)に対応しきれないためです。
参考: Proxmox公式でもCorosyncのチューニングガイドを作成予定とのことです。
デフォルト値を疑い、調整する
数十ノードの大規模クラスタや、L3ネットワーク(ルーター)をまたぐような特殊な構成では、デフォルトのtoken_coefficientによる自動調整だけでは不十分な場合があります。
必ず実環境でネットワークの最大遅延を把握し、corosync.conf の totem { ... } ブロックに、token や token_retransmits_before_loss_const の値を明示的に追記して、チューニングする必要があります。
ネットワークレイテンシの測定
# 基本的なping測定
ping -c 100 10.10.10.2
# ジッターを含めた詳細測定(fping推奨)
# -c: 回数, -p: 間隔(ms), -e: 経過時間表示
fping -c 1000 -p 10 -e 10.10.10.2 10.10.10.3 10.10.10.4
# リアルタイムのレイテンシ監視(タイムスタンプ付き)
ping -D 10.10.10.2 | awk '{print strftime("%Y-%m-%d %H:%M:%S"), $0}'
測定のポイント:
- 通常運用時のピークタイム(業務時間帯)に測定
- ストレージ・VM・バックアップなど、すべての負荷をかけた状態で測定
- 最大レイテンシ、平均レイテンシ、ジッター(揺らぎ)を記録
チューニングの指針
測定した最大レイテンシとノード数をもとに、token 値を決定します。厳密な式はありませんが、基本的な考え方は以下です。
token > (トークン巡回にかかる実測最大時間) + 安全マージン
(トークン巡回時間は、(ノード数 × ノード間最大レイテンシ) + 処理時間 でおおよそ見積もれます)
例:10ノードクラスタ、高負荷時のノード間最大レイテンシが5ms の場合:
- トークン巡回時間は 5ms × 10 = 50ms 以上かかると予想
- 安全マージン(予期しない遅延)を多めに見積もり、
token: 2000(2秒) や、デフォルトの自動計算値 (3000 + (10-2) * 650 = 8200 ms) が妥当か、などと判断します
設定例(大規模・高レイテンシ環境向け)
totem {
cluster_name: production-cluster
config_version: 23 # 前の値からインクリメント
# 大規模クラスタ向けの調整値
token: 10000 # 10秒(基本デフォルト3秒の約3倍)
token_retransmits_before_loss_const: 10 # 回数はデフォルトのまま、または増やす
# その他の関連パラメータ
join: 60 # ノード参加タイムアウト(デフォルト: 50ms)
consensus: 12000 # コンセンサスタイムアウト(デフォルト: token * 1.2)
interface {
linknumber: 0
}
interface {
linknumber: 1
}
ip_version: ipv4-6
link_mode: passive
secauth: on
version: 2
}
注意: join や consensus の調整は、token 値との関連性を理解した上で慎重に行う必要があります。
設定変更の手順
Proxmox公式ドキュメントに従って、以下の手順で設定を変更します:
1. バックアップを作成
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak
2. 編集用のコピーを作成
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.new
3. 設定を編集
テキストエディタ(nano/vim 等)で corosync.conf.new を編集します。必ず totem ブロック内に token や token_retransmits_before_loss_const を明示的に追加し、config_version を +1 してください。
例(編集箇所の抜粋):
totem {
version: 2
token: 10000
token_retransmits_before_loss_const: 10
join: 60
consensus: 12000
# ...既存の interface 等...
}
4. 設定を適用
mv /etc/pve/corosync.conf.new /etc/pve/corosync.conf
このファイルは pmxcfs によってクラスタ全ノードへ自動的に同期されます。
5. Corosync を再読み込みして確認
systemctl reload corosync
systemctl status corosync
pvecm status
# 実行中のパラメータ確認
corosync-cmapctl runtime.config.totem.token
corosync-cmapctl runtime.config.totem.token_retransmits_before_loss_const
すべてのノードで新しい設定が反映されるまで数秒〜数十秒かかる場合があります。再読み込み後のメンバーシップ変動に注意してください。
監視とアラート
本番環境では Corosync の健全性を常時監視することが重要です。以下を監視対象にします。
-
トークンの損失(再送)が発生していないか(理想は 0)
- 監視キー例:
corosync-cmapctl runtime.totem.pg.mrp.srp.retransmits - 補足: 健全なクラスタでは、この
retransmitsキー自体が cmap に存在しないことが正常です(キーが存在しない = 再送 0 回)。多くの runtime.* 統計キーは、そのイベントが初めて発生したときに動的に作成されます。
- 監視キー例:
-
メンバーシップの変化
pvecm status
-
ネットワークレイテンシの継続的監視
-
fping -l -D 10.10.10.2(連続監視)
-
-
ログ監視(タイムアウトの兆候)
journalctl -u corosync -f | grep -E "token lost|timeout|retransmit"
典型的な警告サイン:
- "Token has not been received in X ms"
- "Retransmit List: X"
- "Processor failed to receive"
今回の実行例では、ランタイム設定により runtime.config.totem.token (u32) = 4300、runtime.config.totem.token_retransmits_before_loss_const (u32) = 4 が確認できました。よってフェンシング猶予は 4300 ms × 4 回 = 17200 ms(約 17.2 秒)であり、監視はこのスケール感を念頭に行ってください。
こうしたメッセージや retransmits の出現が頻発する場合はネットワーク環境の見直し(専用スイッチ、専用NIC、ボンディング設定等)を行ってください。
Prometheus と Grafana による監視
- prometheus-pve-exporter 等でクラスタ全体の健全性(ノード数、クォーラム状態)を収集できます
- corosync-exporter のような専用エクスポーターを導入すると、トークン再送数や内部統計をダッシュボード化でき、障害の予兆検知に有効です。
おわりに(まとめ)
この記事では、Proxmox クラスタを脅かす「見えない危機」として Corosync のタイムアウト機構を解説し、大規模クラスタで陥りやすい落とし穴と対策を示しました。
要点まとめ:
- 見えないデフォルト値: Proxmox(Corosync)のデフォルト
tokenは 3000 ms。3ノード以上ではtoken_coefficientによって実際のtokenが補正される(例: 3ノード = 3000 + 1×650 = 3650 ms、4ノード = 3000 + 2×650 = 4300 ms)。token_retransmits_before_loss_constのデフォルトは 4 回。 - フェンシング発動の目安: デフォルト設定のままでは小規模クラスタで概ね数十秒ではなく、3ノードで約14.6秒(3650×4)、4ノードで約17.2秒(4300×4)程度でフェンシングに至る可能性があることに注意する。
- 遅延は蓄積する: 単一の長時間停止だけでなく、短時間の遅延が断続的に蓄積して問題となる。
- STP / LACP は罠: スイッチ側の PortFast/Edge や LACP の fast 設定など、本番環境でのネットワーク調整は必須。
- ネットワーク分離は絶対: Corosync 用の専用 NIC / 専用スイッチで低レイテンシ・低ジッターを維持する。
- Knet を活用する: 複数リンクを直接扱える Knet の採用が安定性向上に有効。
- スケールの目安: PVE のクラスタノード数に技術的上限はないが、デフォルト設定のまま運用する場合は概ね 20〜25 ノード程度までが実務上の目安。それ以上は Corosync の明示的チューニングが必要。
Homelab での簡易運用と、本番環境で求められる堅牢性の差を理解することで、不要な停止を防ぐ設計が可能になります。
※割と素人寄りの人が調べて書いてるので、設定変更する際はしっかり調べて納得してから実施くださいm(__)m
参考資料
-
Proxmox VE 公式ドキュメント - Cluster Network
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#pvecm_cluster_network -
Proxmox VE 公式ドキュメント - High Availability
https://pve.proxmox.com/pve-docs/pve-admin-guide.html#ha_manager -
The Totem Single-Ring Ordering and Membership Protocol
Y. AMIR, L. E. MOSER, P. M. MELLIAR-SMITH, D. A. AGARWAL, P. CIARFELLA
University of California, Santa Barbara
https://corosync.github.io/corosync/doc/tocssrp95.pdf