はじめに
なんだかんだBERTを使ったことがなかった。
いまや、自然言語処理といえばBERTの世の中だというのに。
若者でなくなり、流行を追えず、Facebookはやっているが、InstagramやTiktokはやっていない、そんな自分…。
せめて仕事にしているデータ分析の世界では後追いでも流行を追うべきでは?そんな気持ちになった今日この頃。
ということで、事前学習済みモデルを使うとか、そもそも手持ちデータで自分で事前学習するとか、huggingfaceのtransformersでいろいろできるようになっておきたかったので触ってみた。
普通に触るだけでは味気ないので、単語分散表現を抽出し、cos類似度を計算して同義語抽出についてword2vecの結果と比較することに。
WordNetで定義された同義語と同じ単語をいくつ同義語として抽出できるか評価した。
word2vec、Transformer、BERT・・・etcとはなにかといった説明はしない。
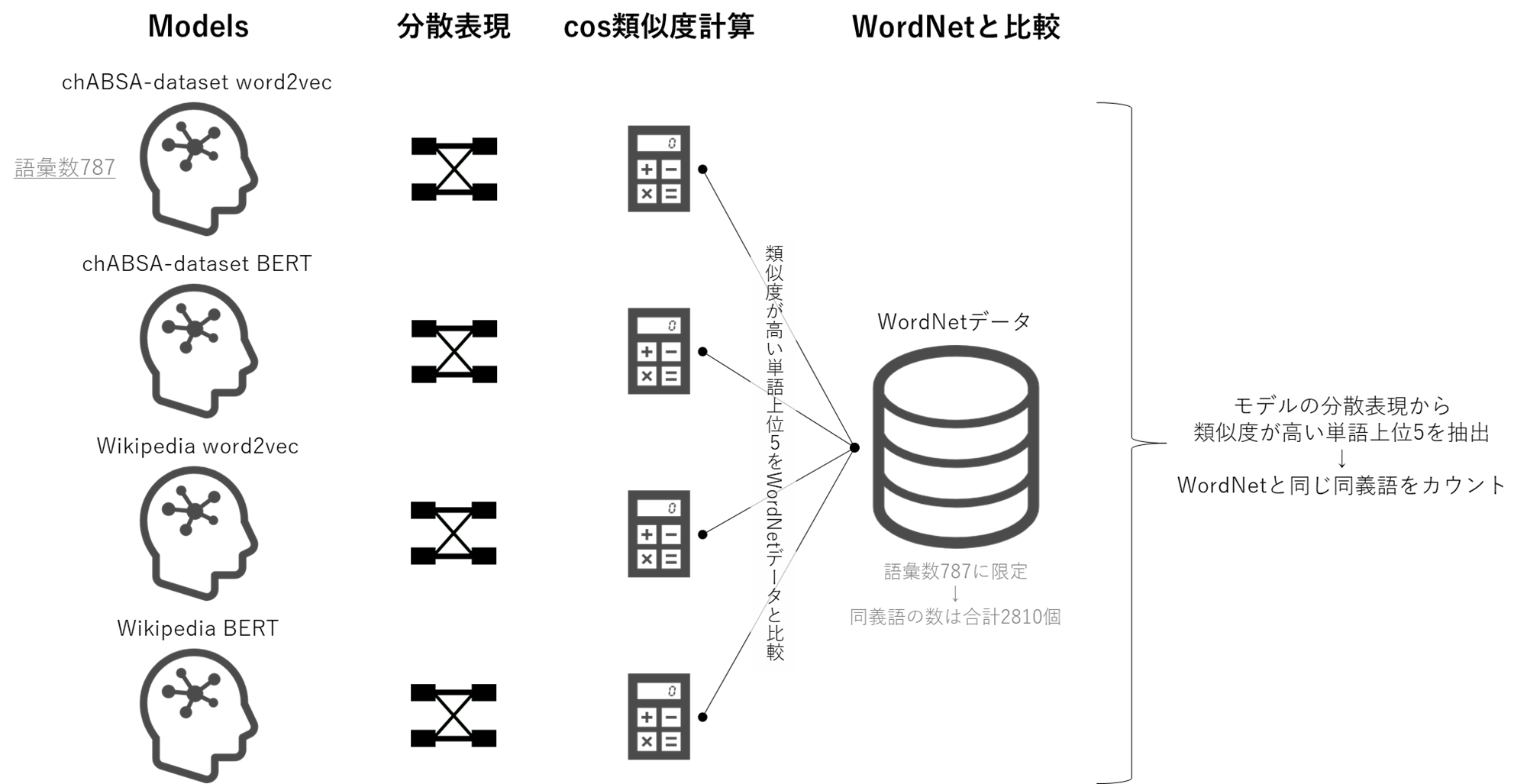
ざっくり概要
まず公開されているchABSA-datasetで学習してword2vecモデル、BERTモデルを作成。
その次に、word2vec、BERTそれぞれのWikipedia学習済みモデルを読み込む。
chABSA-datasetのモデル2つ、Wikipediaのモデル2つ、計4つのモデルについてそれぞれ、分散表現からcos類似度を計算して同義語抽出を実施し、結果をWordNetの同義語と比較することで評価する。
なので、
- chABSA-datasetで学習したword2vecモデル vs BERTモデル
- Wikipediaで学習したword2vecモデル vs BERTモデル
という比較になる。
イメージ図:
参考
先に参考文献を書いておく。
書籍やいろんな方々の記事を参考にした。ありがとうございます!(いろいろ検索しまくったので参考先に漏れがあったら申し訳ございません。)
- [書籍]BERTによる自然言語処理入門: Transformersを使った実践プログラミング(Amazon URL)
- [書籍]BERT/GPT-3/DALL-E 自然言語処理・画像処理・音声処理 人工知能プログラミング実践入門(Amazon URL)
- 自然言語処理の王様「BERT」の論文を徹底解説
- 日本語WordNetを使って、類義語を検索できるツールをpythonで作ってみた
- 日本語WordNetを知る
- 【Python】一行で全角と半角を相互変換する(英字+数字+記号)
- huggingface / transformersを使って日本語BERTの事前学習を実施してオリジナルな言語モデルを作ってみる
- 日本語BERTに新しい単語(ユーザ辞書)を追加してみる
- huggingfaceでの自然言語処理事始めBERT系モデルの前処理方法
- huggingface Transformers公式
使用データ
word2vecの学習やBERTの学習には、chABSA-datasetを使用した。
chABSA-datasetは上場企業の有価証券報告書(2016年度)をベースに作成されたデータセット。
(例:sentence_id:0 → 当連結会計年度におけるわが国経済は、政府の経済政策や日銀の金融緩和策により、企業業績、雇用・所得環境は改善し、景気も緩やかな回復基調のうちに推移いたしましたが、~~以下略)
使用PCがGPUなしの雑魚雑魚の環境なので、データ量がWikipediaのように膨大ではないchABSA-datasetを選んだ。
学習済みのモデルはword2vecもBERTも日本語Wikipediaのデータを使ったものを活用。
BERTの学習済みモデルは東北大学が公開しているものをTransformersライブラリから使用。
東北大学 乾研究室, huggingface:bert-base-japanese
word2vecの学習済みモデルも東北大学が公開しているものをダウンロードし、gensimライブラリで読み込んで使用。
日本語 Wikipedia エンティティベクトル
同義語の定義はWordNetで定義されたものを使用。
日本語 WordNetのsqlite3 databaseをダウンロードした。
Japanese Wordnet and English WordNet in an sqlite3 database
ストップワードはslothlibのJapanese.txtを使用。
前処理
まず使用するパッケージをimport
import numpy as np
import pandas as pd
import sqlite3
import json
import glob
import gensim
import tqdm as tq
from tqdm import tqdm
import scipy
import gc
import pickle
import os
import collections
import string
import re
import MeCab
import gensim
from gensim.models import word2vec
from gensim.models import KeyedVectors
import torch
from transformers import BertJapaneseTokenizer, BertModel, BertForMaskedLM
from transformers import BertConfig
from transformers import BertForMaskedLM
from transformers import DataCollatorForLanguageModeling
from transformers import LineByLineTextDataset
from transformers import TrainingArguments
from transformers import Trainer
import datasets
print('pytorch', torch.__version__)
print('transformers', transformers.__version__)
print('gensim', gensim.__version__)
# pytorch 1.12.0+cpu
# transformers 4.20.1
# gensim 4.1.2
chABSA-datasetのデータの確認。
# ファイル一覧
data_dir = "bert_test/chABSA-dataset"
path_list = glob.glob(data_dir+'/*.json')
print("jsonファイル数 ",len(path_list))
# jsonファイル数 230
# json確認
with open(path_list[0], "br") as f:
j = json.load(f)
sentences = j["sentences"]
print("1ファイル目のデータ数:", len(sentences))
print("sentences:", sentences)

chABSA-datasetのデータをすべて読み込んでsentence_idとsentenceを抽出してデータフレームに格納。
# idと文章のdf作成
def makeSentenceDf(path_list):
sentenceDf = pd.DataFrame()
for file in tqdm(path_list):
with open(file, "br") as f:
j = json.load(f)
sentences = j["sentences"]
idsList = []
sList = []
for obj in sentences:
ids = obj["sentence_id"]
s = obj["sentence"] #文章
sList.append(s)
idsList.append(ids)
tmp = pd.DataFrame({'sentence_id':idsList, 'sentence':sList})
sentenceDf = pd.concat([sentenceDf, tmp])
return sentenceDf.reset_index(drop=True)
# df作成
sentenceDf = makeSentenceDf(path_list[:])
display(sentenceDf.head())

文字の小文字化、記号・丸囲い数字の除去、全角を半角に変更するなど、前処理を実施。
前処理した文をデータフレームの新たな列に入れる。
# 丸囲い数字のコード取得
def get_marumoji(val):
# ①を文字コードに変換[bytes型]
maru_date = "①".encode("UTF8")
# ①を文字コードに変換[int型]
maru_code = int.from_bytes(maru_date, 'big')
# 文字コードの変換
maru_code += val - 1
# 文字コードを文字に変換して返却
return maru_code.to_bytes(4, "big").decode("UTF8")[1]
# 小文字化、記号・丸囲い数字除去、全角を半角など前処理関数
def preprocessing(text):
text = text.lower() # 小文字化
text = re.sub('\r\n','',text) # \r\nをdelete
text = re.sub(r'\d+','',text) # 数字列をdelete
ZEN = "".join(chr(0xff01 + i) for i in range(94)) # 全角文字列一覧
HAN = "".join(chr(0x21 + i) for i in range(94)) # 半角文字列一覧
ALL=re.sub(r'[a-zA-Za-zA-Z\d]+','',ZEN+HAN)
code_regex = re.compile('['+'〜'+'、'+'。'+'~'+'*'+'*'+ALL+'「'+'」'+']')
text = code_regex.sub(' ', text) # 記号を消す
maru_int = []
for i in range(1,100):
try:
tmp = get_marumoji(i)
maru_int.append(tmp)
except UnicodeDecodeError:
'UnicodeDecodeError, Skip a processing'
code_regex = re.compile('['+"".join(i for i in maru_int)+']')
text = code_regex.sub(' ', text) # 丸囲い数字を消す
ZEN = "".join(chr(0xff01 + i) for i in range(94))
HAN = "".join(chr(0x21 + i) for i in range(94))
ZEN2HAN = str.maketrans(ZEN, HAN)
HAN2ZEN = str.maketrans(HAN, ZEN)
text=text.translate(ZEN2HAN) # 全角を半角に
return text
# 前処理した文章をdfの新たな列に入れる
sentenceDf['preprocessingSentence'] = [preprocessing(text) for text in sentenceDf['sentence']]
sentenceDf = sentenceDf[sentenceDf['preprocessingSentence'].apply(lambda x:len(x)>0)] # 何もない行は消す
display(sentenceDf.head())

Mecabで分かち書きをする関数。
今回、辞書はNeologdを使っている。
分かち書きした結果がリストで返ってくる。
ストップワードも定義。
# Mecabで分かち書きする関数
def wakachi(text, select_word_type=['名詞']):
# MeCabの準備
tagger = MeCab.Tagger()
tagger.parse('')
node = tagger.parseToNode(text)
word_list = []
while node:
word_type = node.feature.split(',')[0]
if word_type in select_word_type: # 指定した品詞のみ処理
if word_type == '名詞':
word_list.append(node.surface)
else:
word_list.append(node.feature.split(",")[6])
else:
pass
node = node.next
# リストを文字列に変換
word_chain = ' '.join(word_list)
if len(word_list)==0:
'no list!'
return word_list, word_chain # リストでまとめた結果とすべてつなげた文字列を返す
# dfでまとめた文章をすべて分かち書き処理する関数
def makeWakachiDf(sentenceDf, col, stop_words, select_word_type=['名詞']):
word_list_noun_list = []
word_chain_noun_list = []
for i, text in tqdm(enumerate(sentenceDf[col])): # 指定した列にある文章を1行ずつ分かち書き処理
word_list_noun, word_chain_noun = wakachi(text, select_word_type=select_word_type)
word_list_noun = [w for w in word_list_noun if w not in stop_words] # ストップワードも設定
if len(word_list_noun)==0: # 分かち書きとストップワード除去で何もなかった場合何もない結果を追加
word_list_noun_list.append([])
word_chain_noun_list.append('')
continue
word_list_noun_list.append(word_list_noun) #分かち書きとストップワード除去の結果を追加
word_chain_noun_list.append(word_chain_noun) #分かち書きとストップワード除去の結果を追加
return word_list_noun_list, word_chain_noun_list # リストでまとめた結果とすべてつなげた文字列をリストにまとめて返す
# ストップワードを定義
with open('bert_test/Japanese.txt', 'r', encoding='utf-8') as f:
stop_words = [w.strip() for w in f]
stop_words = stop_words+['する', 'なる', 'いる', 'ある']
stop_words = set(stop_words)
print(list(stop_words)[:10])
分かち書きの関数を適用してデータフレームに列を追加する。
今回は分かち書きして残す単語は名詞だけにした。
# dfでまとめた文章をすべて分かち書き処理
word_list_noun_list, word_chain_noun_list = makeWakachiDf(sentenceDf, 'preprocessingSentence'
, stop_words, select_word_type=['名詞']) # 今回は名詞だけ
# 分かち書き処理の結果をdfに追加
sentenceDf['wakachiSentenceList'] = word_list_noun_list
sentenceDf['wakachiSentenceChain'] = word_chain_noun_list
# 分かち書き処理の結果、空のリストの行を削除
sentenceDf = sentenceDf[sentenceDf['wakachiSentenceList'].apply(lambda x:len(x)>0)].reset_index(drop=True)
display(sentenceDf.head())

これでざっくり前処理は終了。
データフレームの'wakachiSentenceList'列はword2vec学習時に使用し、'preprocessingSentence'列はBERT学習時に使用する。
モデル定義
以下4つのモデルを定義していく。
- chABSA-datasetで学習したword2vecモデル
- chABSA-datasetで学習したBERTモデル
- Wikipedia学習済みword2vecモデル
- Wikipedia学習済みBERTモデル
chABSA-dataset Word2Vecの学習
前処理は終わらしたのでgensimでさくっとword2vecモデル学習。
%%time
# gensimでWord2Vecモデル作成
# vector_size : output dimention
# min_count : この値以下の出現回数の単語を無視
# window : 対象単語を中心とした前後の単語数
# epochs : epochs数
# sg : skip-gramを使うかどうか 0:CBOW 1:skip-gram
wv_model = word2vec.Word2Vec(sentenceDf['wakachiSentenceList'].to_numpy()
, vector_size=200, min_count=5, window=5, sg=1)
# モデルの学習
wv_model.train(sentenceDf['wakachiSentenceList'].to_numpy(), total_examples=wv_model.corpus_count, epochs=20)
vocab = wv_model.wv.index_to_key # 分かち書きした語彙
print(vocab[:5])
# > ['事業', '年度', '連結会計', '百万円', '売上高']
# > Wall time: 3.19 s
chABSA-dataset BERTの学習(MaskedLM)
BERTの学習はマスクされた単語を予測するタスクであるMaskedLMによって実施。
例えば以下の文、
当 連結会計 年度 に おける わが国 経済 は~~
これの一部をマスクし、以下のようにする。
当 連結会計 [MASK] に おける わが国 経済 は~~
この[MASK]に入るトークンを語彙の中から予測できるようにモデルを学習する。
MaskedLMでは、教師データを用意する必要がなく、自身のテキストをマスクすることによって学習できるので、BERTの事前学習のタスクとしてよく用いられている。
まず、モデルの学習の前に分かち書きやトークンid化を行うためのTokenizerを用意する必要がある。
東北大学が公開しているWikipedia学習済みTokenizerを読み込み、chABSA-datasetにある語彙をTokenizerに追加する。
追加する語彙はMecab Neologdで分かち書きされた名詞の単語である。
これにより語彙数が32000から37138に増加し、Tokenizerによる分かち書きの結果も、['連結', '会計'] → ['連結会計']のように、一部変化する。(['わが', '##国'] → ['わが国']のようにサブワードではなく単語に分割されるものも出てくる)
# 東北大学の学習済みTokenizerを使用する
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
# 東北大学の学習済みTokenizer読み込み
tokenizerOrg = BertJapaneseTokenizer.from_pretrained(model_name)
text_example = "当連結会計年度におけるわが国経済は 政府の経済政策や日銀の金融緩和策により 企業業績 雇用・所得環境は改善"
print(len(tokenizerOrg)) # トークンの数
print(tokenizerOrg.tokenize(text_example)) # 例文をトークンに分割
# chABSA-datasetをMecabで分けた結果の語彙をtokenizerに追加
addVocab = ' '.join(sentenceDf['wakachiSentenceChain'].to_list()).split(' ')
tokenizerOrg.add_tokens(addVocab)
print(len(tokenizerOrg)) # トークンの数
print(tokenizerOrg.tokenize(text_example)) # 例文をトークンに分割
tokenizerOrg.save_pretrained("bert_test/qiita_bert_token/") # Save
# 注意:tokenizerOrg.vocab_sizeはOriginalのサイズを出力し、追加しても変わらないので注意(issue#4486)

次に、モデルの構造を定義するBertConfigを設定する。語彙数が増えたので語彙数の設定だけを変更し、あとはデフォルトの設定を使用。モデルはMaskedLMタスクで学習するので、BertForMaskedLMでモデルを宣言する。
# モデルの構造を定義するBertConfigを設定
config = BertConfig(vocab_size=len(tokenizerOrg)) # 語彙数だけ設定してあとはデフォルト
print(config)
bertModel = BertForMaskedLM(config) # MaskedLMタスクで学習
次に、DataCollatorForLanguageModelingによってテキストのマスク処理の内容を定義する。
マスク処理では、ランダムに選ばれた15%のトークンをある確率で[MASK]という特殊トークンに置き換える。ある確率とは、"MASKに置き換え:80%", "ランダムに他のトークンに変更:10%", "何も変更しない:10%"である。
この処理により、すべてをマスクに置き換えることに比べて、個別でのタスクの性能が上がることがわかっている。
# DataCollatorはいくつかの処理(パディングなど)を適用する
# DataCollatorForLanguageModelingなどは、形成されたバッチにランダムデータ拡張(ランダムマスキングなど)も適用
# ランダムに選ばれた15%のトークンを[MASK]という特殊トークンに置き換え、[MASK]にもともとあったトークンを予測するタスクで学習
# ただし、右のような確率でマスクする:80% MASK, 10% ランダムに他のトークンに, 10% 何も変更しない.
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizerOrg, mlm=True, mlm_probability=0.15)
次に、学習するテキストをtxtファイルで保存しておく。このtxtファイルを読み込んで学習する。
# 学習するテキストをtxtファイルで保存しておく
display(sentenceDf['preprocessingSentence'].head(2))
sentenceDf['preprocessingSentence'].to_csv('bert_test/preprocessingSentence.txt', index=False, header=False)

次に、文書の最大長を定義。
# 1文書の最大長を定義
#with open('bert_test/preprocessingSentence.txt', encoding='utf-8') as f:
# max_length = np.max([len(tokenizerOrg(line)['input_ids']) for line in f])
max_length = np.max([len(line) for line in tokenizerOrg(list(sentenceDf['preprocessingSentence'].to_numpy()))['input_ids']])
print('max length', max_length)
# > max length 166
次に、LineByLineTextDatasetでMaskedLMタスクで学習させるためのdatasetに加工する。tokenizerはchABSA-datasetにある語彙を追加したTokenizerを指定、file_pathで先ほど保存したtxtファイルを指定、block_sizeは文書の最大長max_lengthを指定。
# MaskedLMタスクで学習させるためのdatasetに加工
textDataset = LineByLineTextDataset(tokenizer=tokenizerOrg # 使用するtokenizer
, file_path='bert_test/preprocessingSentence.txt' # 学習するテキスト
, block_size=max_length, # tokenizerのmax_length
)
TrainingArgumentsで事前学習に関するパラメータを設定し、Trainerで事前学習するインスタンスを作成。
Trainerクラスは、PyTorchで学習させるためのAPIを提供していて、基本的なトレーニングループを含んでいる。
なので以下のように学習モードに切り替えてループで学習させるといったコードを書く必要がなくなる。
# こんな感じで書かなくてよい
model.train() # 学習モードに切り替え
for data, target in datasets:
data, target = Variable(data), Variable(target)
・・・
・・・
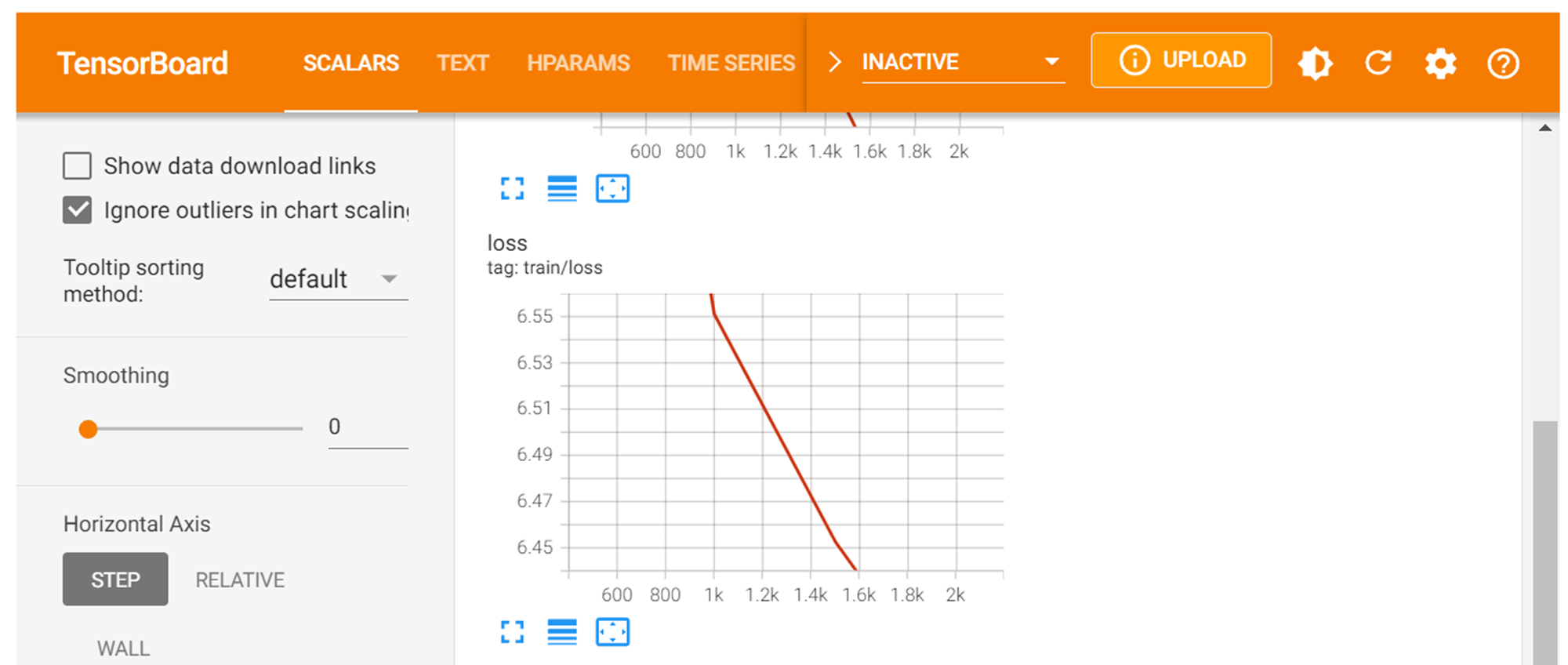
雑魚雑魚環境なので、epoch数は小さく、learning_rate(デフォルト5e-5)は大きめにした。
それでも学習に3h 25min 33sかかった…。しかも全然収束していない(笑)。
# 事前学習に関するパラメータを設定
trainingArguments = TrainingArguments(output_dir= 'bert_test/'
, overwrite_output_dir=True
, num_train_epochs=3 # CPUなので少なめ
#, per_device_train_batch_size=32
#, save_steps=200
#, save_strategy='steps'
#, do_eval=True # 評価データを用意する必要がある
#, eval_steps=200 # 評価データを用意する必要がある
#, evaluation_strategy='steps' # 評価データを用意する必要がある
#, load_best_model_at_end=True # 評価データを用意する必要がある
, logging_dir='bert_test/qiita_bert/'
, save_total_limit=3
, prediction_loss_only=True
, learning_rate=1e-3, # CPUなので大きめ
)
# 事前学習するインスタンス作成
trainer = Trainer(model=bertModel
, args=trainingArguments
, data_collator=data_collator
, train_dataset=textDataset
)
%%time
trainer.train()
trainer.save_model('bert_test/qiita_bert/')
# > 3h 25min 33s
%load_ext tensorboard
%tensorboard --logdir 'bert_test/qiita_bert/runs/' --host=127.0.0.1
まあとりあえずモデルはできたので、最後の隠れ層から分散表現を抽出する。
保存したBERTモデルを読み込み、tokenizerで前処理済みの文書を分かち書き & idに変換。
# 保存したBERTモデルを読み込み
bertModel = BertForMaskedLM.from_pretrained('bert_test/qiita_bert/')
# 前処理済みの文章をtokenizerでidに変換
encoded = tokenizerOrg.batch_encode_plus(sentenceDf['preprocessingSentence'].to_list()
, padding=True
, add_special_tokens=True) # [CLS]のようなspecial tokenも含む
print(encoded.keys())
print(len(encoded['input_ids'][0])) # input_idsの1文書の長さ
# BERTトークンID列を抽出
input_ids = torch.tensor(encoded['input_ids'])[:,:]
print(input_ids.shape) # input_idsの型 文書数×1文書の長さ
# > dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
# > 166
# > torch.Size([6099, 166])
最後の隠れ層の分散表現は、モデル推論時のoutput_hidden_states=Trueにして、'hidden_states' keyの最後の配列を取り出せばいい。
すべてのデータを一気に処理するとMemory errorにより出力できなかったので、1文書ずつモデルに適用していった。(1h 36min 21sかかった…。)
%%time
# 分散表現抽出
# 一気に処理するとMemory errorになるのでループで1行づつ抽出
last_hidden_states = torch.Tensor()
for inid in tqdm(input_ids[:]):
bertModel.eval()
with torch.no_grad(): # 勾配計算なし
# 単語ベクトルを計算
outputs = bertModel(inid.reshape(1,-1), output_hidden_states=True) # 隠れ層の出力もさせる
last_hidden_states = torch.cat((last_hidden_states, outputs['hidden_states'][-1])) # 最後の隠れ層ベクトルを抽出
print(last_hidden_states.shape)
# > torch.Size([6099, 166, 768])
# > 1h 36min 21s
抽出した分散表現などを保存。
# 最後の隠れ層ベクトルsave
torch.save(last_hidden_states, 'bert_test/last_hidden_states01.pt')
# input_idsもsave
with open("bert_test/encoded01.pkl", "wb") as tf:
pickle.dump(encoded, tf)
# tokenizersave
tokenizerOrg.save_pretrained('bert_test/tokenizer01')
Wikipedia学習済みword2vecモデル
Wikipedia学習済みword2vecモデルをLoad。
%%time
# Wikipediaで学習されたモデルをLoad
model_dir = 'bert_test/entity_vector/entity_vector.model.bin'
wv_modelPre = KeyedVectors.load_word2vec_format(model_dir, binary=True)
index2wordPre = wv_modelPre.index_to_key # Wikipediaの語彙数
Wikipedia学習済みBERTモデル
Wikipedia学習済みBERTモデルとtokenizerをLoad。
# 東北大学の学習済みmodelを使用する
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
# トークナイザーの読み込み
tokenizerPre = BertJapaneseTokenizer.from_pretrained(model_name)
# 学習済みモデルの読み込み
bertModelPre = BertModel.from_pretrained(model_name)
前処理済みの文書をTokenizerで分かち書きやトークンid化を実施。
# 東北大学の学習済みTokenizerで分かち書き
encoded = tokenizerPre.batch_encode_plus(sentenceDf['preprocessingSentence'].to_list(), padding=True, add_special_tokens=True)
print(encoded.keys())
print(len(encoded['input_ids'][0])) # input_idsの1文書の長さ
# 学習済みBERTトークンID列を抽出
input_ids = torch.tensor(encoded['input_ids'])[:,:]
print(input_ids.shape) # input_idsの型 文書数×1文書の長さ
# > dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
# > 258
# > torch.Size([6099, 258])
分散表現を抽出。
最後の隠れ層の分散表現は、'last_hidden_state' keyが存在するのでそれを取り出せばいい。
すべてのデータを一気に処理するとMemory errorにより出力できなかったので、1文書ずつモデルに適用していった。(2h 10min 46sかかった…。)
%%time
# 分散表現抽出
# 一気に処理するとMemory errorになるのでFor文で1行づつ抽出
last_hidden_statesPre = torch.Tensor()
for inid in tqdm(input_ids[:]):
with torch.no_grad(): # 勾配計算なし
# 単語ベクトルを計算
outputs = bertModelPre(inid.reshape(1,-1), output_hidden_states=True)
last_hidden_statesPre = torch.cat((last_hidden_statesPre, outputs.last_hidden_state))
# 最終層の隠れ状態ベクトルを取得
print(last_hidden_statesPre.shape)
# 最後の隠れ層ベクトルsave
torch.save(last_hidden_statesPre, 'bert_test/last_hidden_states02.pt')
# > torch.Size([6099, 258, 768])
# > 2h 10min 46s
WordNetの同義語取得
WordNetのデータから同義語を抽出する。
db形式でダウンロードしているので、sqlite3でデータを抽出する。
まずDBに接続。
# WordNet DBと接続
conn = sqlite3.connect("bert_test/wnjpn.db")
テーブルの一覧を確認。
使うテーブルはword, sense, synset, synlink, synset_defの5つ。
# Table一覧取得
tableDf=pd.read_sql_query(
"""
select
name
from
sqlite_master
where
type='table'
"""
, conn
)
display(tableDf)

それぞれのテーブルからデータを抽出し、紐づけて、同義語のマスタデータフレームを作る。
# wordidと単語一覧Table
# 日本語に限定
wordDf=pd.read_sql_query(
"""
select
*
from
word
"""
, conn
)
wordDf = wordDf[wordDf['lang']=='jpn']
display(wordDf.head())
# 日本語の概念(上位語、被包含領域など)を表すsynsetとwordidを紐づけるためのTable
senseDf=pd.read_sql_query(
"""
select
*
from
sense
"""
, conn
)
senseDf = senseDf[senseDf['lang']=='jpn']
display(senseDf.head())
# synsetの一覧Table
synsetDf=pd.read_sql_query(
"""
select
*
from
synset
"""
, conn
)
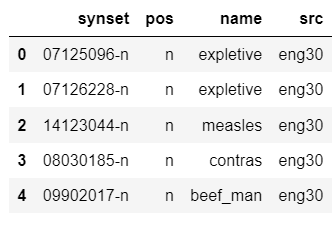
display(synsetDf.head())
# 日本語の概念の関係の定義Table
synlinkDf=pd.read_sql_query(
"""
select
*
from
synlink
"""
, conn
)
display(synlinkDf.head())
# 概念の例文の定義Table
synset_defDf=pd.read_sql_query(
"""
select
*
from
synset_def
"""
, conn
)
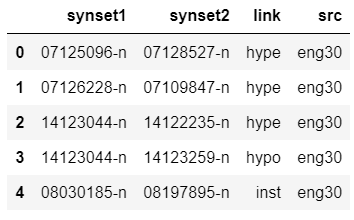
synset_defDf = synset_defDf[synset_defDf['lang']=='jpn']
display(synset_defDf.head())

↑これらを紐づける。
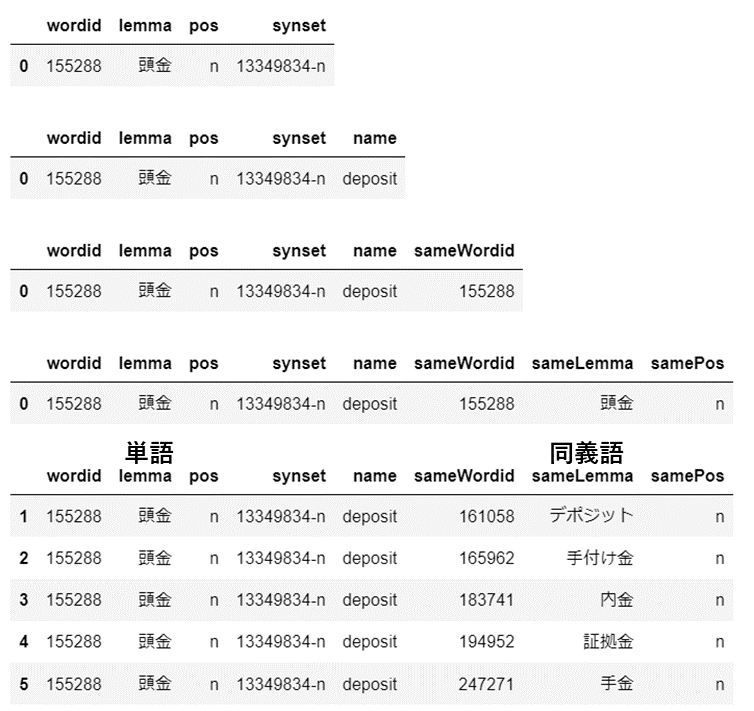
紐づけた結果のマスタはwordid, lemma, pos, synset, name, sameWordid, sameLemma, samePosの列があるデータとなる。
# 各テーブルを紐づける
# 各wordidにsynsetを追加
wordMaster = pd.merge(wordDf[['wordid', 'lemma', 'pos']], senseDf[['wordid', 'synset']], on=['wordid'], how='left')
display(wordMaster.head(1))
# 各synsetにnameを追加
wordMaster = pd.merge(wordMaster, synsetDf[['synset', 'name']], on=['synset'], how='left')
display(wordMaster.head(1))
# 各synsetに対応するwordidを追加
wordMaster = pd.merge(wordMaster, senseDf[['wordid', 'synset']].rename(columns={'wordid':'sameWordid'}), on=['synset'], how='left')
display(wordMaster.head(1))
# 各synsetに対応するwordidに対応するlemmaを追加
wordMaster = pd.merge(wordMaster
, wordDf[['wordid', 'lemma', 'pos']].rename(columns={'wordid':'sameWordid', 'lemma':'sameLemma', 'pos':'samePos'})
, on=['sameWordid'], how='left')
display(wordMaster.head(1))
# もともとのwordidと各synsetに対応するwordidが同じ行は削除
wordMaster = wordMaster[wordMaster['wordid']!=wordMaster['sameWordid']]
display(wordMaster.head())
(もしくは普通にSQLだけで抽出)
wordMaster =pd.read_sql_query(
"""
select
wordid
, lemma
, pos
, lang
, synset
, name
, t_merge02.sameWordid as sameWordid
, sameLemma
, samePos
from
(
select
t_merge01.wordid as wordid
, lemma
, pos
, lang
, t_merge01.synset as synset
, name
, sameWordid
from
(
select
t_word.wordid as wordid
, lemma
, pos
, lang
, synset
from
(
select
wordid
, lemma
, pos
, lang
from
word
where
lang='jpn'
) as t_word
left join
(
select
wordid
, synset
from
sense
where
lang='jpn'
) as t_sense
on
t_word.wordid = t_sense.wordid
) as t_merge01
left join
(
select
synset
, name
from
synset
) as t_synset
on
t_merge01.synset = t_synset.synset
left join
(
select
wordid as sameWordid
, synset
from
sense
where
lang='jpn'
) as t_sense02
on
t_merge01.synset = t_sense02.synset
) as t_merge02
left join
(
select
wordid as sameWordid
, lemma as sameLemma
, pos as samePos
from
word
where
lang='jpn'
) as t_word02
on
t_merge02.sameWordid = t_word02.sameWordid
where
wordid<>t_merge02.sameWordid
"""
, conn
)
display(wordMaster.head())
同義語抽出の評価
同義語のマスタデータフレームである、wordMasterから、最初に学習したword2vecに含まれる語彙だけを抜き出しwordMasterPartデータフレームを作る。
今回は、そのデータフレームwordMasterPartの同義語と同じものを、モデルは分散表現から抽出できるのか、答え合わせを行う。
wordMasterPartのすべての単語787個において、同義語の数は合計2810個ある。
このうちいくつの同義語をモデルは抽出できるのか、数をカウントして多い方が良い精度と定義する。
chABSA-dataset Word2Vec評価
ではさっそくchABSA-dataset word2vecで各単語と類似度が高い単語上位5を抽出し、WordNetの同義語と比較。
gensimはmodel.wv.most_similar()で簡単に出せる。
いくつか同義語を抽出できていたが、結果は、正解数 79 / 2810だった。
まあchABSA-datasetだと厳しい気がしていたけど、その通りでしたって感じ。
# Word2Vec学習時に定義した語彙のリスト vocabに出てくる単語を評価対象にする
# 同義語抽出評価
sameWordsCnt = 0 # 初期値 同義語の数
# vocabに出てくる単語に限定
wordMasterPart = wordMaster[(wordMaster['lemma'].isin(list(vocab)))&(wordMaster['sameLemma'].isin(list(vocab)))]
# vocabに出てくる単語に限定した後のWordNetの同義語の数
allSameWordsCnt = wordMasterPart[['lemma', 'sameLemma']].drop_duplicates().shape[0]
print('限定したWordNetの語彙数', wordMasterPart['lemma'].unique().shape[0])
print('限定したWordNetの単語にあるすべての同義語の数', allSameWordsCnt, '\n')
# 限定したWordNetの単語ごとの同義語についてモデルがいくつ同じ同義語を抽出できているかカウントする
for i, tango in enumerate(wordMasterPart['lemma'].unique()):
# tango=WordNetの単語1つずつループ
# tangoに最も似ている単語Top5をdfにまとめる
w2vCosDf = pd.DataFrame(wv_model.wv.most_similar(tango), columns=['sameLemma', 'cos'])
w2vCosDf.insert(0, 'lemma', tango)
# 限定したWordNetと紐づける
mergeDf = pd.merge(wordMasterPart[wordMasterPart['lemma']==tango][['lemma', 'sameLemma']].drop_duplicates()
, w2vCosDf, on=['lemma', 'sameLemma'], how='inner')
# 紐づけたdfの結果
if len(mergeDf) > 0:
print(tango)
display(mergeDf)
print('===============', '\n')
sameWordsCnt += len(mergeDf) # 紐づけられた同義語の数を足す
# 最終的な正解数
print('正解数', str(sameWordsCnt), '/', allSameWordsCnt)
# > 正解数 79 / 2810

chABSA-dataset BERT評価
続いて、chABSA-dataset BERTで各単語と類似度が高い単語上位5を抽出し、WordNetの同義語と比較。
gensimと違って自分で似ている単語を抽出する必要がある。
なので分散表現のcos類似度を計算して、最も近い単語Top5を抽出するコードは自分で書く。
まず保存していた分散表現とtokenizerをLoad。
# 最後の隠れ層ベクトルLoad
last_hidden_states = torch.load('bert_test/last_hidden_states01.pt')
# input_idsもLoad
with open("bert_test/encoded01.pkl", "rb") as tf:
encoded = pickle.load(tf)
input_ids = torch.tensor(encoded.input_ids)
tokenizerOrg = BertJapaneseTokenizer.from_pretrained('bert_test/tokenizer01')
input_idsとそれに対応する分散表現を連結し、3つ目の次元の0番目がトークンid、1番目以降が分散表現の配列にする。
# input_idsと分散表現を連結
summaryOrg = torch.cat((input_ids.reshape(input_ids.shape[0], input_ids.shape[1], 1)
, last_hidden_states), dim=2)
print(summaryOrg.shape)
# > torch.Size([6099, 166, 769])
input_idsと分散表現を連結した配列のうち、787に絞ったWordNetの語彙の部分だけ抽出。
特殊トークンの部分は消す。
そして各文書の単語(トークン)ひとつひとつのidと分散表現の配列を縦に連結していくことで3次元配列から2次元配列にする。
%%time
# 共通する語彙の分散表現だけ集計
commonVocabs = wordMasterPart['lemma'].unique() # 語彙
nonDelVocab = tokenizerOrg.encode(list(commonVocabs)) # WordNetにある単語のトークン
delVocab = [0.,1.,2.,3.,4.] # 特殊トークン
summaryOrgTs = torch.Tensor()
for ts in tqdm(summaryOrg[:,:,:]):
tmp = pd.DataFrame(ts[:,:].numpy()) #1行目の各トークンの分散表現
tmp = tmp[tmp[0].isin(nonDelVocab)] # WordNetにある単語のトークンは消さない
tmp = tmp[~tmp[0].isin(delVocab)] # 特殊トークン消す
summaryOrgTs = torch.cat((summaryOrgTs, torch.tensor(tmp.to_numpy())))
display(tmp.head()) # 1列目はトークンid、2列目以降は分散表現
print(summaryOrgTs.shape)
# > torch.Size([38317, 769])
# > 1min 53s
で、BERTの良いところとして、同じ単語でも文によって分散表現が変化するので文脈に沿った分散表現を得られる("背が高い"と"価格が高い"の"高い"を区別できる)というところがあるが、今回は 問題設定がめんどう(ry 1単語1分散表現にしたいので、分散表現が複数ある場合は平均をとることにする。
その結果、語彙の数は781になった。おそらくをBERTの場合、word2vecと違ってtokenizerがサブワード分割もしているので、WordNetと一致しない単語がでてきて787から減ってしまったと思われる。仕方ないのでそのまま進める。
# 複数の分散表現がある単語は平均とる
summaryOrgDf = pd.DataFrame(summaryOrgTs.numpy())
summaryOrgTsMean = torch.tensor(summaryOrgDf.groupby([0]).mean().reset_index().to_numpy())
# 語彙数
# Word2vecの方は787個
print(summaryOrgTsMean.shape[0])
# > 781
chABSA-dataset BERTで各単語と類似度が高い単語上位5を抽出し、WordNetの同義語と比較していく。
各トークンidと分散表現のcos類似度が高いトークンidをループで処理して見つけていく。
cos類似度はscipy.spatial.distance.cosineを使用。
⇒ cos類似度:1 - (scipy.spatial.distance.cosine(v1, v2))
いくつか同義語を抽出できていたが、結果は、正解数 28 / 2810だった。
epoch数も少なく、Lossも収束していないし、データもchABSA-datasetだし、ということで散々な結果。word2vecにも負けてら…。
Wikipediaの学習済みモデルでは名誉挽回なるか?
# Word2Vec学習時に定義した語彙のリスト vocabに出てくる単語を評価対象にする
# 各トークンのcos類似度が最も高いTop5のトークンを取得
# 同義語抽出評価
sameWordsCnt = 0 # 初期値 同義語の数
num=0 # カウントの変数
print('限定したWordNetの語彙数', wordMasterPart['lemma'].unique().shape[0])
print('限定したWordNetの語彙と共通する語彙数', summaryOrgTsMean[:,1:].shape[0]) # 限定したWordNetの語彙と共通する語彙数
print('限定したWordNetの単語にあるすべての同義語の数', allSameWordsCnt, '\n')
# 限定したWordNetの単語ごとの同義語についてモデルがいくつ同じ同義語を抽出できているかカウントする
for i, v1 in tqdm(enumerate(summaryOrgTsMean[:,1:])):
# i行目のトークンidをdecode
tango = tokenizerOrg.decode(int(summaryOrgTsMean[i,0].item())).replace(' ','') # 変な空白が入っているときがあるので削除
tagger = MeCab.Tagger()
noun = re.split('[\t,]', tagger.parse(tango))[1] # 品詞取得
if noun!='名詞': # 名詞以外のときはスキップ
continue
# 単語v1とv2のcos類似度を計算する
cosList = []
for j, v2 in (enumerate(summaryOrgTsMean[:,1:])):
if i==j:
cosList.append(0)
else:
cosList.append(1 - scipy.spatial.distance.cosine(v1, v2)) # cos類似度
# cos類似度top5 Token取得
top5Token = summaryOrgTsMean[list(np.argsort(cosList)[-5:][::-1]),0].tolist()
top5Cos = [cosList[co] for co in list(np.argsort(cosList)[-5:][::-1])]
top5 = [(tokenizerOrg.decode(int(to)).replace(' ',''), co) for to, co in zip(top5Token, top5Cos)]
# tangoに最も似ている単語Top5をdfにまとめる
tmp = pd.DataFrame(top5
, columns=['sameLemma', 'cos'])
tmp.insert(0, 'lemma', tango)
# 限定したWordNetと紐づける
mergeDf = pd.merge(wordMasterPart[wordMasterPart['lemma']==tango][['lemma', 'sameLemma']].drop_duplicates()
, tmp, on=['lemma', 'sameLemma'], how='inner')
# 紐づけたdfの結果
if len(mergeDf) > 0:
print(tango)
display(mergeDf)
print('===============', '\n')
sameWordsCnt += len(mergeDf) # 紐づけられた同義語の数を足す
num += 1
# 最終的な正解数
print('正解数', str(sameWordsCnt), '/', allSameWordsCnt)
# > 正解数 28 / 2810

Wikipedia学習済みWord2Vec評価
さくっとLoadして、同義語抽出してWordNetと比較。
正解数 426 / 2810ということで、chABSA-datasetの時と比べかなり良くなった。
# Word2Vec学習時に定義した語彙のリスト vocabに出てくる単語を評価対象にする
# 同義語抽出評価
sameWordsCnt = 0 # 初期値 同義語の数
print('限定したWordNetの語彙数', wordMasterPart['lemma'].unique().shape[0])
# 重複する単語を抽出して長さ確認
print('限定したWordNetの語彙と共通する語彙数'
, len([k for k, v in collections.Counter(list(wordMasterPart['lemma'].unique())+index2wordPre).items() if v > 1]))
print('限定したWordNetの単語にあるすべての同義語の数', allSameWordsCnt, '\n')
# 限定したWordNetの単語ごとの同義語についてモデルがいくつ同じ同義語を抽出できているかカウントする
for i, tango in tqdm(enumerate(wordMasterPart['lemma'].unique())):
try:
# tango=WordNetの単語1つずつループ
# tangoに最も似ている単語Top5をdfにまとめる
w2vCosDf = pd.DataFrame(wv_modelPre.most_similar(tango), columns=['sameLemma', 'cos'])
w2vCosDf.insert(0, 'lemma', tango)
# 限定したWordNetと紐づける
mergeDf = pd.merge(wordMasterPart[wordMasterPart['lemma']==tango][['lemma', 'sameLemma']].drop_duplicates()
, w2vCosDf, on=['lemma', 'sameLemma'], how='inner')
# 紐づけたdfの結果(数が多いので出力しない)
#if len(mergeDf) > 0:
# print(tango)
# display(mergeDf)
# print('===============', '\n')
sameWordsCnt += len(mergeDf) # 紐づけられた同義語の数を足す
except KeyError:
'A tango not present'
# 最終的な正解数
print('正解数', str(sameWordsCnt), '/', allSameWordsCnt)
# > 正解数 426 / 2810

Wikipedia学習済みBERT評価
続いて、Wikipedia学習済みBERTの評価。
保存した分散表現や東北大学の学習済みmodelとかいろいろ読み込み、Tokenizerで分かち書き & トークンid化。
# いろいろ読み込み
# 最後の隠れ層ベクトルLoad
last_hidden_states = torch.load('bert_test/last_hidden_states02.pt')
# 東北大学の学習済みmodelを使用する
model_name = 'cl-tohoku/bert-base-japanese-whole-word-masking'
# トークナイザーの読み込み
tokenizerPre = BertJapaneseTokenizer.from_pretrained(model_name)
# 学習済みモデルの読み込み
bertModelPre = BertModel.from_pretrained(model_name)
# 東北大学の学習済みTokenizerで分かち書き
encoded = tokenizerPre.batch_encode_plus(sentenceDf['preprocessingSentence'].to_list(), padding=True, add_special_tokens=True)
print(encoded.keys())
print(len(encoded['input_ids'][0])) # input_idsの1文書の長さ
# 学習済みBERTトークンID列を抽出
input_ids = torch.tensor(encoded['input_ids'])[:,:]
print(input_ids.shape) # input_idsの型 文書数×1文書の長さ
input_idsとそれに対応する分散表現を連結し、3つ目の次元の0番目がトークンid、1番目以降が分散表現の配列にする。
# input_idsと分散表現を連結
summaryOrgPre = torch.cat((input_ids.reshape(input_ids.shape[0], input_ids.shape[1], 1)
, last_hidden_states), dim=2)
print(summaryOrgPre.shape)
# > torch.Size([6099, 258, 769])
input_idsと分散表現を連結した配列のうち、787に絞ったWordNetの語彙の部分だけ抽出。
特殊トークンの部分は消す。
そして各文書の単語(トークン)ひとつひとつのidと分散表現の配列を縦に連結していくことで3次元配列から2次元配列にする。
commonVocabsはこの後モデルに入れるわけでもなく、ただエンコードしたかっただけなので警告は無視。
%%time
# 共通する語彙の分散表現だけ集計
nonDelVocab = tokenizerPre.encode(list(commonVocabs)) # WordNetにある単語のトークン
delVocab = [0.,1.,2.,3.,4.] # 特殊トークン
summaryOrgTsPre = torch.Tensor()
for ts in tqdm(summaryOrgPre[:,:,:]):
tmp = pd.DataFrame(ts[:,:].numpy()) #1行目の各トークンの分散表現
tmp = tmp[tmp[0].isin(nonDelVocab)] # WordNetにある単語のトークンは消さない
tmp = tmp[~tmp[0].isin(delVocab)] # 特殊トークン消す
summaryOrgTsPre = torch.cat((summaryOrgTsPre, torch.tensor(tmp.to_numpy())))
display(tmp.head()) # 1列目はトークンid、2列目以降は分散表現
print(summaryOrgTsPre.shape)
# > torch.Size([52080, 769])
# > 2min 34s
分散表現が複数ある場合は平均をとることにする。
その結果、語彙の数は718になった。
chABSA-datasetのword2vecを基準に、WordNetの語彙数を787個に絞ったので、WikipediaのtokenizerではWordNetと一致しない単語がでてきて787から減ってしまったと思われる。
# 複数の分散表現がある単語は平均とる
summaryOrgDfPre = pd.DataFrame(summaryOrgTsPre.numpy())
summaryOrgTsPreMean = torch.tensor(summaryOrgDfPre.groupby([0]).mean().reset_index().to_numpy())
# 語彙数
# Word2vecの方は787個
print(summaryOrgTsPreMean.shape[0])
# > 718
Wikipedia学習済みBERTで各単語と類似度が高い単語上位5を抽出し、WordNetの同義語と比較していく。
各トークンidと分散表現のcos類似度が高いトークンidをループで処理して見つけていく。
cos類似度はscipy.spatial.distance.cosineを使用。
⇒ cos類似度:1 - (scipy.spatial.distance.cosine(v1, v2))
結果は、正解数 673 / 2810だった。
見事1位、やったね。
# Word2Vec学習時に定義した語彙のリスト vocabに出てくる単語を評価対象にする
# 各トークンのcos類似度が最も高いTop5のトークンを取得
# 同義語抽出評価
sameWordsCnt = 0 # 初期値 同義語の数
num=0 # カウントの変数
print('限定したWordNetの語彙数', wordMasterPart['lemma'].unique().shape[0])
print('限定したWordNetの語彙と共通する語彙数', summaryOrgTsPreMean[:,1:].shape[0]) # 限定したWordNetの語彙と共通する語彙数
print('限定したWordNetの単語にあるすべての同義語の数', allSameWordsCnt, '\n')
# 限定したWordNetの単語ごとの同義語についてモデルがいくつ同じ同義語を抽出できているかカウントする
for i, v1 in tqdm(enumerate(summaryOrgTsPreMean[:,1:])):
# i行目のトークンidをdecode
tango = tokenizerOrg.decode(int(summaryOrgTsPreMean[i,0].item())).replace(' ','') # 変な空白は言っているときがあるので削除
tagger = MeCab.Tagger()
noun = re.split('[\t,]', tagger.parse(tango))[1] # 品詞取得
if noun!='名詞': # 名詞のときはスキップ
continue
# 単語v1とv2のcos類似度を計算する
cosList = []
for j, v2 in (enumerate(summaryOrgTsPreMean[:,1:])):
if i==j:
cosList.append(0)
else:
cosList.append(1 - scipy.spatial.distance.cosine(v1, v2)) # cos類似度
# cos類似度top5 Token取得
top5Token = summaryOrgTsPreMean[list(np.argsort(cosList)[-5:][::-1]),0].tolist()
top5Cos = [cosList[co] for co in list(np.argsort(cosList)[-5:][::-1])]
top5 = [(tokenizerOrg.decode(int(to)).replace(' ',''), co) for to, co in zip(top5Token, top5Cos)]
# tangoに最も似ている単語Top5をdfにまとめる
tmp = pd.DataFrame(top5
, columns=['sameLemma', 'cos'])
tmp.insert(0, 'lemma', tango)
# 限定したWordNetと紐づける
mergeDf = pd.merge(wordMasterPart[wordMasterPart['lemma']==tango][['lemma', 'sameLemma']].drop_duplicates()
, tmp, on=['lemma', 'sameLemma'], how='inner')
# 紐づけたdfの結果(数が多いので出力しない)
#if len(mergeDf) > 0:
# print(tango)
# display(mergeDf)
# print('===============', '\n')
sameWordsCnt += len(mergeDf) # 紐づけられた同義語の数を足す
num += 1
# 最終的な正解数
print('正解数', str(sameWordsCnt), '/', allSameWordsCnt)
# > 正解数 673 / 2810

結果
- chABSA-datasetで学習したword2vecモデル
- 正解数 79 / 2810
- chABSA-datasetで学習したBERTモデル
- 正解数 28 / 2810
- Wikipedia学習済みword2vecモデル
- 正解数 426 / 2810
- Wikipedia学習済みBERTモデル
- 正解数 673 / 2810
おわりに
BERTの事前学習が一番疲れた。それなのに一番精度が悪かった(笑)。
でもこれでデータがあれば、事前学習できるようになったぞ。
学習済みモデルも使えるようになったし。
それにしても、やっぱり大量のデータでちゃんと学習したBERTは強かったな。
タスク別のファインチューニング方法は、事前学習の方法より書籍やいろんな人の記事でたくさん載っているし、ある程度はBERTというかhuggingfaceのtransformersを使えるようになったのではないだろうか。やったね。
以上!