はじめに
huggingfaceのtransformersのライブラリを使ってBERTの事前学習をやってみました。日本語でBERTの事前学習をスクラッチで行っている記事が現段階であまり見当たらなかったですが、一通り動かすことができたので、メモがてら残しておきます。
BERTの事前学習をしてみたいけど、いまいちやり方がわからない人の一助になれば幸いです。
正直まだわかっていないところが多々ありますし、紹介する内容がセオリーな方法かもよくわかっていません。
あれこれ試している最中ですので、もっとこうしたほうがいいよ、みたいなアドバイスございましたらご教示いただけると幸いです!
参考文献
以下を参考にしました。
- https://www.kaggle.com/arnabs007/pretrain-a-bert-language-model-from-scratch/notebook
- https://stackoverflow.com/questions/65646925/how-to-train-bert-from-scratch-on-a-new-domain-for-both-mlm-and-nsp
- https://colab.research.google.com/github/huggingface/blog/blob/master/notebooks/01_how_to_train.ipynb#scrollTo=hDLs73HcIHk5
扱うデータセットについて
今回は事前学習の動かし方を確認することを目的としているので、事前学習にやたらと時間がかからないように、データ量は小さいものを使用することにします。
というわけで青空文庫から夏目漱石の作品をざっと一通りダウンロードしました。100件ほどのテキストファイルで約8MBほどになりました。
このデータを使って夏目漱石言語モデルSousekiBERTを作ってみようと思います。
実装環境について
実装環境としてはGoogle Colab Proを使っています。16GBのGPUを1枚だけ使っています。
transformersはアップデートが頻繁に行われるため、近い将来ここで紹介する方法が通用しなくなる可能性もあるかもしれません。
検証した時点でのtransformersや関連するライブラリのバージョンは以下の通りです。
!pip list | grep transformers
!pip list | grep tokenizers
!pip list | grep torch
# transformers 4.8.2
# tokenizers 0.10.3
# torch 1.9.0+cu102
# 〜省略〜
事前学習モデルの作り方
流れは大きく以下の6つかなーと思っています。この流れに沿って1つ1つ動かし方を確認していきます。
- 事前学習用のコーパスを準備する
- tokenizerを学習する
- BERTモデルのconfigを設定する
- 事前学習用のデータセットを準備する
- 事前学習する
- 言語モデルの確認
1. 事前学習用のコーパスを準備する
青空文庫から夏目漱石の作品をざっとダウンロードしたものに簡単な前処理(ルビの除去であったり、段落のラベル的なものを除去したり)を行い、1つのテキストファイルに書き込みました。1文章(。区切り)1行になるように書き込んでいます。
ここのコードはちょっとテキトーに書いているので、隠しておきます。。。
import re
import os
import numpy as np
import pandas as pd
from glob import glob
from tqdm import tqdm
drive_dir = '/content/drive/MyDrive/ColabNotebooks/aozora/'
file_list = glob(drive_dir + "original_data/*.txt")
corpus = []
for filename in tqdm(file_list):
with open(filename, 'r', encoding='shift-jis') as r:
text = r.read()
text = re.sub(r"《[^》]*》", "", text)
text = text.replace("\u3000", "")
head_num = 0
tail_num = 0
for sent in text.split('\n')[2:]:
if '--' in sent:
head_num += 1
continue
if head_num == 2:
if sent == '':
tail_num += 1
if tail_num == 3:
break
else:
continue
else:
tail_num = 0
sent = re.sub(r'^[.*]$', '', sent)
sent = re.sub(r'[.*]', '', sent)
sent = re.sub(r'※[.*]', '', sent)
if sent == '': continue
sent = "。\n".join(sent.split('。'))
for _s in sent.split('\n'):
corpus.append(_s)
corpus = list(filter(("").__ne__, corpus))
with open(drive_dir + 'corpus/corpus.txt', 'w', encoding='utf-8') as w:
w.write("\n".join(corpus))
出来上がったコーパスはこんな感じ
如何なるものを描かんと欲するかとの御質問であるが、私は、如何なるものをも書きたいと思う。
自分の能力の許す限りは、色々種類の変化したものを書きたい。
自分の性情に適したものは、なるべく多方面に亙って書きたい。
然し、私のような人間であるから、それは単に希望|丈けで、其希望通りに書くことは出来ないかも知れぬ。
で、御質問に対して漠然としたお答えではあるが、大抵以上に尽きて居る。
〜以下略〜
2. tokenizerを学習する
続いてtokenizerを学習します。BERTの事前学習において、tokenizerを用意するのが一番大変なんじゃないかと思ったりしています。
結論、今回はsentencepieceを使ってtokenizerを学習させることにしました。動作方法を確認する上で非常に楽だったからです。
東北大学が提供してくれている日本語BERT('cl-tohoku/bert-base-japanese-whole-word-masking')はMeCabとWord Pieceを使ってtokenizerを学習していますが、以下の記事にもあるように現状のhuggingfaceのtokenizer周りの多言語対応はPoC的な位置づけのようで、自前で色々と実装する必要があり、ちょっとハードルが上がります。
とはいえこちらの記事でMeCabとWord Pieceを使ったtokenizerの学習方法はコード付きで詳しく解説してくれているので、自分も動かせるようになったら、本記事に追記したいと思います。
sentencepieceの学習方法はとても簡単で、先程用意したコーパスを以下のようにSentencePieceTrainer.Trainに渡してやればOK。
# sentencepieceはpipでインストールできます。
# !pip install sentencepiece
from sentencepiece import SentencePieceTrainer
SentencePieceTrainer.Train(
'--input='+drive_dir+'corpus/corpus.txt, --model_prefix='+drive_dir+'souseki_sentencepiece --character_coverage=0.9995 --vocab_size=32000 --pad_id=3 --add_dummy_prefix=False'
)
今回のデータ量であれば、sentencepieceの学習は30秒ほどで終わりました。学習が完了すると、--model_prefixで指定した名前で.vocabファイルと.modelファイルが作成されます。
この.modelファイルをBertTokenizer.from_pretrainedとかで読み込みたいところですが、sentencepieceのライブラリで学習されたモデルを読み込めるtokenizerとそうでないtokenizerとあるようで、少なくともBertTokenizerでは読み込むことができませんでした。Word Pieceを前提としたtokenizerだからなんですかね。sentencepieceに対応しているtokenizerのモデルはhuggingfaceのリファレンスで確認することができます。
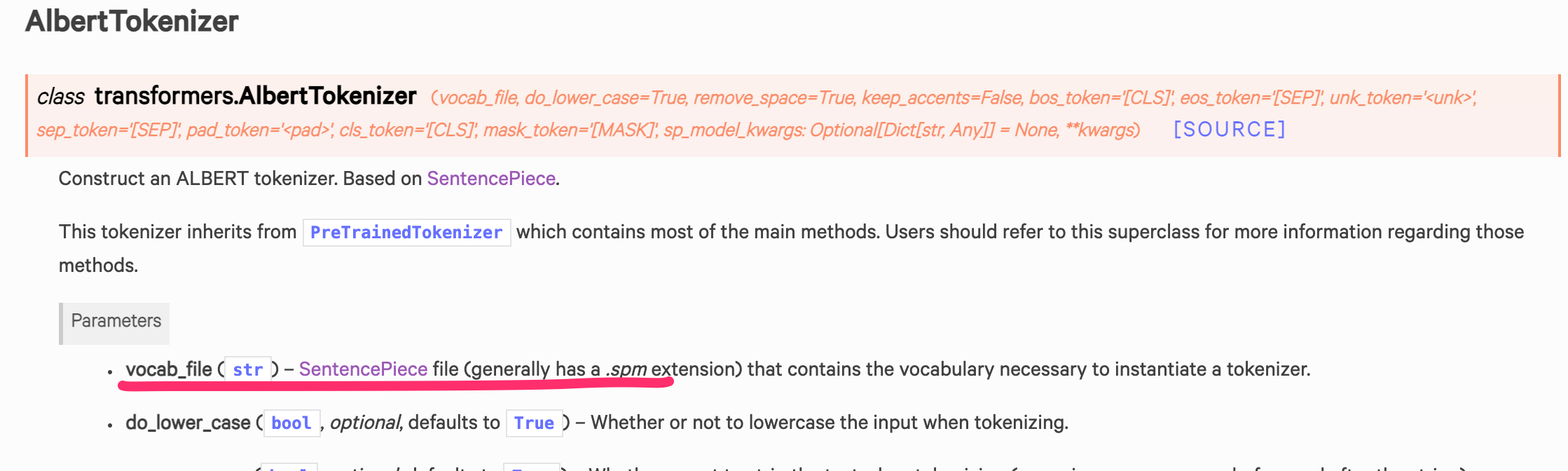
今回の検証では、上で参照したALBERTに紐づくtokenizerのAlbertTokenizerを使おうと思います。
先程学習したsentencepieceのモデルをfrom_pretrainedで読み込みます。事前学習で使うspecial tokenが自動で追加されました。
from transformers import AlbertTokenizer
# AlbertTokenizerではkeep_accents=Trueを指定しないと濁点が除去されてしまいます。
tokenizer = AlbertTokenizer.from_pretrained(drive_dir+'souseki_sentencepiece.model', keep_accents=True)
text = "吾輩は猫である。名前はまだ無い。"
print(tokenizer.tokenize(text))
# Adding [CLS] to the vocabulary
# Adding [SEP] to the vocabulary
# Adding [MASK] to the vocabulary
# Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
# ['吾輩は猫である', '。', '名前は', 'まだ', '無い', '。']
3. BERTモデルのconfigを設定する
続いて、BERTモデルのアーキテクチャーを決定するためにBertConfigを設定し、そのconfigを元に事前学習用のBERTモデルを宣言します。
configで設定できるパラメータについてはリファレンスを参照するのが良いと思います。
tokenizerはALBERTのものを使いましたが、モデル自体はいつものBERTを使おうと思います。これから事前学習する段階なので、どんなアーキテクチャーでどんな事前学習でモデル作るかは柔軟に選べるって感じですかね。
今回事前学習としてはMLMだけでいいやと思ったので、BertForMaskedLMでモデルを宣言していますが、NSPも合わせて事前学習に組み込みたいときは、BertForPreTrainingでモデルを宣言すれば良いと思います。
注意1.
事前学習でNSPするときは、参考文献2.で紹介されているように、用意するコーパスはドキュメント毎に空行を入れる必要があるようです。
注意2.
下記ではvocab_size=32003で設定しています。sentencepieceの学習の際は32000語に収まるように学習していますが、AlbertTokenizer.from_pretrainedで読み込んだ際に追加された3つのspecial tokenの数も合わせてvocab_sizeに追加する必要があります。32000のままだと事前学習時に次元が合わないことによるエラーが出ます。
参考文献とかを見る限り、tokenizer学習時の語彙数とconfigに設定する語彙数を揃えているようなので、huggingfaceのライブラリでtokenizerを学習していればこの辺のspecial tokenも含まれた状態でtokenizerが学習されるんですかね。
from transformers import BertConfig
from transformers import BertForMaskedLM
config = BertConfig(vocab_size=32003, num_hidden_layers=12, intermediate_size=768, num_attention_heads=12)
model = BertForMaskedLM(config)
4. 事前学習用のデータセットを準備する
事前学習用のデータセットを準備します。事前学習をMLMだけする場合は下記のようにLineByLineTextDatasetを使えばOKですが、NSPもしたい場合はTextDatasetForNextSentencePrediction を使うようです。
この辺正直良くわかってないのですが、参考文献1.の方の言葉をお借りすると、
-
LineByLineTextDatasetはテキストを1行ずつ読み込んでトークンに変換するためのもの -
DataCollatorForLanguageModelingはデータセットからサンプルのリストを受け取り、それらをテンソルの辞書としてバッチに照合するための関数
のようです。
from transformers import LineByLineTextDataset
dataset = LineByLineTextDataset(
tokenizer=tokenizer,
file_path=drive_dir + 'corpus/corpus.txt',
block_size=256, # tokenizerのmax_length
)
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=True,
mlm_probability= 0.15
)
5. 事前学習する
TrainingArgumentsで事前学習に関するパラメータを設定し、Trainerで事前学習するインスタンスを作ります。
とりあえずepoch数は10にしてます。今回のデータだとper_device_train_batch_size=32で13GBほどGPUメモリ喰いました。
from transformers import TrainingArguments
from transformers import Trainer
training_args = TrainingArguments(
output_dir= drive_dir + 'SousekiBERT/',
overwrite_output_dir=True,
num_train_epochs=10,
per_device_train_batch_size=32,
save_steps=10000,
save_total_limit=2,
prediction_loss_only=True
)
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=dataset
)
trainer.train()で事前学習を開始できます。自動でプログレスバーとか表示してくれるので、学習にどれくらい時間かかるのかわかりやすくて助かります。
trainer.train()
trainer.save_model(drive_dir + 'SousekiBERT/')
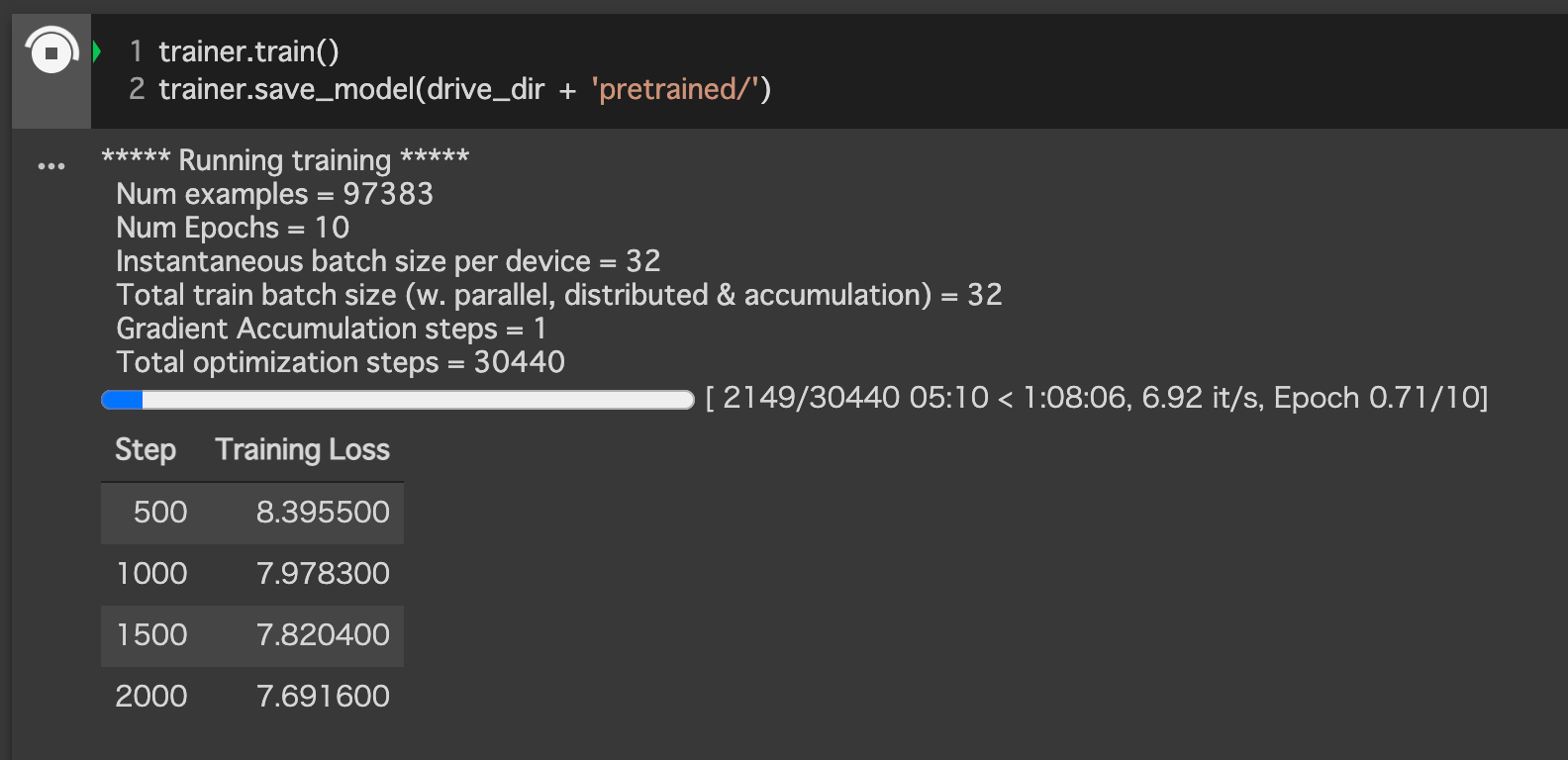
データ量が少ないおかげで10epoch回しても1時間ほどで学習が終わりました。
6. 言語モデルの確認
事前学習はこれで終わりなのですが、ちゃんと事前学習されて思い描いた言語モデルが出来上がっているか確認する方法として、MASKされた単語を予測させる方法があります。以下のようにpipelineを使って簡単に穴埋め問題を解かせることができます。
動作方法を確認したかったので言語モデルとしての精度はまぁ良しとします。
from transformers import pipeline
tokenizer = AlbertTokenizer.from_pretrained(drive_dir+'souseki_sentencepiece.model', keep_accents=True)
model = BertForMaskedLM.from_pretrained(drive_dir + 'SousekiBERT')
fill_mask = pipeline(
"fill-mask",
model=model,
tokenizer=tokenizer
)
MASK_TOKEN = tokenizer.mask_token
text = '''
吾輩は{}である。名前はまだ無い。
'''.format(MASK_TOKEN)
fill_mask(text)
# [{'score': 0.002911926247179508,
# 'sequence': '吾輩は自分である。名前はまだ無い。',
# 'token': 164,
# 'token_str': '自分'},
# {'score': 0.0022156336344778538,
# 'sequence': '吾輩はそれである。名前はまだ無い。',
# 'token': 193,
# 'token_str': 'それ'},
# {'score': 0.002098929136991501,
# 'sequence': '吾輩は人間である。名前はまだ無い。',
# 'token': 207,
# 'token_str': '人間'},
# {'score': 0.001998839434236288,
# 'sequence': '吾輩は先生である。名前はまだ無い。',
# 'token': 217,
# 'token_str': '先生'},
# {'score': 0.0019333077361807227,
# 'sequence': '吾輩は私である。名前はまだ無い。',
# 'token': 183,
# 'token_str': '私'}]
今回事前学習したモデルをファインチューニングして使いたい場合、BertForMaskedLMで宣言したモデルだと最終層がMLM仕様になってますが、今回学習したモデルは(BERTのアーキテクチャーで学習したので)BertModel.from_pretrainedで呼び出すことができて、ちゃんとパラメータも学習されたものがセットされているようです。
これでオリジナルなBERTモデルを使って個々のタスクを解かせることができそうです。
おわりに
これを機にへんてこなBERTモデル作ってみたい。
おわり