
はじめに
本記事は後編になります。実際にETLフローを構築してComposer,GKEを駆使してフローを実行させてみようと思います。
使用するリソースの概要など知りたい方は前編からご覧ください!
【DevOps】【ETL】とあるOSS CICD環境のGCPマネージド化 -前編-【GCP】
構築準備
最初にディレクトリ構造を決めておきます。
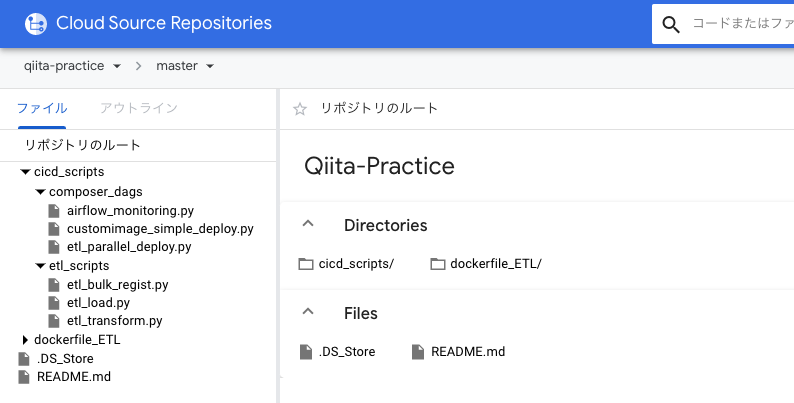
主にComposerをベースに進めていきますが、基本的な話は割愛します。もし「Airflowってなんぞや?」って方は下記記事をご覧ください。
Dockerfileの修正
- この後、説明していく処理に必要なライブラリを追加しておきます
- イメージ作成時にリポジトリのクローンのために強引にサービスアカウントキーを埋め込んでいます(非推奨中の非推奨です、安全な方法を考えてください)
FROM loblaw/google-sdk-docker
# Required Tools
RUN apk update && \
apk add git && \
apk add py-pip && \
apk add --virtual .build-deps gcc python-dev musl-dev postgresql-dev && \
pip install --upgrade google-cloud-storage psycopg2 google-cloud-bigquery
RUN echo '[]' >> /root/sa.json # Not Recommend
# Cloud SQL Config
ENV USER qiita
ENV DATABASE qiita-practice
ENV PORT 5432
ENV PASSWORD qiita
ENV HOST **.**.**.**
# Update Google SDK
RUN gcloud components update && \
gcloud components update kubectl
# Google SDK Config
RUN gcloud config set project [プロジェクト名] && \
gcloud config set account [サービスアカウント名] && \
gcloud auth activate-service-account [サービスアカウント名] --key-file=/root/sa.json && \
gcloud source repos clone qiita-practice && \
gcloud info
サンプルを独自イメージで実行
- Composer環境の構築が完了してウェブUIにアクセスすると
airflow_monitoringという名前のDAGがあると思います - このDAGのコードは
environments describeコマンドで取得した情報の中のdagGcsPrefix: gs://asia-northeast1-qiita-pract-xxxxxx-bucket/dagsに存在します - このコードをベースにいじっていくのでCloudStorageからダウロードしてきます
- これを
KubernetesPodOperatorをつかって独自コンテナイメージで実行できるようにします
→ ContainerRegistoryに保存したコンテナイメージを指定します
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.contrib.kubernetes import secret
from airflow.contrib.operators import kubernetes_pod_operator
from datetime import timedelta
defalt_args = {
'owner':'hayashi',
'depends_on_past':False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
'schedule_interval':'@hourly'
}
dag = DAG(
'customimage_simple_deploy',
default_args=defalt_args,
description='liveness monitoring dag',
dagrun_timeout=timedelta(minutes=10),
start_date=airflow.utils.dates.days_ago(0)
)
echo_test = kubernetes_pod_operator.KubernetesPodOperator(
task_id="echo",
name="echo",
namespace="default",
image="gcr.io/[プロジェクト名]/qiita-practice",
image_pull_policy="Always",
cmds=["echo", "test"],
dag=dag
)
- このファイルをAirflowに読み込ませるためには、
gs://asia-northeast1-qiita-pract-xxxxxx-bucket/dagsに格納します。シンプルにgsutil cpで送ってください。するといくらか待つとAirflowのウェブサーバーが同期してUI画面に表示されます
- ひとまずトリガー実行してみます

- 無事タスクが成功しました、これでContainerRegistryに保存してある独自のコンテナイメージを使用したGKE上のタスク実行が完了です!
注意点
- ここでの注意点は
image_pull_policy="Always"についてです - デフォルトでは
IfNotPrecsentになっていてGKEのノード上にすでにイメージがある場合はPullしないという設定になっています - しかしこのデフォルトだと、dockerfileを編集してBuildで自動ビルドしてContainerRegistryに新たなイメージを上書きしてもノード上にすでにイメージがあるためPullされません
- なので、Pullするルールを決める
image_pull_policyを毎回PullするというAlwaysに設定することで常に最新イメージをPullする状態にしています - ただ、毎回Pullするためコンテナの立ち上がりが遅いというデメリットあるので考慮した上でという感じでしょうか
それっぽい ETLフローの構築
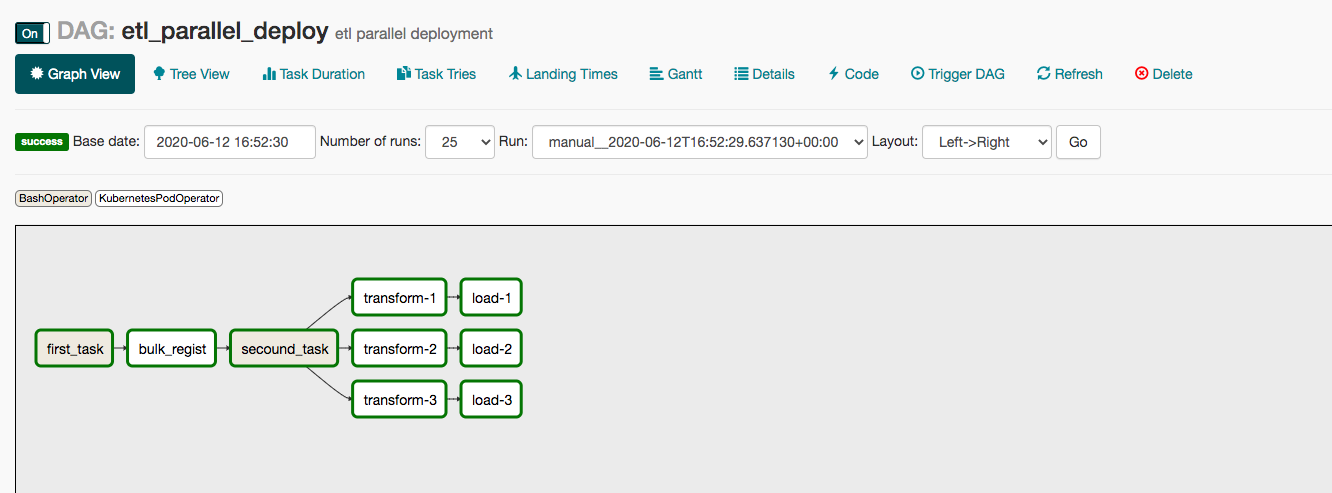
- 今回実装するETLフローはこんな感じです!
- CloudStorageの生データを加工してBigQueryに投入するといったイメージです
- DAGはこのように実装します
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.contrib.kubernetes import secret
from airflow.contrib.operators import kubernetes_pod_operator
from datetime import timedelta
defalt_args = {
'owner':'qiita',
'depends_on_past':False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
'schedule_interval':'@hourly'
}
dag = DAG(
'etl_parallel_deploy',
default_args=defalt_args,
description='etl parallel deployment',
dagrun_timeout=timedelta(minutes=10),
start_date=airflow.utils.dates.days_ago(0)
)
first_task = BashOperator(
task_id='first_task',
bash_command='echo ===============Bulk_Regist===============',
dag=dag
)
# Step1
bulk_regist = kubernetes_pod_operator.KubernetesPodOperator(
task_id="bulk_regist",
name="bulk-regist",
namespace="default",
image="gcr.io/****/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_bulk_regist.py"],
dag=dag
)
secound_task = BashOperator(
task_id='secound_task',
bash_command='echo ===============Transform===============',
dag=dag
)
# Step2
transform_1 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="transform-1",
name="transform-1",
namespace="default",
image="gcr.io/***/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_transform.py"],
dag=dag
)
transform_2 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="transform-2",
name="transform-2",
namespace="default",
image="gcr.io/***/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_transform.py"],
dag=dag
)
transform_3 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="transform-3",
name="transform-3",
namespace="default",
image="gcr.io/***/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_transform.py"],
dag=dag
)
# Step3
load_1 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="load-1",
name="load-1",
namespace="default",
image="gcr.io/***/qiita-practicee",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_load.py"],
dag=dag
)
load_2 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="load-2",
name="load-2",
namespace="default",
image="gcr.io/***/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_load.py"],
dag=dag
)
load_3 = kubernetes_pod_operator.KubernetesPodOperator(
task_id="load-3",
name="load-3",
namespace="default",
image="gcr.io/***/qiita-practice",
image_pull_policy="Always",
cmds=["python", "/qiita-practice/cicd_scripts/etl_scripts/etl_load.py"],
dag=dag
)
first_task.set_downstream(bulk_regist)
bulk_regist.set_downstream(secound_task)
secound_task.set_downstream(transform_1)
secound_task.set_downstream(transform_2)
secound_task.set_downstream(transform_3)
transform_1.set_downstream(load_1)
transform_2.set_downstream(load_2)
transform_3.set_downstream(load_3)
-
Graph Viewで表示してみるとこんな感じです
注意点
- DAGを書くの際の注意点はコンテナの名前です
- コンテナに_(アンダースコア)をいれるとなぜかエラーになってしまいます
Step1. 生データのバルク登録 -Extract-
- ここではCloudStorageの生データを読み込み、データの量を把握します
- Step2で分散処理させるためにデータをある程度の大きさに区切って処理できるようにします
→ サンプルデータは50万レコードあるデータにしたので1万行ずつでバルク登録を行います
→ 生データはなんでも良いです!実際の加工処理は今回省く予定です - 生データは
gs://qiita-practice/raw_file.csvにある想定です
import os
from google.cloud import storage
import psycopg2
import psycopg2.extras
# Cloud Storageから生データをダウンロード
def download_file(file_path, bucket_name):
client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob = bucket.blob("raw_file.csv")
blob.download_to_filename(file_path)
# 生データに行番号を付け加えて再度ファイル書き出し&データベースに状態を書き出し
def add_rownum(file_path, cur, conn):
etl_file_path = "/".join(file_path.split("/")[0:-1])+"/pre_etl_file.csv"
write_file = open(etl_file_path, "w")
with open(file_path) as f:
for row_num, line in enumerate(f):
# 1行目にカラム名が入っている場合はとばす
if row_num == 0:continue
# 生データに行番号がなかったため挿入して書き出し
row_num = row_num - 1
write_file.write(str(row_num) + "," + line)
# 1万行ごとにデータベースに状態を書き出し
if (row_num+1) % 10000 == 0:
sql = "insert into etl.bulk_list (row_start, row_end, state) values ({},{},'wait_trans');".format(row_num-9999, row_num)
cur.execute(sql)
print("========= comp from {} to {} =========".format(row_num-9999, row_num))
return etl_file_path
# データベース接続のセットアップ
def regist_bulk_rownum(file_path):
with psycopg2.connect(
host=os.environ.get('HOST'),
user=os.environ.get('USER'),
password=os.environ.get('PASSWORD'),
database=os.environ.get('DATABASE'),
port=int(os.environ.get('PORT'))
) as conn:
conn.set_client_encoding('utf-8')
conn.cursor_factory=psycopg2.extras.DictCursor
with conn.cursor() as cur:
etl_file_path = add_rownum(file_path, cur, conn)
conn.commit()
return etl_file_path
# 再度書き出したファイルをCloud Storageにアップロード
def upload_etl_file(etl_file_path, bucket_name):
client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob = bucket.blob("etl/etl_file.csv")
blob.upload_from_filename(etl_file_path)
def set_runenv():
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/root/sa.json'
return "/qiita-practice/cicd_scripts/etl_data/raw_file.csv"
if __name__=='__main__':
file_path = set_runenv()
bucket_name = 'qiita-practice'
download_file(file_path, bucket_name)
print("========= comp download =========")
etl_file_path = regist_bulk_rownum(file_path)
print("========= comp regist =========")
upload_etl_file(etl_file_path, bucket_name)
print("========= comp upload =========")
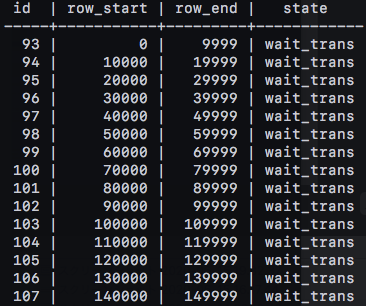
-
このタスクがうまく実行できると、1万行ごとに処理状態(登録時はtransを待ちということでwait_transにしています)を登録できているはずです
-
これでStep1のバルク登録は完了です
-
このデータベースの処理状態を参照しながら次の処理で分散処理を行なっていきます
Step2 分散加工処理 -Transform-
- Step1で行番号を足したファイルを再びダウンロードします
- データベースにidを昇順で問い合わせしstateを確認します、stateが「wait_trans」であれば「row_start」と「row_end」を参照してその間の行を加工してファイル書き出しをします
- この処理を3ノードで同時に行なっていくことで分散処理を行なっていきます
- できるだけ他のノードとの重複処理を防ぐために「wait_trans」を見つけたらすぐにstateを「comp_trans」にアップデートします
- 再び書き出したファイルをCloud Storageにアップロードします
- アップロードは
gs://qiita-practice/etl/comp_etl_file_*_*.csv
- アップロードは
import os
from google.cloud import storage
import psycopg2
import psycopg2.extras
import time
# 行番号を追加したファイルをダウンロード
def download_file(file_path, bucket_name):
client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob = bucket.blob("etl/etl_file.csv")
blob.download_to_filename(file_path)
# データベースに「wait_trans」がないか確認
def check_alltask(conn, cur):
sql = "select * from etl.bulk_list order by id asc;"
cur.execute(sql)
for row in cur:
if row[3] == "wait_trans":
sql = "update etl.bulk_list set state = 'comp_trans' where id = {};".format(row[0])
cur.execute(sql)
conn.commit()
return 0, row[0:3]
return 1, "comp transform"
# 「wait_trans」の行に対して加工処理(今回はファイル書き出し+sleep(5)としています)
def transform_task(file_path, trans_info):
start_rownum = trans_info[1]
end_rownum = trans_info[2]
etl_file_path = "/".join(file_path.split("/")[0:-1])+"/comp_etl_file_{}_{}.csv".format(start_rownum, end_rownum)
write_file = open(etl_file_path, "w")
with open(file_path) as f:
for row_num, line in enumerate(f):
if start_rownum <= row_num and row_num <= end_rownum:
write_file.write(line)
time.sleep(5)
return etl_file_path
# 各ノードで実行して分散処理
def transform_by_parallel(file_path, bucket_name):
with psycopg2.connect(
host=os.environ.get('HOST'),
user=os.environ.get('USER'),
password=os.environ.get('PASSWORD'),
database=os.environ.get('DATABASE'),
port=int(os.environ.get('PORT'))
) as conn:
conn.set_client_encoding('utf-8')
conn.cursor_factory=psycopg2.extras.DictCursor
with conn.cursor() as cur:
comp_flg = 0
while comp_flg != 1:
comp_flg, trans_info = check_alltask(conn, cur)
etl_file_path = transform_task(file_path, trans_info)
print("========= comp transform from {} to {}=========".format(trans_info[1], trans_info[2]))
upload_etl_file(etl_file_path, trans_info, bucket_name)
print("========= comp upload from {} to {}==========".format(trans_info[1], trans_info[2]))
# 書き出した細かいファイルをCloud Storageにアップロード
def upload_etl_file(etl_file_path, trans_info, bucket_name):
start_rownum = trans_info[1]
end_rownum = trans_info[2]
client = storage.Client()
bucket = client.get_bucket(bucket_name)
blob = bucket.blob("etl/comp_etl_file_{}_{}.csv".format(start_rownum, end_rownum))
blob.upload_from_filename(etl_file_path)
def switch_runenv():
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/root/sa.json'
return "/qiita-practice/cicd_scripts/etl_data/pre_etl_file.csv"
if __name__=='__main__':
file_path = switch_runenv()
bucket_name = "qiita-practice"
download_file(file_path, bucket_name)
print("========= comp download =========")
transform_by_parallel(file_path, bucket_name)
print("========= comp =========")
- このタスクがうまく実行されるとstateが「comp_trans」に変わっていきます
Step3 BigQueryへのロード -Load-
- 最後に加工済みのファイルをBigQueryにロードします
- Step2で「wait_trans」を見つからなくなったポッドはタスクは終了しすぐにStep3のポッドが立ち上がります
- ここでもデータベースのstateを参照しながら「comp_load」を探し、該当のファイルに対してロードを実行します
- 今回のデータセットは
qiita_practiceとしてあらかじめ作成しておきます - 投入するテーブルは
qiita_practice.qiita_etlとします
import os
from google.cloud import storage
from google.cloud import bigquery
import psycopg2
import psycopg2.extras
import time
# データベースに「comp_trans」がないか確認
def check_alltask(conn, cur):
sql = "select * from etl.bulk_list order by id asc;"
cur.execute(sql)
for row in cur:
if row[3] == "comp_trans":
sql = "update etl.bulk_list set state = 'comp_load' where id = {};".format(row[0])
cur.execute(sql)
conn.commit()
return 0, row[0:3]
return 1, "comp load"
# 加工済みファイルの削除
def delete_file(file_path):
client = storage.Client()
bucket_name = "qiita-practice"
bucket = client.get_bucket(bucket_name)
blob = bucket.blob("etl/{}".format(file_path.split('/')[-1]))
blob.delete()
# BigQueryへのロード
def load_to_bigquery(start_rownum, end_rownum):
client = bigquery.Client()
dataset = "qiita_practice"
table = "qiita_etl"
dataset_ref = client.dataset(dataset)
job_config = bigquery.LoadJobConfig()
# 投入テーブルのスキーマ
job_config.schema = [
bigquery.SchemaField("ROW_ID", "INTEGER"),
bigquery.SchemaField("FL_DATE", "DATE"),
bigquery.SchemaField("UNIQUE_CARRIER", "STRING"),
・・・
]
job_config.skip_leading_rows = 0
job_config.source_format = bigquery.SourceFormat.CSV
uri = "gs://qiita-practice/etl/comp_etl_file_{}_{}.csv".format(start_rownum, end_rownum)
load_job = client.load_table_from_uri(
uri,
dataset_ref.table(table),
job_config=job_config
)
print("Starting job from {} to {}".format(start_rownum, end_rownum))
load_job.result()
print("Job finished.")
time.sleep(5)
delete_file(uri)
# 各ノードで実行して分散処理
def load_by_parallel():
with psycopg2.connect(
host=os.environ.get('HOST'),
user=os.environ.get('USER'),
password=os.environ.get('PASSWORD'),
database=os.environ.get('DATABASE'),
port=int(os.environ.get('PORT'))
) as conn:
conn.set_client_encoding('utf-8')
conn.cursor_factory=psycopg2.extras.DictCursor
with conn.cursor() as cur:
comp_flg = 0
while comp_flg != 1:
comp_flg, trans_info = check_alltask(conn, cur)
load_to_bigquery(trans_info[1], trans_info[2])
print("========= comp load from {} to {}=========".format(trans_info[1], trans_info[2]))
def switch_runenv(env_name):
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/root/sa.json'
if __name__=='__main__':
switch_runenv()
load_by_parallel()
- これをうまく実行できれば、「comp_load」にstateが切り替わっていきます
- これでComposerを介してGKE上で処理を実現できました
ETLフローを構築してみて
1度CI/CD環境を構築できると[ローカルでコード開発] → [git push & 自動build & gsutil cp] → [トリガー実行でGKE上にデプロイ]といった流れがスムーズに行えました。最初のOSS CI/CD環境のGCPマネージド化からETLフローの構築に話はそれてしまいましたが、実際にフローを構築することで有用性を確認することができてよかったです。
やはりGCPで一貫して環境を構築すると、それぞれのリソースとの親和性が高いのが効いてすぐに簡単に実現したい環境が作れるという印象でした。特にBuild,ContainerRegistryはCloudFunctionやCloudStorageなどとも連携がとれてより柔軟にCI/CD環境が構築できそうです。
ここらへん資格で言えばDevOps Engineerあたりの内容になってくれるのでしょうか。取得目指してる方の役に立てると幸いです。