はじめに
Google Cloud Dataflowは、データ処理をバッチとリアルタイムストリームの両方で行えるデータ処理サービスです。データを分析ツールで使用できるようにするために、Dataflowでデータを取り込むためのパイプを作成し、必要に応じて変換および処理できますが、データ連携は面倒です。
この記事では、簡略化するべくGoogle Cloud DataflowとDataDirect Salesforce JDBCドライバを使用して、Salesforceデータを簡単にGoogle BigQueryに抽出、変換、ロード(ETL)する方法について記述します。
記事はJavaプロジェクトを使用したものですが、SQL Server、IBM DB2、Amazon Redshift、Eloqua、Hadoop HiveなどのJDBCデータソースからデータを読み取るためのApache Beamでも同様の手順で行うことができます。
DataDirect Salesforce JDBCドライバのインストール
1, DataDirect Salesforce JDBCドライバダウンロードサイトからドライバを以下の手順通りにインストールします。
2, .jar パッケージを実行し、インストールします。ターミナルで以下のコマンドを実行するか、jarパッケージをダブルクリックください。
java -jar PROGRESS_DATADIRECT_JDBC_SF_ALL.jar
3, 対話形式のJavaインストーラーが起動され、ライセンス版または評価版のSalesforce JDBCドライバを目的の場所にインストールできます。
備考:同じフォルダにSalesforce JDBCドライバと他のお試しドライバもインストールされますので、色々試せます。
Google Cloud Data Flow SDKとプロジェクトのセットアップ
1, Googleのクイックスタートの「始める前に」セクションの手順を完了します。
2, Eclipseでファイル ->新規 -> プロジェクト より新規プロジェクトを作成します。
3, Google Cloud Platformディレクトリで、Google Cloud Dataflow Java Projectを選択します。

4, グループ IDおよびアーティファクトIDを入力します。
5, ドロップダウンから簡単なパイプラインを使用して、プロジェクトテンプレートをスタータープロジェクトとして選択します。
6, Data Flowバージョンを2.2.0以上として選択します。
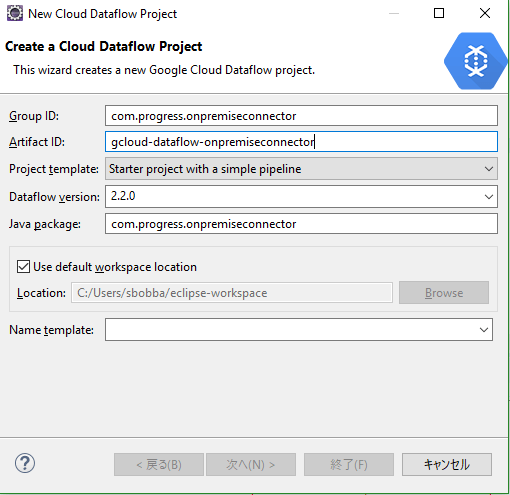
7, Nextをクリックすると、プロジェクトが作成されます。
8, Avenge BeamのJDBC IOライブラリをmavenとDataDirect Salesforce JDBCドライバからビルドパスに追加します。Salesforce JDBCドライバはインストールパスで見つけることができます。
パイプラインの作成
1, Salesforceへの接続、データの読み取り、簡単な変換を適用してBigQueryに書き込んでみます。このプロジェクトのコードは、参照用としてこちら(GitHub)にアップロードされています。
2, StarterPipeline.javaファイルを開き、main関数のすべてのコードをクリアします。
3, まず最初に、下記のとおりパイプラインを作成します:
Pipeline p = Pipeline.create(
PipelineOptionsFactory.fromArgs(args).withValidation().create());
4, これはパイプラインを構成するためにプログラムへの入力引数を使用するものです。
5, DataDirect Salesforce JDBCドライバを経由してSalesforceに接続し、下記に示すように、JdbcIO. read()メソッドを使用してPCollectionにデータを読み込みます。
PCollection<List<String>> rows = p.apply(JdbcIO.<List<String>>read()
.withDataSourceConfiguration(JdbcIO.DataSourceConfiguration.create(
"com.ddtek.jdbc.sforce.SForceDriver", "jdbc:datadirect:sforce://login.salesforce.com;SecurityToken=<Security Token>")
.withUsername("<username>")
.withPassword("<password>"))
.withQuery("SELECT * FROM SFORCE.NOTE")
.withCoder(ListCoder.of(StringUtf8Coder.of()))
.withRowMapper(new JdbcIO.RowMapper<List<String>>() {
public List<String> mapRow(ResultSet resultSet) throws Exception {
List<String> addRow = new ArrayList<String>();
//Get the Schema for BigQuery
if(schema == null)
{
schema = getSchemaFromResultSet(resultSet);
}
//Creating a List of Strings for each Record that comes back from JDBC Driver.
for(int i=1; i<= resultSet.getMetaData().getColumnCount(); i++ )
{
addRow.add(i-1, String.valueOf(resultSet.getObject(i)));
}
//LOG.info(String.join(",", addRow));
return addRow;
}
})
)
6, PCollection内のデータを取得したら、ParDoを使用してPCollection内のすべての項目を繰り返して処理することにより、下記に示すように、transformをapplyしてデータ(コメント)の任意のカラムのデータをhashします。
.apply(ParDo.of(new DoFn<List<String>, List<String>>() {
@ProcessElement
//Apply Transformation - Mask the EmailAddresses by Hashing the value
public void processElement(ProcessContext c) {
List<String> record = c.element();
List<String> record_copy = new ArrayList(record);
//String hashedEmail = hashemail(record.get(11));
//record_copy.set(11, hashedEmail);
c.output(record_copy);
}
}));
7, 次に、List 形式の各行のPCollectionをBigQueryモデルのTableRowオブジェクトに変換します。
PCollection<TableRow> tableRows = rows.apply(ParDo.of(new DoFn<List<String>, TableRow>() {
@ProcessElement
//Convert the rows to TableRows of BigQuery
public void processElement(ProcessContext c) {
TableRow tableRow = new TableRow();
List<TableFieldSchema> columnNames = schema.getFields();
List<String> rowValues = c.element();
for(int i =0; i< columnNames.size(); i++)
{
tableRow.put(columnNames.get(i).get("name").toString(), rowValues.get(i));
}
c.output(tableRow);
}
}));
8, 最後に、下記に示すようにBigQueryIO.writeTableRows()メソッドを使用してBigQueryにデータを書き込みます。
//Write Table Rows to BigQuery
tableRows.apply(BigQueryIO.writeTableRows()
.withSchema(schema)
.to("nodal-time-161120:Salesforce.NOTE")
.withWriteDisposition(BigQueryIO.Write.WriteDisposition.WRITE_APPEND));
備考: パイプラインを実行する前に、BigQueryコンソールでSalesforceテーブルと同じスキーマでテーブルを作成します。
9, 参照用として、このプロジェクトのすべてのコードは こちら(GitHub) 内にあります。
パイプラインの実行
1, GRun > Run Configurationsに進みます。パイプライン引数の下に、パイプラインを実行するための2つのオプションが表示されます。
1)DirectRunner – ローカルでパイプラインを実行
2)DataFlowRunner –Google Cloud DataFlow上でパイプラインを実行
2, ローカルで実行する場合は、RunnerをDirectRunnerに設定して実行します。パイプラインの実行が完了すると、Google BigQueryにSalesforceデータが表示されます。
3, Google Cloud Data Flow上でパイプラインを実行する場合は、RunnerをDataFlowRunnerに設定し、下記に示すように、アカウント、プロジェクトID、ステージング場所を選択していることを確認します。
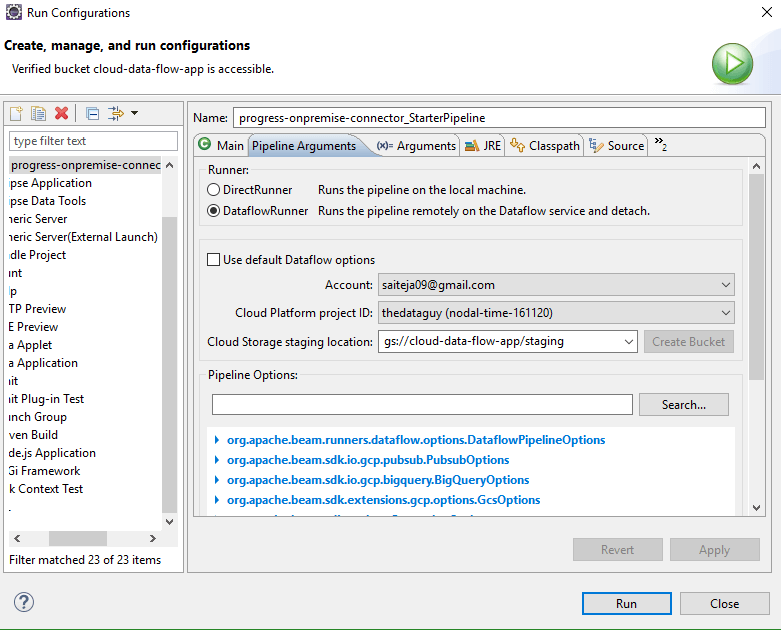
4, Argumentsの下にある Program Argumentsで、BigQuery WriteのtempLocationへのパスを設定し、下記に示すように一時ファイルを保存します。

5, Runをクリックすると、Google Data Flowコンソールに新規のジョブが開始されることが確認できます。ジョブ上をクリックすると、進行状況を追跡することができ、各ステージのステータスを示すフローチャートが表示されます。

6, パイプラインが正常に実行されると、Google BigQueryコンソールでテーブルのクエリを実行して、すべてのデータを参照することができます。

以上、簡単ですね!