とあるトラブルシューティングにおける覚書(まだ公開されていない情報を含む可能性があるため、結果は一部ぼかしておく)。
現象
DBサーバでとある操作をするとSTANDBYサーバでCPU使用率が高騰する。
初動
なんとなく遅いとか、とあるトランザクションのレイテンシが2倍だとか、エラーになったとかいう類の問題と違って、CPU使用率の高騰という事象は明確である。ただし、事象を説明するのにまだ十分に具体的ではない(そもそもCPU使用率が高騰すること自体は悪ではなく、むしろIO待ちもなく効率的にお仕事をしてくれているよい兆候である可能性もある。この場合は明らかになにか無駄な処理をしていると想定された)。
とにかくトラブルシューティングの初動において重要なのは、事象を正確かつ具体的に記述できるようにすることになる(5W1Hを掘り下げていく)。
真っ先に確認すべきポイントは、例えば以下のようなものになる。
- 具体的なCPU使用率(HOW)
- 具体的に何のプロセス(または複数)がCPUを使用しているか (WHO)
- 具体的にどのレベルでCPUを飽和させているか、ユーザ空間か、カーネル空間か(WHERE・WHAT)
- その事象はいつ発生するか(WHEN)→このケースではまさに今この瞬間であるが、きっかけとなった動作はなにか
- システムのどのコンポーネントで発生しているか(WHERE)→このケースではSTANDBYのDBサーバ
- なぜその事象が発生するのか(WHY)→このケースではこれを明らかにするのがとりあえずのゴール(真のゴールは当然事象の解消・解決)
何のプロセスが具体的にどれくらいCPUを使用しているか
これはOSのtopコマンドやpidstatコマンドで観測できる。まずはtopを実行するのがわかりやすい。
top -d1
top - 22:57:50 up 1:01, 2 users, load average: 1.12, 1.10, 1.11
Tasks: 354 total, 1 running, 353 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.9 us, 8.4 sy, 0.0 ni, 81.5 id, 0.0 wa, 0.0 hi, 0.1 si, 0.0 st
KiB Mem : 16266584 total, 14474140 free, 625108 used, 1167336 buff/cache
KiB Swap: 2101244 total, 2101244 free, 0 used. 14733996 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5573 appuser 20 0 3800348 896120 664472 S 101.0 5.5 55:24.00 <TARGET>
6854 root 20 0 162144 2508 1596 R 0.7 0.0 0:07.21 top
6727 root 20 0 159228 6160 4788 S 0.3 0.0 0:00.81 sshd
幸運なことに非常にわかりやすく、被疑プロセスは1つのみだった(%CPUが101.0になっているPID 5573のプロセス)。このサーバは複数コアを搭載しているので、被疑プロセスは100%のCPUを使用しているものの、全体としては80%近くがIDLE状態であることがわかる。そして、wa(IOウェイト)が0.0であることから、ディスクIOのリソース競合が発生しているわけではないということもわかる。ユーザ空間(us)なのかカーネル空間(sy)なのかは、システム全体で丸められているので、この時点ではどちらともつかない(他のプロセスがおとなしいので、おそらく被疑プロセスの状況をある程度色濃く反映していると思ってもよさそうではある)。
個別プロセスのリソース利用状況をprtstatとpidstatでもう少し深く調べてみる。
※以降では被疑プロセスのプロセスIDを$PIDと記載する(入力コマンド)
prtstat $PID
Process: <TARGET> State: S (sleeping)
CPU#: 1 TTY: 0:0 Threads: 43
Process, Group and Session IDs
Process ID: 5573 Parent ID: 5571
Group ID: 5573 Session ID: 4393
T Group ID: -1
Page Faults
This Process (minor major): 187723 21
Child Processes (minor major): 0 0
CPU Times
This Process (user system guest blkio): 3107.80 2756.89 0.00 0.11
Child processes (user system guest): 0.00 0.00 0.00
Memory
Vsize: 3891 MB
RSS: 917 MB RSS Limit: 18446744073709 MB
Code Start: 0x400000 Code Stop: 0x45a40c
Stack Start: 0x7ffc0d830f70
Stack Pointer (ESP): 0x7ffc0d830bb0 Inst Pointer (EIP): 0x7f5bdfb04f47
Scheduling
Policy: normal
Nice: 0 RT Priority: 0 (non RT)
CPU Timesの項目から、やはりユーザ空間(user)でやや多く、カーネル空間(system)でも多くのCPU時間を使用しており、ディスクIO(blkio)はほとんどないことが再確認できる。
# -u: CPU使用率を出力
# -I: CPUコアごとに出力
# 1 5: 1秒間隔5回
pidstat -p $PID -u -I 1 5
Linux 3.10.0-957.el7.x86_64 (db1) 2019年06月07日 _x86_64_ (3 CPU)
23時07分54秒 UID PID %usr %system %guest %CPU CPU Command
23時07分55秒 2000 5573 51.92 48.08 0.00 41.60 1 <TARGET>
23時07分56秒 2000 5573 58.00 44.00 0.00 43.22 1 <TARGET>
23時07分57秒 2000 5573 54.90 46.08 0.00 42.56 1 <TARGET>
23時07分58秒 2000 5573 51.49 48.51 0.00 42.44 1 <TARGET>
23時07分59秒 2000 5573 55.34 45.63 0.00 43.33 1 <TARGET>
平均値: 2000 5573 54.31 46.47 0.00 42.62 - <TARGET>
pidstatでも目新しい情報はない。3つのCPUを搭載していて、CPU#1をほぼ占有している様が見て取れる(あくまでもサンプリングした1秒5回の間は)。
さらに-tオプションを付与することで、どのスレッドが騒がしいのかを確認可能。
pidstat -p $PID -u -I -t 1 1
23時08分01秒 UID TGID TID %usr %system %guest %CPU CPU Command
23時08分02秒 2000 5573 - 59.22 41.75 0.00 42.28 1 <TARGET>
23時08分02秒 2000 - 5573 0.00 0.00 0.00 0.00 1 |__<TARGET>
23時08分02秒 2000 - 5575 0.00 0.00 0.00 0.00 0 |__<TARGET>
23時08分02秒 2000 - 6125 59.22 40.78 0.00 41.87 1 |__<TARGET>
23時08分02秒 2000 - 6563 0.00 0.00 0.00 0.00 0 |__<TARGET>
スレッド#6125(TID)が元気よく動いていることが明白になった。
なお、pidstatがインストールされていなければ、psが使える("-L"オプションを付与すればスレッド情報も得られる)。
ps -p $PID -Lf
UID PID PPID LWP C NLWP STIME TTY TIME CMD
appuser 5573 5571 6123 0 43 6月07 ? 00:00:00 <TARGET>
appuser 5573 5571 6125 99 43 6月07 ? 02:07:51 <TARGET>
appuser 5573 5571 6127 0 43 6月07 ? 00:00:00 <TARGET>
C列がCPU使用率(man上では100%を超えてカウントしないと書いてある)になる。NLWP(Number of Light Weight Process)はスレッド数。LWPがスレッドID。
これだとどのCPU上で動作しているかまではわからないので、必要であれば例えば以下のように出力をカスタマイズする(ついでに少し余分な項目も出力させてみる)。
# -L: スレッド情報出力
# -o: 出力項目指示
# tid: thread id, c: CPU使用率, sgi_p: どのCPUか
# cls: スケジューラクラス, ni: NICE値, pri: スケジューラプライオリティ, rtprio: リアルタイムスケジューラのプライオリティ
ps -p $PID -L -otid,c,sgi_p,cls,ni,pri,rtprio
TID C P CLS NI PRI RTPRIO
6123 0 * TS 0 19 -
6125 99 1 TS 0 19 -
6127 0 * TS 0 19 -
sgi_pでその瞬間(つまりpsコマンドがサンプリングしにいったタイミング)でそのプロセスまたはスレッドがどのCPU上で動いていたかを表示できる。CLSはCPUのスケジューラでTS(デフォルトのTimeSharing)で動作している。
とにかくここまでで、特定プロセスの特定のスレッドが、1つのCPUをほぼ占有して動作しており、ユーザ空間とカーネル空間とは6:4くらいの割合であるということがわかった。
次は、この騒がしいスレッドが一体なににCPU時間を費やしているのかを探ることになる。
当該プロセス・スレッドは具体的に何をしているのか
実行中のプロセスが何をしているかを調べるのにstraceが使えるが、干渉性が高いので使用には注意が必要になる。場合によってはこの干渉によって当該事象が発生しなくなったり、別の問題が発生する可能性もある。
そこで便利なのがシステムコールを何回実行したかをカウントしてくれるperfやstap(systemtap)、dtraceといった観測ツールになる。
ただし、stapやdtraceはスクリプトを自分で書かなくてはならないので、ある程度型にはまった調査のためにはperfが容易に使えてかつ使いようによってはかなり深い洞察が得られる。
今回は対象プロセスがわかっているので、当該プロセスのみを対象にいろいろと調べてみる。
# stat: 基本統計を出力
# -p: 指定したPIDのプロセスを対象(システム全体を対象とする場合は"-a"指定)
# -d: 詳細情報出力
perf stat -p $PID -d sleep 1
これでsleep 1を実行している間、つまり1秒間の統計を取ってくれる。
Performance counter stats for process id '5573':
1006.984534 task-clock (msec) # 0.998 CPUs utilized
121 context-switches # 0.120 K/sec
4 cpu-migrations # 0.004 K/sec
5 page-faults # 0.005 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
<not supported> L1-dcache-loads
<not supported> L1-dcache-load-misses
<not supported> LLC-loads
<not supported> LLC-load-misses
1.009087391 seconds time elapsed
この環境では残念ながらCPUサイクルや命令、分岐数といった細かなCPU統計は取得できない(仮想環境にありがち)。
ここからわかるのは、約1秒の間ほとんどCPUを使っていたということと、context-switch(実行コンテキスト切替え、つまりユーザ空間とカーネル空間の切替え)はそれほど頻繁ではなさそうとういことくらい(あまり目新しい情報はない)。
次にstarceのかわりにどんなシステムコールを実行しているのかを調べる。
# -e: カウントするイベントを指定(ワイルドカード可)
# 指定可能なイベントのリストは`perf list`で確認できる
perf stat -p $PID -e 'syscalls:*' sleep 1
0 syscalls:sys_exit_getcwd
454,232 syscalls:sys_enter_select
454,246 syscalls:sys_exit_select
0 syscalls:sys_enter_pselect6
...
0 syscalls:sys_exit_setns
91 syscalls:sys_enter_nanosleep
90 syscalls:sys_exit_nanosleep
0 syscalls:sys_enter_timer_create
1秒間にselectシステムコールが40万回以上コールされていることがわかる。もう少し具体的にコールしている部分がどうなっているのかも調べてみる。
perf top -p $PID
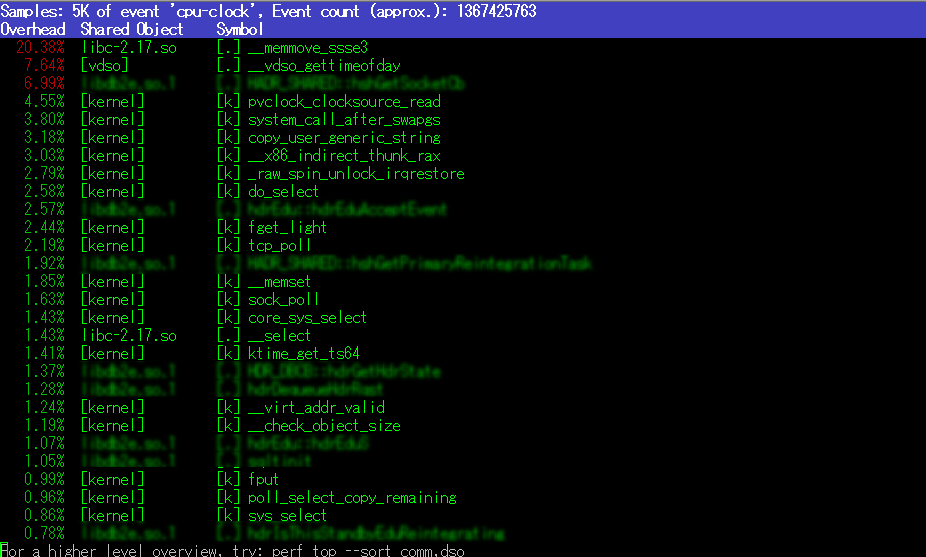
Zoom-inしていくとアセンブラのコードも出てくる。
わかる人が見ればわかるかもしれないが、今のところはご勘弁。
ちなみに、perf top -p $PID --sort comm,dsoとすると概要レベルな出力になる。
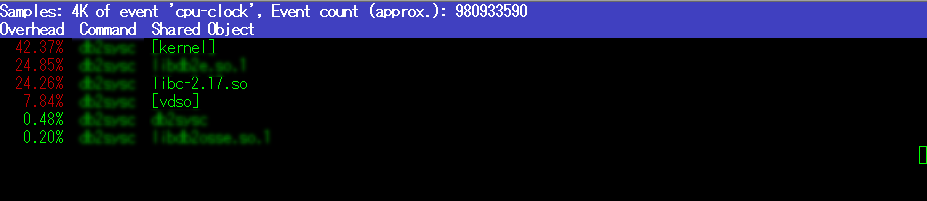
とにかく、ここまででデータレプリケーションを担当するスレッドがCPU高騰の犯人だとあたりがついた(図中はぼかしてしまっているがレプリケーションスレッドであることは名前から明白)。秒間数十万回というselectコール回数からも、おそらくはコードのバグ(不適切なループ)であることがうかがえる。これらの情報を作った人に伝えてWHYについて明らかにしてもらい、解決して(直して)もらうしかない。
ちなみにstrace -f -e trace=select -p $PIDとしてみると、通常時はタイムアウト指定が100000 μs、つまり100 msであり、多くても秒間10回しか実行されないこと、当該事象発生時はselectが非0を返しているにもかかわらず、メインの処理を実行するのではなく再度selectしていることも見て取れた。