強化学習を勉強したい
普段私は業務でAI/機械学習に触れています。
ただ今までは教師あり学習を中心に勉強してきたのもあり、教師なし学習や強化学習についてあまり触れたことが無いなと思いました。
そこで昨日、強化学習ハンズオンに最適なこちらの記事を拝見し、実際自分もやってみようと。
やるにしても何かテーマが欲しいなぁと思いつつ記事を眺めていると、エージェントの動きに「あれこれ酔っ払いみたいじゃね?」と感じてしまいました。
こちらの記事では、始点から終点までの最適経路を求める強化学習をテーマとしていました。
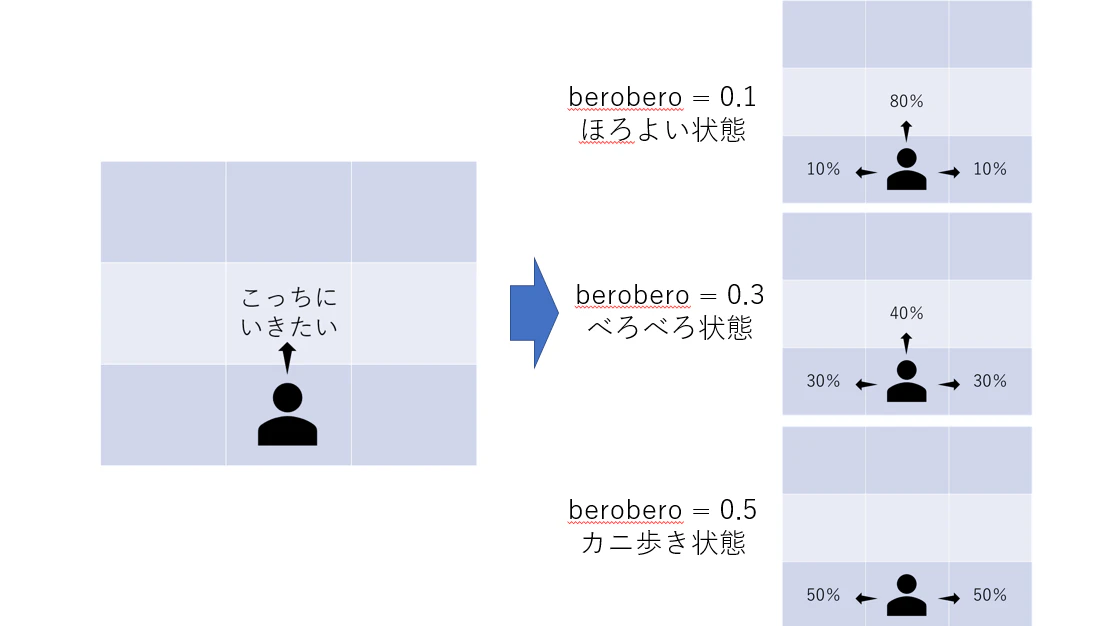
エージェントは80%の確率で希望の方向に進み、10%の確率で左方向、10%の確率で右方向へ行ってしまう設定になっています。

これを使えば「酔っ払いの挙動を再現できるのでは・・・?」と思い、ハンズオンがてら実験してみました。
コロナ前、__居酒屋でべろべろになった記憶__を思い出しながらご覧ください。
こちらの記事もむちゃくちゃ便利ですのでご覧になってくださいね。
サンプルコード
ほぼこちらの記事にある通りで、__酔っ払い変数berobero__を導入するために一部改変しています。
定義したメソッドの中身については↑の記事にあるGithubを参照ください。
改変した箇所だけ取り出します。
# 抽象クラス
class MDP:
#MDP:マルコフ決定過程(Markov decision processes
#引数に酔っ払い度合いberoberoを定義
def __init__(self, init, actlist, terminals, gamma=.9,berobero=0.1):
#init:初期状態
#actlist:行動
#erminals:終了状態
#gamma:割引関数
self.init = init
self.actlist = actlist
self.terminals = terminals
# 具象クラス
class GridMDP(MDP):
#引数に酔っ払い度合いberoberoを定義
def __init__(self, grid, terminals, init=(0, 0), gamma=.9,berobero=0.1):
#gridは場を定義する行列
grid.reverse() # because we want row 0 on bottom, not on top
MDP.__init__(self, init, actlist=orientations,
terminals=terminals, gamma=gamma,berobero=berobero)
self.grid = grid
self.berobero=berobero
self.rows = len(grid)
self.cols = len(grid[0])
#遷移確率と次の行動のリスト
#berobero=0がしらふ、0.1がほろよい、0.3でべろべろなイメージ
#berobero=0.5で確実に蟹歩きになるので一周回って大丈夫的な
def T(self, state, action):
if action is None:
return [(0.0, state)]
else:
return [(1-2*self.berobero, self.go(state, action)),
(self.berobero, self.go(state, turn_right(action))),
(self.berobero, self.go(state, turn_left(action)))]
問題設定
始点から終点までエージェントが進むときに、報酬が最大になるような進み方を探します。
エージェントは一定の確率で希望とは違う方向にすすむ。beroberoの確率で左、beroberoの確率で右、1-2*beroberoの確率で希望通りの方向に進めます。
なので、__berobero=0がしらふ、0.1がほろよい、0.3でべろべろなイメージ__です。
berobero=0.5で確実にカニ歩きになるので「一周回って大丈夫な人」をイメージしてください。
酔っぱらった時は壁沿いを歩く
実際に自分が酔っぱらった時、壁に手をついて壁沿いに移動したりしませんか?
座敷なんかだと__「間失礼しまーす」と通るのが怖いので、最短で壁までいって壁に沿って移動するイメージ__があります。
これをちょっとシミュレーションしてみたいと思います。
出口の近くに人がいる時
まずはこちらの記事の例を使って検証してみます。
お店には柱が一本あり、出口のそばに人が一人いるパターンを考えます。
人にぶつからずに出口に出られる最適な経路を導きます。

酔っ払いなのであれば可能な限り右にすすんで人にぶつかるリスクは負いたくないものです。
なので__直観的には上にいって突き当たってそのまま右にいくのが良さそう__です。
lossはそこに行ったときにもらう報酬で、-0.5にすると「移動するごとに-0.5される」みたいな部屋になります。
報酬のマイナスが大きいほど可能な限り最短で移動しようとします。
「早く出口に行かないと吐いちゃうぅぅぅ」みたいな設計はlossを使えばできそうですね。(今回はやりません)
# もともとのパターン
loss = 0
grid=[
[loss, loss, loss, +1],
[loss, None, loss, -1],
[loss, loss,loss,loss]
]
# 左下から数える
sequential_decision_environment = GridMDP(grid,terminals=[(3, 2), (3, 1)],berobero=0.1)
pi = best_policy(sequential_decision_environment, value_iteration(sequential_decision_environment, .01))
print_table(sequential_decision_environment.to_arrows(pi))
ほろよいパターン
berobero=0.1の場合はこちら。
見方としては「そのマスからどっち向きに移動するのがもっとも妥当か」を矢印にして出力しています。
この場合、「始点から上へ行き右へ行くルートが最適だ」という結果になります。
直観的にも妥当そうですね。

べろべろパターン
berobero=0.3の場合はこちら。
面白いのは最初に左を向こうとするんですよね。
__意地でも右方向には行かないという意志__を感じます。
終点に入る直前も上方向を向くことで「右方向、最悪左に戻ってもよし」みたいにしているのが面白い。

カニ歩きパターン
berobero=0.5の場合がこちら。
もうこれ「やべぇ酔いすぎた・・・横方向に着実にすすんでいこ・・・」という強い意志を感じます。
右を向いて横歩きし、上を向いて横歩きすることで難なくゴール。
前に進めないことを逆手に取った悟りの境地を感じますね。
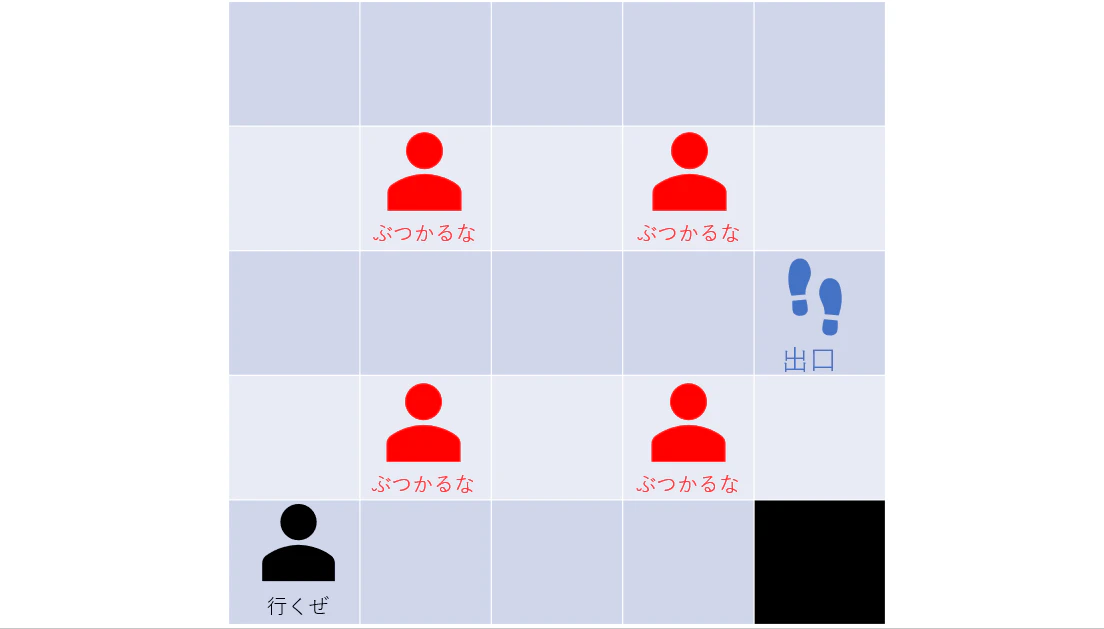
4つの座敷卓の飲み会から脱出する時
さて、いよいよ実践編です。
4つの卓の飲み会の奥の席から脱出することを考えます。
4つの卓を疑似的に4人の人に見立て、「間失礼しまーす」しながら出口へ行くか、遠回りでも壁沿いに行くかを見てみます。
ほろよいパターン
berobero=0.1の場合はこちら。
この場合は「間失礼しまーす」のパターンですね。
酔っぱらっていないので間を抜けても大丈夫だろう的な気持ちを感じます。

べろべろパターン
berobero=0.3の場合はこちら。
これです!!壁伝いに行こうとする強い意志を感じますね!!
酔っぱらったときはとにかく壁沿いにすすんで無難に行くべし!!
ふと思ったんですがberobero=0.1にしてこれにならない理由って何故なんでしょう?
loss=0なので遠回りするデメリットは無いはずですし、これなら確実です。
ご存じの方はご教示いただけると嬉しいです!

カニ歩きパターン
berobero=0.5の場合がこちら。
前に進めないことを逆手にとってカニ歩きしているのがなんか面白いですね
べろべろになりすぎて危機感感じて冷静になっている姿がありありと浮かびます。

遠回りにもリスクがあるとき
先ほどは遠回りにリスクがありませんでしたが、今回は少しリスクをつけてみます。
近道で行こうが遠回りで行こうが「間失礼しまーす」が生じ、遠回りすると道が太くより安全に右側に進めるシチュエーションを考えます。
こんな居酒屋あるかい。

ほろよいパターン
berobero=0.1の場合はこちら。
この場合は右向きに「間失礼しまーす」のパターンですね。
スタート地点で下方向を向いている現象って何故でしょう・・・?
「いやだぁあ出口行きたくなアアアアイィ」的な厭世的な嘆きを感じます。

べろべろパターン
berobero=0.3の場合はこちら。
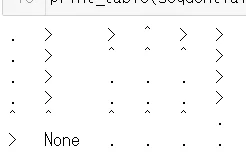
安全択を取ったパターンですね。
None一つ上の場所で左を向くことで「右には絶対行かない」という強い意志を感じます。
カニ歩きパターン
berobero=0.5の場合がこちら。
カニ歩きを習得すれば人込みなぞ何のその。
さいごに
今回は強化学習ハンズオンが目的だったので条件検討はまだまだ甘いかもしれません。
特にloss=0で設定したので、そこが変わることによる挙動変化もみたいですね。
また今回は価値反復法という手法をモデルにしましたが、Q-learningについても実装してみたい。
そしてお酒はほどほどに楽しく飲みましょう!!!!
最後まで読んでいただきありがとうございました!
是非是非LGTMしてくれると嬉しいです。