この記事でやること
この記事ではMicrosoft Purviewのコレクション情報をREST APIで取得して各コレクションに登録されたユーザやマネージドIDのオブジェクトIDの一覧を取得します。
コレクション情報の取得
接続情報などの設定
今回はInteractiveBrowserCredentialを使っているので、アプリ登録せずにデータ取得できます。トークン取得時にブラウザが立ち上がって認証情報を入力する流れになります。
import json
import sys
from pprint import pprint
import pandas as pd
import requests
from azure.identity import InteractiveBrowserCredential
from flatten_json import flatten
TENANT_ID = ""
RESOURCE_URL = "https://purview.azure.net/.default"
PURVIEW_ACCOUNT_NAME = ""
# アクセストークンの取得
endpoint = f"https://{PURVIEW_ACCOUNT_NAME}.purview.azure.com"
credential = InteractiveBrowserCredential(tenant_id=TENANT_ID)
token = credential.get_token(RESOURCE_URL).token
コレクション情報の取得
コレクションの一覧を取得してデータフレームにします。
def get_collection_list():
url = f"{endpoint}/collections?api-version=2019-11-01-preview"
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
response = json.loads(requests.request(
"GET", url, headers=headers).content)
return response
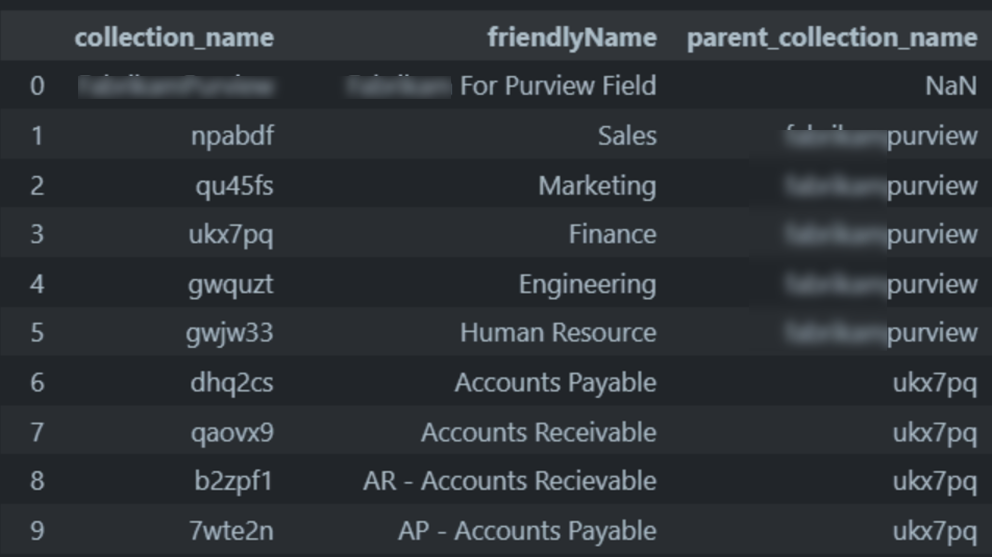
collections = get_collection_list()
df_collections = (pd.json_normalize(collections["value"])
.filter(["name", "friendlyName", "parentCollection.referenceName"])
.rename(columns={"name": "collection_name", "parentCollection.referenceName": "parent_collection_name"})
)
ルートコレクション以外はシステムに付与されたコレクション名が付き、表示されるコレクション名はfriendlyNameに格納されているようです。
コレクションに設定されているロールとユーザ情報を取得
コレクションに設定されているロールやユーザの情報がJSONで返るので必要な情報だけ抜き出します。
def get_collection_policies():
url = f"{endpoint}/policystore/metadataPolicies?api-version=2021-07-01-preview"
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json"
}
response = json.loads(requests.request("GET", url, headers=headers).content)
return response
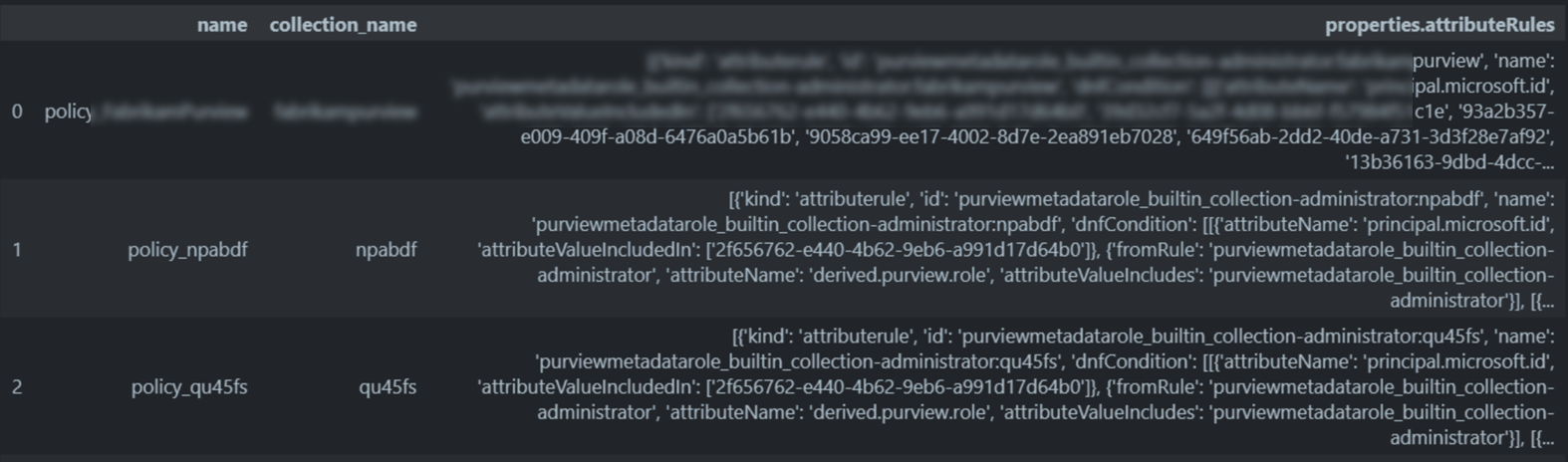
collection_policy = get_collection_policies()
df_collection_policy = (pd.json_normalize(collection_policy["values"])
.filter(["name", "properties.collection.referenceName", "properties.attributeRules"])
.rename(columns={"properties.collection.referenceName": "collection_name"})
)
properties.attributeRulesにコレクション管理者やデータ キュレーターなどのロールのIDとそこにアサインされているユーザやサービスプリンシパルのオブジェクトIDがJSONの配列として格納されています。
JSONをフラット化してコレクションのリストを作ります。
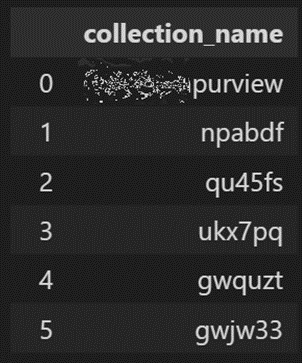
collection_policy_flattened = [flatten(d) for d in collection_policy["values"]]
df_collection_policy_flattened = pd.json_normalize(collection_policy_flattened)
df_collection = (df_collection_policy_flattened
.filter(["properties_decisionRules_0_dnfCondition_0_0_attributeValueIncludes"])
.rename(columns={"properties_decisionRules_0_dnfCondition_0_0_attributeValueIncludes": "collection_name"})
)
JSONをフラット化したデータフレームからオブジェクトIDを抜き出します。結合用に元のインデックスをold_indexとして残しておきます。また、結合用にもう一つJSON Pathから作成された情報をsub_pathとして追加します。
def sub_path(x):
y = x.split("_")[0:5]
return "_".join(y)
df_object_id = (df_collection_policy_flattened.filter(like="attributeValueIncludedIn")
.stack()
.explode()
.reset_index()
.rename(columns={"level_0": "old_index", "level_1": "path", 0: "object_id"})
)
df_object_id["sub_path"] = df_object_id["path"].apply(sub_path)

ロールも同じように抜き出します。
df_role = (df_collection_policy_flattened
.filter(regex="^properties_attributeRules.*attributeValueIncludes$")
.stack()
.explode()
.reset_index()
.rename(columns={"level_0": "old_index", "level_1": "path", 0: "role_id"})
)
df_role["sub_path"] = df_role["path"].apply(sub_path)

データの加工
コレクション毎のロールとユーザなどのオブジェクトIDを結合します。
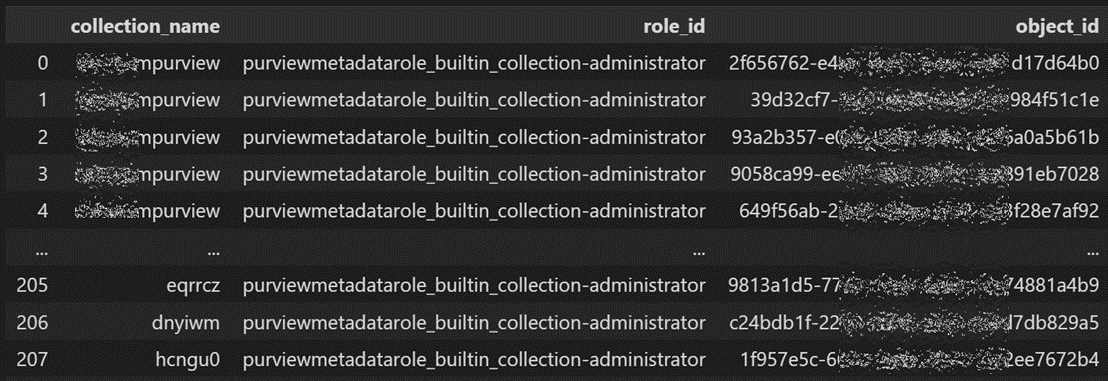
df_role_object = (pd.merge(df_role, df_object_id, on=["old_index", "sub_path"])
.filter(["old_index", "role_id", "object_id"])
)

コレクションと結合します。
df_collection_role_object = (pd.merge(df_collection, df_role_object, left_index=True, right_on="old_index")
.filter(["collection_name", "role_id", "object_id"])
)
さらにコレクションのフレンドリ名や親コレクションの情報と結合します。
df_collection2 = pd.merge(df_collections, df_collection_role_object)
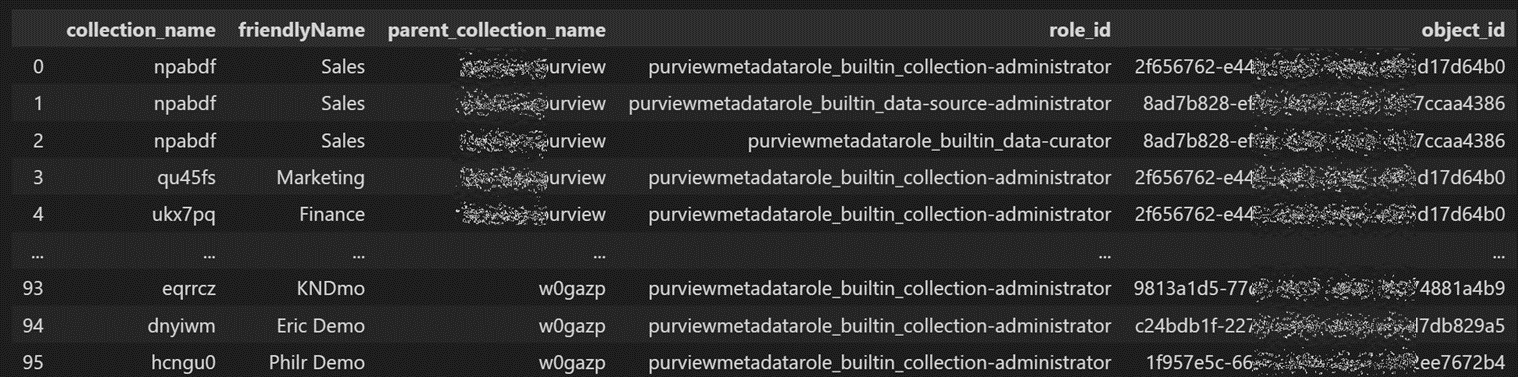
ロール名が分かりにくいので情報を与えます。
df_role = pd.DataFrame(
data={
"role_id": [
"purviewmetadatarole_builtin_collection-administrator",
"purviewmetadatarole_builtin_data-source-administrator",
"purviewmetadatarole_builtin_data-curator",
"purviewmetadatarole_builtin_purview-reader",
"purviewmetadatarole_builtin_data-share-contributor",
"purviewmetadatarole_builtin_insights-reader",
"purviewmetadatarole_builtin_workflow-administrator",
"purviewmetadatarole_builtin_policy-author"
],
"role_display_name": [
"Collection admins",
"Data source admins",
"Data curators",
"Data readers",
"Data share contributors",
"Insights readers",
"Workflow admins",
"(non-display) Policy authers",
],
}
)
df_collection3 = (pd.merge(df_collection2, df_role, on="role_id")
.filter(["collection_name", "friendlyName", "parent_collection_name", "role_display_name", "object_id"])
)

これでコレクションの表示名とそこに設定されたロール名と登録されたユーザのオブジェクトIDが一覧になりました。
オブジェクトIDからユーザ名やManaged IDの情報を得るにはMicrosoft Graph Core Python client libraryあたりが使えるかなと思います。