自作物体検出アプリの処理速度を改善したい!
動画から物体検出するアプリの画像処理にOPENCVを利用しています。
物体検出はTensorRT、DirectMLで行っていますが、どちらで実行しても私の環境ではGPU負荷が50%に満たない程度となっていました。もっとGPUを使うことができればさらに高速に処理できるのではないか?と思っていたものの、原因がよくわからずモヤモヤしていました。(何かハードウェア負荷を制限・解除するようなオプションがいるのかなー?とか思ってた)
Windows Copilotとそんなやり取りをしていると、OPENCV-CUDAやOPENCV-OPENCLなどのハードウェアサポートを利用することや並列処理を行うことでスループットがあがり、またGPU負荷も上がってくるのではないか?と提案されました。
なるほど、アプリの動画の入出力は別スレッドになっていますが、前処理>物体検出>後処理>画像処理は、同期処理となっており、GPUに待ちが発生している可能性がありそうかも?
また前処理や後処理、画像処理にはプリビルドのOPENCVを利用しており、CPU処理となっていたので、GPUの待ちが発生しやすい状況となっている可能性もありそうです。
さらにいえば、各処理を非同期処理にすればスループットがさらにあがるのではないか?
非同期化するのは私にとっては結構大変なので、まずは着手しやすそうなOPENCVのハードウェアサポートを有効にしスループットの改善に着手してみることにしました。
OPENCVのビルドから。
環境
Windows11pro
OPENCV 4.13dev
VisualStudio2022
INTEL 11400F
NVIDIA GEFORCE 4070TiS
OPENCVのビルドオプションの選定
OPENCLはともかく、CUDAはOPENCVをビルドしないといけません。
またアプリを配布するので、なんでもかんでもビルドするのではなく、必要な機能に厳選した状態でビルドした方がビルド時間もファイルサイズも良いだろう、と考え、アプリで利用しているOPENCVの機能をCopilotに投げかけて、必要なCUDAの機能を確認しました。
アプリで使ってるOPENCVの機能(順不同、漏れもあるかも)
- resize
- copyTo
- convertTo
- GaussianBlur
- imread
- imwrite
- dnn::NMSBoxes
- rectangle
- inpaint
- dnn::blobFromImage
適用したビルドオプション
CUDA関係
- BUILD_opencv_cudaarithm
- BUILD_opencv_cudafileters
- BUILD_opencv_cudaimgproc
- BUILD_opencv_cudawarping
- BUILD_opencv_cudadev
- CUDA_FAST_MATH
- WITH_CUDA
- CUDA_USE_STATIC_CUDA_RUNTIME
- CUDA_ARCH_BIN 7.5;8.6;8.9;12.0
- CUDA_ARCH_PTX 7.5;8.6;8.9;12.0
OPENCL関係
- WITH_OPENCL
- WITH_OPENCL_SVM
OPENCV標準モジュール関係
- BUILD_opencv_dnn
- BUILD_opencv_imgcodecs
- BUILD_opencv_imgproc
- BUILD_opencv_photo
- BUILD_opencv_world
ビルドオプション選定の理由
標準モジュールもデフォルト入ってくるVIDEOIOやWITH_FFMPEG、HIGHGUI、GAPIやADEなど使わないものは外しました。
CUDA、OPENCLも、使わない機能は入れていません。CUDNNやOPENCV_DNN_OPENCLがないのは、物体検出自体はTensorRTやDirectMLで行うようにしており、NMSBoxesなんかでは機能しないらしいからです。CPU処理になるんだとか。
また例えばInpaintなんかはCUDA、OPENCLではサポートされておらず、CPU処理になるんだとか?
じゃあ、CPUで処理する時でも、ちょっとでも早くする方法はないのかな?
OPENCVのCPU関係のビルドオプション
OPENCVでは、IPPやTBBというものがCPUのハードウェアサポートらしいです。
IPPとは(Intel® Integrated Performance Primitives)
インテル® インテグレーテッド・パフォーマンス・プリミティブ(インテル® IPP)は、多様なインテルアーキテクチャ向けに高度に最適化された、すぐに使えるドメイン固有関数の広範なライブラリです。ロイヤリティフリーのAPIは、開発者に以下のメリットをもたらします。
- SIMD(単一命令複数データ)命令を活用する
- 信号処理、データ圧縮、画像処理、ビデオ処理、コンピューター ビジョンなどの計算集約型アプリケーションのパフォーマンスを向上させます。
- ソフトウェア開発と保守にかかるコストと市場投入までの時間を削減
SIMDという仕組みを使って処理速度を向上させるもののようです。
TBBとは(Intel® oneAPI Threading Building Blocks)
並列アプリケーションの簡素化された開発
インテル® oneAPI スレッディング・ビルディング・ブロック (oneTBB)† は、スレッド化の専門家でなくても、アクセラレーションされたアーキテクチャー全体にわたって複雑なアプリケーションに並列処理を追加する作業を簡素化する柔軟なパフォーマンス・ライブラリーです。
oneTBB は、次のような幅広い計算負荷の高いドメインに最適です。
こちらはスレッドを利用して処理速度を向上させるもののようです。
OPENCVでIPP、TBBを有効にする
それぞれ、WITH_IPP、WITH_TBBを有効にすれば適用されるようですが、Windowsではそれぞれ別に準備する必要がありました。
補足追記
TBBからインストールすると、IPPがcmakeの自動ダウンロードキャッシュを使わなくなりました。TBBとIPPを両方使いたい時は、両方準備する必要があります。
IPPのみだと、自動でダウンロードされたものを利用してくれるようです
IPPの場合
こちらからダウンロードし、インストールしてください。
私は次のオプションを有効にしました。
- WITH_IPP
- BUILD_IPP_IW
- OPENCV_IPP_ENABLE_ALL
TBBの場合
こちらから最新のWindowsリリースをダウンロードして展開ください。
CMAKEでは、TBB_DIR というとこで、TBBのCMAKEのファイルがあるところを指定すると良い感じに適用してくれます。
- WITH_TBB
- TBB_DIR D:/oneapi-tbb-2022.2.0/lib/cmake/tbb
※
私はTBB、IPPと順に個別にいれましたが、もしかするとintelのoneAPIというものをいれると丸っと全部インスコできたのかもしれません
さぁ、ベンチマークの時間だ!
OPENCVでIPP、TBBを有効にする方法がよくわからなくて、ここに来るまでに軽く2,3日はかかっていたりします。
IPP、TBBはOPENCVで有効になっていれば、特に何の指定をしていなくても勝手に有効になって、勝手にいい感じに速くしてくれるそうです。
またIPPはよくわかりませんが、TBBはAMDのCPUでも問題なく動作する模様。
これは入れない手はないね!
ベンチマークのコード
ベンチマークのコードは生成AIに作成してもらいました。
GPUメモリへのコピーがループの外にあるなー、とは思いましたが
試しにループの中に入れてもやっぱり速かったのでとりあえず外側のままに。
nmsやinpaintも無理やり入れています。inpaintは重すぎたので3回にしました。
TBBは、実行ファイルと同じフォルダにTBB.DLLを入れる必要がありました。
ベンチマークのコード
#include <opencv2/opencv.hpp>
#include <opencv2/core/ocl.hpp>
#include <opencv2/dnn.hpp> // NMSBoxes 用
#include <opencv2/cudaimgproc.hpp>
#include <opencv2/cudafilters.hpp>
#include <opencv2/cudawarping.hpp>
#include <chrono>
#include <iostream>
#include <vector>
#include <string>
#include <iomanip> // setw のため
#include <cuda_runtime.h> // 追加: CUDAランタイムAPIのヘッダ
using namespace cv;
using namespace std;
using Clock = chrono::high_resolution_clock;
// 操作ごとの計測結果をまとめる構造体
struct OpTimes {
double resize = 0;
double cvtColor = 0;
double blur = 0;
double nms = 0;
double inpaint = 0;
double total = 0;
string name;
};
// CPU 用ベンチ:IPP/スレッド設定を変えながら測定
OpTimes benchCPU(
const Mat& src, int iter,
bool useIPP, int threads,
const string& label)
{
// 初期設定
//setUseOptimized(useIPP);
//setNumThreads(threads);
// NMSBoxes 用データを事前生成
RNG rng(42);
vector<Rect> boxes;
vector<float> scores;
const int numBoxes = 100;
for (int i = 0; i < numBoxes; ++i) {
int x = rng.uniform(0, src.cols - 100);
int y = rng.uniform(0, src.rows - 100);
boxes.emplace_back(x, y, rng.uniform(20, 100), rng.uniform(20, 100));
scores.push_back(rng.uniform(0.0f, 1.0f));
}
const float scoreThresh = 0.5f, nmsThresh = 0.4f;
vector<int> indices;
// inpaint 用マスクを一度だけ生成
Mat mask(src.size(), CV_8UC1);
randu(mask, Scalar::all(0), Scalar::all(2));
threshold(mask, mask, 0, 255, THRESH_BINARY);
Mat inpaintDst;
OpTimes t;
t.name = label;
// トータル計測開始
auto tot0 = Clock::now();
for (int i = 0; i < iter; ++i) {
Mat dst, gray;
// --- resize ---
auto s0 = Clock::now();
resize(src, dst, Size(), 0.5, 0.5, INTER_LINEAR);
auto e0 = Clock::now();
t.resize += chrono::duration<double, milli>(e0 - s0).count();
// --- cvtColor ---
s0 = Clock::now();
cvtColor(dst, gray, COLOR_BGR2GRAY);
e0 = Clock::now();
t.cvtColor += chrono::duration<double, milli>(e0 - s0).count();
// --- GaussianBlur ---
s0 = Clock::now();
GaussianBlur(gray, gray, Size(15, 15), 1.5, 1.5);
e0 = Clock::now();
t.blur += chrono::duration<double, milli>(e0 - s0).count();
// --- NMSBoxes ---
s0 = Clock::now();
dnn::NMSBoxes(boxes, scores, scoreThresh, nmsThresh, indices);
e0 = Clock::now();
t.nms += chrono::duration<double, milli>(e0 - s0).count();
}
const int inpaintIter = 3; // 3回は実行(遅いから
auto s_inpaint = Clock::now();
for (int j = 0; j < inpaintIter; ++j) {
inpaint(src, mask, inpaintDst, 3.0, INPAINT_TELEA);
}
auto e_inpaint = Clock::now();
t.inpaint += chrono::duration<double, milli>(e_inpaint - s_inpaint).count();
auto tot1 = Clock::now();
t.total = chrono::duration<double, milli>(tot1 - tot0).count();
return t;
}
// OpenCL ベンチ:UMat を使って同じ処理(nms/inpaint は 0 のまま)
OpTimes benchOpenCL(const Mat& src, int iter) {
OpTimes t;
t.name = "OpenCL";
if (!ocl::haveOpenCL()) { cerr << "OpenCL not available\n"; return t; }
ocl::setUseOpenCL(true);
UMat u_src, u_tmp, u_gray;
src.copyTo(u_src);
auto tot0 = Clock::now();
for (int i = 0; i < iter; ++i) {
// resize
auto s0 = Clock::now();
resize(u_src, u_tmp, Size(src.cols / 2, src.rows / 2),
0, 0, INTER_LINEAR);
ocl::finish();
auto e0 = Clock::now();
t.resize += chrono::duration<double, milli>(e0 - s0).count();
// cvtColor
s0 = Clock::now();
cvtColor(u_tmp, u_gray, COLOR_BGR2GRAY);
ocl::finish();
e0 = Clock::now();
t.cvtColor += chrono::duration<double, milli>(e0 - s0).count();
// blur
s0 = Clock::now();
GaussianBlur(u_gray, u_gray, Size(15, 15), 1.5, 1.5);
ocl::finish();
e0 = Clock::now();
t.blur += chrono::duration<double, milli>(e0 - s0).count();
}
t.total = chrono::duration<double, milli>(
Clock::now() - tot0).count();
return t;
}
// CUDA ベンチ:GpuMat を使って同じ処理(nms/inpaint は 0 のまま)
OpTimes benchCUDA(const Mat& src, int iter) {
OpTimes t;
t.name = "CUDA";
if (!cuda::getCudaEnabledDeviceCount()) { cerr << "No CUDA device\n"; return t; }
cuda::setDevice(0);
cuda::GpuMat g_src, g_tmp, g_gray;
g_src.upload(src);
Ptr<cuda::Filter> gauss = cuda::createGaussianFilter(
CV_8UC1, CV_8UC1, Size(15, 15), 1.5);
auto tot0 = Clock::now();
for (int i = 0; i < iter; ++i) {
// resize
auto s0 = Clock::now();
cuda::resize(g_src, g_tmp, Size(src.cols / 2, src.rows / 2));
cudaDeviceSynchronize();
auto e0 = Clock::now();
t.resize += chrono::duration<double, milli>(e0 - s0).count();
// cvtColor
s0 = Clock::now();
cuda::cvtColor(g_tmp, g_gray, COLOR_BGR2GRAY);
cudaDeviceSynchronize();
e0 = Clock::now();
t.cvtColor += chrono::duration<double, milli>(e0 - s0).count();
// blur
s0 = Clock::now();
gauss->apply(g_gray, g_gray);
cudaDeviceSynchronize();
e0 = Clock::now();
t.blur += chrono::duration<double, milli>(e0 - s0).count();
}
t.total = chrono::duration<double, milli>(
Clock::now() - tot0).count();
return t;
}
int main() {
const int W = 3840, H = 2160, ITER = 10000;
Mat src(H, W, CV_8UC3);
randu(src, Scalar::all(0), Scalar::all(255));
int maxTh = getNumberOfCPUs();
cout << "Image: " << W << "x" << H
<< ", iter=" << ITER
<< ", CPU cores=" << maxTh << "\n\n";
// 全設定でベンチ実行
vector<OpTimes> results;
results.push_back(benchCPU(src, ITER, true, maxTh, "CPU"));
results.push_back(benchOpenCL(src, ITER));
results.push_back(benchCUDA(src, ITER));
// 表形式で出力
cout << left
<< setw(12) << "Device"
<< setw(12) << "resize(ms)"
<< setw(12) << "cvtColor(ms)"
<< setw(12) << "blur(ms)"
<< setw(12) << "nms(ms)"
<< setw(12) << "inpaint(ms)"
<< setw(12) << "total(ms)" << "\n";
for (auto& t : results) {
cout << left
<< setw(12) << t.name
<< setw(12) << t.resize
<< setw(12) << t.cvtColor
<< setw(12) << t.blur
<< setw(12) << t.nms
<< setw(12) << t.inpaint
<< setw(12) << t.total << "\n";
}
return 0;
}
結果
Image: 3840x2160, iter=10000, CPU cores=12
Device resize(ms) cvtColor(ms)blur(ms) nms(ms) inpaint(ms) total(ms)
CPU 11832.6 4549.64 35238.2 261.577 15318.5 72315.3
OpenCL 574.691 443.269 12156 0 0 13175
CUDA 285.954 200.929 823.59 0 0 1314.66
ふむふむ。
あ、比較用に、今メインに使ってるprebuildのOPENCV 4.10でも試してみようかな?少なくともTBBはないはず!cudaはビルドされて無いからコメントアウトで!
Image: 3840x2160, iter=10000, CPU cores=12
Device resize(ms) cvtColor(ms)blur(ms) nms(ms) inpaint(ms) total(ms)
CPU 11205.3 3808.8 19499.2 222.741 15306.7 54227.5
OpenCL 507.62 368.223 11704.7 0 0 12581.6
あれ?
ベンチマークしたOPENCVのBuildInformationを貼っておきます。
OpenCV 4.13dev,4.10のBuildInformation
#include <opencv2/core.hpp>
#include <iostream>
int main() {
std::cout << cv::getBuildInformation() << std::endl;
return 0;
}
General configuration for OpenCV 4.13.0-dev =====================================
Version control: 4.12.0-147-gb3f6c86d47
Platform:
Timestamp: 2025-09-12T21:21:08Z
Host: Windows 10.0.26100 AMD64
CMake: 4.1.1
CMake generator: Visual Studio 17 2022
CMake build tool: C:/Program Files/Microsoft Visual Studio/2022/Community/MSBuild/Current/Bin/amd64/MSBuild.exe
MSVC: 1944
Configuration: Release
Algorithm Hint: ALGO_HINT_ACCURATE
CPU/HW features:
Baseline: SSE SSE2 SSE3
requested: SSE3
C/C++:
Built as dynamic libs?: YES
C++ standard: 11
C++ Compiler: C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.44.35207/bin/Hostx64/x64/cl.exe (ver 19.44.35216.0)
C++ flags (Release): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP -openmp /O2 /Ob2 /DNDEBUG
C++ flags (Debug): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP -openmp /Zi /Ob0 /Od /RTC1
C Compiler: C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.44.35207/bin/Hostx64/x64/cl.exe
C flags (Release): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /MP -openmp /O2 /Ob2 /DNDEBUG
C flags (Debug): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /MP -openmp /Zi /Ob0 /Od /RTC1
Linker flags (Release): /machine:x64 /INCREMENTAL:NO
Linker flags (Debug): /machine:x64 /debug /INCREMENTAL
ccache: NO
Precompiled headers: NO
Extra dependencies: cudart_static.lib nppc.lib nppial.lib nppicc.lib nppidei.lib nppif.lib nppig.lib nppim.lib nppist.lib nppisu.lib nppitc.lib npps.lib cufft.lib -LIBPATH:C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.9/lib/x64
3rdparty dependencies:
OpenCV modules:
To be built: core cudaarithm cudafilters cudaimgproc cudawarping cudev dnn imgcodecs imgproc photo world
Disabled: aruco bgsegm bioinspired calib3d ccalib cudabgsegm cudacodec cudafeatures2d cudalegacy cudaobjdetect cudaoptflow cudastereo datasets dnn_objdetect dnn_superres dpm face features2d flann fuzzy hfs highgui img_hash intensity_transform java_bindings_generator js_bindings_generator line_descriptor mcc ml objc_bindings_generator objdetect optflow phase_unwrapping plot python3 python_bindings_generator python_tests quality rapid reg rgbd saliency shape signal stereo stitching structured_light superres surface_matching text tracking video videoio videostab wechat_qrcode xfeatures2d ximgproc xobjdetect xphoto
Disabled by dependency: -
Unavailable: alphamat cannops cvv fastcv freetype gapi hdf java julia matlab ovis python2 python2 sfm ts viz
Applications: -
Documentation: NO
Non-free algorithms: NO
Windows RT support: NO
GUI:
Win32 UI: YES
VTK support: NO
Media I/O:
ZLib: build (ver 1.3.1)
JPEG: build-libjpeg-turbo (ver 3.1.0-70)
SIMD Support Request: YES
SIMD Support: NO
WEBP: build (ver decoder: 0x0209, encoder: 0x020f, demux: 0x0107)
AVIF: NO
PNG: build (ver 1.6.45)
SIMD Support Request: YES
SIMD Support: YES (Intel SSE)
TIFF: build (ver 42 - 4.7.0)
JPEG 2000: build (ver 2.5.3)
OpenEXR: build (ver 2.3.0)
GIF: YES
HDR: YES
SUNRASTER: YES
PXM: YES
PFM: YES
Video I/O:
Parallel framework: TBB (ver 2022.2 interface 12160)
Trace: YES (with Intel ITT(3.25.4))
Other third-party libraries:
Intel IPP: 2022.2.0 [2022.2.0]
at: D:/opencv_build2/3rdparty/ippicv/ippicv_win/icv
Intel IPP IW: sources (2022.2.0)
at: D:/opencv_build2/3rdparty/ippicv/ippicv_win/iw
Custom HAL: YES (ipp (ver 0.0.1))
Protobuf: build (3.19.1)
Flatbuffers: builtin/3rdparty (23.5.9)
NVIDIA CUDA: YES (ver 12.9, CUFFT FAST_MATH)
NVIDIA GPU arch: 75 86 89 120
NVIDIA PTX archs: 75 86 89 120
OpenCL: YES (SVM)
Include path: D:/opencv/3rdparty/include/opencl/1.2
Link libraries: Dynamic load
Python (for build): C:/Users/*****/AppData/Local/Microsoft/WindowsApps/python3.exe
Install to: D:/opencv_build2/install
-----------------------------------------------------------------
General configuration for OpenCV 4.10.0 =====================================
Version control: 4.10.0
Platform:
Timestamp: 2024-06-02T16:42:08Z
Host: Windows 10.0.19045 AMD64
CMake: 3.23.3
CMake generator: Visual Studio 16 2019
CMake build tool: C:/Program Files (x86)/Microsoft Visual Studio/2019/Community/MSBuild/Current/Bin/MSBuild.exe
MSVC: 1929
Configuration: Debug Release
CPU/HW features:
Baseline: SSE SSE2 SSE3
requested: SSE3
Dispatched code generation: SSE4_1 SSE4_2 FP16 AVX AVX2 AVX512_SKX
requested: SSE4_1 SSE4_2 AVX FP16 AVX2 AVX512_SKX
SSE4_1 (16 files): + SSSE3 SSE4_1
SSE4_2 (1 files): + SSSE3 SSE4_1 POPCNT SSE4_2
FP16 (0 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 AVX
AVX (8 files): + SSSE3 SSE4_1 POPCNT SSE4_2 AVX
AVX2 (36 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 FMA3 AVX AVX2
AVX512_SKX (5 files): + SSSE3 SSE4_1 POPCNT SSE4_2 FP16 FMA3 AVX AVX2 AVX_512F AVX512_COMMON AVX512_SKX
C/C++:
Built as dynamic libs?: YES
C++ standard: 11
C++ Compiler: C:/Program Files (x86)/Microsoft Visual Studio/2019/Community/VC/Tools/MSVC/14.29.30133/bin/Hostx64/x64/cl.exe (ver 19.29.30154.0)
C++ flags (Release): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP /O2 /Ob2 /DNDEBUG
C++ flags (Debug): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP /Zi /Ob0 /Od /RTC1
C Compiler: C:/Program Files (x86)/Microsoft Visual Studio/2019/Community/VC/Tools/MSVC/14.29.30133/bin/Hostx64/x64/cl.exe
C flags (Release): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /MP /O2 /Ob2 /DNDEBUG
C flags (Debug): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:precise /MP /Zi /Ob0 /Od /RTC1
Linker flags (Release): /machine:x64 /INCREMENTAL:NO
Linker flags (Debug): /machine:x64 /debug /INCREMENTAL
ccache: NO
Precompiled headers: NO
Extra dependencies:
3rdparty dependencies:
OpenCV modules:
To be built: calib3d core dnn features2d flann gapi highgui imgcodecs imgproc ml objdetect photo stitching video videoio world
Disabled: python3
Disabled by dependency: -
Unavailable: java python2 ts
Applications: apps
Documentation: NO
Non-free algorithms: NO
Windows RT support: NO
GUI:
Win32 UI: YES
VTK support: NO
Media I/O:
ZLib: build (ver 1.3.1)
JPEG: build-libjpeg-turbo (ver 3.0.3-70)
SIMD Support Request: YES
SIMD Support: NO
WEBP: build (ver encoder: 0x020f)
PNG: build (ver 1.6.43)
SIMD Support Request: YES
SIMD Support: YES (Intel SSE)
TIFF: build (ver 42 - 4.6.0)
JPEG 2000: build (ver 2.5.0)
OpenEXR: build (ver 2.3.0)
HDR: YES
SUNRASTER: YES
PXM: YES
PFM: YES
Video I/O:
DC1394: NO
FFMPEG: YES (prebuilt binaries)
avcodec: YES (58.134.100)
avformat: YES (58.76.100)
avutil: YES (56.70.100)
swscale: YES (5.9.100)
avresample: YES (4.0.0)
GStreamer: NO
DirectShow: YES
Media Foundation: YES
DXVA: YES
Parallel framework: Concurrency
Trace: YES (with Intel ITT)
Other third-party libraries:
Intel IPP: 2021.11.0 [2021.11.0]
at: C:/GHA-OCV-1/_work/ci-gha-workflow/ci-gha-workflow/build/3rdparty/ippicv/ippicv_win/icv
Intel IPP IW: sources (2021.11.0)
at: C:/GHA-OCV-1/_work/ci-gha-workflow/ci-gha-workflow/build/3rdparty/ippicv/ippicv_win/iw
Eigen: NO
Custom HAL: NO
Protobuf: build (3.19.1)
Flatbuffers: builtin/3rdparty (23.5.9)
OpenCL: YES (NVD3D11)
Include path: C:/GHA-OCV-1/_work/ci-gha-workflow/ci-gha-workflow/opencv/3rdparty/include/opencl/1.2
Link libraries: Dynamic load
Python (for build): C:/Python-3.9/python.exe
Java:
ant: C:/apache-ant-1.9.15/bin/ant.bat (ver 1.9.15)
Java: NO
JNI: C:/Program Files/Java/jdk-11.0.9/include C:/Program Files/Java/jdk-11.0.9/include/win32 C:/Program Files/Java/jdk-11.0.9/include
Java wrappers: NO
Java tests: NO
Install to: C:/GHA-OCV-1/_work/ci-gha-workflow/ci-gha-workflow/install
-----------------------------------------------------------------
真犯人はBuildInformationの中に!
4.13dev

4.10
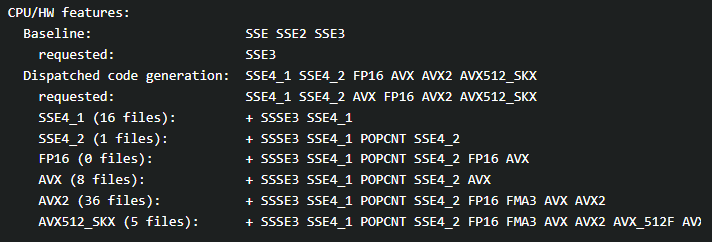
CPUのビルドオプションが全然違う!!
CPU_DISPATCHで4.10と同じように複数選べば解決!と思いましたが、cmake_guiではドロップダウンリストで1つしか選べず、どうしたものか?と地味に詰まりました。
困って、解決できたので、もう1つ投稿しました。
さぁベンチマークの時間だ!(2回目)
こちらの記事でparallel_for_などの指示をしないといけないみたいなので、TBBはもういいかなっていうことでIPPのみにしました。
さて、結果はいかに!!
Image: 3840x2160, iter=10000, CPU cores=12
Device resize(ms) cvtColor(ms)blur(ms) nms(ms) inpaint(ms) total(ms)
CPU 12050.1 4336.77 21256.4 227.268 15695.3 58157.9
OpenCL 671.903 480.813 12734.7 0 0 13888.5
CUDA 278.912 209.164 824.896 0 0 1313.84
Image: 3840x2160, iter=10000, CPU cores=12
Device resize(ms) cvtColor(ms)blur(ms) nms(ms) inpaint(ms) total(ms)
CPU 11205.3 3808.8 19499.2 222.741 15306.7 54227.5
OpenCL 507.62 368.223 11704.7 0 0 12581.6
ん-まだ微妙に差はあるけど、CPU処理となる予定のNMSとINPAINTが近い値になったのでヨシとします!
OpenCV 4.13devのBuildInformation
General configuration for OpenCV 4.13.0-dev =====================================
Version control: 4.12.0-147-gb3f6c86d47
Platform:
Timestamp: 2025-09-12T21:21:08Z
Host: Windows 10.0.26100 AMD64
CMake: 4.1.1
CMake generator: Visual Studio 17 2022
CMake build tool: C:/Program Files/Microsoft Visual Studio/2022/Community/MSBuild/Current/Bin/amd64/MSBuild.exe
MSVC: 1944
Configuration: Release
Algorithm Hint: ALGO_HINT_ACCURATE
CPU/HW features:
Baseline: SSE SSE2 SSE3 SSSE3
requested: SSSE3
Dispatched code generation: SSE4_1 SSE4_2 AVX FP16 AVX2 AVX512_SKX
requested: SSE4_1 SSE4_2 FP16 AVX AVX2 AVX512_SKX
SSE4_1 (14 files): + SSE4_1
SSE4_2 (1 files): + SSE4_1 POPCNT SSE4_2
AVX (9 files): + SSE4_1 POPCNT SSE4_2 AVX
FP16 (0 files): + SSE4_1 POPCNT SSE4_2 AVX FP16
AVX2 (32 files): + SSE4_1 POPCNT SSE4_2 AVX FP16 AVX2 FMA3
AVX512_SKX (5 files): + SSE4_1 POPCNT SSE4_2 AVX FP16 AVX2 FMA3 AVX_512F AVX512_COMMON AVX512_SKX
C/C++:
Built as dynamic libs?: YES
C++ standard: 11
C++ Compiler: C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.44.35207/bin/Hostx64/x64/cl.exe (ver 19.44.35216.0)
C++ flags (Release): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP /O2 /Ob2 /DNDEBUG
C++ flags (Debug): /DWIN32 /D_WINDOWS /W4 /GR /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /EHa /wd4127 /wd4251 /wd4324 /wd4275 /wd4512 /wd4589 /wd4819 /MP /Zi /Ob0 /Od /RTC1
C Compiler: C:/Program Files/Microsoft Visual Studio/2022/Community/VC/Tools/MSVC/14.44.35207/bin/Hostx64/x64/cl.exe
C flags (Release): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /MP /O2 /Ob2 /DNDEBUG
C flags (Debug): /DWIN32 /D_WINDOWS /W3 /D _CRT_SECURE_NO_DEPRECATE /D _CRT_NONSTDC_NO_DEPRECATE /D _SCL_SECURE_NO_WARNINGS /Gy /bigobj /Oi /fp:fast /MP /Zi /Ob0 /Od /RTC1
Linker flags (Release): /machine:x64 /INCREMENTAL:NO
Linker flags (Debug): /machine:x64 /debug /INCREMENTAL
ccache: NO
Precompiled headers: NO
Extra dependencies: cudart_static.lib nppc.lib nppial.lib nppicc.lib nppidei.lib nppif.lib nppig.lib nppim.lib nppist.lib nppisu.lib nppitc.lib npps.lib cufft.lib -LIBPATH:C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v12.9/lib/x64
3rdparty dependencies:
OpenCV modules:
To be built: core cudaarithm cudafilters cudaimgproc cudawarping cudev dnn imgcodecs imgproc photo world
Disabled: aruco bgsegm bioinspired calib3d ccalib cudabgsegm cudacodec cudafeatures2d cudalegacy cudaobjdetect cudaoptflow cudastereo datasets dnn_objdetect dnn_superres dpm face features2d flann fuzzy hfs highgui img_hash intensity_transform java_bindings_generator js_bindings_generator line_descriptor mcc ml objc_bindings_generator objdetect optflow phase_unwrapping plot python3 python_bindings_generator python_tests quality rapid reg rgbd saliency shape signal stereo stitching structured_light superres surface_matching text tracking video videoio videostab wechat_qrcode xfeatures2d ximgproc xobjdetect xphoto
Disabled by dependency: -
Unavailable: alphamat cannops cvv fastcv freetype gapi hdf java julia matlab ovis python2 python2 sfm ts viz
Applications: -
Documentation: NO
Non-free algorithms: NO
Windows RT support: NO
GUI:
Win32 UI: YES
Media I/O:
ZLib: build (ver 1.3.1)
JPEG: build-libjpeg-turbo (ver 3.1.0-70)
SIMD Support Request: YES
SIMD Support: NO
WEBP: build (ver decoder: 0x0209, encoder: 0x020f, demux: 0x0107)
AVIF: NO
PNG: build (ver 1.6.45)
SIMD Support Request: YES
SIMD Support: YES (Intel SSE)
TIFF: build (ver 42 - 4.7.0)
JPEG 2000: build (ver 2.5.3)
OpenEXR: build (ver 2.3.0)
GIF: YES
HDR: YES
SUNRASTER: YES
PXM: YES
PFM: YES
Video I/O:
Parallel framework: Concurrency
Trace: YES (with Intel ITT(3.25.4))
Other third-party libraries:
Intel IPP: 2022.2.0 [2022.2.0]
at: D:/opencv_build2/3rdparty/ippicv/ippicv_win/icv
Intel IPP IW: sources (2022.2.0)
at: D:/opencv_build2/3rdparty/ippicv/ippicv_win/iw
Custom HAL: YES (ipp (ver 0.0.1))
NVIDIA CUDA: YES (ver 12.9, CUFFT FAST_MATH)
NVIDIA GPU arch: 75 86 89 120
NVIDIA PTX archs: 75 86 89 120
OpenCL: YES (SVM)
Include path: D:/opencv/3rdparty/include/opencl/1.2
Link libraries: Dynamic load
Python (for build): C:/Users/*****/AppData/Local/Microsoft/WindowsApps/python3.exe
Install to: D:/opencv_build2/install
-----------------------------------------------------------------
その他設定したOPENCVのビルドオプション
-
CUDA_FAST_MATH:オン
-
ENABLE_FAST_MATH:オン
少しでも処理を早くしたいという気持ちでオンにしました。 -
ENABLE_LTO:オン
Link Time Optimizationで、コンパイル後の最終リンク時にコード全体を最適化するオプションのようです。
処理が速くなるかもしれないのでオンに。 -
WITH_OPENCL_SVM:オン
Shared Virtual Memoryで、CPUとGPUのメモリ共用が仮想メモリを通して可能になりCPU-GPUのメモリ転送が速くなるらしいです。RADEONではOPENCLを利用してもらう予定なのでオンに。 -
OPENCV_IPP_MEAN:オン
-
OPENCV_IPP_MINMAX:オン
-
OPENCV_IPP_SUM:オン
CUDA、OPENCLで未対応なものはCPU処理になるので、少しでも速くしたい気持ちでオンに。
ビルドしたopencv4130.dllをにアプリに適用する!
アプリに適用して実行してみるとこんなエラーが出たりして、ほげー?ってなりました。
他の内容(他のdll)でも出たりしますが、Windowsの基本コンポーネントぽいdllで内部例外エラーとなります。
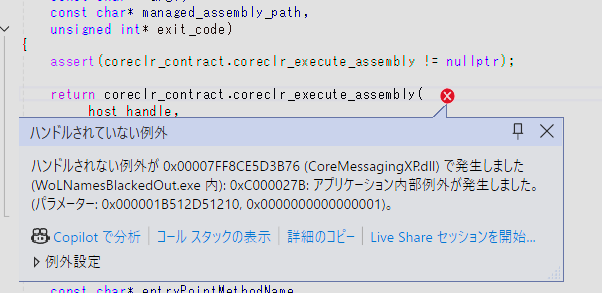
リンク先がないので内部例外エラーということらしく、cuda toolkitで必要なdllをプロジェクトに正しくコピーできてなかったため発生しました(npp*.dllとかcublas*.dllとかが参照できなくなってた)
DependenciesGuiとかで必要なDLLを確認するのがお勧めです。
まとめ
- WindowsのOPENCVで、IPP、TBBの両方を有効にしようと思ったら自分でダウンロードして導入する必要がありそうだよ!
- IPPだけだったらcmakeの時に自動でダウンロードしてくれるよ!
- OPENCL、CUDAは桁違いに速いので、超お勧め!
- OPENCVをビルドする時、特にcmake_guiの人はCPUの設定に注意しようね!
- CUDA入れたなら、cudatoolkitのdllをコピーしてくるのも忘れずに。
- 公式で配布されているビルド済みのOPENCVはいい感じに速いので、CUDA使いたいとかじゃなかったらお勧めです!
- オレはようやくのぼりはじめたばかりだからな
このはてしなく遠いOPENCV Build坂をよ・・・
未完