はじめまして。かっこ株式会社インターン生のwsです。
かっこ株式会社ではインターン生にはまず約1ヶ月を限度として、あるWebサイトへクローリング・スクレイピングし取得したデータの集計・可視化・分析結果をまとめるという一連の分析作業を課題として取り組んでもらいます。
課題について
私の場合は、クラウドファンディングサイト「Makuake」をスクレイピングし、
プロジェクトの成功・失敗率はどうなっているのか、活発なプロジェクトは何か、プロジェクトのカテゴリーや目標金額、達成金額はファンドプロジェクトの成功と関係あるのかを分析する、という課題が出されました。
課題に取り組むうえで苦労した点やハマった点などについてお話しできればと思います。
試用生時点でのスキル
大学でpythonを用いてデータ分析をしていた程度でした。
ごりごりシステム開発をやったことはありませんでした。
分析手順
以下の手順で課題に取り組みました。
1.プロジェクト一覧ページを開く(約450ページくらい)
↓
2.ページにあるプロジェクトのURLを取得し、htmlファイルで保存(クローリング)
↓
3.各プロジェクトのhtmlファイルから、必要なデータを取得(スクレイピング)
↓
4.取得したデータを集計・可視化
↓
5.資料作り
クローリング
まず下図のようなプロジェクトが掲載されているページに移動します。
1ページあたり約15個のプロジェクトが掲載されています。
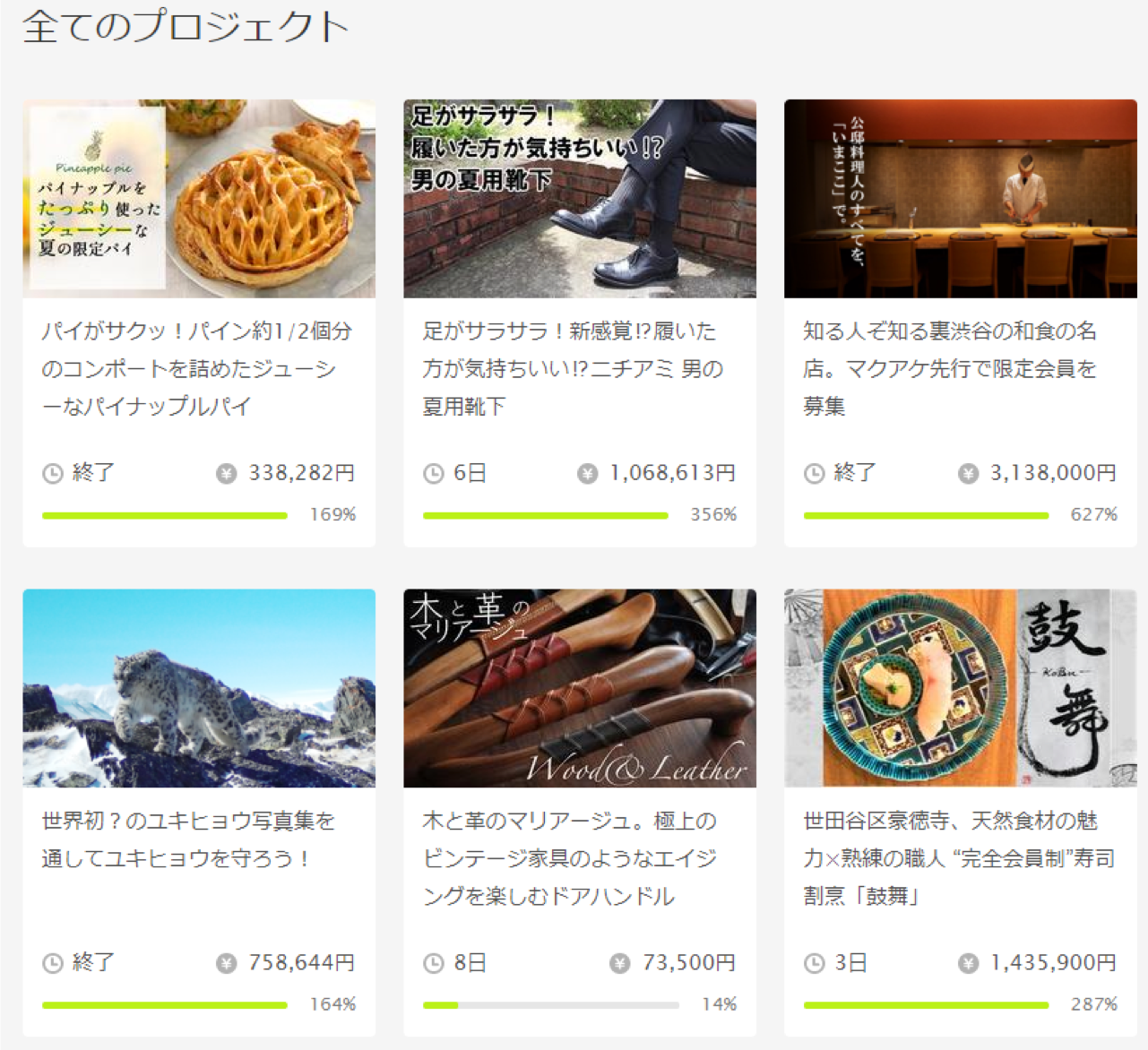
今回の課題の目的は、プロジェクトの成功失敗を可視化することですから、プロジェクトは進行中のものではなく、すでに終了しているものを対象とします。
なので、このページの時点で取得するプロジェクトURLをすでに終了したもので絞り込みます。
さらに、円マークの隣に現時点で集まっている金額が表示されているのですが、
プロジェクトで目標金額を定めていないものは、free goalと表示されます。そのようなプロジェクトのURLも、今回除外します。
プロジェクト一覧ページから対象プロジェクトを絞ったあと、プロジェクト詳細ページをhtmlファイルとして保存します。
まとめますと、今回html取得対象となるプロジェクトは以下の通りです。
:プロジェクトはすでに終了したものである
:目標となる金額が明確に定められている
ここまでのコードが以下の通りです。
import csv
import time
import os
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 基準となるURL
base_url = 'https://www.makuake.com/discover/projects/search/'
r = requests.get(base_url)
soup = BeautifulSoup(r.text, 'lxml')
# プロジェクトが掲載されている全ページをリストで取得する
page_url = []
last_page = int(soup.find('a', class_='pageRightLast')['href'].split('/')[-1])
for p in range(1, (last_page + 1)):
page_url.append(base_url + str(p))
# 第一の検収チェック 全てのページが取得できているか確かめる エラーが発生しない場合,成功
assert len(page_url) == last_page
'''すでに終了しており、かつ目標金額がfree goalや未設定でないプロジェクトのurlのみを今回の課題の対象とし,project_urlに格納する
今回の課題で取得する変数は達成金額,目標金額,目標金額達成率,成功フラグ,カテゴリーであるが,この段階で達成金額のみを取得し(javascriptとの戦闘回避),
get_moneyに格納する'''
project_url = []
get_money = []
# 各ページにある、条件を満たす記事のURLを取得する
for url in page_url:
page_r = requests.get(url)
page_soup = BeautifulSoup(page_r.text, 'lxml')
for tag in page_soup.find_all('article'):
media_middle_time = tag.find('div', class_='media-middle-time').p.string # 経過日数
media_middle_money = tag.find('div', class_='media-middle-money').p.string # 経過時間
# Noneの場合,目標金額がfree goalのプロジェクトとは別の、目標金額が定められていないプロジェクトのため除外
media_low_bar_num = tag.find('div', class_='media-low-bar-num')
if (media_middle_time == '終了') and (media_middle_money != 'free goal') and (media_low_bar_num != None):
money = int(media_middle_money.replace('円', '').replace(',', '').replace(' ', ''))
to_absurl = urljoin(base_url, tag.a['href']) # 相対urlを絶対urlに変換する
project_url.append(to_absurl)
get_money.append(money)
else:
continue
# html格納用ディレクトリ、各プロジェクトのhtmlに対応した達成金額についてのcsvファイルが入ったディレクトリを作成する
cd = os.getcwd()
if os.path.exists('./money_DIR') == False:
dir_name_money = 'money_DIR'
money_DIR = os.path.join(cd, dir_name_money)
os.mkdir(money_DIR) # このディレクトリに達成金額のcsvファイルを入れる
else:
money_DIR = './money_DIR'
if os.path.exists('./html_DIR') == False:
dir_name_html = 'html_DIR'
html_DIR = os.path.join(cd, dir_name_html)
# このディレクトリにhtmlファイルを入れまくる ファイル名の様式は0.py 1.pyのようにする
# 0.pyはproject_url[0]のプロジェクトurlに対応する
os.mkdir(html_DIR)
else:
html_DIR = './html_DIR'
# すでにつくってあるget_moneyをcsvに出力
money_path = os.path.join(money_DIR, 'money.csv')
with open(money_path, 'w', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(get_money)
# html_DIRにプロジェクトのhtmlを入れていく作業
for i, url in enumerate(project_url):
html_path = os.path.join(html_DIR, (str(i) + '.html'))
project_r = requests.get(url)
time.sleep(1)
with open(html_path, 'w', encoding='utf-8') as f:
f.write(project_r.text)
スクレイピング
では、htmlファイルとして保存したプロジェクト詳細ページを見てみます。
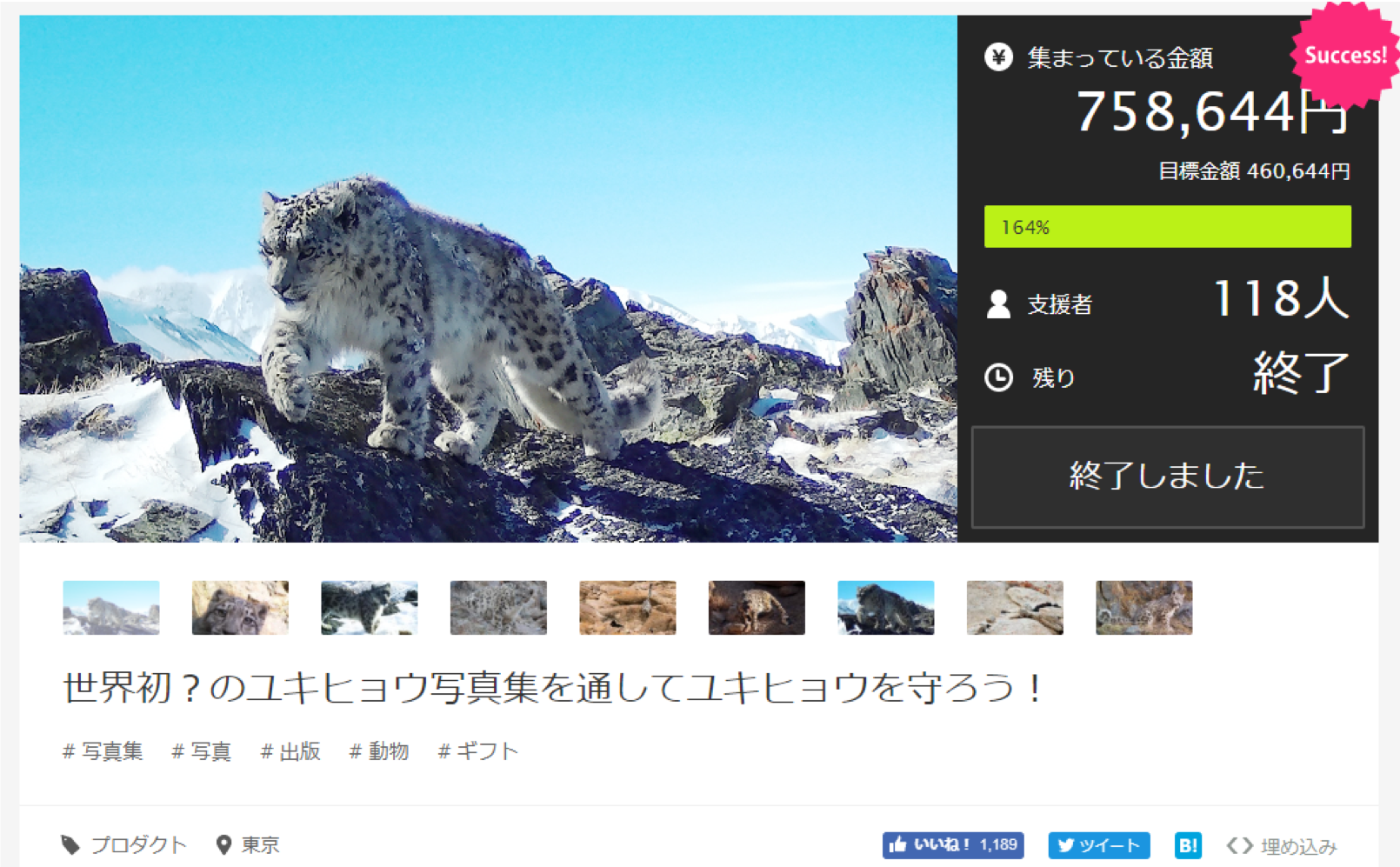
取得したhtmlからスクレイピングして取得したのはカテゴリー、目標金額です。
さらにプロジェクト一覧ページの時点で取得した集まっている金額(達成金額)を用いて、
(達成金額/目標金額)×100を金額達成率として作成しました。
そこから、金額達成率が100以上なら1、未満なら0として成功フラグを作成しました。
さて、ここで一つハマりポイントがありました。
じつはこのページの集まっている金額は、JavaScriptを用いて表示されているのです。(レンダリングされている)
JavaScriptによってレンダリングされている部分は、一般的なライブラリを用いたスクレイピングでは取得できず、
別の方法でJavaScriptでレンダリングされたままのHTMLを取得できるようにする必要があります。(ヘッドレスブラウザの操作)
僕はこの値がレンダリングされているのに気づき、さらに専用のライブラリの学習(Selenium Chromedriverなど)、実装チャレンジするまでに三日潰れました \(^O^)/
結局実装チャレンジしただけで、プロジェクト詳細ページではなく、一覧ページの時点で集まっている金額を取得すればいいことに気づき、回避しました。(もっと早く気づかないものか...)
ここまでのコードが以下の通りです。
import csv
import os
from bs4 import BeautifulSoup
# スクレイピングし、dict型にまとめて返す作業を関数にする
def scrape(parsed, value):
'''以下の各値の取得方法では、find関数の仕様上値がNoneの場合TypeNoneErrorが発生する.関数が無事に実行できた時点で値の取りこぼしがないことが保証される'''
title = parsed.find('h2', class_='projectTtl').string
money = value # 達成金額
category = parsed.find(
'a', class_='projectTag').contents[-1].replace(' ', '').replace('\n', '') # カテゴリー
goal_money = int(parsed.find('p', class_='stMoneyGoal').string.replace(
'目標金額', '').replace('円', '').replace(',', '').replace(' ', '')) # 目標金額
goal_rate = int((money / goal_money) * 100) # 金額達成率 100以上なら,プロジェクトは成功
if goal_rate >= 100: # 成功の場合、successフラグは1,失敗の場合0とする
success = 1
else:
success = 0
unit = {'プロジェクト名': title, '達成金額': money, '目標金額': goal_money,
'金額達成率': goal_rate, '成功フラグ': success, 'カテゴリー': category}
print(unit)
return unit
# htmlを引数とし、読み込んでstrに変換して返す関数
def to_text(html_file):
path = './html_DIR/' + html_file
with open(path, 'r', encoding='utf-8') as f:
text = f.read()
return text
'''html_listのインデックスと、money_listのインデックスは対応している.
(0.htmlの達成金額は,money_list[0]と対応)けれど実行環境のファイルのソート設定の違いで本来の順のhtmlファイルのlistが得られない可能性がある
(1.py 11.py 2.pyみたいなソートにされてしまう可能性がある)
そのためlistdir()で取得したhtml_DIRにあるhtmlファイルのリストを以下の手順でソートし、念入りにきっちり対応させる'''
base_list = os.listdir('./html_DIR')
split_list = list(map(lambda x: x.replace('.html', ''), base_list))
sorted_list = sorted(map(int, split_list))
html_list = list(map(lambda x: str(x) + '.html', sorted_list))
money_csv_path = './money_DIR/money.csv'
with open(money_csv_path, 'r', encoding='utf-8') as f:
money_list = list(map(int, list(csv.reader(f))[0]))
# 第二の検収チェック 取得したhtml_listの要素数と数とmoney_listの要素数が一致しているかチェック
assert len(html_list) == len(money_list)
# rawにscrape関数で取得したdictをrawにappendしていく
raw = []
for i in range(0, len(html_list)):
html = html_list[i]
money = money_list[i]
text = to_text(html)
parsed = BeautifulSoup(text, 'lxml')
unit = scrape(parsed, money) # スクレイピングを実行返り値は変数をkeyにもつdict
raw.append(unit)
print(i) # 進捗度確認
# 第三の検収チェック 対象URL数と,取得した要素数が一致していることを確認する
assert len(html_list) == len(raw)
# csvファイルの作成
cd = os.getcwd()
if os.path.exists('./csv_DIR') == True:
pass
else:
os.mkdir('./csv_DIR')
file_name = 'csv_DIR/makuake_raw.csv'
new_file = os.path.join(cd, file_name)
with open(new_file, 'w', encoding='shift-jis') as f:
fieldnames = raw[0].keys()
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(raw)
集計・可視化
取得したデータを基に、以下のように可視化しました。
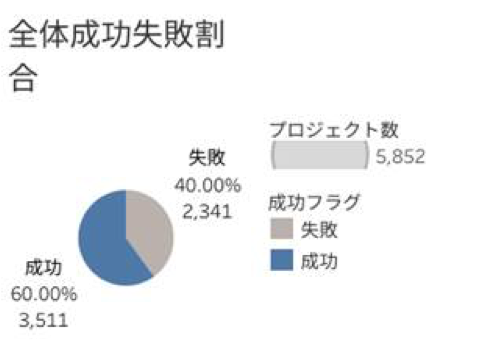
・図1
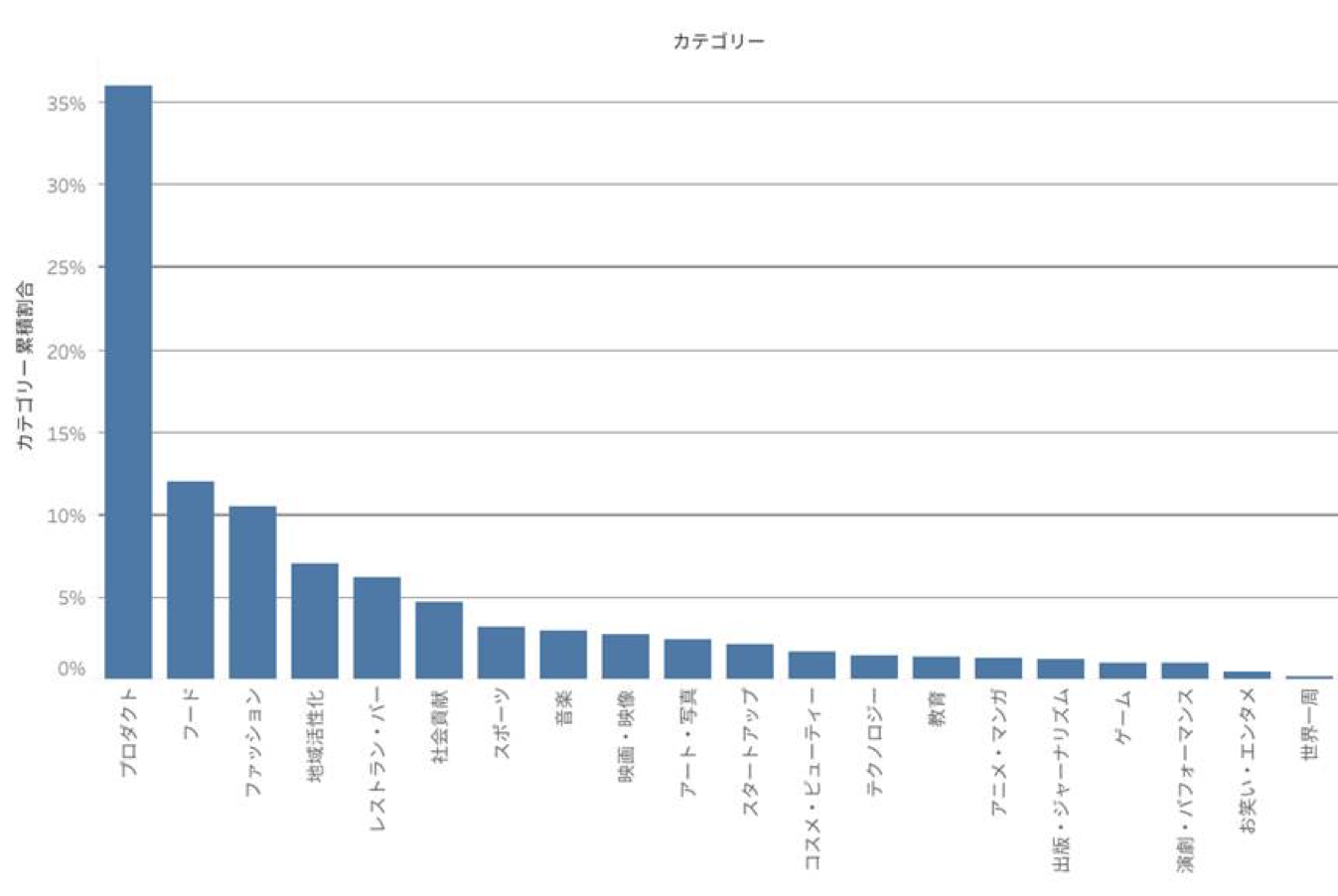
・図2
・図3
・図4
結果と考察
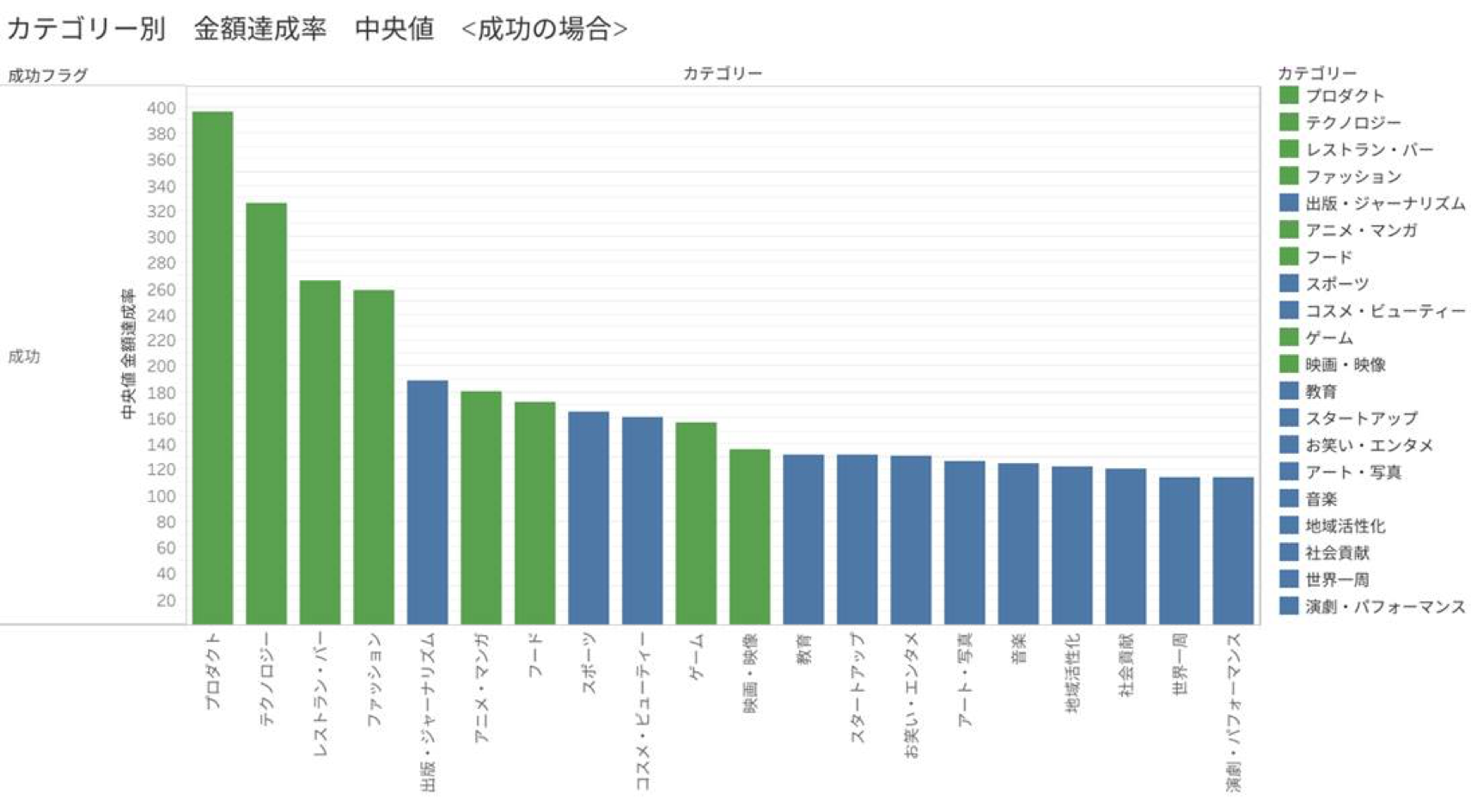
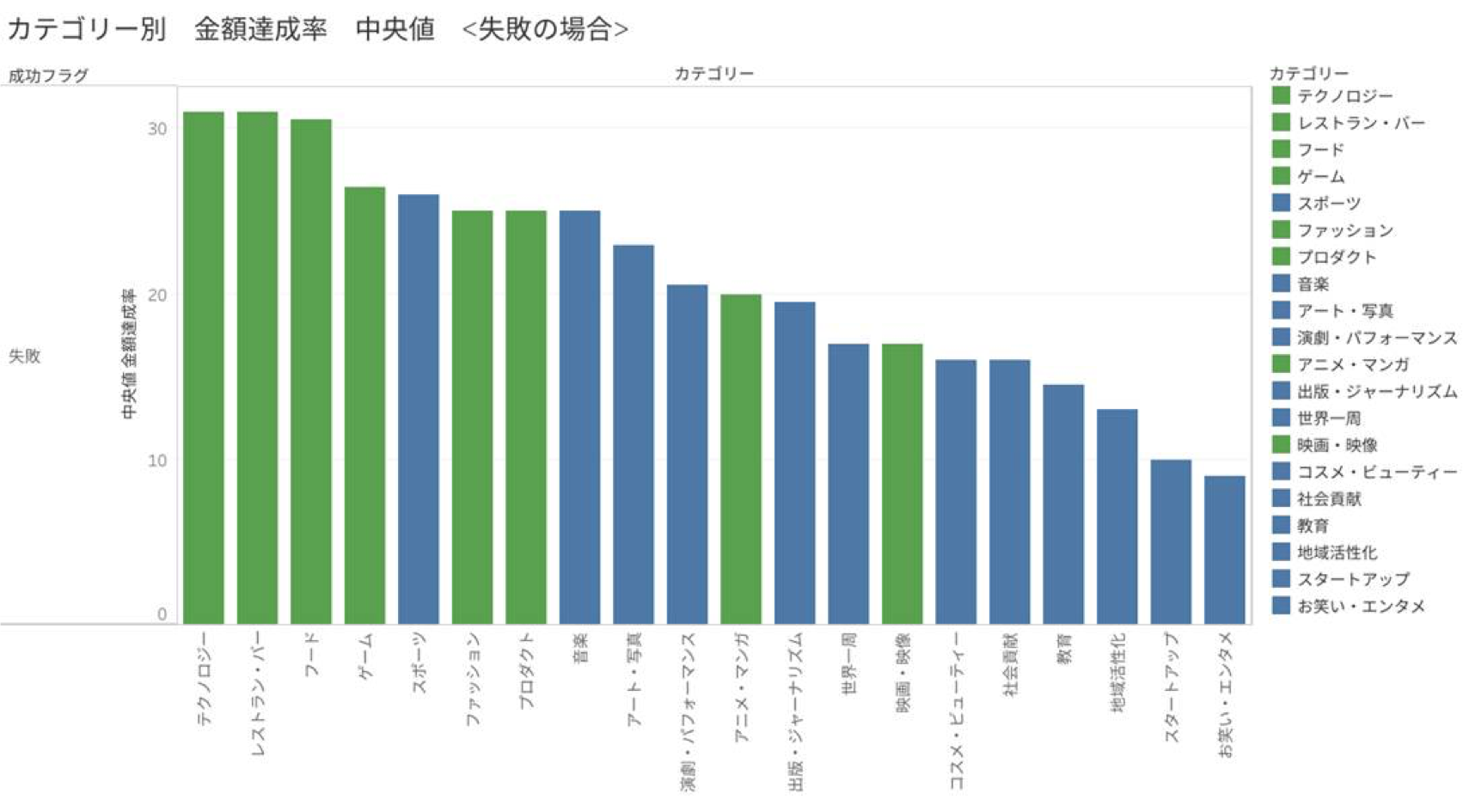
緑の棒が、成功率が失敗率を上回っているカテゴリーを表しています。
図1から、全体でみると成功したプロジェクトの方が多いことがわかります。
図2から、最も活発なカテゴリーはプロダクトであることがわかります。図からわかるとおり、圧倒的ですね。
図3、4では、先に定義した金額達成率のカテゴリーごとの中央値をみています。
成功の場合を見てみると、最も中央値が高いカテゴリーはプロダクト、低いカテゴリーは演劇・パフォーマンスであることがわかります。
テクノロジーやプロダクトなどは300超えちゃってますね。
カテゴリーによって、成功するときは爆発的に成功するカテゴリーと、なんとか成功するカテゴリーに分かれるといえそうです。
失敗の場合はどうでしょう。どのカテゴリーでも金額達成率の中央値にあまり違いは見られません。
失敗するときはどのカテゴリーも大差がないことがわかります。
いくつかのプロジェクトを見た限り、プロダクトやファッションはファンディングに対し目にみえるリターンが返ってくるけれども、
スポーツや映画・映像などはファンディングに対してリターンがお礼の手紙やビデオレターなどが多い印象を受けました。大多数にとってもらったら嬉しいものがリターンかどうかが、カテゴリーの成功しやすさの一因になっているのかも?
分析のまとめ
分析結果から、以下のことがわかりました。
-
全体でみると成功したプロジェクトの方が多い
-
プロダクト関連のプロジェクトが活発である
-
金額達成率でみると、成功しやすいカテゴリーとそうでないカテゴリーに分かれる
プロジェクトが成功しやすいかどうかは、そのプロジェクトがどういったジャンルのプロジェクトかどうかと関係がありそうですね。
おわりに
今回得られたもの
いままでは分析するためにコードを書いてきましたが、今回初めてちゃんとした成果物(簡単なシステム)を作ったので、良い経験でした。
課題に取り組む中で、バグへの対処やシステム設計、プログラムの実行速度を常に意識していたので、データ分析だけでなくシステム開発をするうえで必要となる力を身につけることができたと思います。
反省点
最初に発表資料を見てもらったとき、全然資料の見せ方がなっていなかったため、大幅にグラフ資料を修正する必要がありました。
見た人が直感的にすぐわかるような資料内容になっていなかったのです。
具体的には、
-
グラフ資料の色の割り振りが悪い
-
結論がぼやけている(言いたいことが何かがわかりにくい資料)
-
結論にあった適切な図表の選択
という点が問題でした。
今後は分析資料を作るときは直感的に分かりやすい資料になっているのか意識していきたいです。
以上です。ありがとうございました。