はじめまして。物理学科所属の大学4年のN.Dです。
Pythonの経験は独学で少し触った程度です。スクレイピングやクローリングは初めてでした。
現在インターン中のかっこ株式会社のデータサイエンス事業部では、試用期間にクローラーを作ってデータを収集、加工、可視化し、わかったことについて簡単に考察を述べるという課題が出ます。
課題
テーマ
都内全域のレストランの相場を可視化し考察せよ
また、その他とれそうな変数を取得し、予算と比較しながら分析する。
サブテーマ
テーマが抽象的なので以下のような具体的なシチュエーションを設けたいと思います。
シチュエーション
東京に遊びに来た友達に「東京のレストランの相場はどの程度で、その相場では何のジャンルが一番多いか」ということをデータを使って客観的に示す。
その他発見した事象
サブテーマに添えて予算と他の変数を比較するために可視化し、わかったことを示します。
方針
- グルメサイト「ホットペッパーグルメ」をクローリングし、各お店の詳細ページのurlを取得
- 各お店の詳細ページのurlからそのhtmlファイルを保存(お店の件数=保存したhtml数)
- 取得したHTMLファイルから各変数をスクレイピング
- 可視化・データ分析
- テーマに対する答えを提示
クローリング
今回、クローリングするのはホットペッパーグルメサイトの「都内全域のネット予約可能なお店」の検索結果となっています。
2019/10/16(水)に16475件のお店を取得。
クローリングの手順
- のちに検収結果を確認するためにクローリング前に最初のページからお店の件数を取得
- [1ページ目]各お店の詳細ページのurl(以下、お店url)を読みpythonのリストに保存
- [次ページへの遷移]ページネーションから次ページのURLを取得し遷移する
- 遷移先ページからお店urlを読みpythonのリストに保存
- 次ページがなくなるまで 2,3 を繰り返す
- リストに保存されているお店urlへ飛びからそのhtmlファイルを一軒ずつ保存
- 最後に1.と同様の方法で最後のページからスクレイピングによりお店の件数を取得
クローリングのコードは以下のようになっています。
from bs4 import BeautifulSoup
import requests
import time
import os
# timer
t1 = time.time()
# function
# get number of shop
def get_num(soup):
num = soup.find('p', {'class':'sercheResult fl'}).find('span', {'class':'fcLRed bold fs18 padLR3'}).text
print('num:{}'.format(num))
# get url of shop
def get_shop_urls(tags):
shop_urls = []
# ignore the first shop because it is PR
tags = tags[1:]
for tag in tags:
shop_url = tag.a.get('href')
shop_urls.append(shop_url)
return shop_urls
def save_shop_urls(shop_urls, dir_path=None, test=False):
# make directry
if test:
if dir_path is None:
dir_path = './html_dir_test'
elif dir_path is None:
dir_path = './html_dir'
if not os.path.isdir(dir_path):
os.mkdir(dir_path)
for i, shop_url in enumerate(shop_urls):
time.sleep(1)
shop_url = 'https://www.hotpepper.jp' + shop_url
r = requests.get(shop_url).text
file_path = 'shop{:0>5}_url.html'.format(i)
with open(dir_path + '/' + file_path, 'w') as f:
f.write(r)
# return last shop number
return len(shop_urls)
start_url = 'https://www.hotpepper.jp/yoyaku/SA11/'
response = requests.get(start_url).text
soup = BeautifulSoup(response, 'html.parser')
tags = soup.find_all('h3', {'class':'detailShopNameTitle'})
# get last page number
last_page = soup.find('li', {'class':'lh27'}).text.replace('1/', '').replace('ページ', '')
last_page = int(last_page)
print('last page num:{}'.format(last_page))
# get the number of shops before crawling
get_num(soup)
# first page crawling
start_shop_urls = get_shop_urls(tags)
# from 2nd page
shop_urls = []
# last page(test)
last_page = 10 # test
for p in range(last_page-1):
time.sleep(1)
url = start_url + 'bgn' + str(p+2) + '/'
r = requests.get(url).text
soup = BeautifulSoup(r, 'html.parser')
tags = soup.find_all('h3', {'class':'detailShopNameTitle'})
shop_urls.extend(get_shop_urls(tags))
# how speed
if p % 100 == 0:
percent = p/last_page*100
print('{:.2f}% Done'.format(percent))
start_shop_urls.extend(shop_urls)
shop_urls = start_shop_urls
t2 = time.time()
elapsed_time = t2 - t1
print('time(get_page):{:.2f}s'.format(elapsed_time))
print('num(shop_num):{}'.format(len(shop_urls)))
# get the url of shop
last_num = save_shop_urls(shop_urls) # html_dir
# get the number of shops after crawling
get_num(soup)
t3 = time.time()
elapsed_time = t3 - t1
print('time(get_html):{:.2f}s'.format(elapsed_time))
print('num(shop_num):{}'.format(last_num))
スクレイピング
以下が今回スクレイピングした変数になります。
手順
- 各お店ごとに上記の9つの変数をスクレイピングしていく
- 変数が出揃ったらレコードとしてpandasのDataFrameに追加
- 整合性がとれているかクローリングで取得したお店の件数とレコードの数を照合
スクレイピングのコードは以下のようになっています。
from bs4 import BeautifulSoup
import glob
import requests
import time
import os
import pandas as pd
from tqdm import tqdm
import numpy as np
def get_shopinfo(category, soup):
shopinfo_th = soup.find('div', {'class':'shopInfoDetail'}).find_all('th')
# get 'category' from 'shopinfo_th'
category_value = list(filter(lambda x: category in x , shopinfo_th))
if not category_value:
category_value = None
else:
category_value = category_value[0]
category_index = shopinfo_th.index(category_value)
shopinfo_td = soup.find('div', {'class':'shopInfoDetail'}).find_all('td')
category_value = shopinfo_td[category_index].text.replace('\n', '').replace('\t', '')
return category_value
# judge [] or in
def judge(category):
if category is not None:
category = category.text.replace('\n', '').replace('\t', '')
else:
category = np.nan
return category
# judge [] or in
def judge_atag(category):
if category is not None:
category = category.a.text.replace('\n', '').replace('\t', '')
else:
category = np.nan
return category
# judge [] or in
def judge_ptag(category):
if category is not None:
category = category.p.text.replace('\n', '').replace('\t', '')
else:
category = np.nan
return category
# judge [] or in
def judge_spantag(category):
if category is not None:
category = category.span.text.replace('\n', '').replace('\t', '')
else:
category = 0
return category
# available=1, not=0
def available(strlist):
available_flg = 0
if '利用可' in strlist:
available_flg = 1
return available_flg
# categorize money
def category2index(category, range):
if category in range:
category = range.index(category)
return category
def scraping(html, df, price_range):
soup = BeautifulSoup(html, 'html.parser')
dinner = soup.find('span', {'class':'shopInfoBudgetDinner'})
dinner = judge(dinner)
dinner = category2index(dinner, price_range)
lunch = soup.find('span', {'class':'shopInfoBudgetLunch'})
lunch = judge(lunch)
lunch = category2index(lunch, price_range)
genre_tag = soup.find_all('dl', {'class':'shopInfoInnerSectionBlock cf'})[1]
genre = genre_tag.find('p', {'class':'shopInfoInnerItemTitle'})
genre = judge_atag(genre)
area_tag = soup.find_all('dl', {'class':'shopInfoInnerSectionBlock cf'})[2]
area = area_tag.find('p', {'class':'shopInfoInnerItemTitle'})
area = judge_atag(area)
rating = soup.find('div', {'class':'ratingInfo'})
rating = judge_ptag(rating)
review = soup.find('p', {'class':'review'})
review = judge_spantag(review)
f_meter = soup.find_all('dl', {'class':'featureMeter cf'})
# if 'f_meter' is nan, 'size'='customer'='people'='peek'=nan
if f_meter == []:
size = np.nan
customer = np.nan
people = np.nan
peek = np.nan
else:
meterActive = f_meter[0].find('span', {'class':'meterActive'})
size = f_meter[0].find_all('span').index(meterActive)
meterActive = f_meter[1].find('span', {'class':'meterActive'})
customer = f_meter[1].find_all('span').index(meterActive)
meterActive = f_meter[2].find('span', {'class':'meterActive'})
people = f_meter[2].find_all('span').index(meterActive)
meterActive = f_meter[3].find('span', {'class':'meterActive'})
peek = f_meter[3].find_all('span').index(meterActive)
credits = get_shopinfo('クレジットカード', soup)
credits = available(credits)
emoney = get_shopinfo('電子マネー', soup)
emoney = available(emoney)
data = [lunch, dinner, genre, area, float(rating), review, size, customer, people, peek, credits, emoney]
s = pd.Series(data=data, index=df.columns, name=str(i))
df = df.append(s)
return df
columns = ['予算(昼)', '予算(夜)', "ジャンル", "エリア", '評価', 'レビュー件数', 'お店サイズ'
, '客層', '人数/組', 'ピーク時間帯', 'クレジットカード', '電子マネー']
base_url = 'https://www.hotpepper.jp/SA11/'
response = requests.get(base_url).text
soup = BeautifulSoup(response, 'html.parser')
# GET range of price
price_range = soup.find('ul', {'class':'samaColumnList'}).find_all('a')
price_range = [p.text for p in price_range]
# price_range = ['〜500円', '501〜1000円', '1001〜1500円', '1501〜2000円', '2001〜3000円', '3001〜4000円', '4001〜5000円'
# , '5001〜7000円', '7001〜10000円', '10001〜15000円', '15001〜20000円', '20001〜30000円', '30001円〜']
num = 16475 # number of data
# num = 1000 # test
df = pd.DataFrame(data=None, columns=columns)
for i in range(num):
# for i in tqdm(lis):
html = './html_dir/shop{:0>5}_url.html'.format(i)
with open(html,"r", encoding='utf-8') as f:
shop_html = f.read()
df = scraping(shop_html, df, price_range)
if i % 1600 == 0:
percent = i/num*100
print('{:.3f}% Done'.format(percent))
df.to_csv('shop_info.csv', encoding='shift_jis')
検収結果
以下のような検収結果となりました。

クローリングの際に1時間弱の時間を要したので、その間にサイトが更新してしまい、
最初にあったお店数とクローリング後のお店数に違いが生じていることが分かります。
サブテーマに対する結果
サブテーマの確認
「都内のレストランの相場を可視化して、
その価格帯ではどのジャンルのお店が一番多いかを明らかにする。」
サブテーマに対する結論
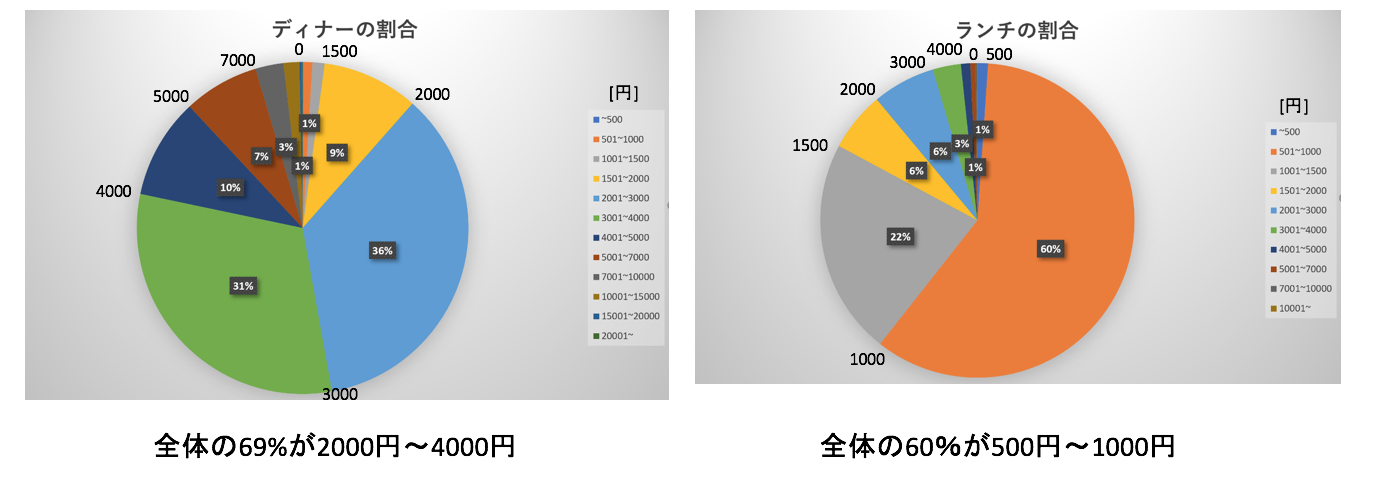
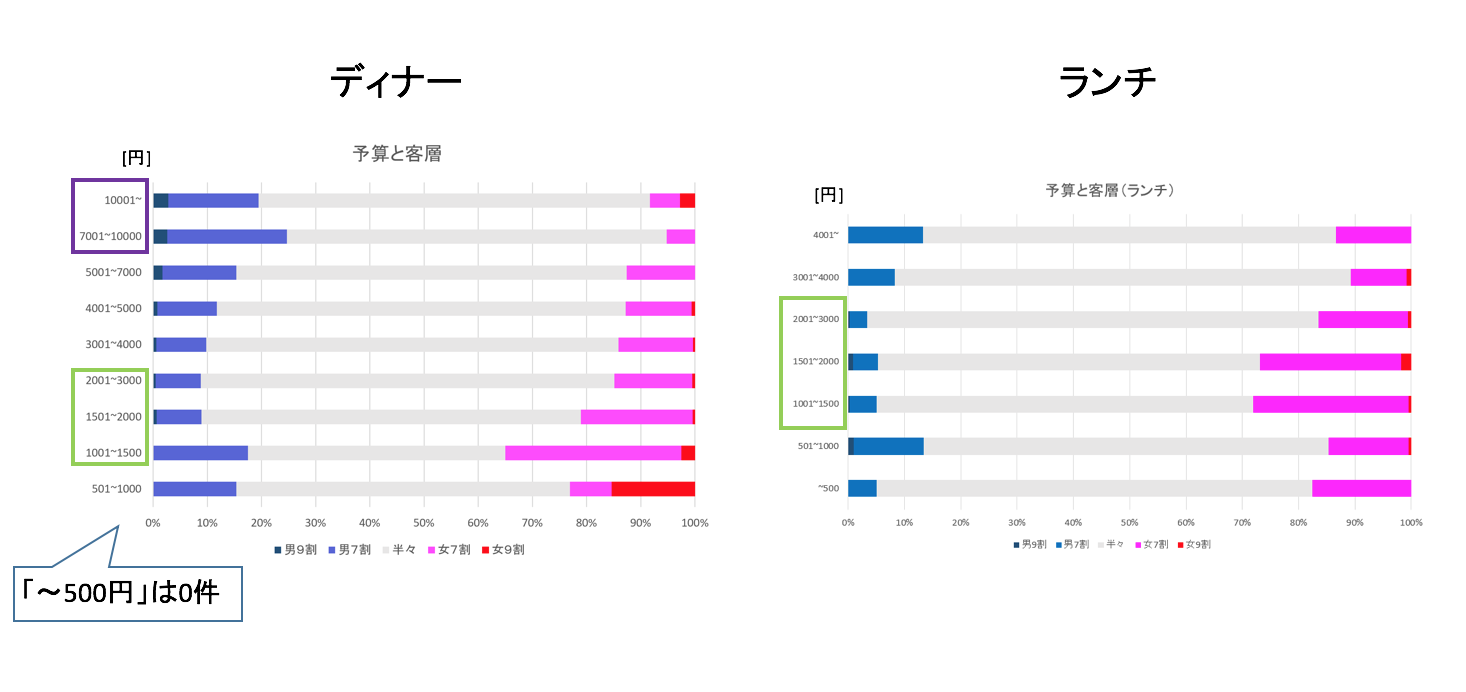
- ディナーの相場は「2000~4000円」である。
- ランチの相場は「500~1000円」である。
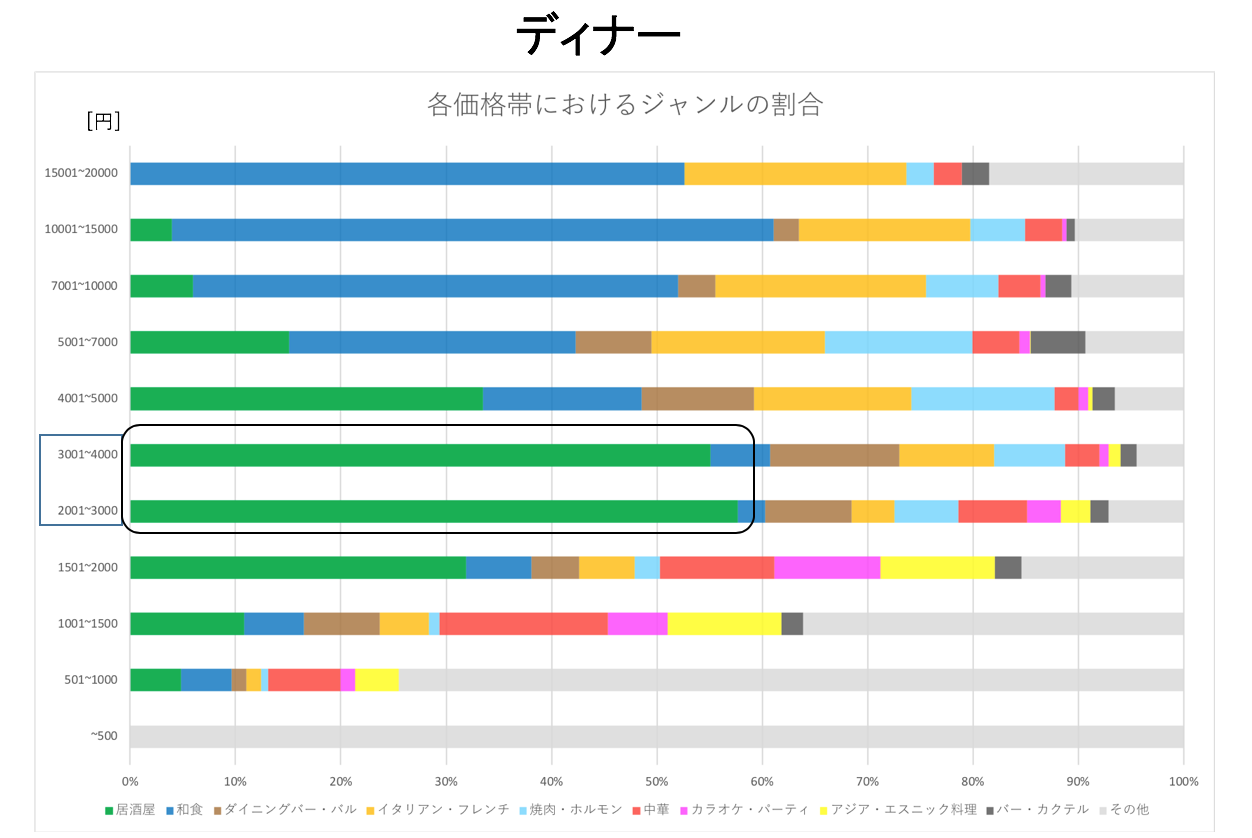
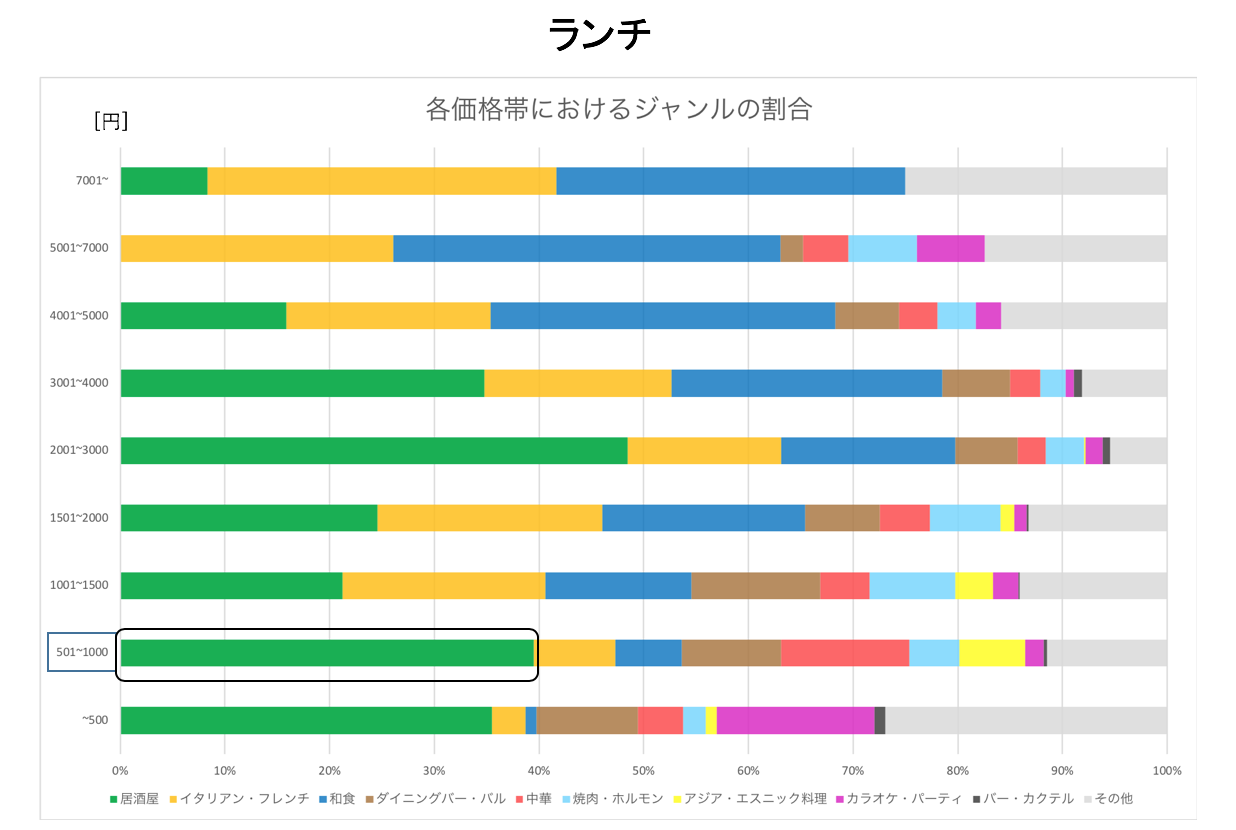
- ディナーとランチのそれぞれの相場で一番割合が多かったジャンルは「居酒屋」である。
- また、ランチにおいて「500~1000円の居酒屋」は二毛作店であろう。
なお、ここでは予算の相場は「平均値ではなく最頻値」と定義している。
以下順に根拠となるデータを示していきます。
予算の相場
ディナーとランチに分けて予算の相場を可視化しました。
価格帯別のジャンル
上記の結果から都内のレストランの大まかな相場が分かったので、次に価格帯別のジャンルを可視化していきます。
「その他」に含まれるジャンル
ディナー・ランチともに以下の全体の数が少なかったジャンルについては「その他」に含んでいます。
[お好み焼き・もんじゃ/カフェ・スイーツ/ラーメン/韓国料理/各国料理/洋食/創作料理/その他グルメ]
ここでランチにおいて「500〜1000円」の価格帯の「居酒屋」があまりにも安いと考えたので、ここを深掘りしていきます。
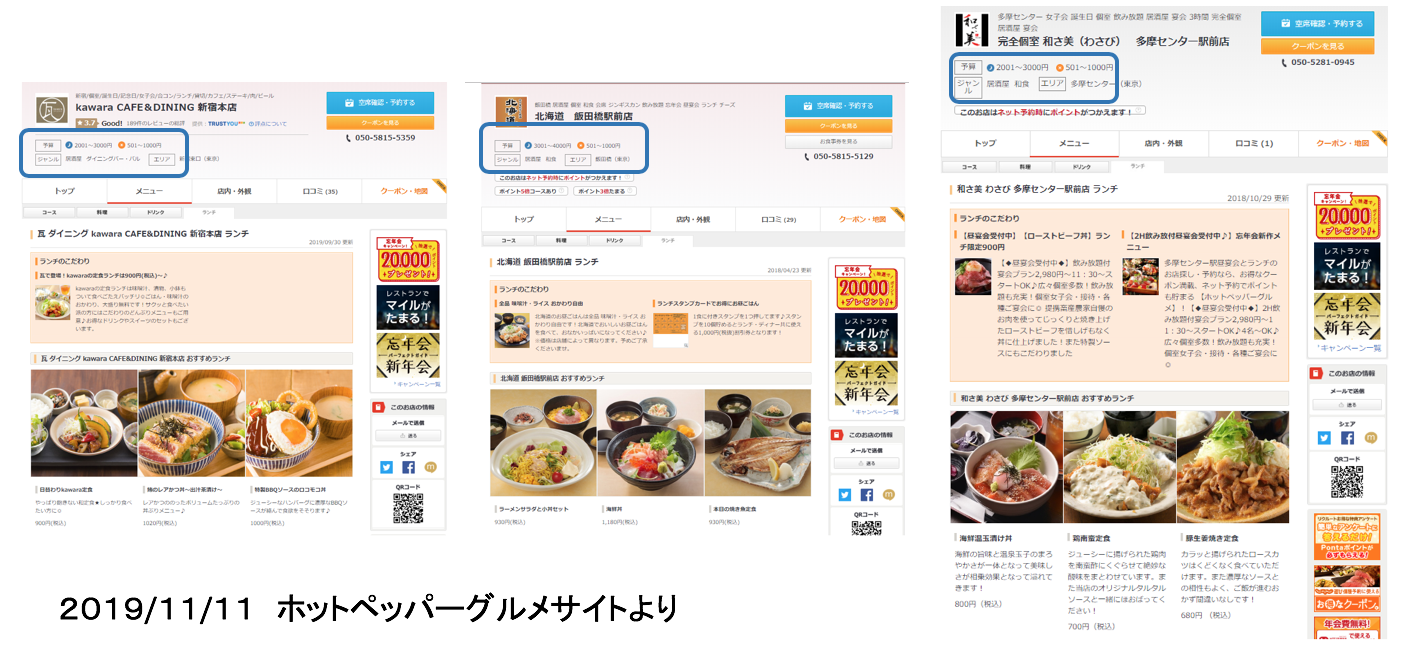
「500〜1000円」の居酒屋とは
以下のように「居酒屋」と名乗りながらも昼間はランチ用のメニューを提供されていることがわかる。
その他発見した事象
結論
-
ディナーの「7000円~」の価格帯のお店の客層は女性客よりも男性客が多い傾向が見られ、また、ディナーとランチともに「1000~3000円」の価格帯のお店の客層は男性客よりも女性客が多い傾向が見られる。
-
ディナーとランチともに高価格帯になるほど高評価になる傾向がある。
-
高価格帯ではクレジットカードを利用可としているお店の割合が多い
-
ディナーの「2000~4000円」の価格帯のお店はそのキャパが広い傾向がある。
以下、根拠となるデータを示します。
価格帯別の客層
客層別に価格帯を比較しました。
このことから言える主張として、ディナーでは「7000円~」の価格帯のお店の客層は女性客よりも男性客が多い傾向が見られ、また、ディナー、ランチともに「1000~3000円」の価格帯のお店の客層は男性客よりも女性客が多い傾向が見られることがわかった。
価格帯別の評価
ディナーとランチのそれぞれの価格帯において評価をプロットしていきます。その際に同じ価格帯の同じ評価のお店が多数ある箇所が存在するのでジッタリングを採用して意図的にずらしてプロットしています。また、グラフの下にt検定の結果を示します。
t検定の定義
ディナー: 4000円以下のお店と4000円以上のお店でグループ分け
ランチ: 2000円以下のお店と2000円以上のお店でグループ分け
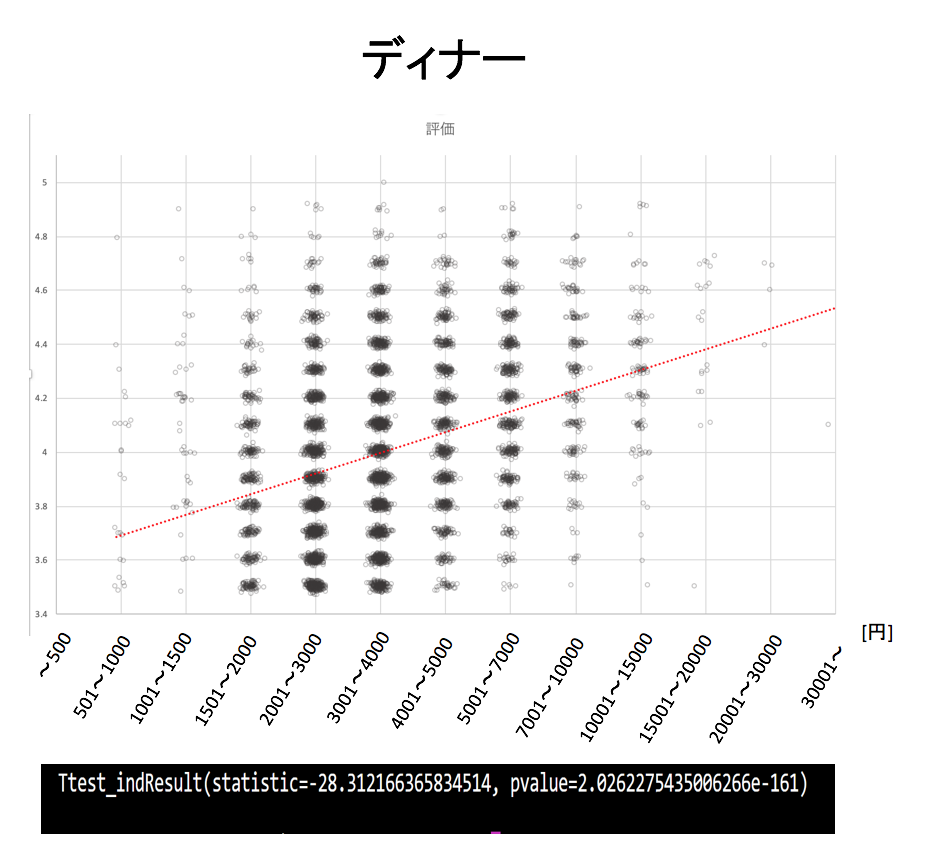
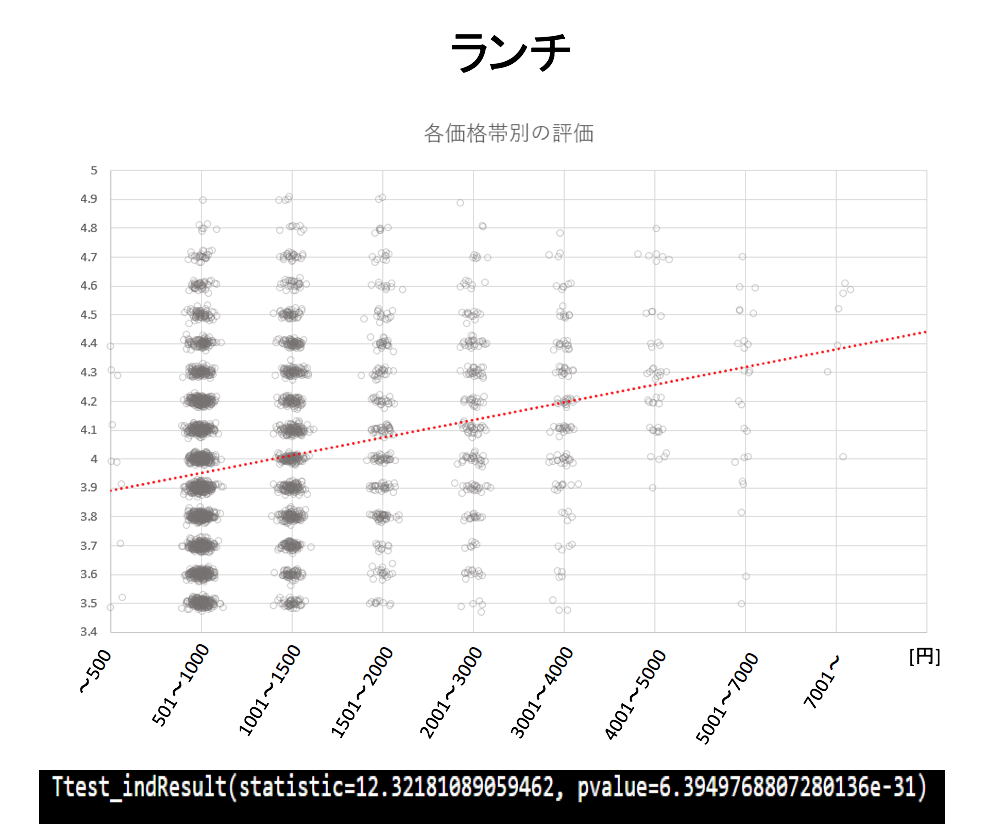
ディナーとランチともに高価格帯になるほど高評価になる傾向があることがわかります。
t検定の結果からも高価格帯と低価格帯で「評価」に差があるといえます。
価格帯別のクレジットカード利用状況
クレジットカードの利用状況を価格帯別で比較しました。
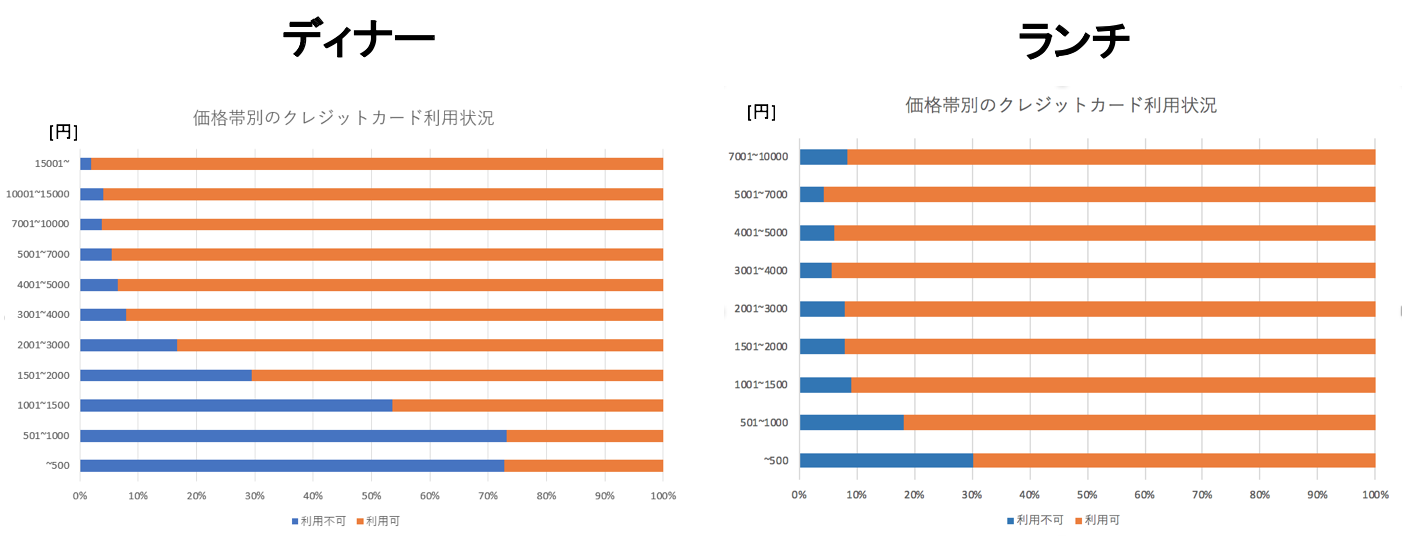
ここでも直感と一致して、高価格帯ではクレジットカードを利用可としているお店の割合が多いことがわかりました。
なお、ランチの「10000円〜」の価格帯は4件と評価に足る件数が得られなかったため表示していません。
価格帯別のお店のサイズ
5段階で評価されたお店のサイズを価格帯別で比較しました。
ここではディナーのみ結論づけることがありましたので、そちらのみの掲載となります。濃い青ほどお店が広いです。
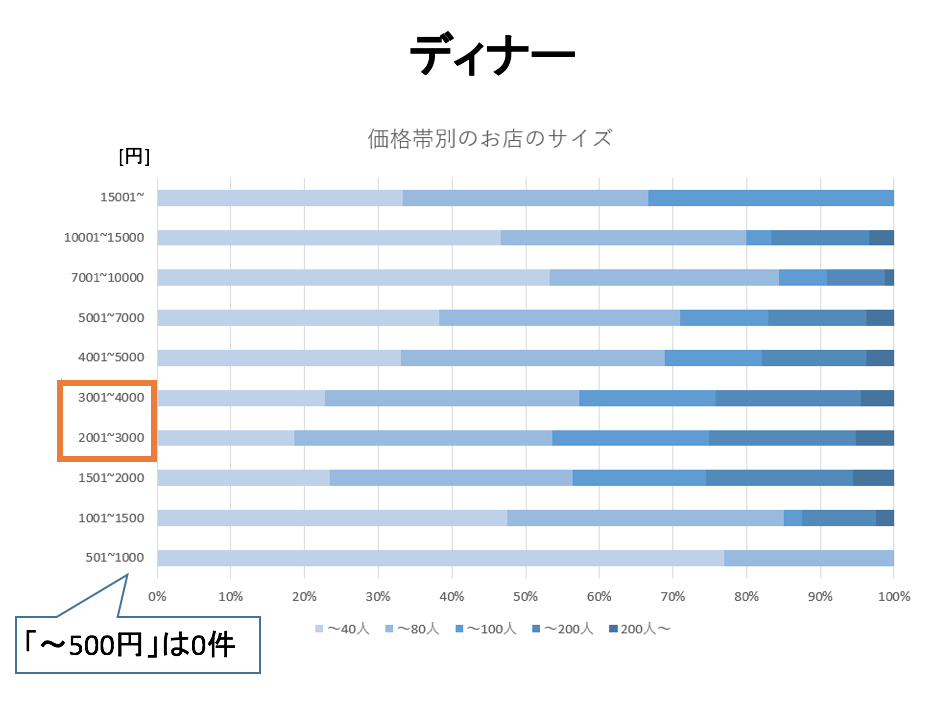
ディナーにおいて「2000~4000円」の価格帯のお店はそのキャパが広い傾向があることがわかります。この価格帯は居酒屋の割合が大きいことから、キャパが広い居酒屋が大きいのではないかと考えられます。
おわりに
反省点
「スクレイピングで得た情報をまとめて、その結論が相手に伝わるように可視化する」ということがいかに難しいかを身をもって実感しました。
もう一度やるなら
コードを書く前に分析の明確な目的を定めて、逆算してプロセスを計画立てる
フィードバックから学んだこと
コードレビューをうけて
以下の指摘を受けましたので、以後改善していきたいと思います。
- pep8と呼ばれるpythonのコード規約を意識しながらコードを書くこと
- 無駄な改行やコメントアウトを整理してから提出すること
発表レビューをうけて
「伝わりやすくするためにどうグラフを見せるか」というプロセスでした。上にいくほど高価格帯になるとしたり、ジッタリングにより密集度を表したりと「直感にあったグラフ」を作成することが大切だとフィードバックを受けました。
また、ストーリー性のある結論を見せることが相手の理解度につながると学びました。得られた結果を現実問題にどうつなげるかを意識しながらこれからの分析ライフを過ごしていきます。