TL;DR;
以下の「ほん訳こんにゃく」を作った。



![]()



(※ 上記のbadgeを 2020/12/18 に追記しました。 )
作りたかったもの
研究室配属で、かねてから取り組みたかった 「シナプス可塑性におけるmiRNA機能とそれらが記憶や学習などの高次認知機能に与える影響の解明」 を自分の研究テーマ(※暫定)にすることができ、生物系の論文を読む機会が圧倒的に増えたのですが、元々深層学習系統の論文しか読んでいなかったため、常識や背景知識不足に悩まされ、DeepLやGoogle Translateなしには論文が読めないという日々が続いていました。
論文を読みながら適宜翻訳するのは非効率ですし、iPadにPDFを保存して電車内で読むなんてこともできず、かといって全部一度翻訳するのは非常に面倒で、「これ、自動化したいな〜」と思ったので、「論文のURLを投げれば、全文翻訳付きのPDFを生成するプログラム」を作りました。
論文たくさん読みたいけど英語の勉強もしたいので、url投げたら全文翻訳付きのPDFに変換してもらうことにした。 pic.twitter.com/dMvqU2PBa4
— しゅーと (@cabernet_rock) June 29, 2020
Python Package
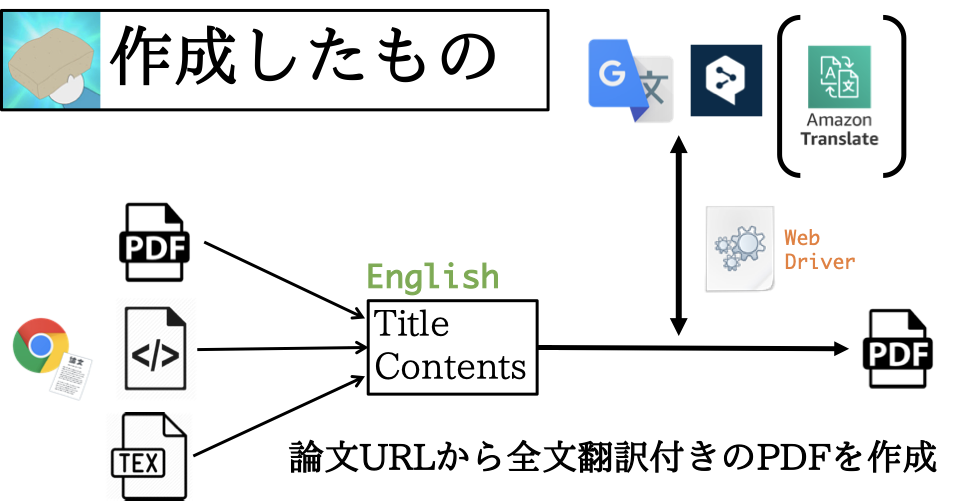
まず、Pythonでライブラリ(Translation-Gummy)を作成しました。先に述べたことを実現するために必要な機能は
- URLから論文の内容をスクレイピング →
requests,Beautiful Soup,pdfminer,pylatexenc - スクレイピングした内容(英語)を日本語に翻訳 →
selenium, DeepL, Google Translate - 両者を並べたPDFを作成 →
jinja2,pdfkit
ですが、それぞれ右に記した各種ライブラリ/サービスを使えば、実現可能です。
なお、翻訳の際に selenium の WebDriver を使っていますが、これは以下のように requests.get でサイト(https://translate.google.co.jp/#ja/en/これはペンです)の内容を取得しても、動的なサイトであるため翻訳結果を取得することができないためです。
# coding:utf-8
import requests
from bs4 import BeautifulSoup
html = requests.get("https://translate.google.co.jp/#ja/en/これはペンです").content
soup = BeautifulSoup(markup=html, features="html.parser")
:
※ より詳しいプログラムコードが見たい方は、Githubからどうぞ。
(↓ 2020/08/28 追記 ↓)
導入方法を 『「ほん訳コンニャク」 を使ってみよう。』 で紹介しました。
(↓ 2020/09/30 追記 ↓)
ドキュメントを作成し、GitHub Pages で公開しました。
PDF converter
ローカルにあるPDFファイルを翻訳してくれるWebサイトがあれば良いなと思い、作成しました。ここでは pdfminerを用いて翻訳を行っていますが、かなり雑な実装になってしまっているので、Pull requests をお待ちしています。(gummy.journals.LocalPDFCrawler というクラスを用いています。)
なお、WebサイトはAWSのEC2を使って公開しております。
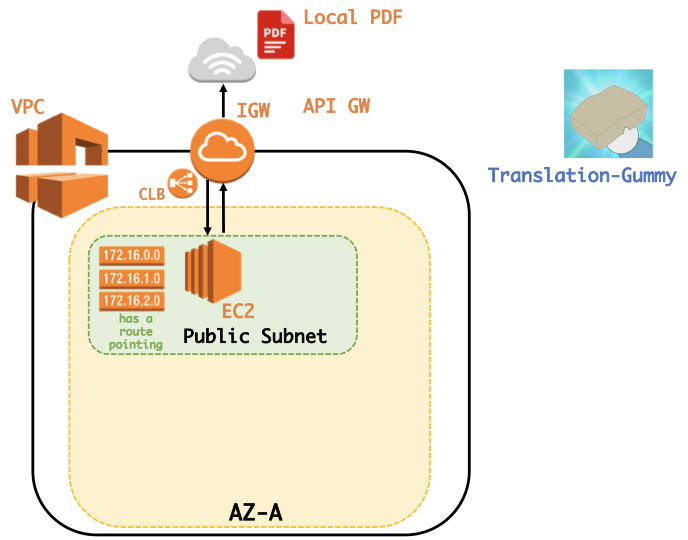
PythonしかかけないけどWebサイトを公開したい、という方はこの記事:『PythonかければWebアプリぐらい作れる。』が参考になるかと思います。(自分の記事を紹介してしまい、すみません。)
Slack App
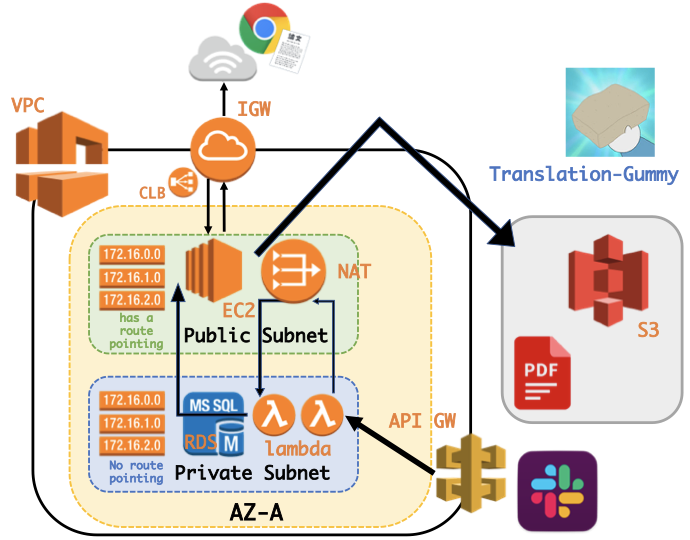
Slack App として、コマンドで呼び出せれば楽だと思い、作成し公開しました。

この時、
- OAuth認証を用いてワークスペースに基づいた
SLACK ACCESS TOKENを取得し、BOT投稿するためにPrivate Subnet内のRDSにSLACK ACCESS TOKENを保存する。 - lambdaからデータベースへの多すぎるコネクションにより過負荷になることを避けるため、RDS PRoxyを使用し、コネクションプールを確立および管理をする。
- Slack Botに3秒以内にレスポンスを返さないといけないためlambdaからlambdaを非同期で呼ぶ。
- Private Subnet内のlambdaから直接lambdaを呼べないため、Public subnetに配置したNAT Gatewayを利用する。
- 負荷を分散するためにLoad Balancerを設置する。
などの機能を実現するため、以下のような少し複雑な構成となってしまいました。(改良点等あればコメントでご指摘ください🙇♂️)
終わりに
自分の欲しい機能を全て実現したサービスができたと思います。対応ジャーナルの数を増やしたり、PDFの解析をより正確に行ったり、PDFをより綺麗に整えたりとまだまだ足りない機能は多々ありますが、使っていただけると幸いです。