はじめに
Ansible Automation Platform on AWS (SaaS) で Execution Node を設定した後、インスタンスを停止 → 起動すると、以前は正常に動作していたジョブが突然失敗する事象が発生していました。
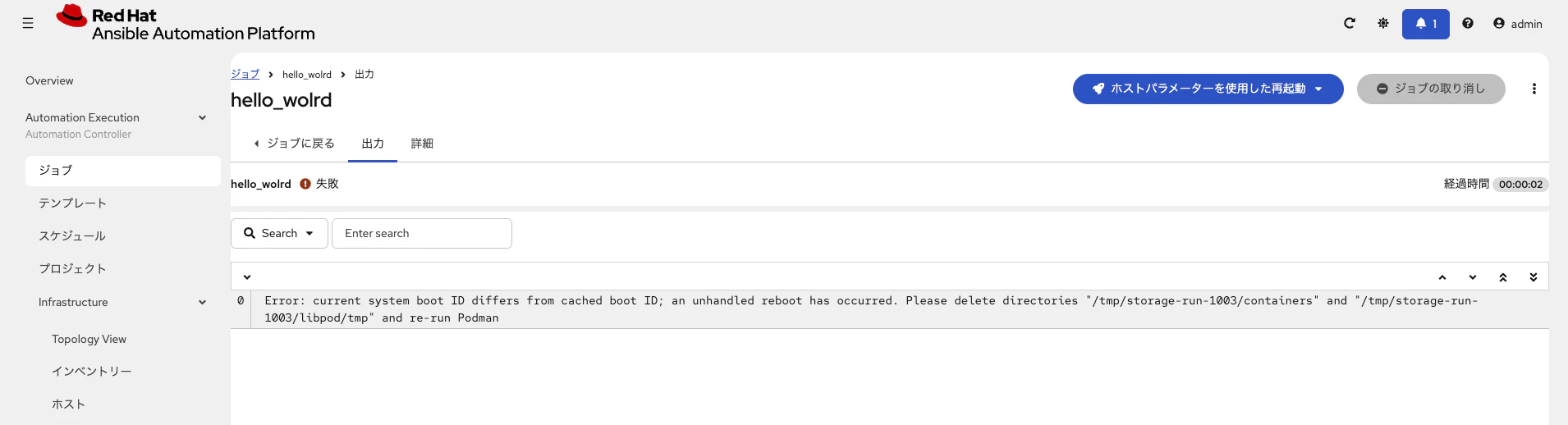
調査したところ、Execution Node 内に保持される一時領域(/tmp 配下)に残った Podman のキャッシュ情報が、再起動後の boot ID と不整合を起こすことが原因であると判明しました。
対応方法を記載します。
AAP on AWS(SaaS)の Execution Node の構築方法については、以下で説明しています。
環境
AWS EC2 instance (RHEL9)
- AAP on AWS の Execution node として構成済み
解決策
/tmp を tmpfs(メモリ上)にマウントし、再起動時に自動的にクリーンにする
Podman rootless 実行環境では、実行状態や一時情報を /tmp 配下に保存する場合があります。
しかし OS を再起動した際、前回実行時の一時データが残っていると、Podman が「前回の boot ID と異なる」と誤認し、ジョブが失敗することがあります。
これを防ぐために、/etc/fstab に /tmp を tmpfs としてマウントする設定を追加します。
tmpfs /tmp tmpfs defaults 0 0
tmpfs とは?
tmpfs は、ディスクではなく RAM(またはスワップ領域)上に作られる一時ファイルシステムです。
- /tmp がメモリ上にマウントされる
- OS 再起動時に /tmp の内容が必ずクリアされる
- Podman の古い一時状態が残らないため、boot ID 不一致エラーを回避できる
今回発生した Podman のエラーは、まさに「再起動後に残った /tmp/storage-run-* などのキャッシュ」が原因のため、tmpfs 化が効果的です。
これにより、OS再起動時に /tmp 内の古い情報が確実にクリアされるため、boot ID の不一致によるエラーが発生しなくなります。
注意点
/tmp を指定しているため、OS 再起動すると /tmp 配下のファイルはすべて削除されます。
ただし、Linux 標準の設計として /tmp に永続ファイルを置くこと自体が非推奨です。
再起動後も保持したい一時ファイルは /var/tmp を利用してください。
設定反映後の確認
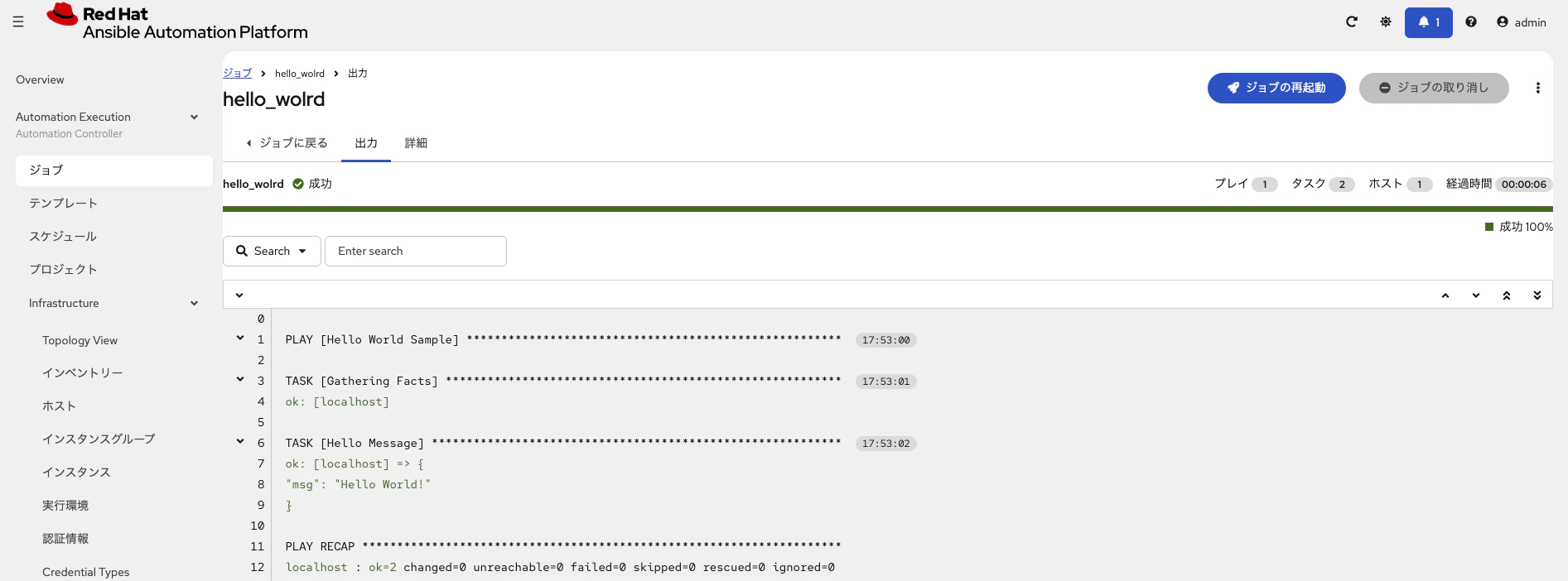
/etc/fstab を修正し、OS を再起動した後に再度同じジョブを実行しました。
Podman の一時情報がクリーンになったことで、ジョブが正常に実行できることを確認しました。
まとめ
・Execution Node 上で Podman が /tmp に残した一時データが原因で、再起動後にジョブが失敗することがある
・/tmp を tmpfs 化することで、再起動時に /tmp が自動的に初期化され、エラーを防止できる
・/tmp の内容は再起動で消えるため、永続データは /var/tmp を使用する
以上です。