IoTと見える化
ここ数年、RaspberryPi、Arduino、M5Stackなど、IoT向けマイコンモジュールが続々登場し、低コストにセンサデータを取得できる時代となっています。
一方で、価値を出すためには人間が分かりやすい形で
「つなぐ」「見える化する」
必要があります。
(下は内閣府のSociety 5.0の資料)
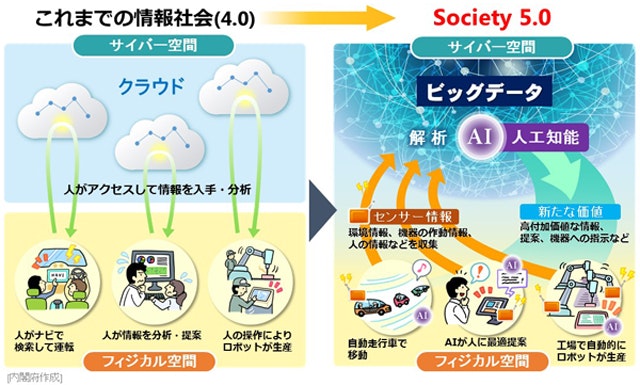
例えば
"smart_meter": {
"echonetlite_properties": [
{
"name": "normal_direction_cumulative_electric_energy",
"epc": 224,
"val": "294263",
"updated_at": "2020-08-12T10:09:14Z"
},
{
"name": "measured_instantaneous",
"epc": 231,
"val": "432",
"updated_at": "2020-08-12T10:09:14Z"
}
]
}
のようなJSONの消費電力生データを見せられても困りますが、
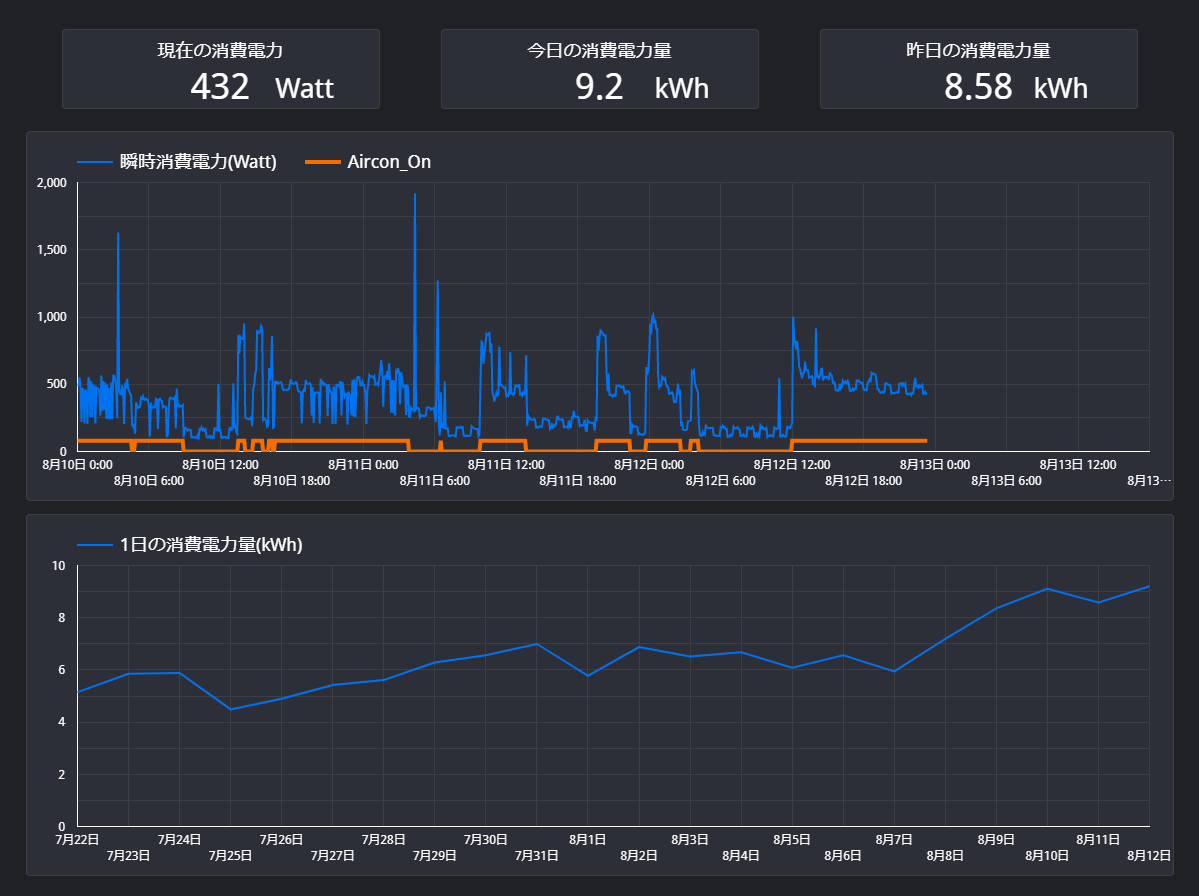
のようにグラフで表示してくれると分かりやすいですね!
それが外出先でスマホやタブレットから見られたり、分析できたりすると、なお嬉しいです!
タダで見える化したい!
上記のような見える化システムは、お金を掛ければいくらでも凄いものは作れます。
ここで問題となるのはコスト!

個人開発ではなるべくタダにしたい、というのが一般的な感覚だと思います
今回はRaspberryPiを例に、**「タダ」で「見える化」**できる手段をまとめてみました
「タダ」で「見える化」の定義
タダはタダでも、
「30日間無料試用版ソフト使用!ラズパイとHDMIケーブル接続した画面でしか見えません!」
では実用性があるとは言い難いので、
高付加価値な構成とするため要件を定めたいと思います
「タダ」とは?
RaspberryPiや、データを取得するためのセンサはもちろんタダではありません。
今回は上記のようなハード購入費や、上記をインターネットに接続するための費用(ルータやネット回線)を除いてタダと定義したいと思います。
具体的には、
①RaspberryPiを出た後の処理は無料サービスのみで構成
→Raspberryから送信したデータを管理するDB、可視化ツールが相当します
②永続無料サービス
→「30日無料」等の期間付き無料サービスは除外。容量制限等は許容します
「見える化」とは?
一般の人からすると、「目的に合わせたグラフ表示」をすることに価値があると思います。
上記を軸として使い勝手を考慮し、下記の3条件を必須とします
①ダッシュボードでのグラフ表示をゴールとする
②自宅ネットワーク外からもアクセス可能とする
③維持コストの掛かるオンプレサーバは避け、クラウドサービスを使用する
調査結果まとめ
前章の条件を満たしつつ、「タダ」で「見える化」できるサービスをまとめてみました。
| ①Ambient使用 | ②Google Spreadsheets + Data Portal | ③クラウドDB + 自作可視化アプリ | |
|---|---|---|---|
| データ管理 | Ambient | Google Spreadsheets | クラウドDB |
| 可視化 | Ambient | Google Data Portal | 自作アプリ(Web, モバイル等) |
| メリット | 最小工数で可視化できる | 手軽さとUIの綺麗さのバランス | 自由度の高さ、スケールアップの容易さ |
| デメリット | 自由度があまりなく、高度な分析は難しい | 数万行以上のデータでは動作が非常に重い | 開発工数大、無料版の制約が分かりづらい |
| 想定用途 | センサのテスト、電子工作 | 個人、少人数チームでのデータ共有効率化 | 高度な分析、サービス展開を前提とした開発 |
①Ambientを使用
下記のような構成となります(公式ホームページより)
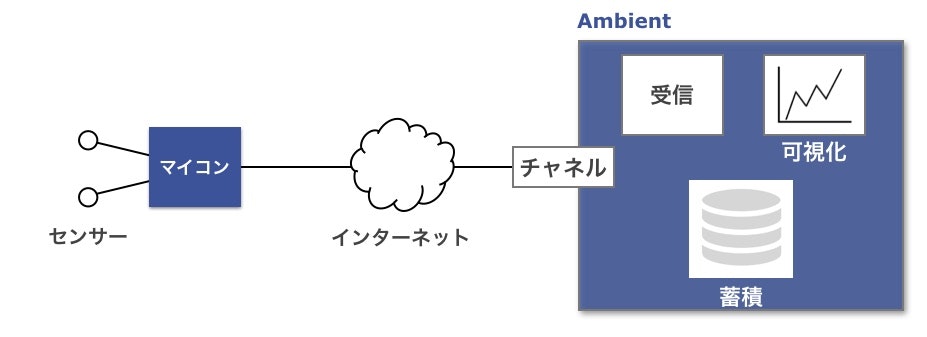
ストレージと可視化を一括管理できるので
最小工数で見える化したい人向けだと思います。
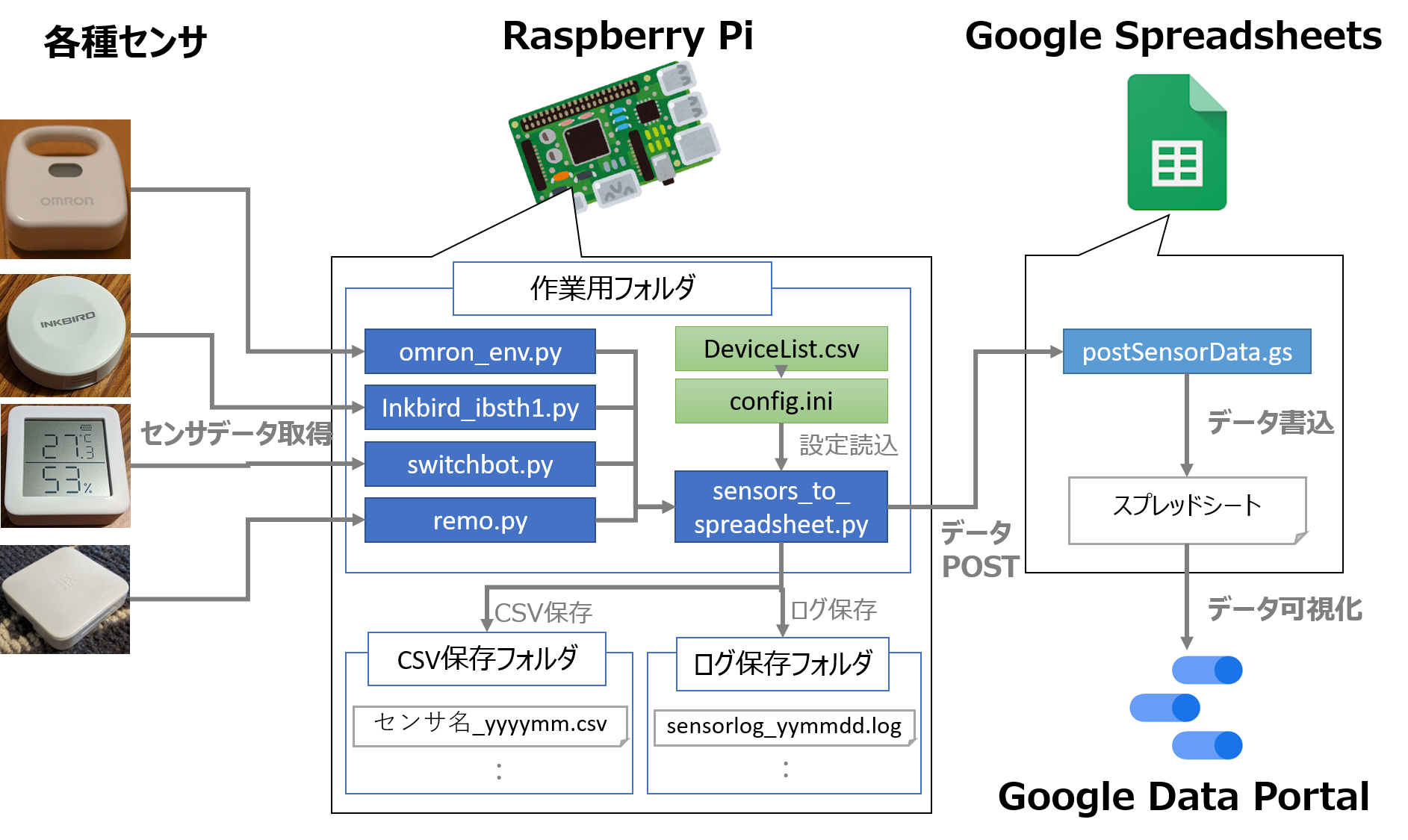
②Google Spreadsheets + Google Data Portalを使用
下記のような構成となります

Googleの既存UIをフル活用できるので、
手軽にキレイなダッシュボードを作りたい人向けだと思います
③クラウドDB + 自作アプリで可視化
下記のような構成となります
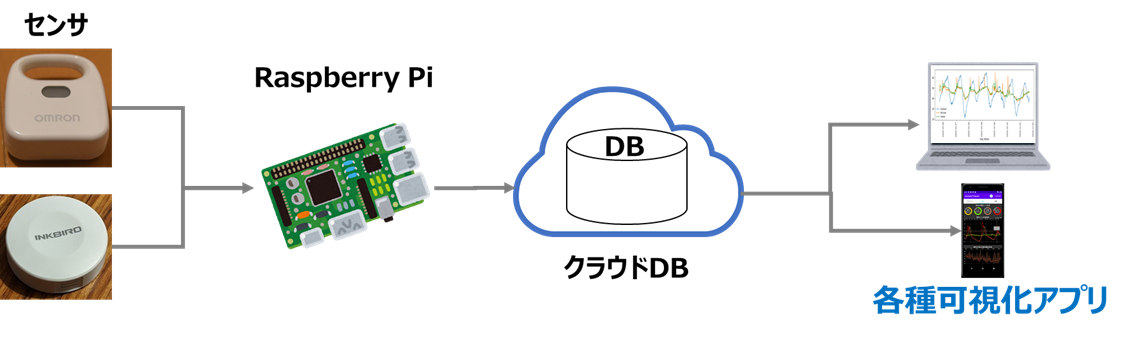
拡張性が高く、無限の可能性が広がる方法だと思いますが、
選択肢が多い分、システム構成の検討や実装に手間が掛かります。
こちらを参考にさせて頂き、無料枠のある主要クラウドDBを表にまとめました
|プラットフォーム|Heroku Postgre|MongoDB Atlas|Google Cloud Platform|Microsoft Azure|AWS|
|---|---|---|---|---|---|---|
|DB|Postgre|MongoDB|BigQuery|Cosmos DB|DynamoDB|
|方式|RDBMS|NoSQL|列志向|NoSQL|NoSQL|
|無料可視化ツール|自作が必要|自作が必要|Google Data Portal|Power BI|自作が必要|
|無料枠でできること|上限1万行|上限500MB|上限10GB(参考リンク)|上限5GB参考リンク|上限25GB(参考リンク)|
|メリット|貴重なリレーショナルDB|プラットフォーム依存低&モバイル連携|Google Data Portalでお手軽UI|高機能なPowerBIを使える|市場シェアNo1で情報が多い|
※無料枠があるとはいえ、上限を超えると予想外の金額が掛かってしまうこともあるので、あくまで最新情報を調査の上、自己責任でご使用ください (こんな恐ろいことも‥)
作ってみた
説明文や構成図だけではイメージが沸かないかと思うので、
下記構成で実際に実装した方法を下の章で解説します。
【構成】
クラウドDB:MongoDB Atlas
可視化ツール:Jupyter Notebook & 自作Androidアプリ(別記事)
※なぜMongoDB Atlasを選んだか?
上表太字のメリットが理由となりますが、さらに詳しく言うと下記のようになります。
(本音を言うとAWS等は記事数が多いので、独自性を出したかったということもあります笑)
1. オンプレミスへの移植が容易
他のクラウド専用DBとは異なり、オンプレDBのMongoDBをベースとしており、少ない改造量で移植可
2. プラットフォーム依存性が低い
企業として当たり前の戦略ですが、例えばAzureのDBからGCPのサービスを使用するには、互換性の壁があるようです。
MongoDBであれば各プラットフォーマーが互換性を(自社DBほどでないにしろ)考慮しているので、どのプラットフォームとも連携、移植の工数が少なく済みます。
※逆に言うと、「私はGoogle一本に絞る」「チームのサービスがAzureで統一されている」という方は、Google Cloud DatastoreやAzure Cosmos DBにした方が、分析サービスとも容易に連携できますし、サポートも手厚いのでおすすめです
3. モバイル連携
こちらで記事となっているように、モバイル向けDBのRealmをMongoDB社が買収し、双方向のデータ同期を始めとした、モバイルアプリとAtlasとの連携性を大幅に強化しています。しかも無料枠が充実!
実際に使用してAndroidアプリを作ってみたので、紹介記事や、実際にアプリを作成した記事をご覧いただければと思います。
具体的な手順:①Ambient
公式サイトやこちらのサイトを参考にすれば、実装できると思います。
このツールで、下記グラフのような見える化をクラウド上で実現できます
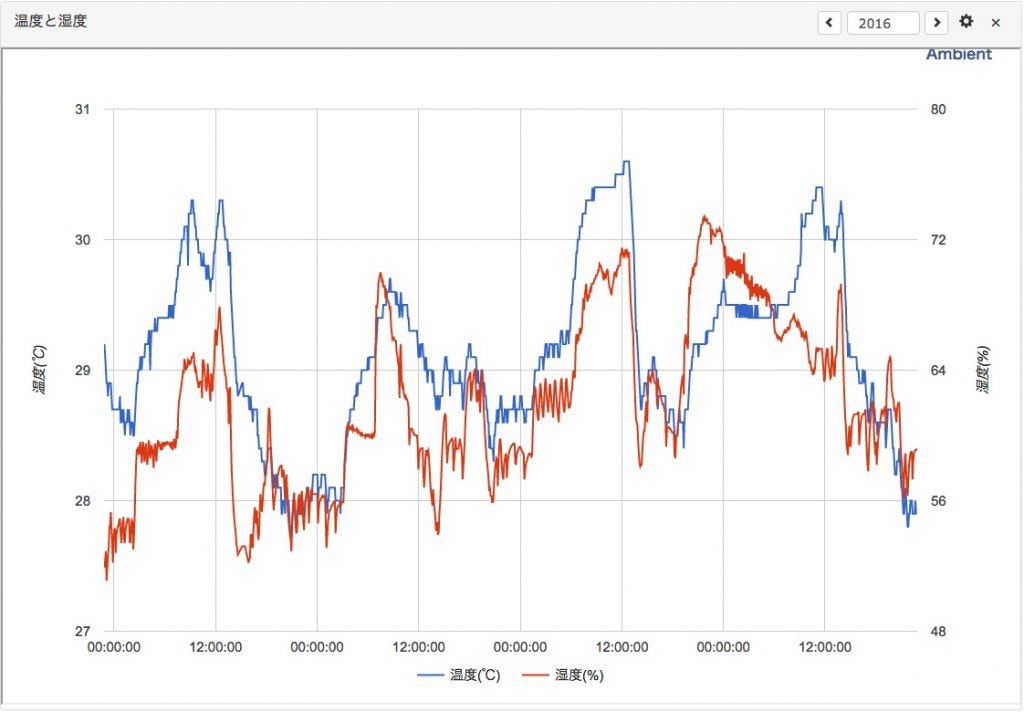
とても簡単に操作・管理できる素晴らしいサービスなので、まずは一度触ってみるのが良いかと思います。
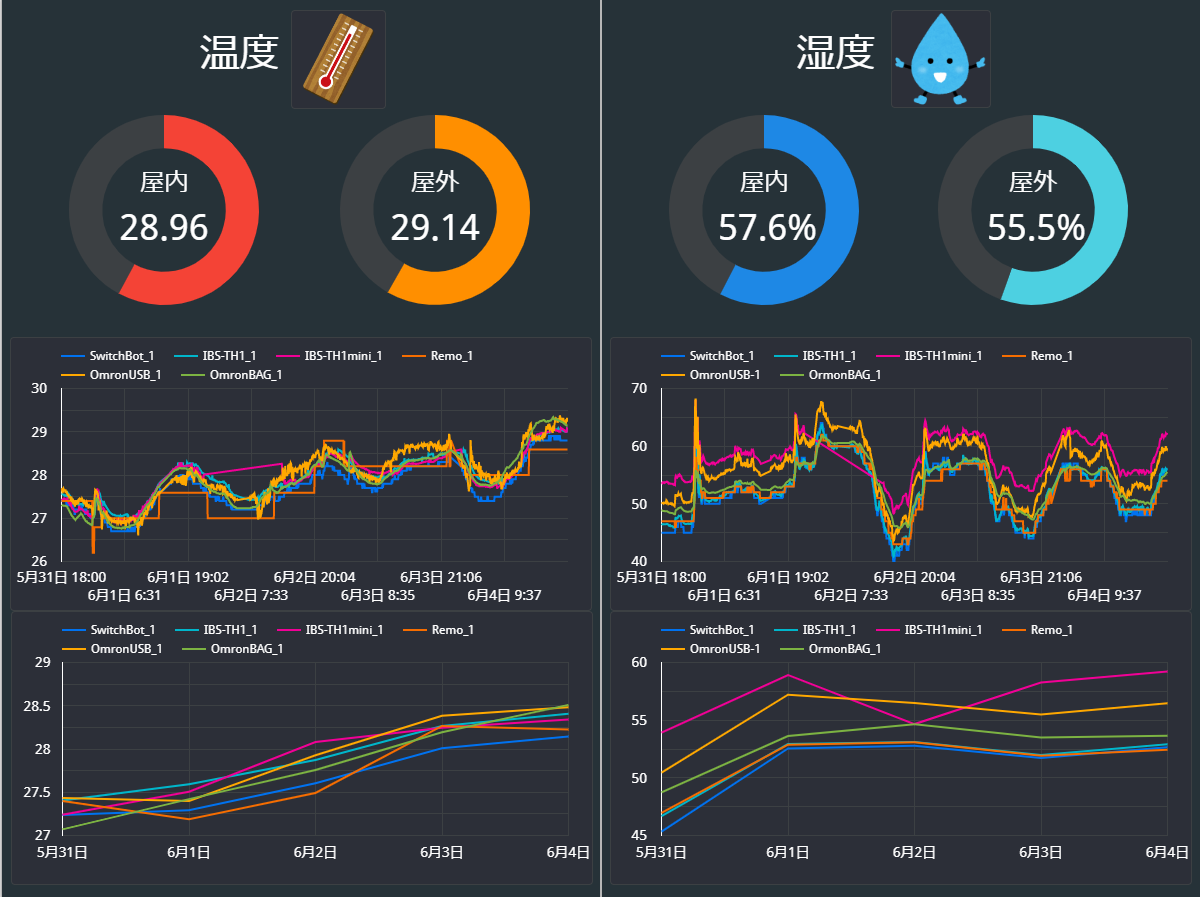
具体的な手順:②Google Spreadsheets + Google Data Portal
下の図のようなダッシュボードが出力されます。
構成は下記のようになります
GoogleDataPortalは綺麗なUIをノンプログラミングで簡単に作る事ができます。
また使い慣れたGoogleのサービスを使用しており、安心感があるのも良いですね。
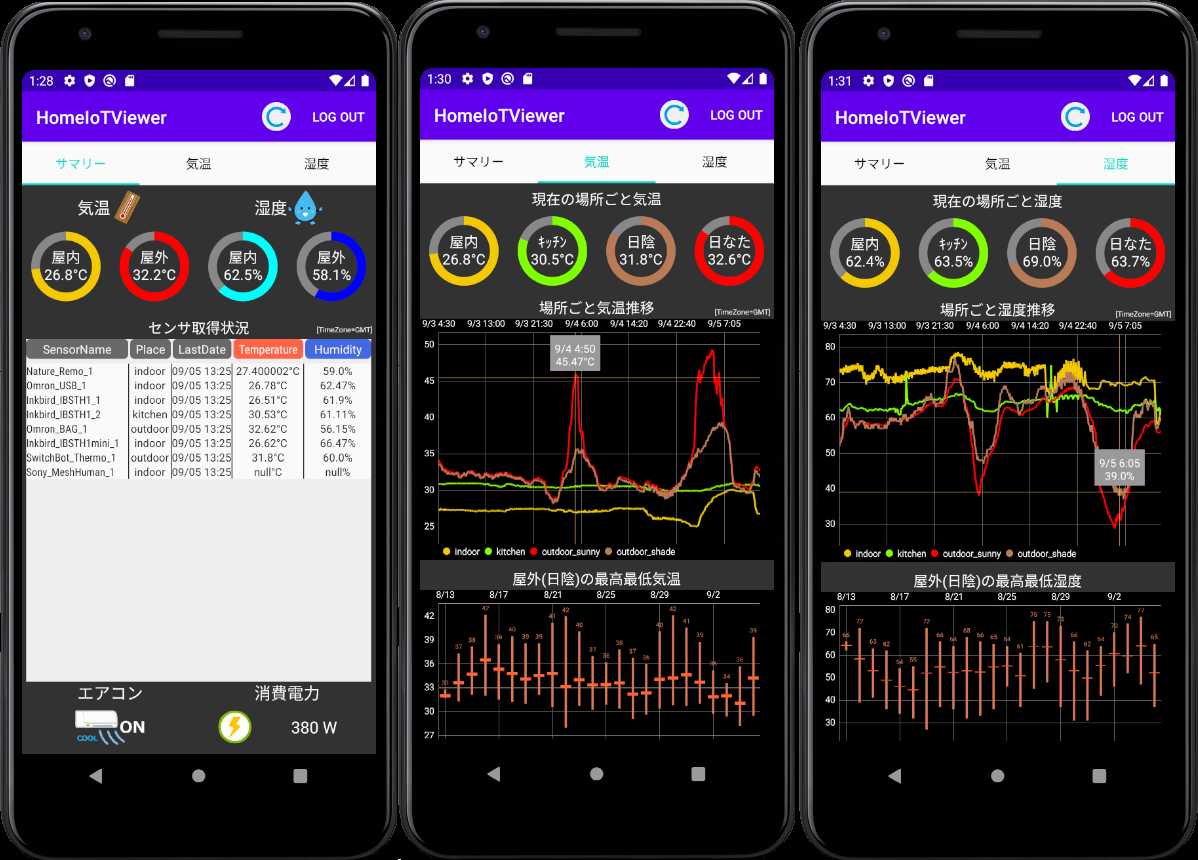
具体的な手順:③クラウドDB+自作可視化アプリ
クラウドDBも可視化ツールも種類が多いですが、
ここでは分析用途を想定し、MongoDB Atlas+Jupiter Notebookによる可視化を試してみました。
※下図のような自作Androidアプリも作ってみましたが、こちらは別記事で紹介します。
1. MongoDB AtlasへのDB作成と、RaspberryPiからのデータアップロード
こちらの記事の1章(MongoDB Atlasへの登録)と2章(RaspberryPiからのアップロード処理作成)の内容を実施してください
2. PythonからDBへのアクセス確認
PythonからMongoDB AtlasのDBにアクセスし、データが取得できることを確認します。
pymongoのインストール
PythonからMongoDBにアクセスするためのライブラリ「PyMongo」をインストールします
pip3 install pymongo
これだけだと
The "dnspython" module must be installed to use mongodb+srv
というエラーが出るので、下記コマンドでdnspythonをインストールします
pip3 install dnspython
データの取得
取得したデータをPandasに読み込ませます
import pandas as pd
import pymongo
def get_collection_to_df(collection_name, filter=None, projection=None):
#各種DB情報の定義
USER_NAME = "1章で作成したMongoDB Atlasのユーザ名"
CLUSTER_NAME = "1章で作成したMongoDB AtlasのCluster名"
DB_NAME = "1章で作成したMongoDB AtlasのDB名"
PASSWORD = "DBのパスワード"
#MongoDBにアクセス(pymongoのMongoClientインスタンス作成)
client = pymongo.MongoClient(f"mongodb+srv://{USER_NAME}:{PASSWORD}@{CLUSTER_NAME}.jipvx.mongodb.net/{DB_NAME}?retryWrites=true&w=majority")
#データを取得してPandasのDataFrameに入力
collection = client[DB_NAME][collection_name]
cursor = collection.find(filter=None, projection=None)
df = pd.DataFrame(list(cursor))
return df
※引数filterおよびprojectionはDBから取得するデータにフィルタや射影を掛ける際に使用します
Jupyter Notebookでデータの冒頭だけ表示
上記に対してJupyter Notebook等でデータが取得できていることを確認できれば成功です。
なお、Jupyter Notebookのインストール方法はこちらに分かりやすくまとめられております
※Anacondaを使用する場合ライセンスに注意
import atlastest
import pandas as pd
SENSOR_COLLECTION_NAME = "1章で作成したセンサデータアップロード用コレクション名"
df = get_collection_to_df(SENSOR_COLLECTION_NAME)
df.head()
_id Date_Master Date_ScanStart no01_DeviceName no01_Date no01_Temperature no01_Humidity no01_Light no01_Human_last no01_HumanMotion ... no07_DeviceName no07_Date no07_Temperature no07_Humidity no07_BatteryVoltage no08_DeviceName no08_Date no08_HumanLast no08_HumanMotion _partition
0 5f68cf4cadc32a9b7fbce8ae 2020-09-22 01:05:00 2020-09-22 01:05:04.159 Nature_Remo_1 2020-09-22 01:05:06.337 27.4 47.0 53.0 2020-09-21T16:04:58Z 1.0 ... SwitchBot_Thermo_1 2020-09-22 01:05:30.018 23.3 55.0 100.0 Sony_MeshHuman_1 2020-09-22 01:05:32.399 None 0 Project HomeIoT
1 5f68d0723c72e8deb4315773 2020-09-22 01:10:00 2020-09-22 01:10:04.524 Nature_Remo_1 2020-09-22 01:10:06.702 27.4 47.0 42.0 2020-09-21T16:09:15Z 1.0 ... SwitchBot_Thermo_1 2020-09-22 01:10:23.870 23.3 56.0 100.0 Sony_MeshHuman_1 2020-09-22 01:10:26.213 None 0 Project HomeIoT
2 5f68d1a3d4916d1fe1d054dc 2020-09-22 01:15:00 2020-09-22 01:15:03.862 Nature_Remo_1 2020-09-22 01:15:06.092 27.4 47.0 42.0 2020-09-21T16:09:15Z 0.0 ... SwitchBot_Thermo_1 2020-09-22 01:15:28.639 23.3 55.0 100.0 Sony_MeshHuman_1 2020-09-22 01:15:31.024 None 0 Project HomeIoT
3 5f68d2cb85e3ac1c7982ef6a 2020-09-22 01:20:00 2020-09-22 01:20:04.550 Nature_Remo_1 2020-09-22 01:20:06.749 27.4 47.0 42.0 2020-09-21T16:15:44Z 1.0 ... SwitchBot_Thermo_1 2020-09-22 01:20:24.392 23.2 55.0 100.0 Sony_MeshHuman_1 2020-09-22 01:20:26.968 None 0 Project HomeIoT
4 5f68d3f93fa649955fe4a5a5 2020-09-22 01:25:00 2020-09-22 01:25:04.178 Nature_Remo_1 2020-09-22 01:25:06.387 27.4 47.0 42.0 2020-09-21T16:15:44Z 0.0 ... SwitchBot_Thermo_1 2020-09-22 01:25:27.275 23.3 55.0 100.0 Sony_MeshHuman_1 2020-09-22 01:25:29.709 None 0 Project HomeIoT
3. Jupyter Notebookでグラフ表示
2章で取得したデータを、Jupyter Notebook (Matplotlib, Seaborn)でグラフ化してみます。
1週間分の気温をセンサごとに折れ線グラフ化
import atlastest
import pandas as pd
import pymongo
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
SENSOR_COLLECTION_NAME = "1章で作成したセンサデータアップロード用コレクション名"
LIST_COLLECTION_NAME = "1章で作成したセンサ一覧コレクション名"
# 1週間分のデータをフィルタで取得
startdate = datetime.now() - timedelta(days=7)
flt = {"Date_Master":{"$gte":startdate}}
df = atlasclient.get_collection_to_df(COLLECTION_NAME, filter=flt)
# センサ情報を取得してdict化
df_sensor_list = atlasclient.get_collection_to_df(LIST_COLLECTION_NAME)
name_dict = {'no'+format(device.no,'02d'):device.sensorname for device in df_sensor_list.itertuples()}
# 抽出対象列('Date_Master' + '_Temperature'で終わる列)
datecols = df.columns.str.endswith('Date_Master')
tempcols = df.columns.str.endswith('_Temperature')
extractcols = np.logical_or(datecols, tempcols)
df_temp = df.iloc[:, extractcols]
# 列名から'_Temperature'を削除
for colname in df_temp.drop('Date_Master', axis=1).columns:
df_temp = df_temp.rename(columns={colname:colname.replace('_Temperature', '')})
display(df_temp.rename(columns=name_dict).tail(1))
# 全て表示
df_temp.rename(columns=name_dict).plot(x='Date_Master', rot=90, figsize=(18, 6))
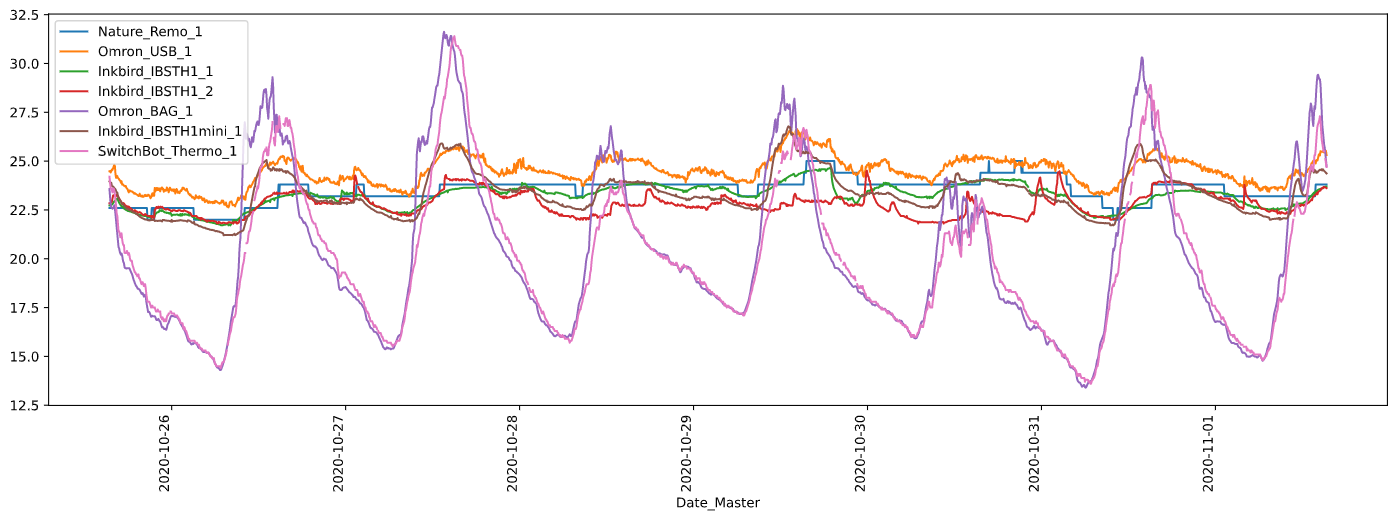
1週間分の湿度を場所ごとに折れ線グラフ化
import atlastest
import pandas as pd
import pymongo
from datetime import datetime, timedelta
import matplotlib.pyplot as plt
import seaborn as sns
SENSOR_COLLECTION_NAME = "1章で作成したセンサデータアップロード用コレクション名"
LIST_COLLECTION_NAME = "1章で作成したセンサ一覧コレクション名"
# 1週間分のデータをフィルタで取得
startdate = datetime.now() - timedelta(days=7)
flt = {"Date_Master":{"$gte":startdate}}
df = atlasclient.get_collection_to_df(COLLECTION_NAME, filter=flt)
# センサ情報を取得してdict化
df_sensor_list = atlasclient.get_collection_to_df(LIST_COLLECTION_NAME)
name_dict = {'no'+format(device.no,'02d'):device.sensorname for device in df_sensor_list.itertuples()}
# 抽出対象列('Date_Master' + '_Humidity'で終わる列)
datecols = df.columns.str.endswith('Date_Master')
humidcols = df.columns.str.endswith('_Humidity')
extractcols = np.logical_or(datecols, humidcols)
df_humid = df.iloc[:, extractcols]
# 列名から'_Humidity'を削除
for colname in df_humid.drop('Date_Master', axis=1).columns:
df_humid = df_humid.rename(columns={colname:colname.replace('_Humidity', '')})
# 屋外の温度列名をリスト化
outdoor_humidcol_list = ['no'+format(device.no,'02d') for device in df_sensor_list.itertuples() if device.place.split('_')[0] == 'outdoor' and device.humidity == True]
# キッチンの温度列名をリスト化
kitchen_humidcol_list = ['no'+format(device.no,'02d') for device in df_sensor_list.itertuples() if device.place == 'kitchen' and device.humidity == True]
# 屋内の温度列名をリスト化
indoor_humidcol_list = ['no'+format(device.no,'02d') for device in df_sensor_list.itertuples() if device.place == 'indoor' and device.humidity == True]
# 屋外、屋内、キッチンの平均をとってプロット
df_humid_inout = df_humid[["Date_Master","no01"]]
df_humid_inout['Outdoor'] = df_humid[outdoor_humidcol_list].mean(axis=1)
df_humid_inout['Kitchen'] = df_humid[kitchen_humidcol_list].mean(axis=1)
df_humid_inout['Indoor'] = df_humid[indoor_humidcol_list].mean(axis=1)
df_humid_inout = df_humid_inout.drop('no01', axis=1)
# 表示
df_humid_inout.plot(x='Date_Master', rot=90, figsize=(12, 4))
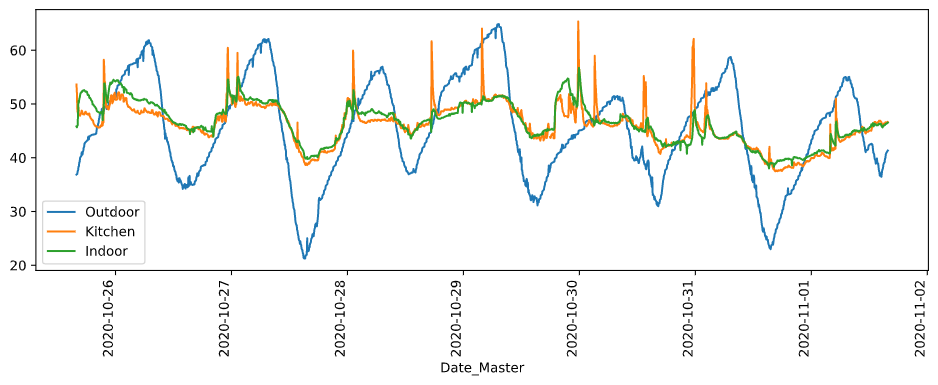
1週間分の湿度を場所ごとに箱ひげ図表示
前節スクリプトの最後の行を下記のように置き換えて、箱ひげ図表示することも可能です(Seaborn使用)
# 場所ごとの列を行に分解して、箱ひげ表示
df_humid_stack = df_humid_inout.set_index('Date_Master')
df_humid_stack = df_humid_stack.stack()
df_humid_stack = df_humid_stack.reset_index()
df_humid_stack = df_humid_stack.rename(columns={'level_1':'place', 0:'Humidity'})
sns.boxplot(data=df_humid_stack ,x='place', y='Humidity')
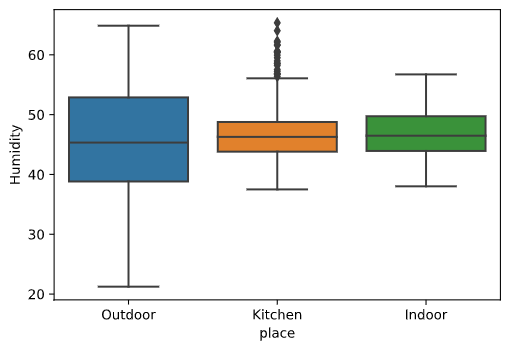
屋外より屋内の方がばらつきが大きく、またキッチンは外れ値(お湯を沸かすと湿度UP)が多くみられます
以上のように、RaspberryPiで取得したデータを可視化することが出来ました!
PandasのDataFrameに入れさえしてしまえば、あとはどうとでもなる。という印象です。
Jupyter Notebookは気軽に可視化できますが、多人数での共有には向かないので、その場合はWebアプリを自作するかBIツールを使用するのが良いかと思います。
まとめ
・RaspberryPi取得データをタダで見える化する方法
①Ambient使用
②Google Spreadsheets + Data Portal
③クラウドDB + 自作可視化アプリ」
・クラウドDBは無料枠のあるサービスも多い。容量上限や連携サービスを見て選定がGood
・MongoDB Atlas + Jupter Notebook(&別記事でスマホアプリ作成)で実際に可視化してみた